
【手把手实战】花半天时间,轻松打造企业级前端CI/CD工作流

CI/CD 是 Continuous Intergration/Continuous Deploy 的简称,翻译过来就是持续集成/持续部署。CD 也会被解释为持续交付(Continuous Delivery),但是对于软件工程师而言,最直接接触的应该是持续部署。
我刚开始工作时,就有接触过CI的概念,那个时候主要是团队 QA(质量保证)使用 hudson 对工程进行质量扫描,跑一些基础的自动化测试。当时印象最深的一幕就是 QA 对我说:”你的代码静态告警了,赶紧改一下...“。
现在一想,我不禁感到诧异,”咦?我们当时没有用 ESLint 吗?记不清楚了...“于是我翻了下 ESLint 的更新记录,发现那时候 ESLint 的大版本号才刚到3,VSCode 的 ESLint 插件也还是比较早期的版本,可能还没普及开吧。
后面我也慢慢地听到了 Jenkins, Travis CI 这样一些名词,但是由于太菜,我一个都不会用。

而且我发现,我对 CI/CD 并没有什么兴趣,为什么呢?因为我还没有使用它的动机。
构建/部署那些事
构建/部署说的简单点,就是先利用 webpack 或者 gulp 这类的工具把工程打包,然后把打包得到的文件放在服务器上某个托管静态资源的 Web 容器里,像 Java 就可以放在 Tomcat,不过现在流行用 Nginx 托管静态资源。有了 Web 容器,前端打包的那些文件(比如index.html, main.js等等)就可以被访问到了,这个相信大家都懂。
16年~18年时,我还不负责打包部署这些事(另一方面也是因为前端根本没权限碰服务器啊,emmm...),所以我压根没关注打包部署这些事情。
18年到19年时,我开始负责打包部署了。当时完全没这方面经验,Linux 命令都是靠着一边百度一边敲。不过我清楚地记得,之前在测试组那间办公室看他们用的是xshell和xftp,把这俩工具搞来用后,我觉得部署真是简单,我只要跑个脚本,安静地等 webpack 和 gulp 的工作流结束后,把文件通过 xftp 传到服务器就行,只要注意不要操作出错就行了(显然,人为操作就容易出错,这也是个隐患)。由于构建部署的频率不高,项目数量也不是很多,这一年我基本应付得过来。
直到去年,我手底下有差不多5个项目,接近10个前端工程。在这种日常部署节奏下,我觉得 xshell+xftp 也救不了我,虽然这些项目不是天天都发版上线,但是测试环境还是经常发的,每天光部署这事我就够烦躁,写代码经常被打断,而且也非常浪费时间。

我想着要寻求些改变了,但我还是没考虑 CI/CD 这事,因为我觉得我好像还是不太懂 CI/CD。于是我考虑先用 shell 脚本来做构建/部署的事情,所以后来就有了这么两篇探索性的文章:
自动化部署的一小步,前端搬砖的一大步[1] 前端自动化部署的深度实践[2]
靠着这一波脚本的探索,我基本上也是过渡到半自动化的阶段了,这种焦虑的状况基本上得到了一些缓解。但是,我发现我的电脑还是扛不住,风扇急速旋转的声音能让我自闭。。。毕竟一边跑本地开发环境,一边还可能同时跑1~2个工程的构建/部署脚本,再加上电脑运行的其他软件,这发热量你懂的!
