
哈工大刘挺:自然语言处理中的可解释性问题!
“知其然,亦知其所以然”是现代计算机科学家针对神经网络可解释性问题追逐努力的方向和梦想。针对自然语言处理中的可解释性问题,哈尔滨工业大学刘挺教授在2022北京智源大会报告中做了详尽的解读。首先介绍了自然语言处理中的可解释性概念,分类及研究可解释性的必要性,重点介绍了可解释自然语言处理中的三种方法,包括白盒透明模型的设计、黑盒事后解释方法以及灰盒融合可解释要素方法。最后,刘挺教授提出了可解释性的白盒模型设计以及可解释性评估等未来发展的挑战和研究方向。(注:本文由第三方整理,未经本人审阅)

刘挺,哈尔滨工业大学教授,哈工大计算学部主任兼计算机学院院长、自然语言处理研究所所长





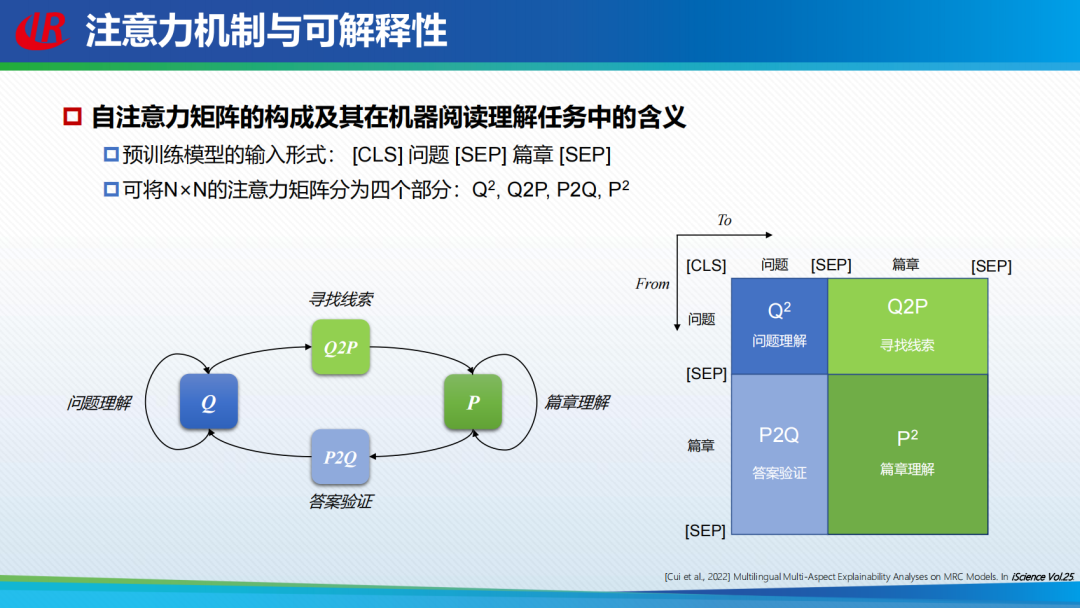
