
“梦回童年,尽享美食“-- AI 识别童年美食
❝昨晚终于把憋了很久的 ModelArts + Wechaty 实现有趣的美食图片识别应用跑通了。尽管结合 Wechaty 调用 AI 相关服务在多年以前就被千人实现过了,不过作为小白的我能够借助一站式AI开发平台 ModelArts 新手制作数据集、训练模型并部署,最终通过最好的微信开发库 Wechaty 实现调用 AI 服务的聊天小助手,还是十分有趣的。当然,我也迫不及待地将我的实践分享给大家,也希望能够获得各位大佬的指导!
❞
数据集制作
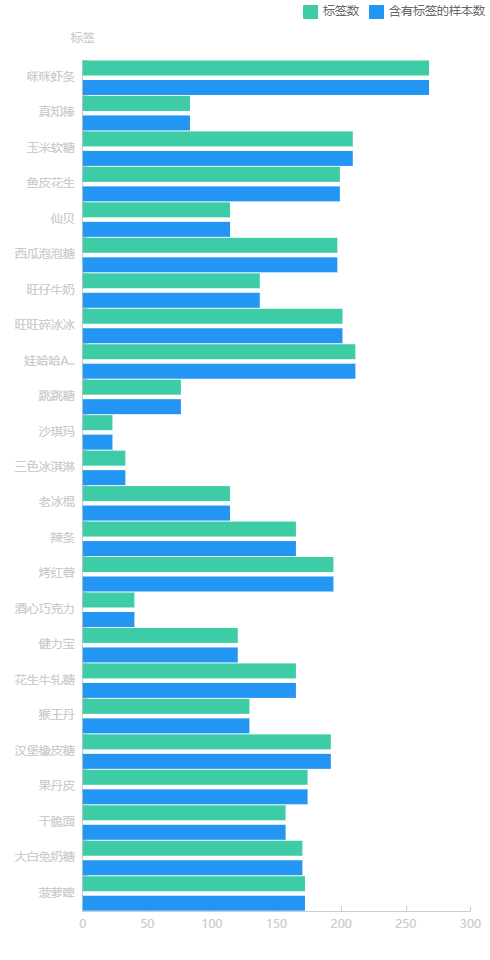
我们从AI开发流程出发,当我确定了我的目的是要结合 ModelArts + Wechaty 来实现童年美食识别,基本上我的技术选型也就确定了,鉴于我学艺不精,零基础都能上手的一站式AI开发平台ModelArts和四行代码就能实现聊天机器人的微信开发库 Wechaty,便成了我唯一的选择。准备数据的阶段,我有幸遇到了前辈贡献的代码,因此能够快速从某度图片获取我想要的图片,具体操作可以查看我的历史文章《新手小白如何快速获取数据集》。我用同样的手法获取到了菠萝啤、大白兔奶糖、干脆面、果丹皮、汉堡橡皮糖、猴王丹、花生牛轧糖、健力宝、酒心巧克力、烤红薯、辣条、老冰棍、三色冰淇淋、沙琪玛、跳跳糖、娃哈哈AD钙、旺旺碎冰冰、旺仔牛奶、西瓜泡泡糖、仙贝、鱼皮花生、玉米软糖、真知棒、咪咪虾条共24个分类,从7200张图片中一张一张分拣,最终标注3543张,实现了一个暂时看上去想那么回事的数据集--《"儿童节特辑"--8090的童年美食》。 不过,目前从数据的标签分布来看,不太合理,被标注最多的标签数量多达268个,而被标注最少的标签数量仅23个,两者差了一个数量级,因此训练出来的模型大概率会跑偏。
不过,目前从数据的标签分布来看,不太合理,被标注最多的标签数量多达268个,而被标注最少的标签数量仅23个,两者差了一个数量级,因此训练出来的模型大概率会跑偏。
在ModelArts上进行数据标注时,其实也是有一定技巧的。比如,我在本地获取到了大量的图片,通过 OBS 的命令行工具上传到 OBS 桶中之后,由于此次标注是图像分类,因此我在标注时可以通过图片存放的 OBS 目录来快速筛选出当前要分拣的标签以及进行标注。目前ModelArts数据集处理时单页最多可显示60张图片,这也给我对图片进行精挑细选提供了强有力的支持。其次,在进行图片挑选时,可以从最后一页进行,每次删除图片时顺带把源文件也从 OBS 中移除,移除往前直至处理到第一页。最后,又可以全选当前页进行标注。整个数据集从数据获取到数据处理再到数据集发布,花了不到2小时,个人感觉对新手小白已经很友好了!