所以,构建/部署这活不应该由我的电脑来承担,它太累了。

而且,我也不想手动触发部署脚本了,太累了,是时候让代码学会自己部署了。也就是这个时候,我对 CI/CD 就有了诉求。
由于我们的代码是托管在自建的 gitlab 服务器上,所以 CI/CD 这块我直接选择了用 gitlab 自带的 CI/CD 能力。工作之余,我差不多花了两天时间去熟悉gitlab CI/CD的文档[3]。
然后我按照文档先把环境搭建好,接着一遍遍地调试.gitlab-ci.yml配置文件,我记得第一次成功跑完一个 Pipeline 前,我一共失败了大概11次,这个过程挺折磨人,有时候你就是不知道到底哪里配错了。
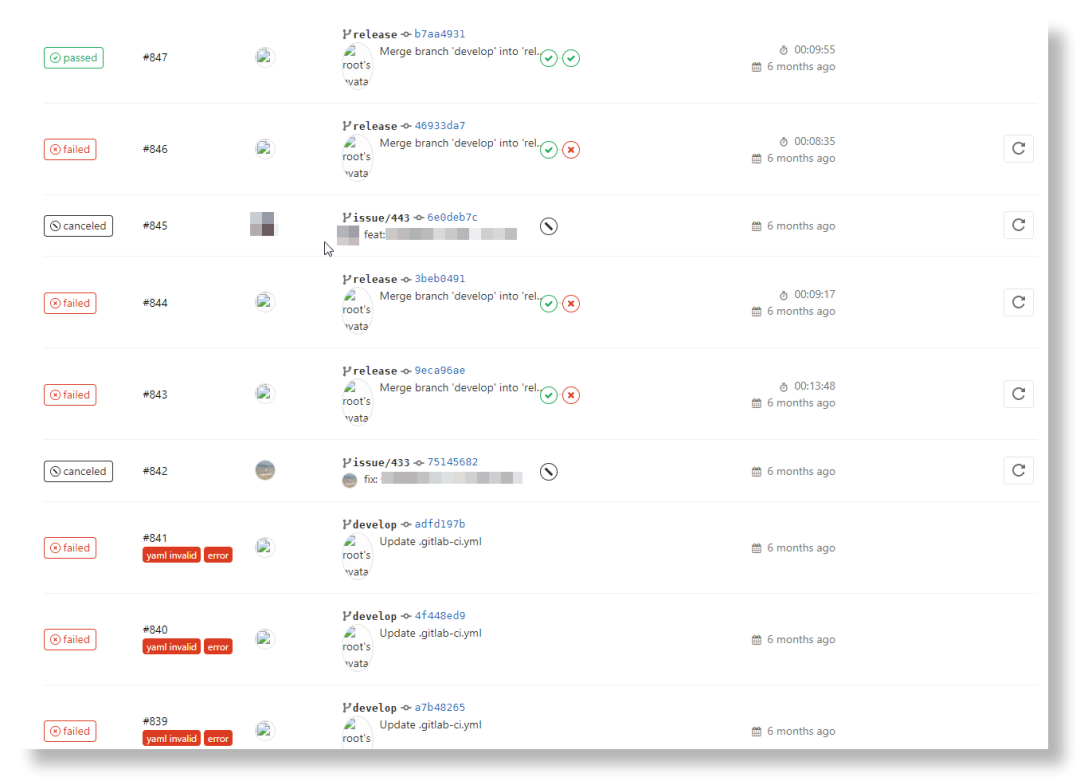
不过调通这个流程后,你就会觉得这整个试错的过程都是值得的。Nice!
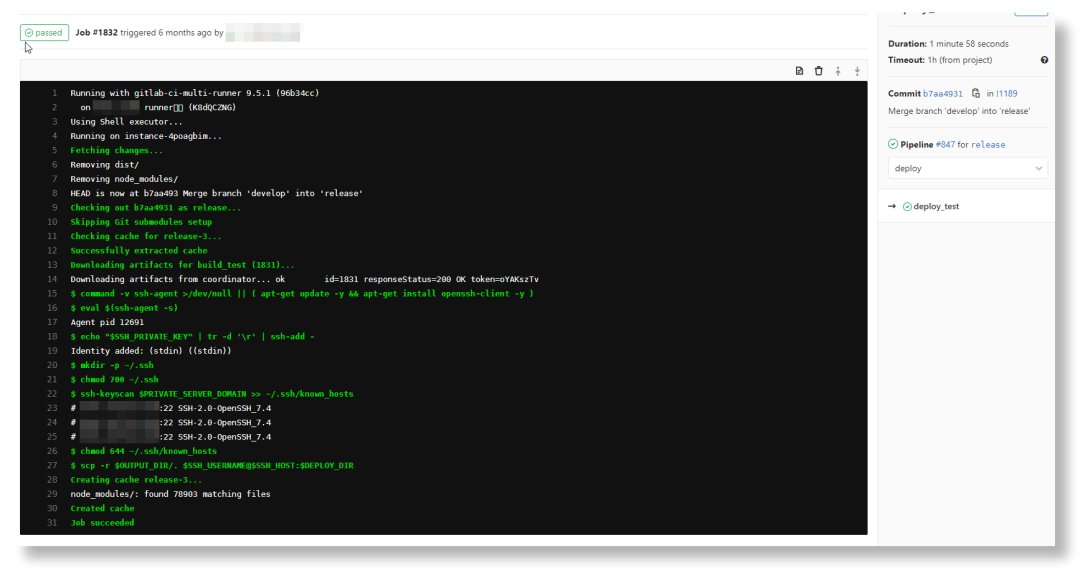
CI/CD到底干了啥?
