
存储介质(SCM)应用设计思考

首先,介绍一下SCM介质的种类。除了英特尔公司的傲腾,整个SCM介质产业包括非常多的种类,包括MRAM、ReRAM、FRAM、Fast NAND,其中Fast NAND的时延是经过优化和改造的,也包括纳米技术碳基半导体的NRAM,这个产业在初步形成之中。
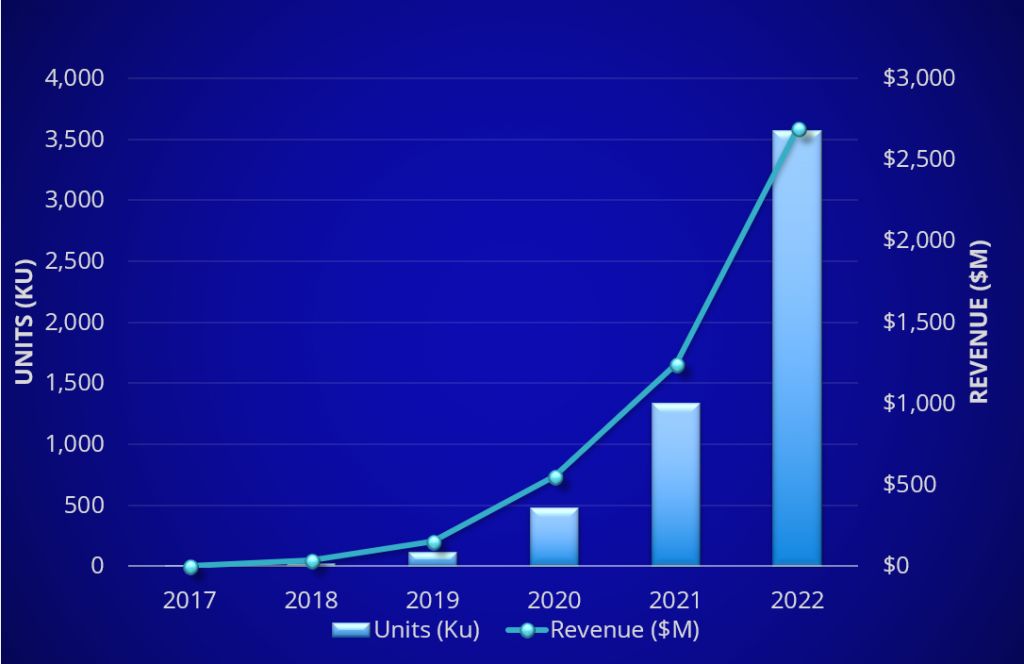
到2022年,估计这个产业可以达到约27亿美元。而整个内存产业的产值是1000亿美金的规模。从商业角度看,在SCM介质也还在初期发展阶段。眼前,一些PCM、Fast NAND SCM介质落地应用,速度也出乎了一些人的意料。毕竟SCM介质在很多方面,比如说时延,不如DRAM,寿命也不行,DRAM的寿命几乎认为是无限的。还有部分时延好的SCM类型,但它的容量不是很大,不能达到内存应用的标准。不管怎样,它已经开始少量落地,并为整个IT,云应用做出了尝试和实践。
这张图可以更清晰地看到,各种SCM介质的种类以及材料。整个半导体产业都在寻求更多材料的解决方案。这些解决方案,可以带来对内存容量需求的补充,同时也可以带来对于内存性能的提升。
SCM可以处在两个位置。从CPU往下,它可以位于SRAM和DRAM中间,时延可以小于内存的时延。这部分SCM介质目前的发展,比如像(MRAM),它利用是自旋霍尔效应,研发出快速介质,但它的容量比较小,成本也相对比较高。它的性能,时延和寿命却远好于例如已经开始实验应用的PCM类型介质。
已经落地的一些新介质商用的话,属于PCM种类的新介质。它的时延可以达到几百个纳秒,对于整个未来数据价值的引导,需要考虑SCM介质在多个方面(性能超越内存,容量更具性价比)发挥作用,共同加速应用。
多核CPU的频率提升。CPU的性能每年大概60%的持续增长。专家们经常也提到,DRAM性能容量增长相对落后于CPU。我们要提升每个CPU核的内存访问性能,如果只是基于比内存还高时延的PCM介质,可能会出现一些不如人意的地方。
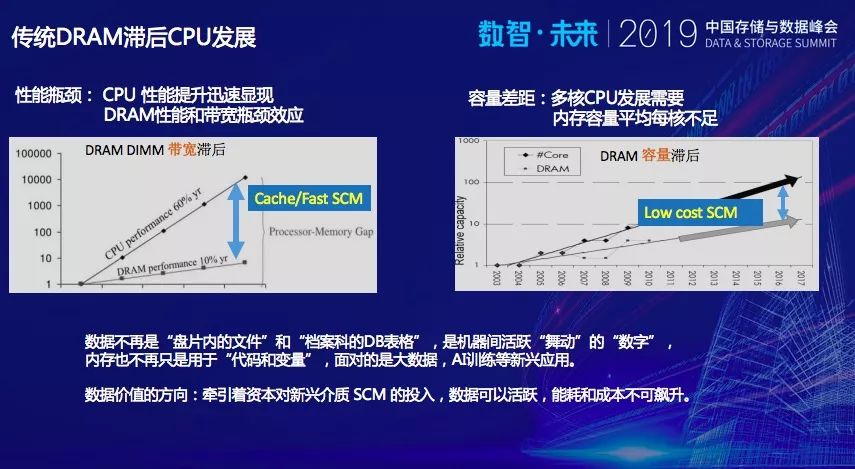
