
你必须知道的Pandas 解析json数据的函数-json_normalize()
写了好几篇文章了,今天写点很少人写但是很有用的!记得点赞收藏加关注哦。
前言:Json数据介绍
Json是一个应用及其广泛的用来传输和交换数据的格式,它被应用在数据库中,也被用于API请求结果数据集中。虽然它应用广泛,机器很容易阅读且节省空间,但是却不利于人来阅读和进一步做数据分析,因此通常情况下需要在获取json数据后,将其转化为表格格式的数据,以方便人来阅读和理解。常见的Json数据格式有2种,均以键值对的形式存储数据,只是包装数据的方法有所差异:
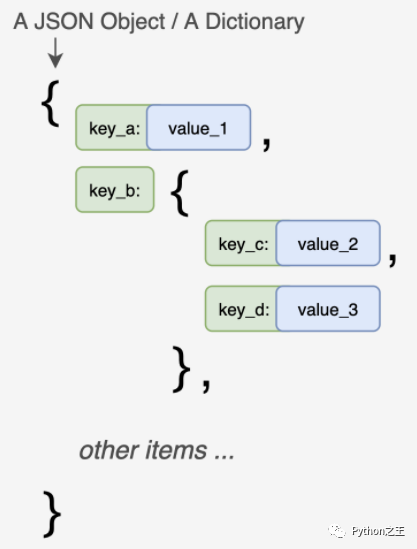
a. 一般JSON对象
采用{}将键值对数据括起来,有时候会有多层{}
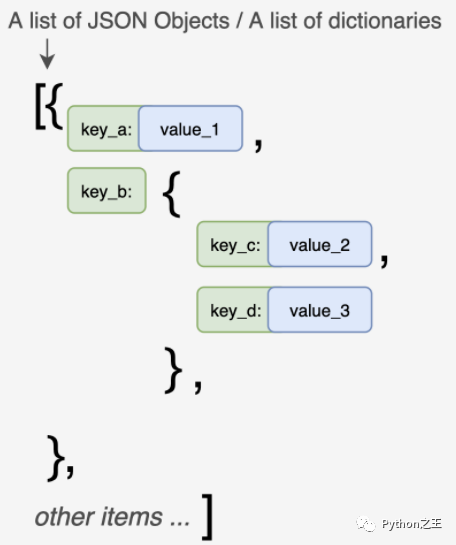
b. JSON对象列表
采用[]将JSON对象括起来,形成一个JSON对象的列表,JSON对象中同样会有多层{},也会有[]出现,形成嵌套列表
这篇文章主要讲述pandas内置的Json数据转换方法json_normalize(),它可以对以上两种Json格式的数据进行解析,最终生成DataFrame,进而对数据进行更多操作。本文的主要解构如下:
解析一个最基本的Json- 解析一个带有多层数据的Json- 解析一个带有嵌套列表的Json- 当 Key不存在时如何忽略系统报错- 使用sep参数为嵌套Json的Key设置分隔符- 为嵌套列表数据和元数据添加前缀- 通过URL获取Json数据并进行解析- 探究:解析带有多个嵌套列表的Json
json_normalize()函数参数讲解
|参数名|解释
|------
|data|未解析的Json对象,也可以是Json列表对象
|record_path|列表或字符串,如果Json对象中的嵌套列表未在此设置,则完成解析后会直接将其整个列表存储到一列中展示
|meta|Json对象中的键,存在多层数据时也可以进行嵌套标记
|meta_prefix|键的前缀
|record_prefix|嵌套列表的前缀
|errors|错误信息,可设置为ignore,表示如果key不存在则忽略错误,也可设置为raise,表示如果key不存在则报错进行提示。默认值为raise|sep|多层key之间的分隔符,默认值是.(一个点)
|max_level|解析Json对象的最大层级数,适用于有多层嵌套的Json对象
在进行代码演示前先导入相应依赖库,未安装pandas库的请自行安装(此代码在Jupyter Notebook环境中运行)。
from pandas import json_normalize
import pandas as pd
1. 解析一个最基本的Json
a. 解析一般Json对象
a_dict = {
'school': 'ABC primary school',
'location': 'London',
'ranking': 2
}
pd.json_normalize(a_dict)
输出结果为:

b. 解析一个Json对象列表
json_list = [
{'class': 'Year 1', 'student number': 20, 'room': 'Yellow'},
{'class': 'Year 2', 'student number': 25, 'room': 'Blue'}
]
pd.json_normalize(json_list)
输出结果为:

