一致性哈希和分库分表有毛关系?
“开局一问:分库分表行为中,一致性哈希到底用处大不大?
现在是大数据的时代,其中一个体现就是数据量非常庞大。当然大数据的概念绝非是数据量就可以定义的,我自己给大数据下的定义是:无处不在的大量数据,这些数据是要经过收集,加工,转化,然后输出具有业务意义的数据,比如:现在人物画像。
回归主题,那到底什么样的场景下才开始分库分表呢:
数据量大 存储压力大 提高写操作IO 提高读操作IO
“这里多啰嗦一句,如果你的分库分表存储最终还是落在一个物理磁盘上,其实整体IO的提高并不明显,应该把分出的库(分区表)散落在多个物理磁盘,利用并行IO来提高性能。
设计到分库分表策略,我建议选择有业务意义的键值作为分的依据。举个例子,拿用户信息来说,如果业务中多数是根据用户ID来取用户信息的场景,那应该利用用户id作为分的策略主键。
接下来的部分就以用户信息的场景来举例说明。
分库分表行为属于变动性行为,因为,随着数据量的不断增大,分库分表的策略会随着改变,最简单的例子,现在分了10个表,当数据量到达10个表的巅峰容量时候,就需要继续分,这就是变动因子。最致命的是这个变动因子会影响已有数据的定位。
现在有很多缓存的应用场景和分库分表思想类似,但是却又有本质的区别,因为缓存数据不需要持久化,所以就算是定位错了,重新加载即可,数据库可就不一样了
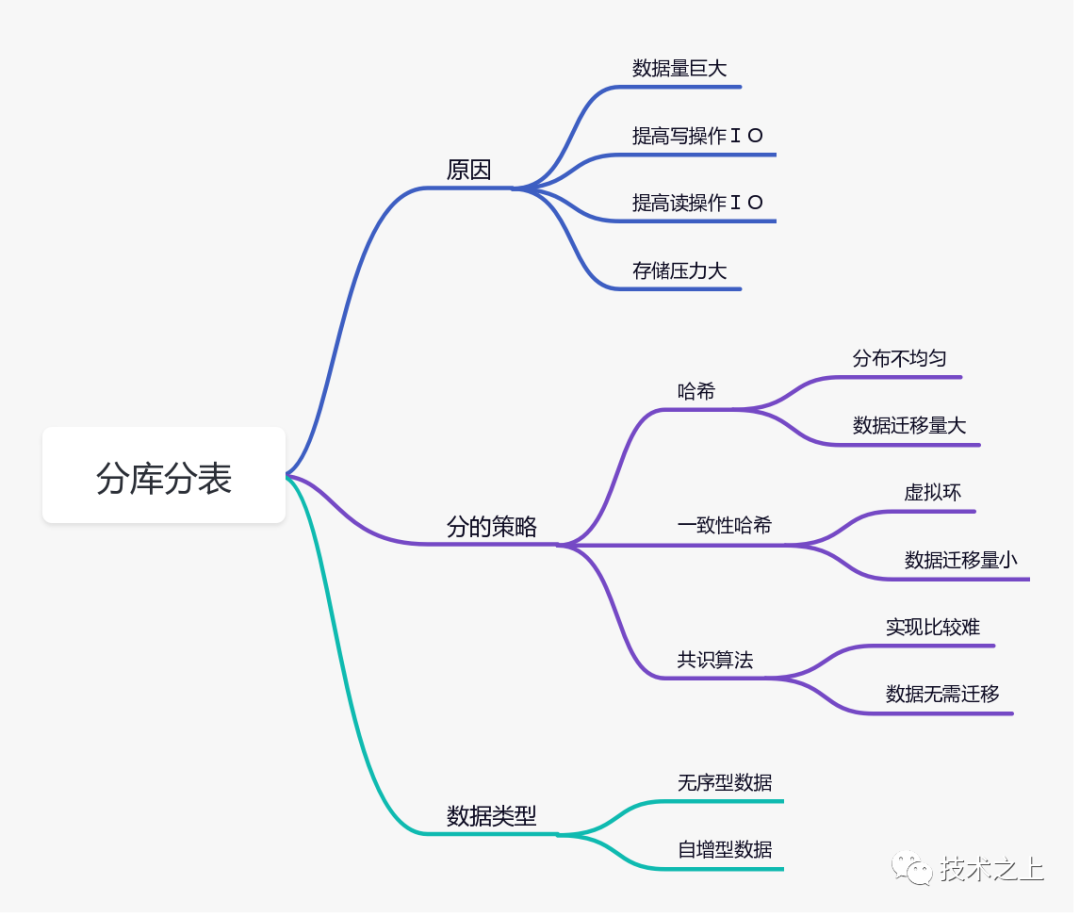
简单哈希有用吗?
