
Uber大型实时数据智能平台建设
为什么是 Gairos?
Gairos 概述
Uber 用例
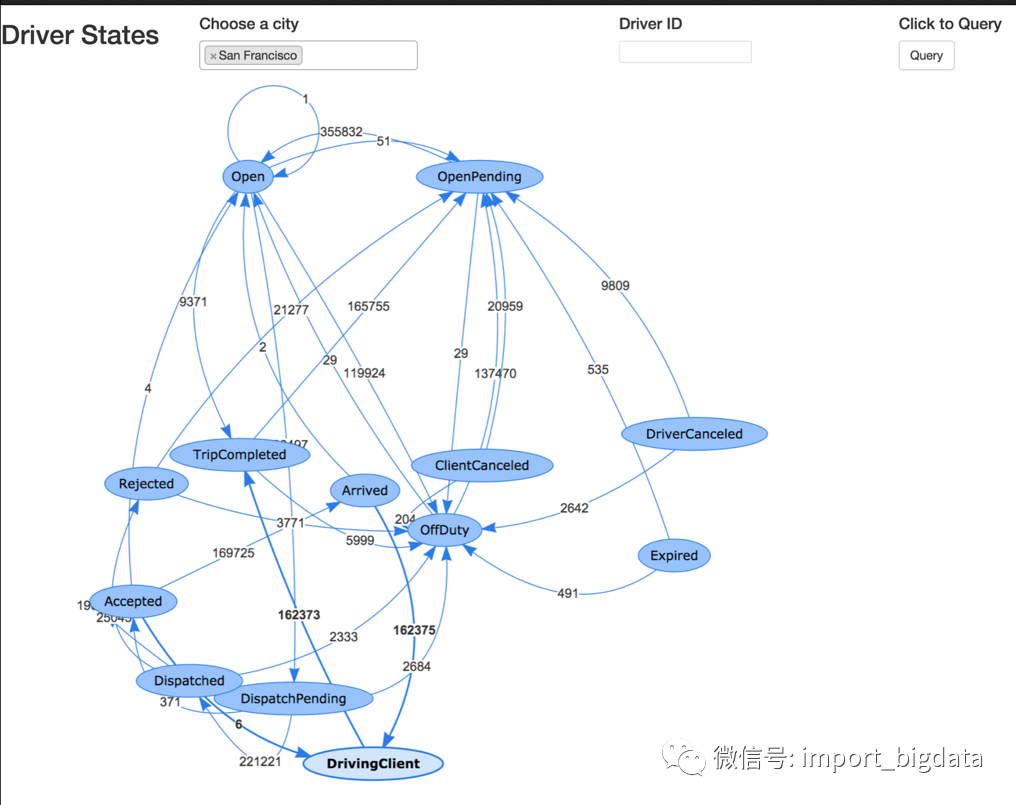
司机的状态转换
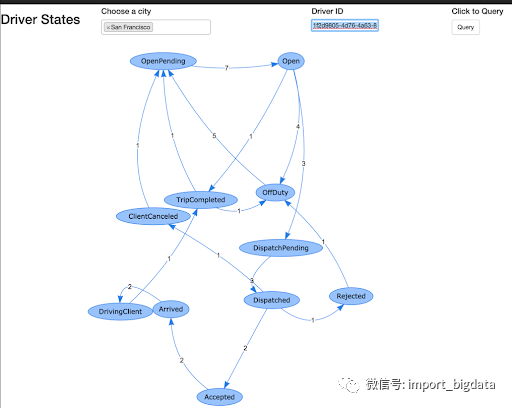
单个司机的状态转换
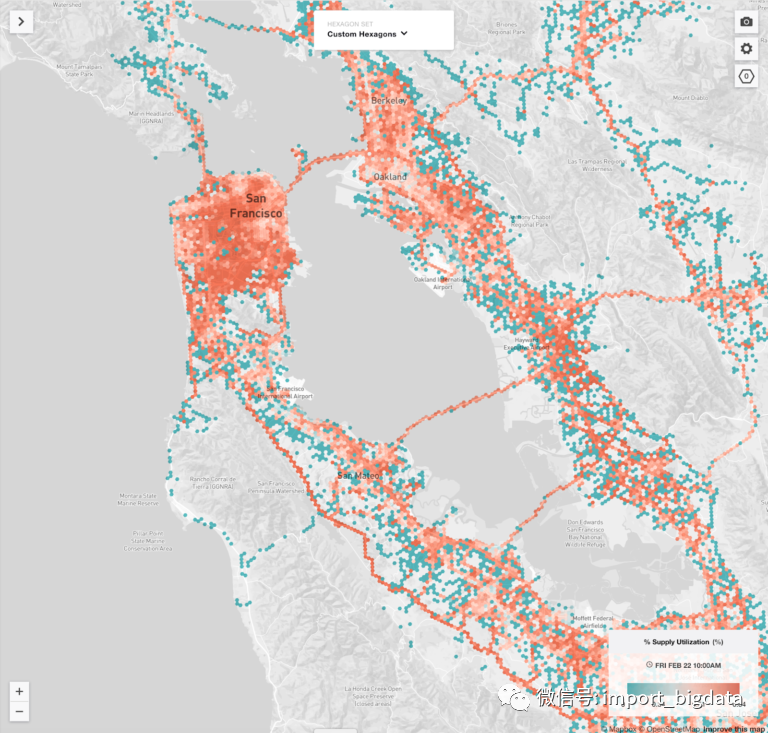
按地理位置划分的司机使用情况
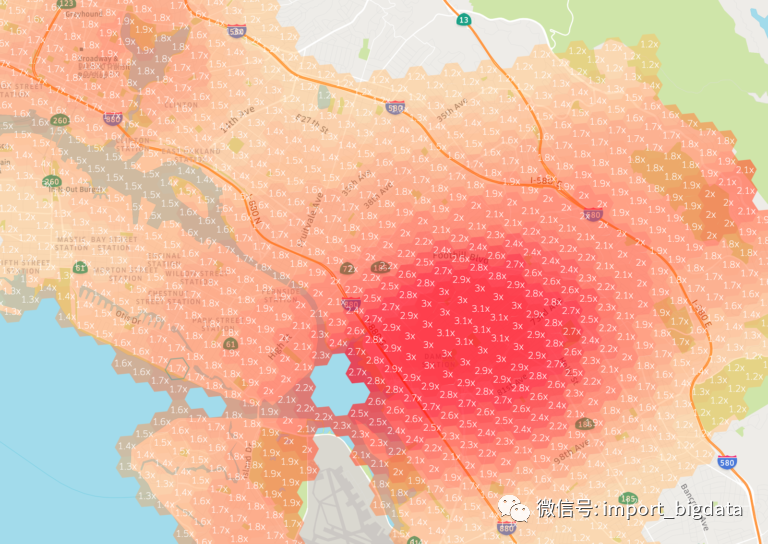
可扩展性 / 可靠性方面的挑战
多种用例共享同一个集群将导致集群的不稳定性。某个用例中的某些显著变化可能会影响该集群中其他所有用例。举例来说,如果一个用例的输入数据量翻倍,就会影响到其它用例的数据可用性。
摄取管线的滞后性是一个对所有实时流水线的普遍挑战。SLA(service level agreement,服务水平协议)通常是非常紧凑的,从几秒钟到几分钟不等。若管道中的任何一个组件变慢,就会造成延迟和 SLA 错误。
查询性能因某些客户端的流量峰值而降低。因为是多租户系统,突如其来的流量高峰可能会影响同一个集群中运行的某些查询。
有些数据源已经不再使用。在将用例加载 Gairos 之后,就无法自动地检查这些用例的使用情况了。不使用数据时,最好为其他用例腾出资源。