2. 解析一个带有多层数据的Json
a. 解析一个有多层数据的Json对象
json_obj = {
'school': 'ABC primary school',
'location': 'London',
'ranking': 2,
'info': {
'president': 'John Kasich',
'contacts': {
'email': {
'admission': 'admission@abc.com',
'general': 'info@abc.com'
},
'tel': '123456789',
}
}
}
pd.json_normalize(json_obj)
输出结果为:
多层key之间使用点隔开,展示了所有的数据,这已经解析了3层,上述写法和pd.json_normalize(json_obj, max_level=3)等价。
如果设置max_level=1,则输出结果为下图所示,contacts部分的数据汇集成了一列
如果设置max_level=2,则输出结果为下图所示,contacts 下的email部分的数据汇集成了一列
b. 解析一个有多层数据的Json对象列表
json_list = [
{
'class': 'Year 1',
'student count': 20,
'room': 'Yellow',
'info': {
'teachers': {
'math': 'Rick Scott',
'physics': 'Elon Mask'
}
}
},
{
'class': 'Year 2',
'student count': 25,
'room': 'Blue',
'info': {
'teachers': {
'math': 'Alan Turing',
'physics': 'Albert Einstein'
}
}
}
]
pd.json_normalize(json_list)
输出结果为:

若分别将max_level设置为2和3,则输出结果应分别是什么?请自行尝试~
3. 解析一个带有嵌套列表的Json
json_obj = {
'school': 'ABC primary school',
'location': 'London',
'ranking': 2,
'info': {
'president': 'John Kasich',
'contacts': {
'email': {
'admission': 'admission@abc.com',
'general': 'info@abc.com'
},
'tel': '123456789',
}
},
'students': [
{'name': 'Tom'},
{'name': 'James'},
{'name': 'Jacqueline'}
],
}
pd.json_normalize(json_obj)
此例中students键对应的值是一个列表,使用[]括起来。直接采用上述的方法进行解析,则得到的结果如下:

students部分的数据并未被成功解析,此时可以为record_path设置值即可,调用方式为pd.json_normalize(json_obj, record_path='students'),在此调用方式下,得到的结果只包含了name部分的数据。

若要增加其他字段的信息,则需为meta参数赋值,例如下述调用方式下,得到的结果如下:
pd.json_normalize(json_obj, record_path='students', meta=['school', 'location', ['info', 'contacts', 'tel'], ['info', 'contacts', 'email', 'general']])