上图中左边,内存性能墙,需要一种低时延SCM介质,姑且称为Fast SCM。在未来的大数据以及AI训练,需要非常快速的内存访问应用,提供非常低的时延。配合多核的算力,可以充分发挥出性能,解决带宽的问题。
右边这个,要寻求一种低成本SCM,成本较低,容量较大,在多核CPU的环境中,不管云应用还是企业环境中,每个CPU可以使用内存容量,性能效果都重要。两方面都是需要兼顾和结合。同时,我们也看到,整个资本市场对于SCM介质的投入变得非常积极,面对应用的需求,数据越来越活跃,但系统的能耗和成本是不能飙升。
如果我们应用了SCM介质,可以从哪些方面具体得到收益?举三个例子。
新兴应用加速和简化:第一个例子,也许大家比较熟悉AI的训练,需要大量的模型数据,大量的样本数据,这个数据量,可能会达到几TB到十几TB,甚至几十TB规模。
同时,目前AI训练开发中,AI程序编写是非常高效的,恨不得把所有的数据全部放在内存中,训练的速度就比较快。比如你老板说,明天我们希望知道前一个月所有销售的情况,给你有限的的时间来进行训练学习,比如1~2天,把训练好的模型、学习的结果,应用到下一个销售周期的推理中,自动决定我该怎么样调整我的在线商城的商品推荐。只有1~2时间,所以时间是非常宝贵的。

一个月的销售数据数据,客户交流信息(文字,语音)等是很大量的,需要从IO的存储设备读取这些数据样本,再进行NN网络的训练获得关键特征,这个过程是在有限内存中操作的。中间结果,又要通过IO的方式输出。虽然AI芯片本身连接的内存是非常快的,带宽也是非常高的内存,但是在这个过程中,有大量IO的操作,不管是从性能,还是从编程的方便性来说,都没有达到行业最理想的效果。
程序员的理想是我写的程序不想跟IO打交道,IO操作这个概念,很多时候是拖慢整个系统性能的关键因素。上图这行右边,我们把IO的操作除去,利用SCM介质实现直接内存的操作,一个CNN,一个AI训练的过程,对性能提升,简化了整个编程的过程。

数据快速恢复“所用即所存”:如上图,对于我们的数据库或者存储系统,如果出现了一个业务的恢复场景,不管是什么原因,它需要恢复的时候,是需要从持久化的HDD或者SSD介质中导入数据的,导入后,才能在内存中构建它的数据结构,并且提供服务操作。