基于注意力机制为阅读理解任务提供可解释性也属于「事后解释方法」。这里面主要探讨注意力机制是否能够解释预训练模型的运行机制。研究者采用了一个包含四部分的注意力矩阵,Q2 代表问题到问题;P2 代表篇章理解;Q2P是从问题到篇章;寻找答案的线索;P2Q是对答案进行验证。研究者分别对这几个部分进行注意力机制的分析。
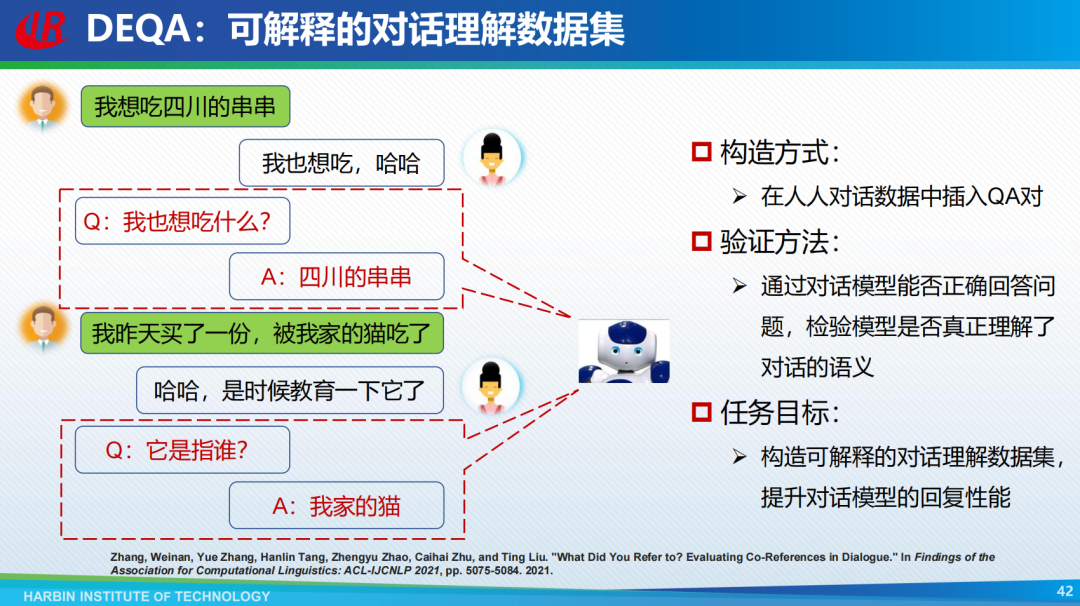