有些繁琐的查询会导致整个 Elasticsearch 集群变慢。
Elasticsearch 集群主节点宕机。这可能有多种原因:网络不稳定,元数据太大无法管理,等等。
有些节点有很高的 CPU 负载。这类节点有热点问题,换句话说,它们处理的分片或读写流量超出了合理的资源处理能力(CPU / 内存 / 网络)。
有些节点会崩溃。可能是由于磁盘故障或其他硬件故障。
一些分片丢失。当一次处理多个节点时,分片仅对这些节点可用。在分片中我们可能会丢失数据。
待命工程师经常被派去维修这些管道和系统,费用很高。
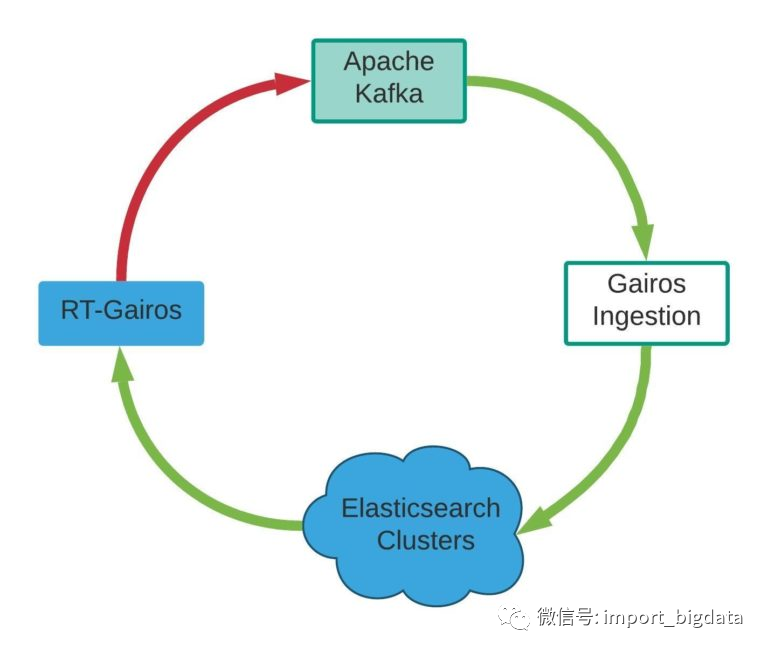
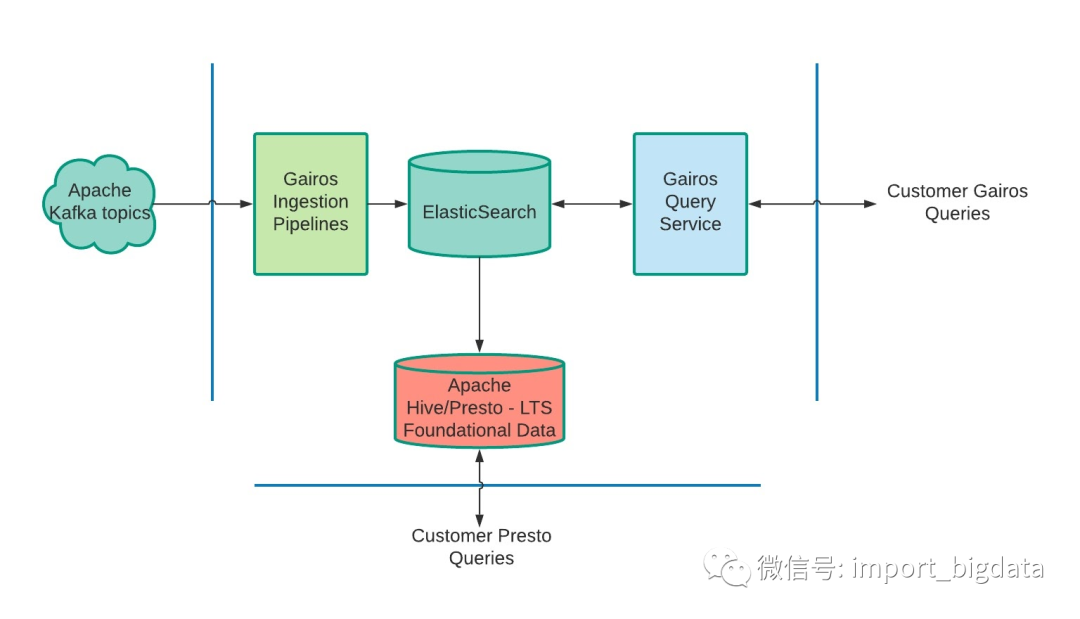
客户端:Gairos 的客户端可以是一项服务、一个仪表盘、一个数据分析师等。
Apache Kafka:我们使用 Apache Kafka 作为消息队列系统来处理服务中的事件、RT-Gairos 查询以及 Gairos 平台的指标和事件。
Gairos-Ingestion:Gairos-Ingestion 组件接收来自不同数据源的数据并向 Gairos 发布事件。