训练及评估模型
如果您对《"儿童节特辑"--8090的童年美食》数据集感兴趣,可以在 AI Gallery 进行一键下载,既可以下载到 OBS 也也可直接下载到 ModelArts 数据集。
基于数据集,在 ModelArts 平台上除了可以自行开发算法并训练模型,也可以使用 AI Gallery 的订阅算法或者直接使用 ModelArts 的自动学习来训练模型。这里为了更简便的操作,本大狮就直接使用简单粗暴的自动学习来实现,主要想看到当前的数据集能训练出怎么样的结果(PS:其实主要是免费,「请把免费打在评论区」),您期待吗?
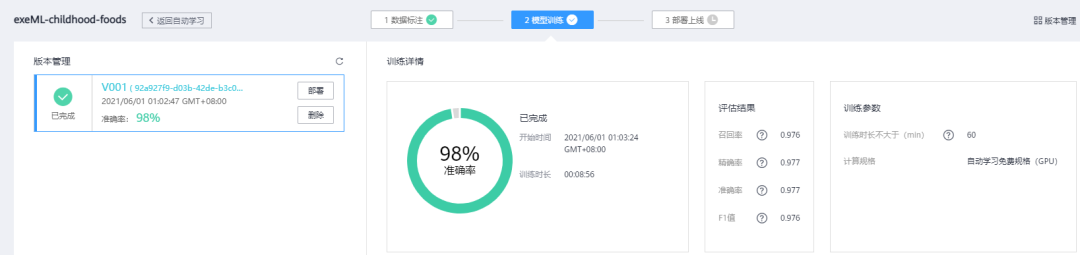
在创建完自动学习的任务运行9分钟之后,我 Get 到了一个模型,从训练结果来看还是非常理想的,不过究竟是骡子是马,还得看最终部署之后的效果。
表中是各个标签所对应的参考值,其中F1值是模型精确率和召回率的加权调和平均,用于评价模型的好坏,当F1值较高时说明模型效果较好;精确度指的是被模型预测为某个分类的所有样本中,模型正确预测的样本比率,反映模型对负样本的区分能力;召回率指的是被用户标注为某个分类的所有样本中,模型正确预测为该分类的样本比率,反映模型对正样本的识别能力。
| 标签名 | F1值 | 精确率 | 召回率 |
|---|---|---|---|
| 三色冰淇淋 | 0.933 | 0.875 | 1.000 |
| 仙贝 | 0.985 | 1.000 | 0.971 |
| 健力宝 | 0.957 | 1.000 | 0.917 |
| 咪咪虾条 | 0.990 | 0.980 | 1.000 |
| 大白兔奶糖 | 0.986 | 0.972 | 1.000 |
| 娃哈哈AD钙 | 0.977 | 0.955 | 1.000 |
| 干脆面 | 0.944 | 0.919 | 0.971 |
| 旺仔牛奶 | 0.971 | 0.971 | 0.971 |
| 旺旺碎冰冰 | 1.000 | 1.000 | 1.000 |
| 果丹皮 | 0.968 | 1.000 | 0.938 |
| 汉堡橡皮糖 | 0.971 | 1.000 | 0.943 |
| 沙琪玛 | 1.000 | 1.000 | 1.000 |
| 烤红薯 | 0.990 | 1.000 | 0.981 |
| 猴王丹 | 1.000 | 1.000 | 1.000 |
| 玉米软糖 | 0.977 | 0.956 | 1.000 |
| 真知棒 | 1.000 | 1.000 | 1.000 |
| 老冰棍 | 1.000 | 1.000 | 1.000 |