其实我前面也提到了,一个版本发布的过程,主要就是分为以下几个步骤:
代码合并:测试环境或生产环境都有独立的分支,等所有待发版的代码都合并到对应分支后,就可以考虑发版了。 打包:或者叫构建。以生产环境部署为例,我们切到生产环境分支并 pull 最新代码后,就可以开始打包步骤了。这一步主要是通过一些 bundler 完成的,比如 webpack。而打包命令嘛,一般都是定义在 package.json的scripts中了,我这儿定义的命令是build:prod,所以只要运行npm run build:prod就行了。部署:把打包得到的文件放在 web 容器中,而 web 容器通常在 Linux 服务器上,这涉及到远程传输文件,这个时候我们一般要借助 shell 脚本或者 xftp。
而 CI/CD 做的事情就是:用自动化技术接管流程。
监控Mutation
我的诉求是:当代码合并到某个分支后,gitlab能自动帮我执行完打包和部署这两个步骤。
所以,首先就必须有代码变动的监控能力。这个确实有,如果你有关注过git hook[4],就知道这是可以实现的。
而且,绝大部分代码托管平台都提供了 webhooks,能监控不少事件,比如 push 和 merge。
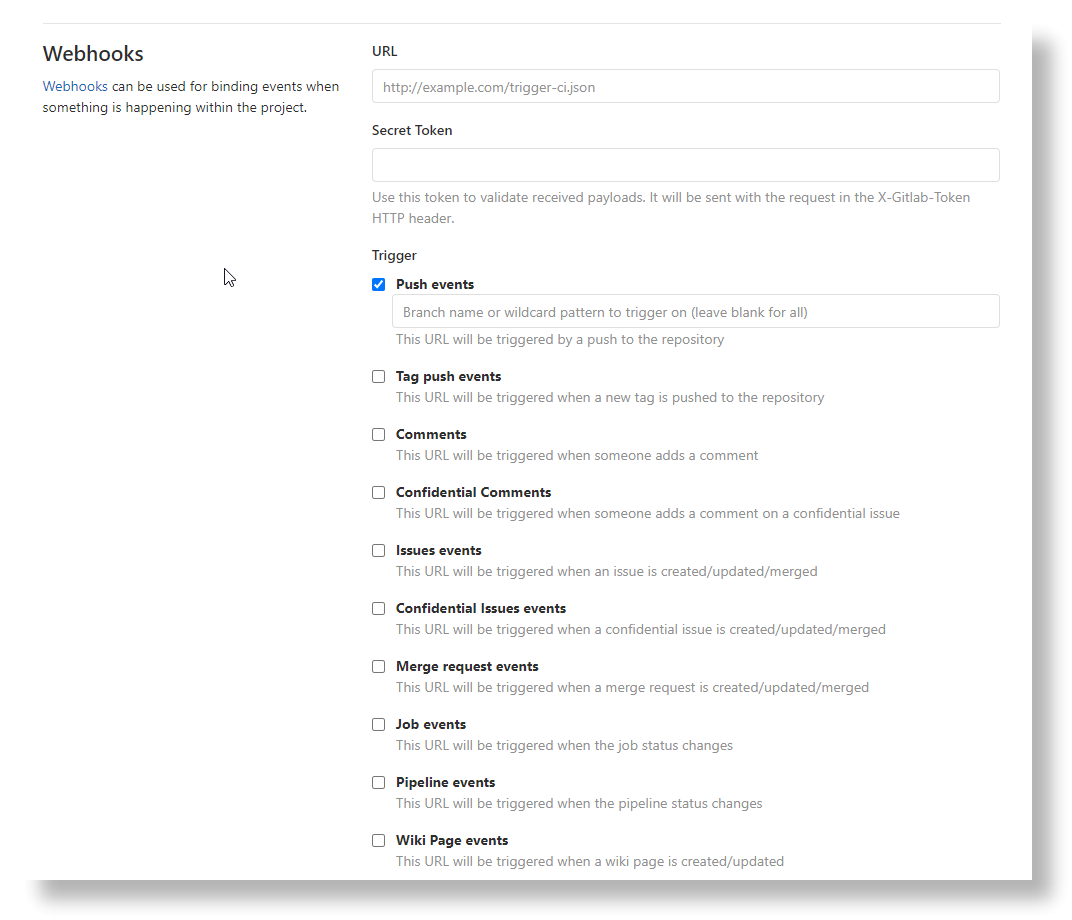
这也就是说,即便不使用代码托管平台提供的 CI/CD 能力,开发者也有能力实现自己的 CI/CD 机制。
ps:当然,除了 CI/CD,做短信/邮件通知也是可行的,只要你敢去尝试,基于平台开放的能力,我们能做很多事情。自研 CI/CD 的事情我们就不去搞了,人家造的轮子已经6翻了,直接拿来用。
回归主题,只要我监控到代码变动了,服务器端自动执行构建/部署脚本即可。
Gitlab CI/CD是怎么工作的
软件服务于生活,也源于生活。Gitlab CI/CD 设计了很多概念,其中我觉得最有意思的是:Pipeline 和 Runner。
Pipeline