从上电开始到提供服务,需要等待IO操作的时间,这个时间对于大型数据系统来说是很漫长的(分钟,甚至小时级)。如果使用了SCM介质,可以实现新型的内存数据库和存储系统设计。它的服务可以瞬间拉起,并且预热,不需要等待IO重建内存数据结构的过程。很多客户对你服务的恢复和停止时间有苛刻的要求,如果你的系统中出现了需要恢复的情况,时间长意味着竞争力差。这个地方可以实现一个数据库新的架构,叫“所用即所存”。
你的数据,链表,矩阵… 在内存中,运行时是怎么提供服务的,最后就可以类似地(适当一些修改checkpoint),直接地持久化存储到SCM,这是非常大的架构和应用收益。

SCM支撑绿色DC:传统的DDR内存需要动态刷新,这个数据不刷新,数据就丢失了,或者就会出现错误。如果运用了持久化的SCM介质,可以减少这种刷新。整个数据中心内存容量运用越来越多,很大一部分能耗是不停地在内存刷新中,消耗了能源。所以我们认为第三个收益,它可以从数据中心能耗综合成本得到收益的。
除了这些,SCM是不是只有收益?我记得在2010年,我们去新加坡的时候,很多专家告诉我们,PCM这种新介质没有前途了,更早的时候,很多公司,其实已经研发了PCM类的SCM介质(例如~2009三星的手机),但是认为MRAM才是更好的方向,因为MRAM比PCM的时延很低很多,达到了内存的时延效果。但目前时延比内存大很多的PCM介质(Intel,美光),FastNAND(东芝)又开始在服务器应用中尝试落地。这些说法谁对,谁不对?我觉得,一切还是要看用市场应用来说话。
我们除了看到SCM应用的可能收益以外,看一下它具体会面临哪些问题和挑战。
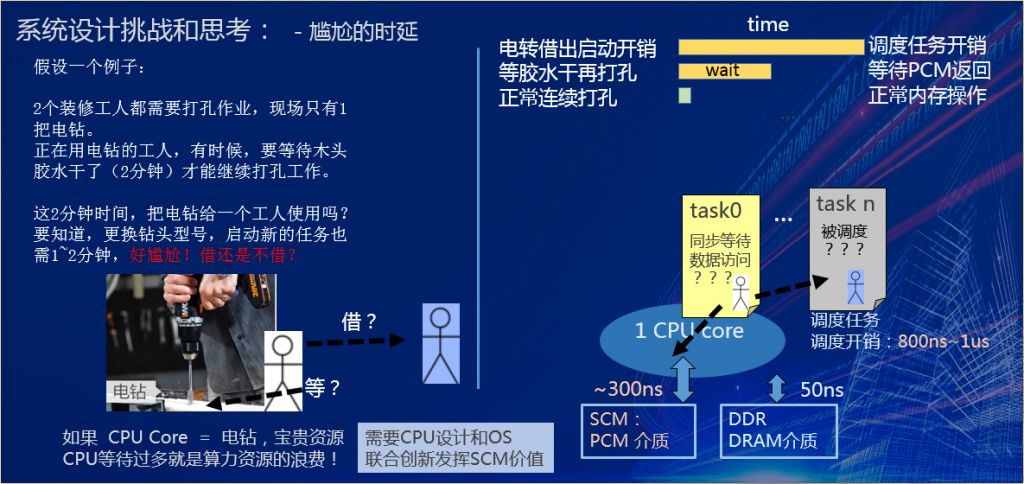
假设我们有两个装修工人,需要同时进行打孔作业,现场只有一把电钻,正在用电钻的工人,平时正常打孔就可以了,但有时候,要等待木头的胶水干了,才能继续打孔工作。2分钟等待胶水干。
这2分钟,是把这个电钻借给另外一个工人,还是继续占用这个电钻,等这个胶水干了?这个选择是非常尴尬的。因为我借给另外一个工人,很可能,第2个工人如果开始他自己的工作,也需要1-2分钟(例如需要换钻头,摆放位置启动工作)。所以,出现了非常尴尬的时延情况,“借”还是“等”?