分库分表最简单的策略就是对业务数据键取模(%),以余数来作为导向。带来的问题也显而易见:
数据很有可能分布不均匀 数据量迁移量大
所以真实的落地项目中,用简单哈希分库分表的很少,这就诞生了简单哈希无用论。
一致性哈希
一致性哈希算法在1997年由麻省理工学院提出的一种分布式哈希(DHT)实现算法,设计目标是为了解决因特网中的热点(Hot spot)问题。一致性hash算法提出了在动态变化的Cache环境中,断定哈希算法好坏的四个定义:
平衡性(Balance):平衡性是指哈希的结果可以尽量分布到全部的缓冲中去,这样可使得全部的缓冲空间都获得利用。不少哈希算法都可以知足这一条件。 单调性(Monotonicity):单调性是指若是已经有一些内容经过哈希分派到了相应的缓冲中,又有新的缓冲加入到系统中。哈希的结果应可以保证原有已分配的内容能够被映射到原有的或者新的缓冲中去,而不会被映射到旧的缓冲集合中的其余缓冲区。 分散性(Spread):在分布式环境中,终端有可能看不到全部的缓冲,而是只能看到其中的一部分。当终端但愿经过哈希过程将内容映射到缓冲上时,因为不一样终端所见的缓冲范围有可能不一样,从而致使哈希的结果不一致,最终的结果是相同的内容被不一样的终端映射到不一样的缓冲区中。这种状况显然是应该避免的,由于它致使相同内容被存储到不一样缓冲中去,下降了系统存储的效率。分散性的定义就是上述状况发生的严重程度。好的哈希算法应可以尽可能避免不一致的状况发生,也就是尽可能下降分散性。 负载(Load):负载问题其实是从另外一个角度看待分散性问题。既然不一样的终端可能将相同的内容映射到不一样的缓冲区中,那么对于一个特定的缓冲区而言,也可能被不一样的用户映射为不一样 的内容。与分散性同样,这种状况也是应当避免的,所以好的哈希算法应可以尽可能下降缓冲的负荷。
看完上边这几条比较官方的介绍应该大体了解了一致性哈希的特性,用作分库分表场景下也无可厚非,对比简单哈希,它要好很多。
其实,一致性哈希算法也是使用取模的方法,但是它把分母扩大到了2^32,纵观所有的业务场景,能把数据库(表)分到2的32次方个的也是个“人才”了。一致性哈希把2的32次方想象成一个圆形,这个圆形上有2^32个点。具体的一致性哈希请移步这里
“
一致性哈希虽然解决了一些问题,但是数据倾斜问题依然存在,为了使数据最大程度上平均分布,所以引入了虚拟哈希节点的玩法:对同一个物理服务器节点,通过不同的哈希算法或者其他手段得到多个不同的哈希值,均匀分布在哈希环上。
“其实一致性哈希环点的个数没有必要是2的32次方个,我觉得只要足够大得支撑将来业务的扩展即可,同时能满足最大平均分配的原则。
共识算法
共识算法在分库分表的场景中很少有人提出,它现在广泛用于分布式系统中,像喜闻乐见的Paxis,Raft都属于共识算法。
分库分表业务场景下,就算了一致性哈希做到极致,当服务器节点增加或者减少的时候,总有需要数据需要迁移,只不过是多少的问题。那有没有办法不用迁移数据呢?
首先说明一点:数据库不像缓存服务一样,可以随时减少节点。数据库是有状态的,一般只增不减。
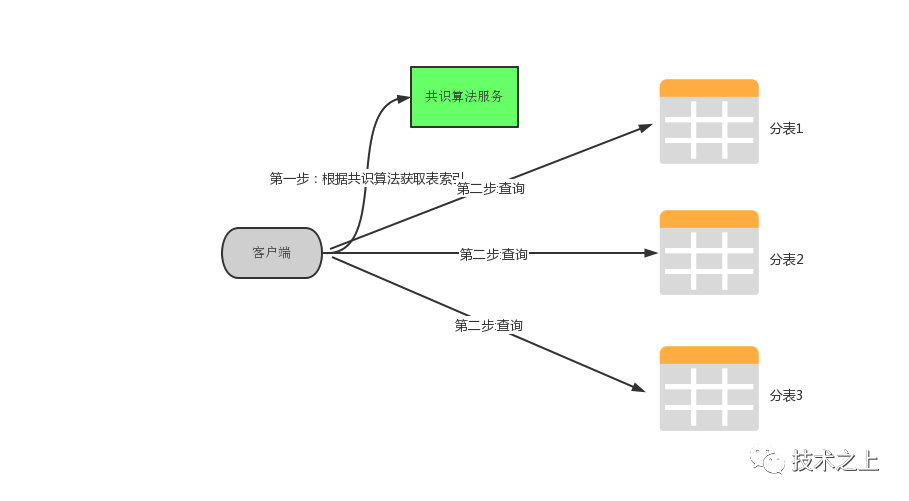
利用共识算法,我认为在只增加节点的情况下是可以做到不迁移数据的。因为共识算法的特性就是:一个值达成一致之后,这个值就不会变化了。
假设:现在对用户信息表已经分了5张表,用户id为1的会落在表1,id为2的会落在表2.....依此类推(这里可以先不考虑一致性哈希虚拟节点,因为原理类似),当增加分表6的时候,按照简单哈希原则,id为6的用户信息应该在表6中,但是现实情况是在表1中,按照以往的经验,这条数据是需要迁移的。
但是引入了共识算法之后,id为6的用户数据被算法认为仍然在表1中,因为已经达成了共识。前提是你需要开发一套共识算法服务来保证,为什么很少有人这么用呢,也许是共识算法门槛过高的原因,但是它却能真正的解决我们的问题。
自增型数据
以上的说明都是针对散乱型数据而言,其实还有一种log型数据,简单来说就一直追加型的数据,比如操作日志,这种数据的典型特点就是时间有序,这样的数据进行分库分表,完全可以按照时间维度来进行的,比如:可以设计一个月为一个表,类似table_202109
写在最后
无论哪种分表方式,都避免不了热点问题,就像微博,一个明星出轨了,这条数据就会成为热点,而这一条数据只能存储于一个表中。解决这种热点问题从来都不能依靠数据库,像缓存,CDN等解决方案才是正解。