Pipeline是CI/CD的最上层组件,它翻译过来是管道,其实你可以将之理解为流水线,每一个符合.gitlab-ci.yml触发规则的 CI/CD 任务都会产生一个 Pipeline。这个概念就有点像工厂中的车间流水线了,我们知道车间中有很多条流水线,不同的流水线可能会处理同一类型的生产任务,也可能处理不同类型的生产任务。当一条流水线空闲的时候,就有可能会被用来安排执行其他的生产任务。而 Gitlab 的 Pipeline 虽然没有空闲的概念,一个 Pipeline 执行结束后也不会被复用,但是会将资源让出来给其他的 Pipeline,所以和车间流水线也有异曲同工之妙。

Runner
有了流水线,还必须有辛勤的工人进行生产作业,Runner在 Gitlab Pipeline 中就扮演着工人角色,根据我们下达的指令进行作业。
Runner的类型
在 Gitlab 中,Runner 有很多种,分为Shared Runner, Group Runner, Specific Runner。
Shared Runner 可以理解为机动人员,他可能会在工厂的各个流水线机动作业,随时支援!在整个 Gitlab 应用中,Shared Runner 可以服务于各个 Project。

Group Runner 就比较好理解了,他只在这个组上班,别的组他是不会去的。在 Gitlab 中,我们是可以建立不同的 Group 的,比如前端一个 Group,后端一个 Group,甚至前端里面还可以分 N 个 Group。所以,Group Runner 只服务于指定的 Group。

Specific Runner 就更牛逼了,它只服务于指定的项目,也就是 Project 级别,别的项目咱都不去。

注册Runner
工人是要持证上岗的,同样地,Runner 有一个注册的过程,就相当于在工厂中入职登记的意思。具体见Registering runners[5]。只有合法注册的 Runner,才有资格执行 Pipeline。不过,Gitlab 好像没给 Runner 发工资啊!

.gitlab-ci.yml配置
流水线和工人都安排好之后,就必须制定车间生产规章制度了。一条流水线到底怎么干活,总要有个规矩吧,你说呢?