Elasticsearch 集群:这些集群从 Gairos-Ingestion 管道中存储输出数据。
RT-Gairos(Real-time-Gairos):RT-Gairos 是 Gairos 查询服务。它作为所有 Elasticsearch 集群的网关。
查询分析器:Gairos 查询分析器分析从 RT-Gairos 收集的查询,并为我们的优化引擎提供一些见解。
优化引擎:Gairos 优化引擎根据查询结果和系统统计数据优化 Gairos 的摄取管道、 Elasticsearch 集群 / 索引设置以及 RT-Gairos。举例来说,一个摄取管道需要使用多少容器,才能达到 SLA 99% 的要求?你想用多少分片来处理写 / 读流量?
客户端
Apache Kafka
Gairos-Ingestion(加工层)
Elasticsearch(Gairos 存储层)
RT-Gairos(查询层)
查询分析器
优化引擎
索引基准服务

Elasticsearch Production Clusters:Elasticsearch 生产集群包含用于负载测试的将复制到暂存的生产数据。生产索引可用作基准测试基准。
Elasticsearch Staging Clusters:这些集群被用来存储测试数据,也就是随机生成的数据,或者用来做实验的生产数据。
Benchmarking Service:基准测试服务接受索引的不同设置,并针对不同设置的索引进行基准测试。测试完成后,测试结果可供其他服务使用。
Load Test Tool:给定大量的读 / 写请求,这个工具可以模拟不同数量的读 / 写 QPS(每秒查询)并记录 KPI。读取将从生产中的 RT-Gairos 收集查询。写入将从生产中使用的相关 Apache Kafka 主题或直接发布主题进行模拟。
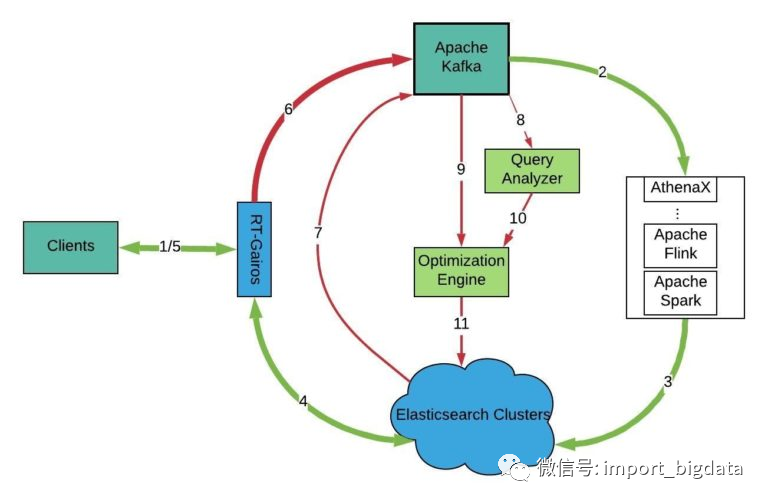
Gairos 客户端将请求发送到 RT-Gairos 以获取数据。
Gairos-ingestion 摄取来自 Apache Kafka 主题的数据并将其发布到 Elasticsearch 集群。
Gairos 索引数据,并为查询做好准备。
RT-Gairos 将查询转换为 Elasticsearch 查询,并从 Elasticsearch 集群中获取数据。
RT-Gairos 将数据发送回客户端。
RT-Gairos 向 Apache Kafka 主题发送查询信息。
Sample Elasticsearch 集群数据定期 向 Apache Kafka 主题发送信息。