| 花生牛轧糖 | 0.947 | 0.973 | 0.923 |
| 菠萝啤 | 0.987 | 1.000 | 0.974 |
| 西瓜泡泡糖 | 0.957 | 0.917 | 1.000 |
| 跳跳糖 | 0.933 | 1.000 | 0.875 |
| 辣条 | 0.969 | 0.969 | 0.969 |
| 酒心巧克力 | 1.000 | 1.000 | 1.000 |
| 鱼皮花生 | 0.978 | 0.957 | 1.000 |
部署模型
目前 ModelArts 支持一个免费的部署服务实例,因为我之前的实践已经占用了名额,因此当我再次在自动学习中部署模型时会提示以下图中的报错,从而我只能去到「部署在线--在线服务」手动新建一个服务实例。
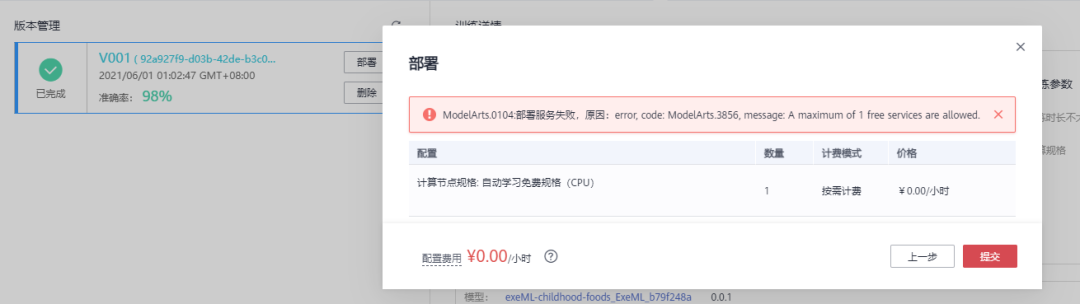
在部署模型的时候,我们可以根据自身的需求添加一些个性化设置或者其他功能,比如数据采集、难例筛选等等。
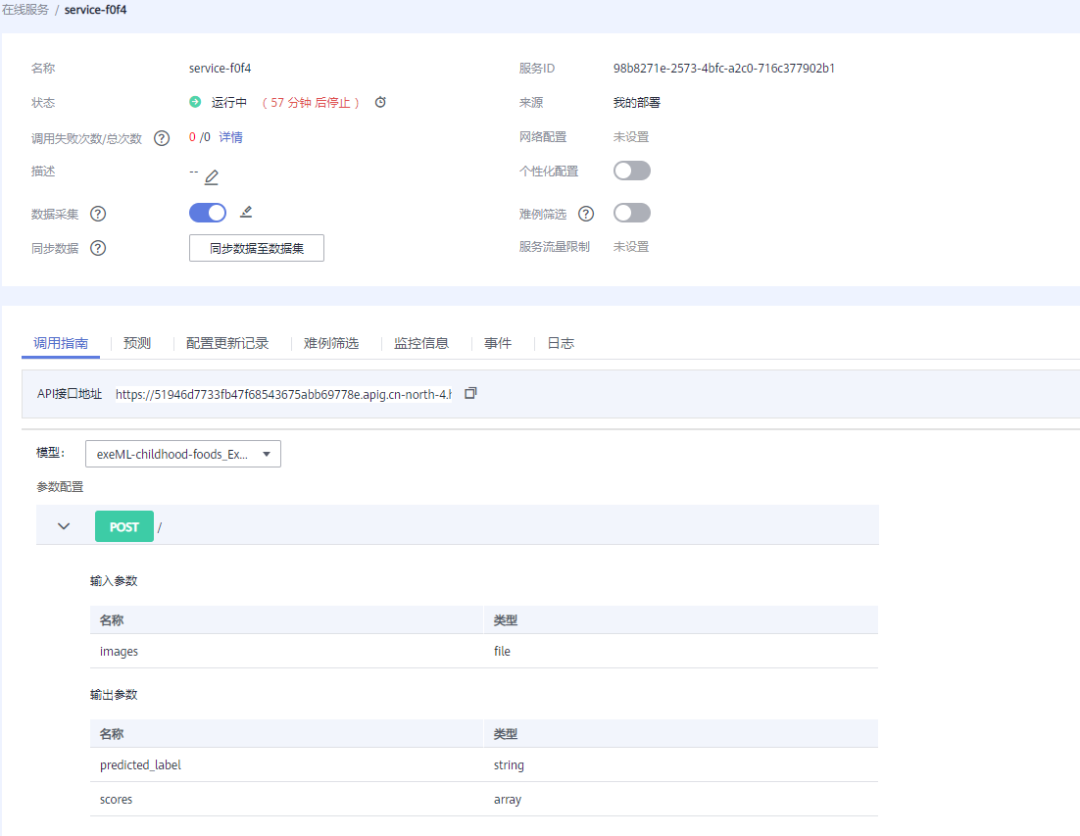
看到服务部署成功之后,我已经迫不及待地想先调试一下,随便找了一张「跳跳糖」的图片,让 AI 识别一下,哎呀还不错哦,感觉比我想象中的要好。ModelArts 的开发部分就告一段落,接着我们按照在线服务的调试指南进行与 Wechaty 的联合开发,“Talk is cheap. Show me the code.”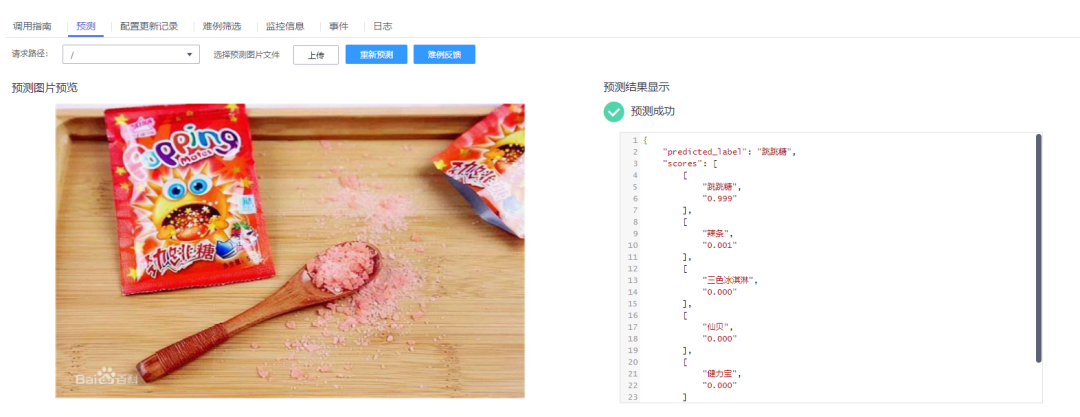
此时,我们获得的信息:AI 服务的在线地址以及file形式的输入参数images。
Wechaty 开发
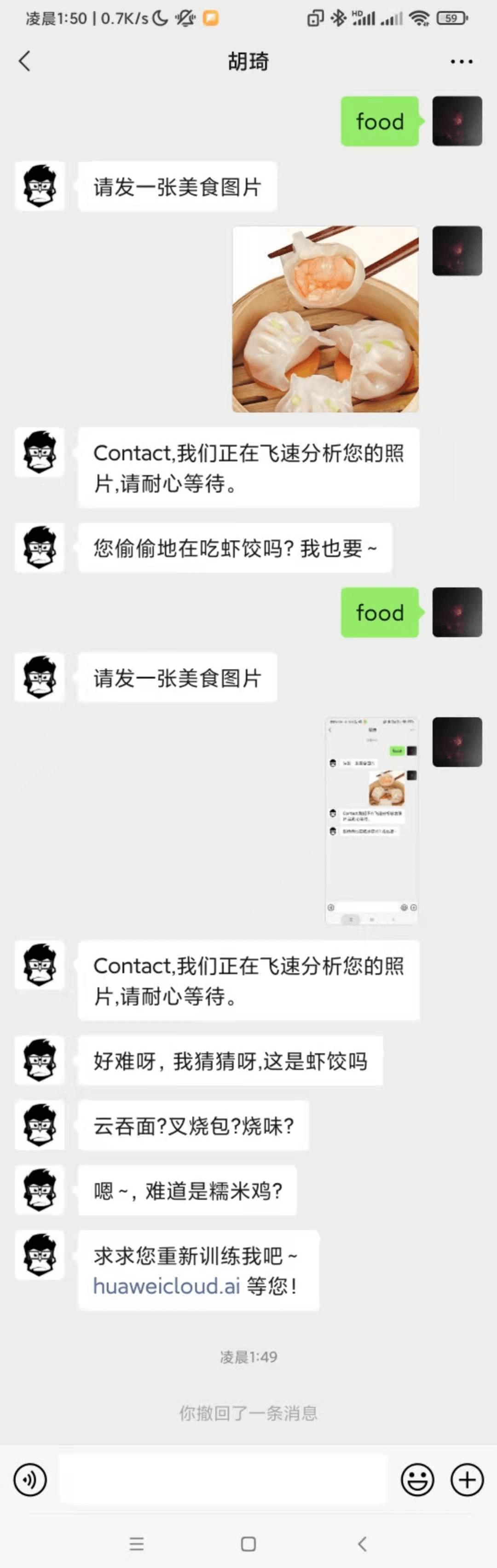
先看看我们最终的呈现效果,也就是像微信机器人发送指定关键字之后再发送图片,微信机器人就会调用 ModelArts 的在线服务来识别图片并将结果返回给微信端。这里我们就需要用到 Wechaty 这个强大的微信开发库。关于 Wechaty 的详细情况,您可以访问 Wechaty 的官网了解--https://wechaty.js.org/。从域名来看,这个开发库应该和 JavaScript 有关,经过翻阅文档,我得知,新手使用 Wechaty 仅需四行代码:
npm install qrcode-terminal --save
npm install wechaty
npm install wechaty-puppet-wechat --save // 这个依赖是关键