没错,.gitlab-ci.yml文件就是来制定规则的!其实我要求的 CI/CD 流程并不复杂,只要帮我把构建和部署两步搞定就行了。下面以一个简化的生产环境构建部署流程为例说明:
workflow:
rules:
- if: '$CI_COMMIT_REF_NAME == "master"'
stages:
- build
- deploy
build_prod:
stage: build
cache:
key: build_prod
paths:
- node_modules/
script:
- yarn install
- yarn build:prod
artifacts:
paths:
- dist
deploy_prod:
stage: deploy
script:
- scp -r $CI_PROJECT_DIR username@host:/usr/share/nginx/html
首先,我希望只在 master 分支进行构建/部署作业,这个可以通过workflow.rules下的if条件约束完成。
然后,我希望把整个过程分为两个阶段执行,第一个阶段是build,用于执行构建任务;第二个阶段是deploy,用于执行部署任务。这可以通过stages来完成定义。
接着,我定义了两个job,第一个job是build_prod,属于build阶段;第二个job是deploy_prod,属于deploy阶段。
在buiild_prod这个job中,主要是运行了yarn install和yarn build:prod两个脚本,打包生成的文件资产会根据artifacts的配置保存下来,供后面的job使用。
在deploy_prod这个job中,主要是通过scp命令向 linux 服务器上的 nginx 目录下传输文件。