4. 当Key不存在时如何忽略系统报错
data = [
{
'class': 'Year 1',
'student count': 20,
'room': 'Yellow',
'info': {
'teachers': {
'math': 'Rick Scott',
'physics': 'Elon Mask',
}
},
'students': [
{ 'name': 'Tom', 'sex': 'M' },
{ 'name': 'James', 'sex': 'M' },
]
},
{
'class': 'Year 2',
'student count': 25,
'room': 'Blue',
'info': {
'teachers': {
# no math teacher
'physics': 'Albert Einstein'
}
},
'students': [
{ 'name': 'Tony', 'sex': 'M' },
{ 'name': 'Jacqueline', 'sex': 'F' },
]
},
]
pd.json_normalize(
data,
record_path =['students'],
meta=['class', 'room', ['info', 'teachers', 'math']]
)
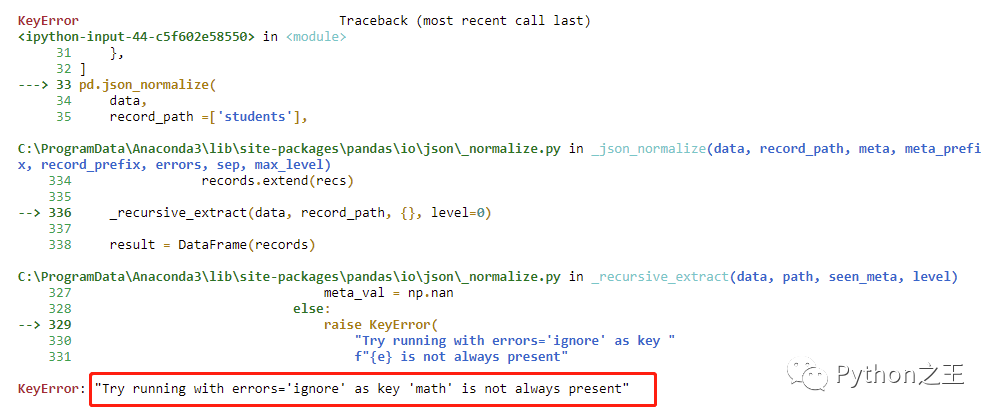
在class等于Year 2的Json对象中,teachers下的math键不存在,直接运行上述代码会报以下错误,提示math键并不总是存在,且给出了相应建议:Try running with errors='ignore'。
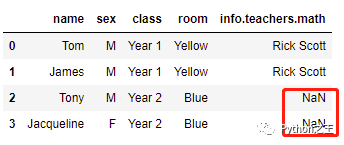
添加errors条件后,重新运行得出的结果如下图所示,没有math键的部分使用NaN进行了填补。
pd.json_normalize(
data,
record_path =['students'],
meta=['class', 'room', ['info', 'teachers', 'math']],
errors='ignore'
)
5. 使用sep参数为嵌套Json的Key设置分隔符
在2.a的案例中,可以注意到输出结果的具有多层key的数据列标题是采用.对多层key进行分隔的,可以为sep赋值以更改分隔符。
json_obj = {
'school': 'ABC primary school',
'location': 'London',
'ranking': 2,
'info': {
'president': 'John Kasich',
'contacts': {
'email': {
'admission': 'admission@abc.com',
'general': 'info@abc.com'
},
'tel': '123456789',
}
}
}
pd.json_normalize(json_obj, sep='->')
输出结果为:

6. 为嵌套列表数据和元数据添加前缀
在3例的输出结果中,各列名均无前缀,例如name这一列不知是元数据解析得到的数据,还是通过student嵌套列表的的出的数据,因此为record_prefix和meta_prefix参数分别赋值,即可为输出结果添加相应前缀。
json_obj = {
'school': 'ABC primary school',
'location': 'London',
'ranking': 2,
'info': {
'president': 'John Kasich',
'contacts': {
'email': {
'admission': 'admission@abc.com',
'general': 'info@abc.com'
},
'tel': '123456789',
}
},
'students': [
{'name': 'Tom'},
{'name': 'James'},
{'name': 'Jacqueline'}
],
}
pd.json_normalize(json_obj, record_path='students',
meta=['school', 'location', ['info', 'contacts', 'tel'], ['info', 'contacts', 'email', 'general']],
record_prefix='students->',
meta_prefix='meta->',
sep='->')
本例中,为嵌套列表数据添加students->前缀,为元数据添加meta->前缀,将嵌套key之间的分隔符修改为->,输出结果为:

7. 通过URL获取Json数据并进行解析
通过URL获取数据需要用到requests库,请自行安装相应库。
import requests
from pandas import json_normalize
# 通过天气API,获取深圳近7天的天气
url = 'https://tianqiapi.com/free/week'
# 传入url,并设定好相应的params
r = requests.get(url, params={"appid":"59257444", "appsecret":"uULlTGV9 ", 'city':'深圳'})
# 将获取到的值转换为json对象
result = r.json()
df = json_normalize(result, meta=['city', 'cityid', 'update_time'], record_path=['data'])
df
result的结果如下所示,其中data为一个嵌套列表:
{'cityid': '101280601',
'city': '深圳',
'update_time': '2021-08-09 06:39:49',
'data': [{'date': '2021-08-09',
'wea': '中雨转雷阵雨',
'wea_img': 'yu',
'tem_day': '32',
'tem_night': '26',
'win': '无持续风向',
'win_speed': '<3级'},
{'date': '2021-08-10',
'wea': '雷阵雨',
'wea_img': 'yu',
'tem_day': '32',
'tem_night': '27',
'win': '无持续风向',
'win_speed': '<3级'},
{'date': '2021-08-11',
'wea': '雷阵雨',
'wea_img': 'yu',
'tem_day': '31',
'tem_night': '27',
'win': '无持续风向',
'win_speed': '<3级'},
{'date': '2021-08-12',
'wea': '多云',
'wea_img': 'yun',
'tem_day': '33',
'tem_night': '27',
'win': '无持续风向',
'win_speed': '<3级'},
{'date': '2021-08-13',
'wea': '多云',
'wea_img': 'yun',
'tem_day': '33',
'tem_night': '27',
'win': '无持续风向',
'win_speed': '<3级'},
{'date': '2021-08-14',
'wea': '多云',
'wea_img': 'yun',
'tem_day': '32',
'tem_night': '27',
'win': '无持续风向',
'win_speed': '<3级'},
{'date': '2021-08-15',
'wea': '多云',
'wea_img': 'yun',
'tem_day': '32',
'tem_night': '27',
'win': '无持续风向',
'win_speed': '<3级'}]}
解析后的输出结果为:
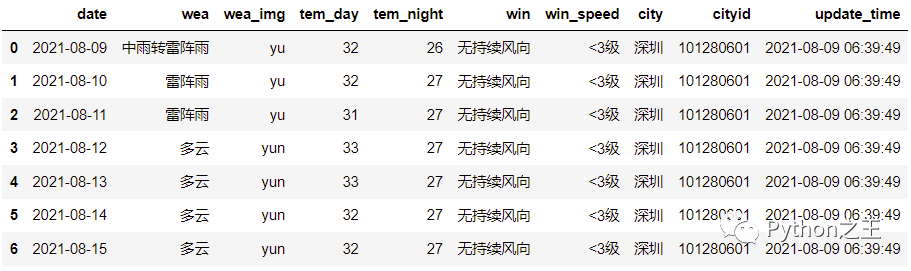
8. 探究:解析带有多个嵌套列表的Json
当一个Json对象或对象列表中有超过一个嵌套列表时,record_path无法将所有的嵌套列表包含进去,因为它只能接收一个key值。此时,我们需要先根据多个嵌套列表的key将Json解析成多个DataFrame,再将这些DataFrame根据实际关联条件拼接起来,并去除重复值。
json_obj = {
'school': 'ABC primary school',
'location': 'shenzhen',
'ranking': 2,
'info': {
'president': 'John Kasich',
'contacts': {
'email': {
'admission': 'admission@abc.com',
'general': 'info@abc.com'
},
'tel': '123456789',
}
},
'students': [
{'name': 'Tom'},
{'name': 'James'},
{'name': 'Jacqueline'}
],
# 添加university嵌套列表,加上students,该JSON对象中就有2个嵌套列表了
'university': [
{'university_name': 'HongKong university shenzhen'},
{'university_name': 'zhongshan university shenzhen'},
{'university_name': 'shenzhen university'}
],
}
# 尝试在record_path中写上两个嵌套列表的名字,即record_path = ['students', 'university],结果无济于事
# 于是决定分两次进行解析,分别将record_path设置成为university和students,最终将2个结果合并起来
df1 = pd.json_normalize(json_obj, record_path=['university'],
meta=['school', 'location', ['info', 'contacts', 'tel'],
['info', 'contacts', 'email', 'general']],
record_prefix='university->',
meta_prefix='meta->',
sep='->')
df2 = pd.json_normalize(json_obj, record_path=['students'],
meta=['school', 'location', ['info', 'contacts', 'tel'],
['info', 'contacts', 'email', 'general']],
record_prefix='students->',
meta_prefix='meta->',
sep='->')
# 将两个结果根据index关联起来并去除重复列
df1.merge(df2, how='left', left_index=True, right_index=True, suffixes=['->', '->']).T.drop_duplicates().T
输出结果为:

途中红框标出来的部分为Json对象中所对应的两个嵌套列表。
总结
json_normalize()方法异常强大,几乎涵盖了所有解析JSON的场景,涉及到一些更复杂场景时,可以给予已有的功能进行发散整合,例如8. 探究中遇到的问题一样。
拥有了这个强大的Json解析库,以后再也不怕遇到复杂的Json数据了!


Python“宝藏级”公众号【Python之王】专注于Python领域,会爬虫,数分,C++,tensorflow和Pytorch等等。
近 2年共原创 100+ 篇技术文章。创作的精品文章系列有:
日常收集整理了一批不错的 Python 学习资料,有需要的小伙可以自行免费领取。
获取方式如下:公众号回复资料。领取Python等系列笔记,项目,书籍,直接套上模板就可以用了。资料包含算法、python、算法小抄、力扣刷题手册和 C++ 等学习资料!