PCM新介质应用的场景类似。我如果把电钻借给了另外一个人,启动任务的开销时间很长,而等待胶水干,也有一个等待时间。在这种情况下,很难决策。
比喻归比喻,回到系统,上图右边这个CPU核,它在运行的时候,突然要访问PCM介质了,很可能这次访问没有命中它的CPU内的Cache,DRAM也没有缓冲,必须要访问慢速的,但容量很大、密度很高的PCM,访问时间会达到300纳秒。CPU到底是继续等待PCM的数据返回,还是把CPU调度执行其他的任务task n?如果我要调度其他的任务,软件专家们都知道,这个调度本身也是有开销的(us级)。如果,刚好把任务的各种环境上下文拉起来准备好,正要运行的时候,PCM这边的介质数据又返回了,task1也在等待,介质本身这个时延在实际数据业务应用中是非常尴尬的。
如果CPU核等于例子中的“电钻”,它是一个非常宝贵的资源。CPU如果等待SCM介质数据读取返回的时间和次数过多,将使得整个系统的算力浪费,你花钱买的CPU也并不便宜。
值得高兴的是,不管是从学术界还是产业界,在这个问题上都有了一些非常好的解决算法。这个案例就提出来,也是告诉大家,数据系统要用发挥好SCM存储的价值,需要发挥出CPU、操作系统和应用之间的相互紧密的配合,一切才刚刚开始。
下面再来看一个挑战和思考。
大家可以想想,我们对应用的内存访问模型很清楚,还是很陌生?IO的性能和模型,大家非常清楚,因为经常要进行优化,因为IO是整个计算产业中时延最糟糕的一个东西,所有关注性能的IT从业者人都长期在它的泥潭中(SSD替换HDD有缓解)。我们花了大量的时间去优化IO最终交付给客户,每秒钟交易的数量,每个交易延时是怎么样的,如何并发,如何降低任务等待调度,也有大量的工具、经验和成功实践可以参加。
但是!你清楚你应用的内存访问模型吗?相信,这个方向对很多人来说都是一个非常陌生的领域。内存读写有随机和顺序访问的差别吗?自己的某个应用哪些地址的内存被多次访问,哪些地址的内存只是偶尔访问?你关注过吗?怎样的内存访问模型,会造成PCM应用实际性能糟糕?可能得不偿失,比如这个介质慢一点,或者另一种介质快一点,该怎么用它们?
把经常访问的数据,用在比内存还快的SCM介质中去。把不经常访问的数据,放到稍微慢一点的SCM介质中去,这是最直接的想法。但是难的是,哪些时候,哪些空间,哪些页面怎么存放?非常频繁地访问怎么处理?哪些是长期,几十分钟不访问的内存该如何存储性价比更好?需要非常多的实践,应用分析来支撑系统设计。
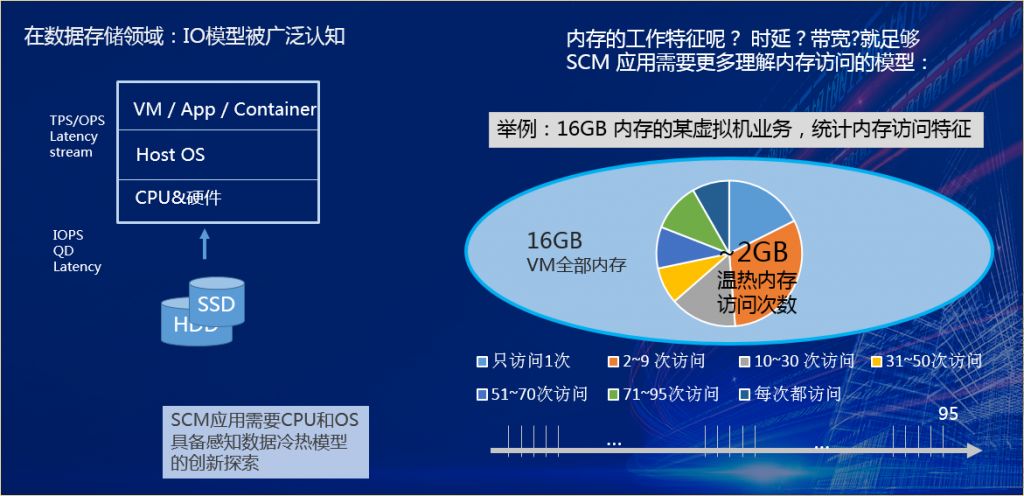
我们可以看某一个虚拟机,实际可以获得它的内存访问特征模型,重点关注它的内存页面访问标志,而不会关心页面中的内容。
我们会看到16G的内存空间内有大量的空间分配了,但并没有访问,中间那个彩色的饼图,大概2GB访问过的内存,称为温热内存数据。在长达6分多钟,95个周期的统计范围内,只有2GB的空间被访问,其他14GB的内存空间一直没有访问。6分钟,如果把这14GB内存用于其他在线服务,可能支撑其完成十万次的交互了。