这个简单的 Pipeline 配置示例其实应用的是 Basic Pipeline Architecture,只不过示例中每个 stage 只定义了一个 job。
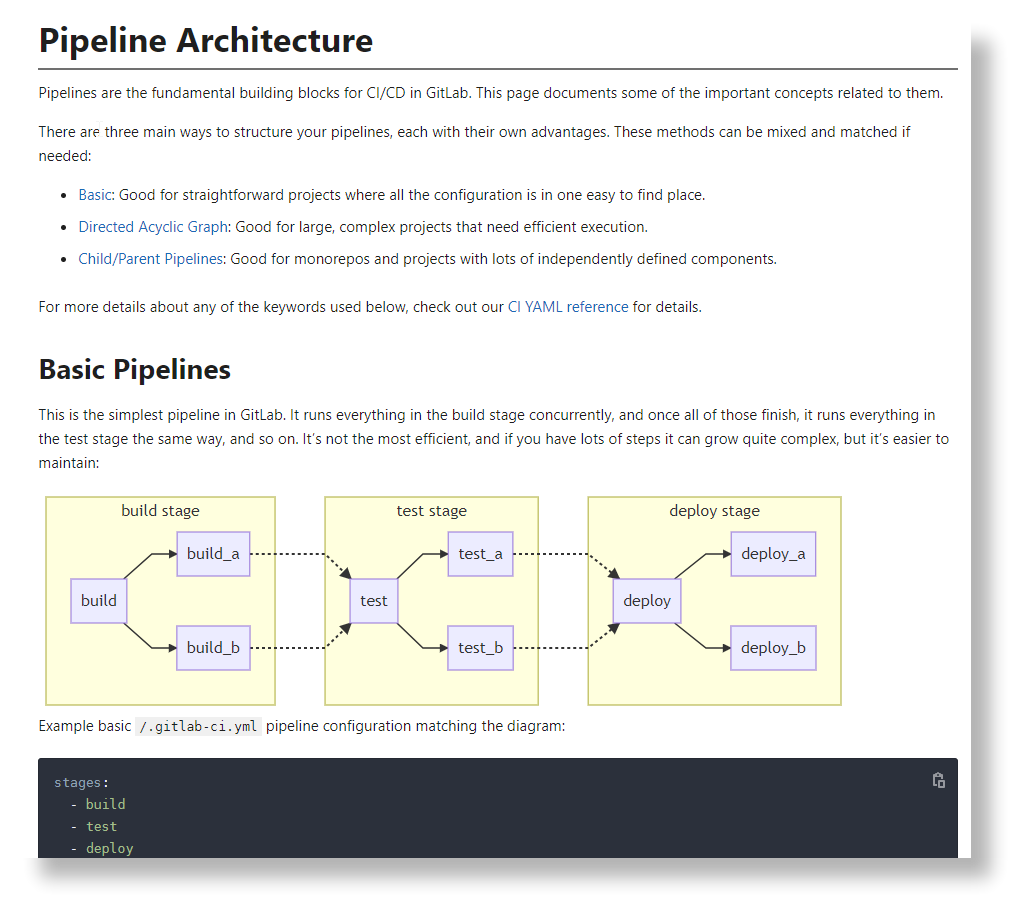
Gitlab CI/CD Variables
Gitlab 通过 Variables 为 CI/CD 提供了更多配置化的能力,方便我们快速取得一些关键信息,用来做流程决策。上述示例中的$CI_COMMIT_REF_NAME和$CI_PROJECT_DIR就是 Gitlab 的预定义变量。
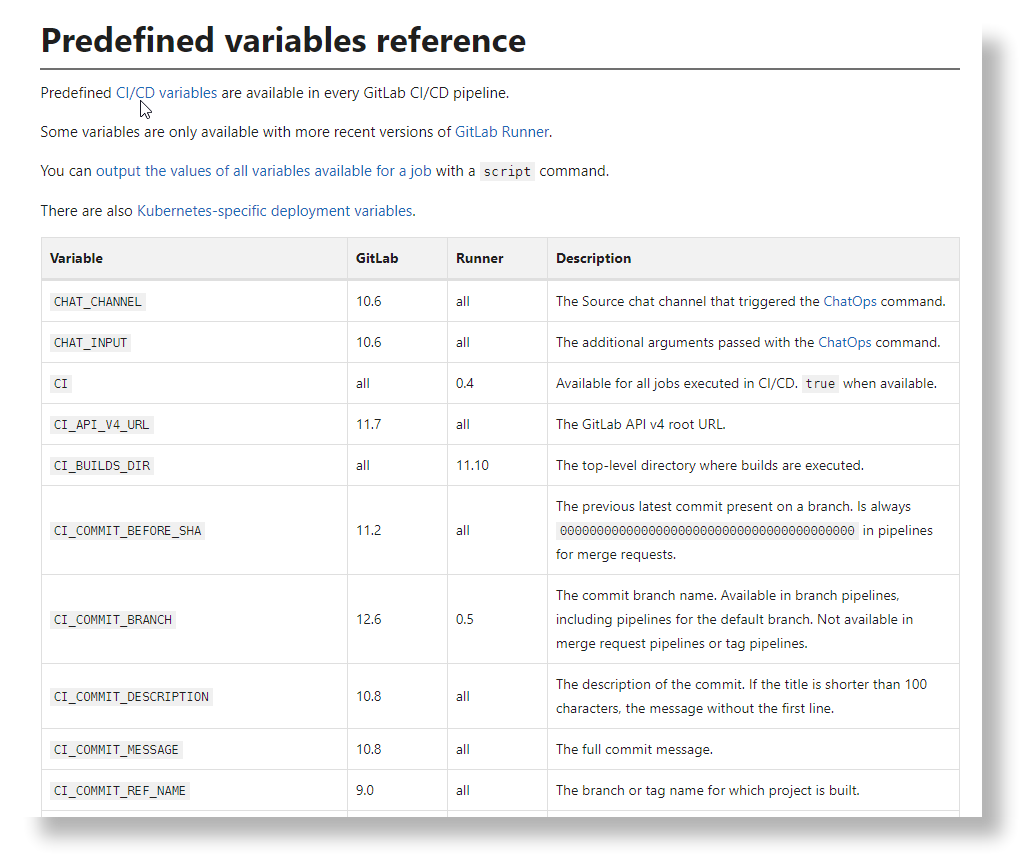
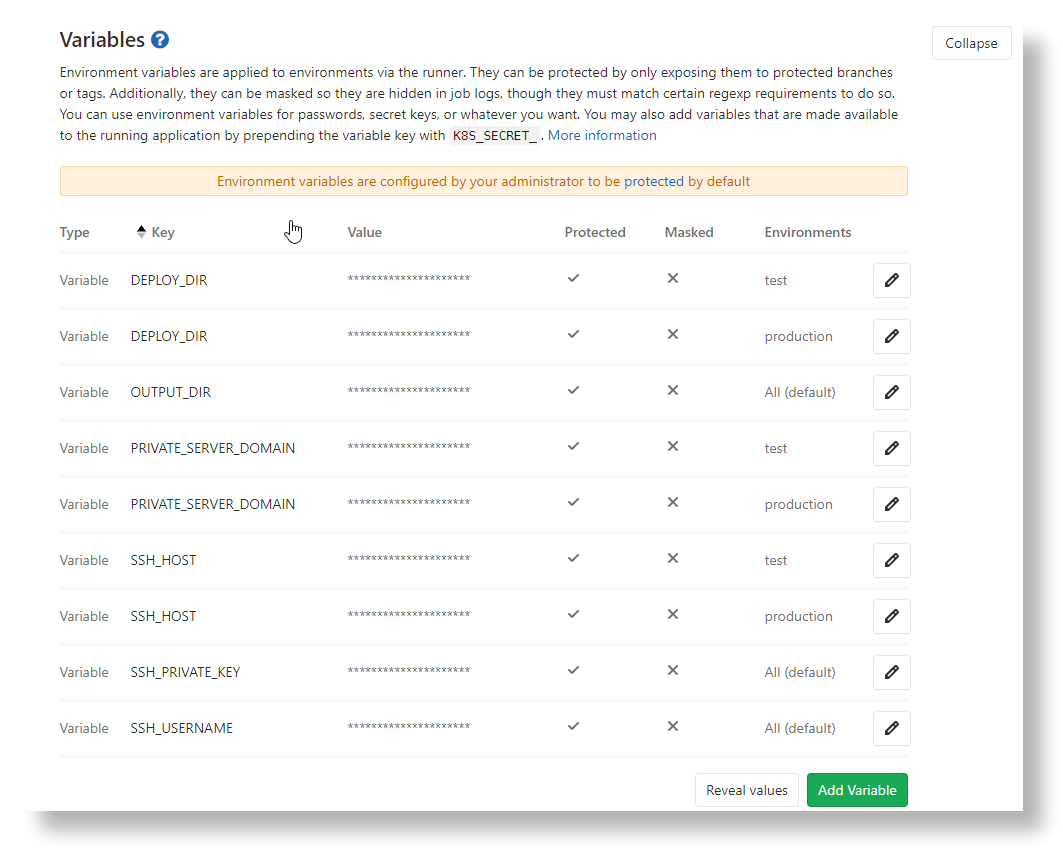
除了预定义变量,我们也可以自行定义一些环境变量,比如服务器 ip,用户名等等,这样就免去了在配置文件中明文列出私密信息的风险;另一方面也方便后期快速调整配置,避免直接修改.gitlab-ci.yml。
授信问题
在不同主机间通过scp传输文件需要建立信任关系,在 CI/CD 中最好选择免密方式,其基本原理就是把 ssh公钥 交给对方。而这一点我在自动化部署的一小步,前端搬砖的一大步[1]这篇文章中也提到了,这里就不再赘述。
Runner独立部署
由于我是将 Runner 直接部署到了 Gitlab 代码服务器上,而我司配的这台代码服务器的配置本身就不高,用来跑高 CPU 占用的构建部署 Pipeline 还是有点吃力的,有时候 Pipeline 跑起来甚至直接把 Gitlab 的 Web 服务搞崩了。
队友问我:”怎么 Gitlab 白屏打不开了?“

没过多久,领导那边给我发了一台 Linux 服务器,专门给前端搞日常工作用的。bingo,我就顺手把 Runner 独立部署到新机器上了,这样就不会影响队友了,而且每次发版时间直接从 8min 缩短到 2min 以内,简直 Nice!