export WECHATY_PUPPET=wechaty-puppet-wechat // 这里也是关键,需要配置你使用的puppet
我们可以新建一个文件夹,执行npm init初始化一个项目,然后执行上述代码,接着新建index.js,写入:
const { Wechaty } = require('wechaty');
const name = 'wechat-puppet-wechat';
let bot = '';
bot = new Wechaty({
name, // generate xxxx.memory-card.json and save login data for the next login
});
// 二维码生成
function onScan(qrcode, status) {
require('qrcode-terminal').generate(qrcode); // 在console端显示二维码
const qrcodeImageUrl = [
'https://wechaty.js.org/qrcode/',
encodeURIComponent(qrcode),
].join('');
console.log(qrcodeImageUrl);
}
// 登录
async function onLogin(user) {
console.log(`贴心小助理${user}登录了`);
// if (config.AUTOREPLY) {
// console.log(`已开启机器人自动聊天模式`);
// }
// 登陆后创建定时任务
// await initDay();
}
//登出
function onLogout(user) {
console.log(`小助手${user} 已经登出`);
}
bot.on('scan', onScan);
bot.on('login', onLogin);
bot.on('logout', onLogout);
bot
.start()
.then(() => console.log('开始登陆微信'))
.catch((e) => console.error(e));
基本上就完成了 Wechaty 部分的开发,执行node index.js就能在控制台显示一个二维码,其实类似我们登录桌面端的微信,接着我们主要需要解决的问题:
监听微信消息 -- 可以使用 bot.on('message')来实现;对接 ModelArts -- 可以使用 token 鉴权方式访问; 文件传递 -- 可以通过 form-data进行数据转换。
基本代码实现如下:
// 获取Token