再深入2GB访问内存中,深蓝色部分,每个周期都有访问,我们认为它是极热。这部分的数据所占比例很小。统计的经验告诉我们,我们希望这部分数据在CPU内以一种非常快速的存储空间来支撑,而不是要CPU去等待,等待那个“胶水”,太慢的SCM介质会是性能的灾难。
设计的原则是,不能够因为我频繁地从慢的介质中访问数据,使得我的整个系统CPU计算能力浪费而受到损失。这个案例告诉我们,SCM介质应用同时也是需要CPU、OS配合,感知数据的内存访问模型,也需要非常多的创新给出解决方案。目前CPU和硬件缓存算法简单粗暴(例如LRU),能起到一些效果,但是它可能是处于SCM应用早期的一种方法。
面对SCM的应用,可以回头看看SSD的应用过程,可以看到SSD刚刚出来的时候,就只是少量的加速,把热文件和数据放在里面。到现在,大家看一下,SSD的应用有非常多深入应用思考,如:识别热数据和冷数据,热数据和冷数据不能放在同一个块里,放同一个块会带来更多的磨损。SCM的时期还处在2008年的SSD时代,对于内存访问模型还需要持续地探索。
总结一下前面的案例看到的问题。内存业务的中坚力量仍然是50纳秒的内存,是最常用的,最容易获得的解决方案。如果认为将来整个数据系统需要容量,同时又需要性能,希望先要从更加广阔的介质中去选择,这个介质业界现在有很多研究。当然最成熟的,行业中比较早期尝试落地的傲腾(Intel,美光)的解决方案已经推出了,也包括Fast NAND(东芝,三星)的应用将在2020年落地。
超低时延的介质,它的容量很低,但更能够在整个系统中发挥出它的配合的性能(前面内存模型案例中极热部分比例很少)。同时,要用好一个SCM介质,任何系统都要付出非常大的代价和努力,要非常长的时间,包括它的CPU设计、介质设计、内存体系架构的修改,整个和业务的配合,怎么动态的调度,这方面不是很短期内就能够完成的。在这样一个协同构建生态的局面下希望未来出现对整个产业界有贡献的解决方案。
1、数据业务的需求对传统内存、带宽和容量形成压力。
2、SCM介质可以在提升性能、简化编程、持久化、快速恢复等痛点上形成收益。现在已经有一些厂家在持久化地快速恢复上,包括数据库,已经形成了一些收益。
3、面对应用的内存模型差异,希望考虑多种的SCM介质类型的配合,发挥出真正的性能优势。
4、CPU操作系统服务以及软件配合。最后还是要看实际的效果表现。
5、SCM仍处在整个实践的初期,包括内存业务模型,可靠性模型,都处于实践的初期。积极地推动这种生态,去积极推动这种实践,才能使得整个高性能且稳定可靠的解决方案。
华为将以致力于每比特价值最大,每比特成本最优,数据安全可靠,持续地投入芯片和基础IT技术的研究。
转载申明:转载本号文章请注明作者和来源,本号发布文章若存在版权等问题,请留言联系处理,谢谢。
推荐阅读
更多架构相关技术知识总结请参考“架构师全店铺技术资料打包”相关电子书(37本技术资料打包汇总详情可通过“阅读原文”获取)。
全店内容持续更新,现下单“全店铺技术资料打包(全)”,后续可享全店内容更新“免费”赠阅,价格仅收198元(原总价350元)。
温馨提示:
扫描二维码关注公众号,点击阅读原文链接获取“架构师技术全店资料打包汇总(全)”电子书资料详情。