CI/CD带来的收益
直观来看,我的重复劳动被去除了大部分,多出来的这部分时间我可以用来干更多有意义的事情,或者摸鱼它不香吗?而且,每天不用手动发版,心情也是倍儿棒!
此外,由于 CI/CD 采用自动化作业方式,只要脚本写对了,几乎不会出错,出生产事故的几率也就大大降低了。
小结
本文从笔者的一些亲身经历出发,回忆了笔者在构建/部署过程中遇到的痛点,并围绕一个最基础的Gitlab CI/CD案例,讲述了笔者使用 CI/CD 来解决这些痛点的过程。虽然本文的主角是Gitlab CI/CD,但它和其他代码托管平台的CI/CD在思路上是类似的,掌握了一个,触类旁通也就不难。并且,利用 Pipeline 这类工具,我们还可以做更多事情,比如持续集成+自动化测试。这就考验大家的想象力了,剩下的就交给聪明的读者啦!
参考
自动化部署的一小步,前端搬砖的一大步: https://juejin.cn/post/6844904049582538760#heading-0
[2]前端自动化部署的深度实践: https://juejin.cn/post/6844904056498946055
[3]gitlab CI/CD的文档: https://docs.gitlab.com/ee/ci/quick_start/
[4]git hook: https://git-scm.com/book/zh/v2/%E8%87%AA%E5%AE%9A%E4%B9%89-Git-Git-%E9%92%A9%E5%AD%90
[5]Registering runners: https://docs.gitlab.com/runner/register/
END


“分享、点赞、在看” 支持一波 