针对可解释性评价的挑战,刘挺教授团队也提出了两个针对可解释性评价的数据集,分别是可解释性阅读理解数据集ExpMRC和可解释的因果推理数据集。
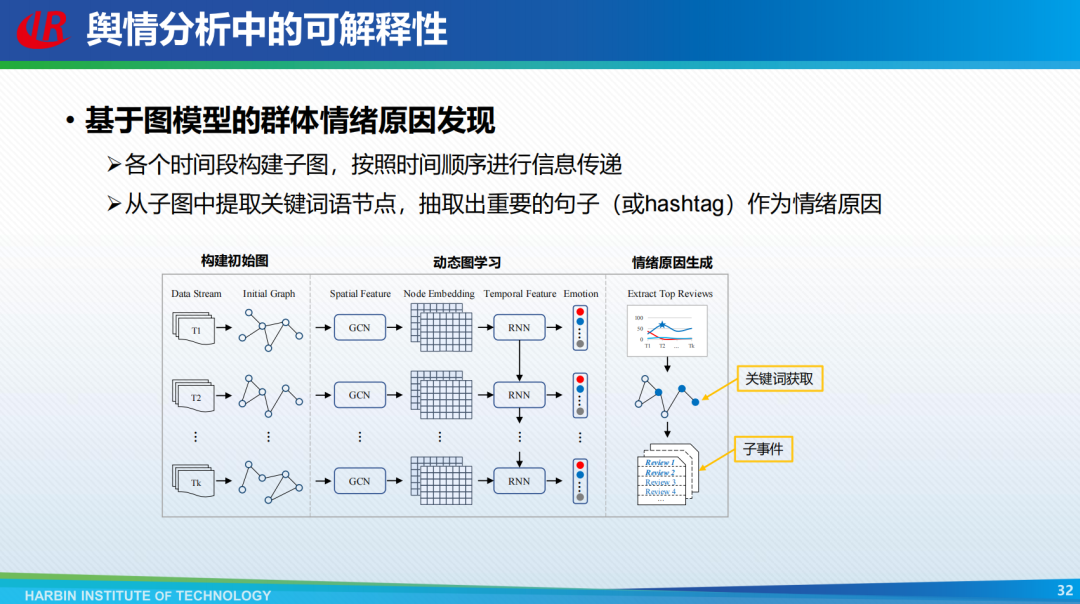
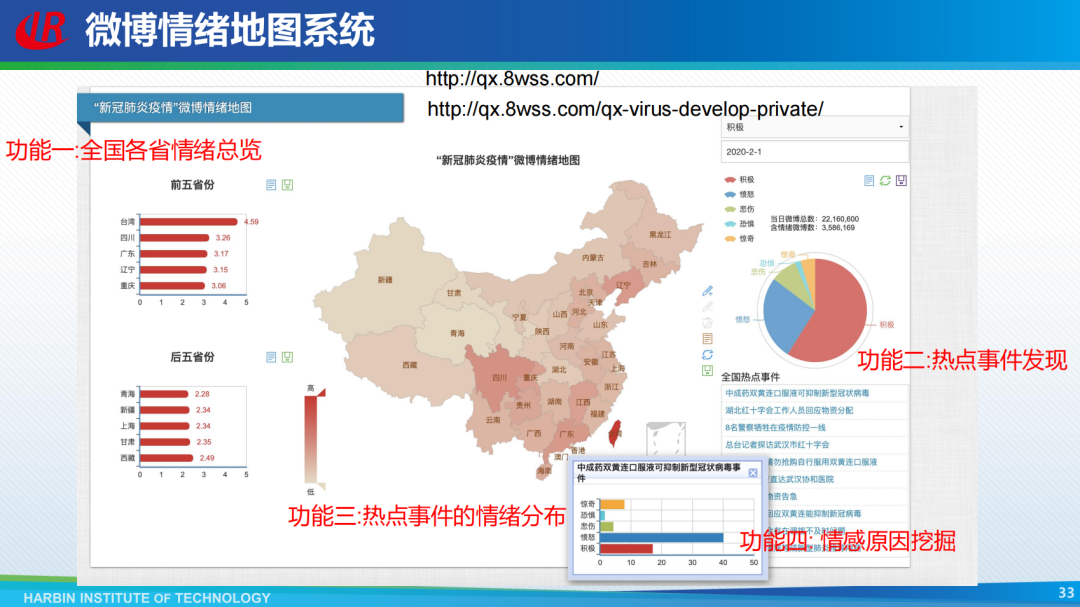
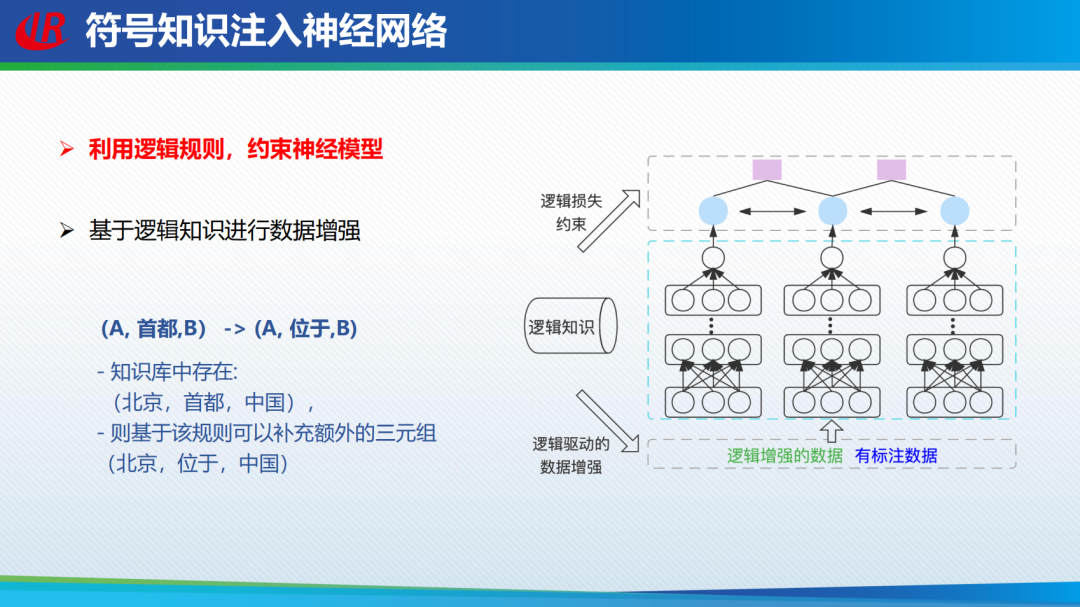