async function getToken() {
let token = ''
const data = {
"auth": {
"identity": {
"methods": [
"password"
],
"password": {
"user": {
"domain": {
"name": config.IAMDomain
},
"name": config.IAMUser,
"password": config.IAMPassword
}
}
},
"scope": {
"project": {
"name": config.IAMProject
}
}
}
}
await axios.post(config.TokenURL, data).then(res => {
token = res.headers['x-subject-token']
}).catch(err => {
console.log(err)
token = ''
});
return token
}
// 识别美食
async function sendImage(fileName) {
let resp = {}
await getToken().then(async res => {
// console.log(res)
const form = new FormData();
form.append('images', fs.createReadStream(fileName));
console.log(form.getHeaders())
await axios.post(config.URL, form, { headers: Object.assign(form.getHeaders(), { "X-Auth-Token": res }) }).then(res => {
console.log(res.data)
resp = res.data
}).catch(err => {
console.log(err)
if (err.response && err.response.data) {
resp = err.response.data
}
})
}).catch(err => {
console.log(err)
resp = err.data
})
return resp
}
完整代码参见:https://github.com/hu-qi/modelarts-wechaty
如需体验可以添加我Hugi66并发送「food」, 也可以登录 AI Gallery -- huaweicloud.ai联系我,期待您的指导!