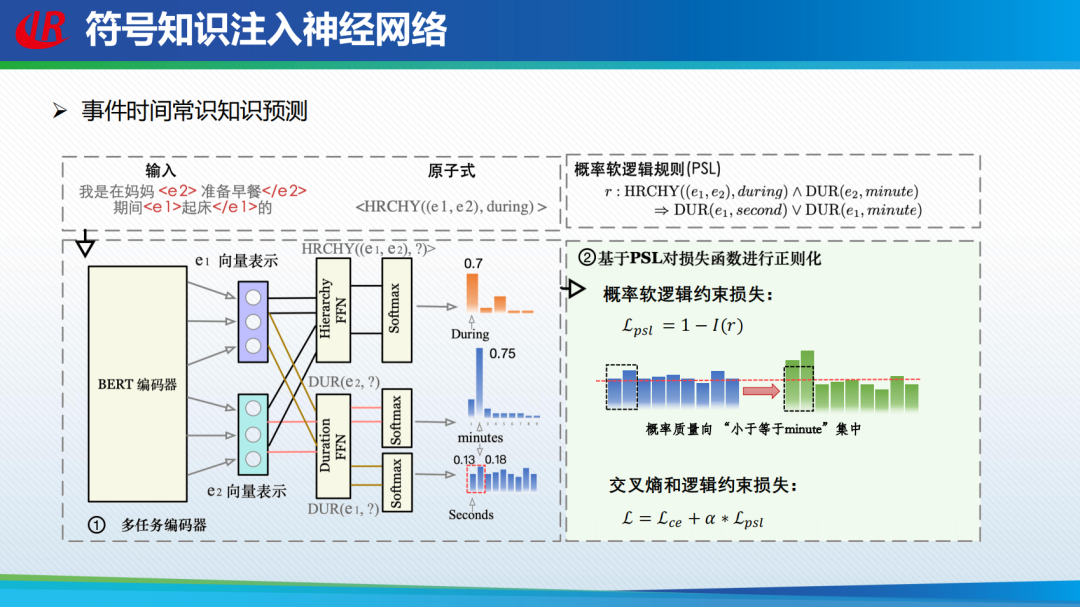
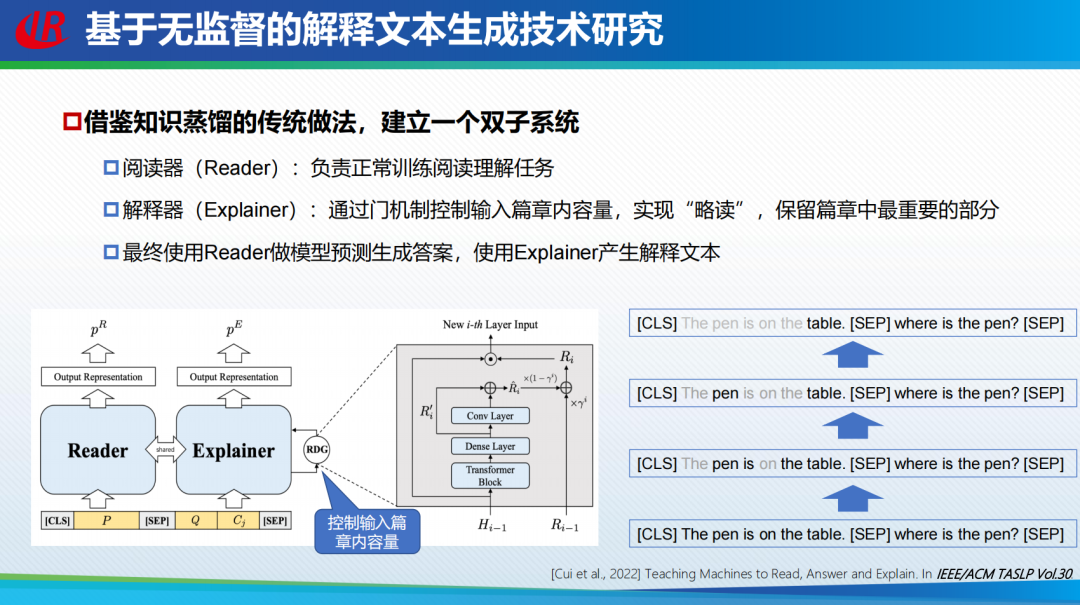
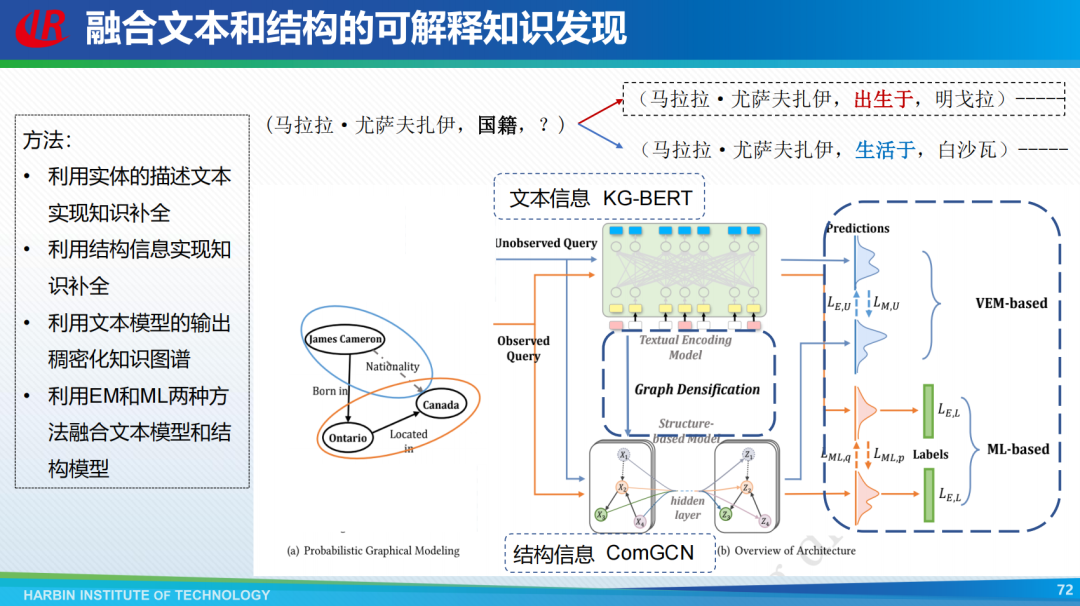
灰盒融合可解释要素方法
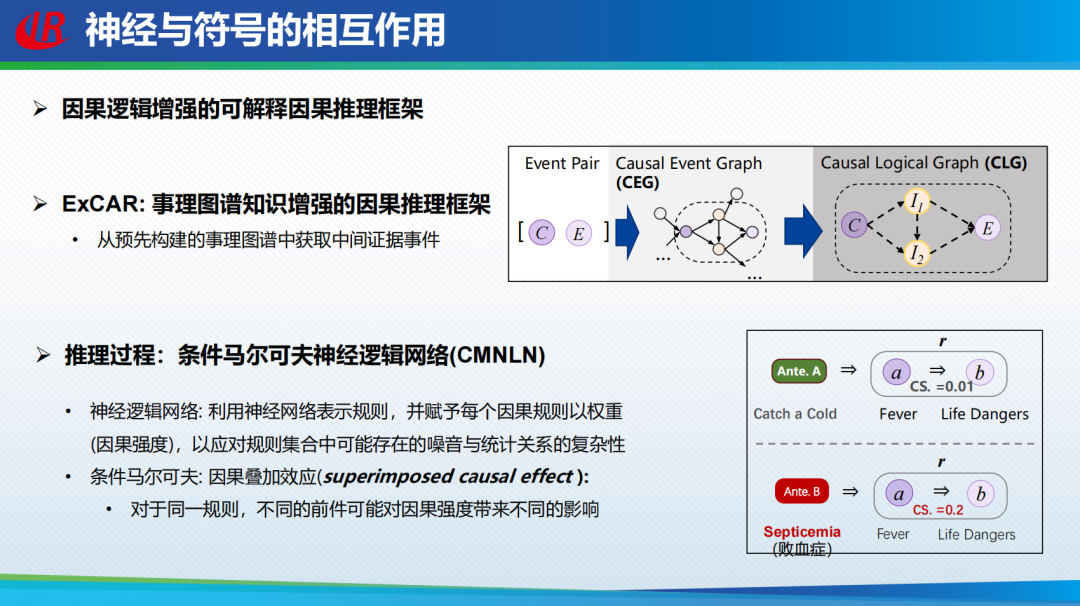
总结和展望
整理不易,点赞三连↓
评论