Query Analyzer 从查询 Apache Kafka 主题中提取查询信息进行分析。
Optimization Engine 从 Apache Kafka 主题中提取 Gairos 平台统计数据进行分析。
Optimization Engine 从 Query analyery 分析器中提取 Gairos 查询见解,以查看是否需要执行任何操作。
Optimization Engine 将优化计划推送到 Gairos 平台的不同组件。
优化策略
分片和查询路由。
基于查询模式和签名的缓存。
合并索引。
处理繁重的查询。
索引模板优化。
分片优化。
界定索引范围。
清除未使用的数据。
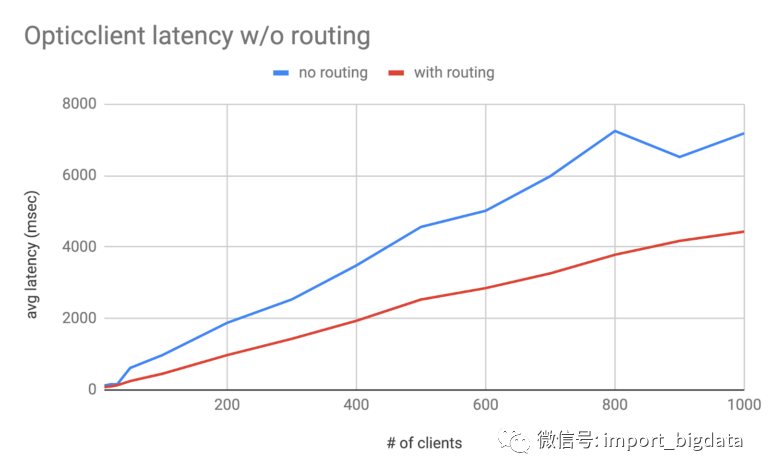
分片和查询路由
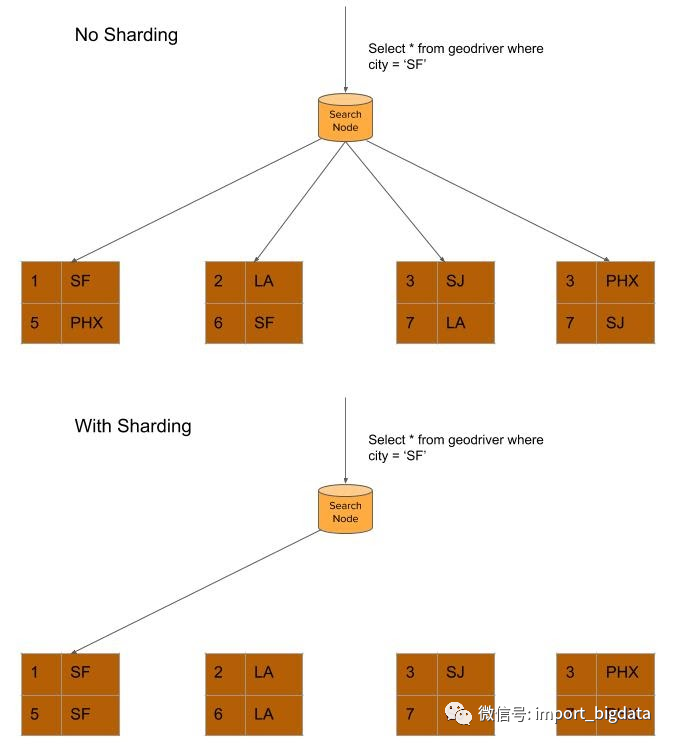
Write QPS:此因素要求分片应该能够处理高峰期的流量。
Read QPS:此因素要求分片应该能够处理峰值查询。
Filters:查询中使用的前 x 个频繁过滤器。顶部过滤器可以被认为是可能的分片关键候选者。过滤器必须具有足够多的不同值。
SLA:无论是分析用例还是实时用例。
Shard Size:我们建议将分片大小控制在 60 GB 以内。
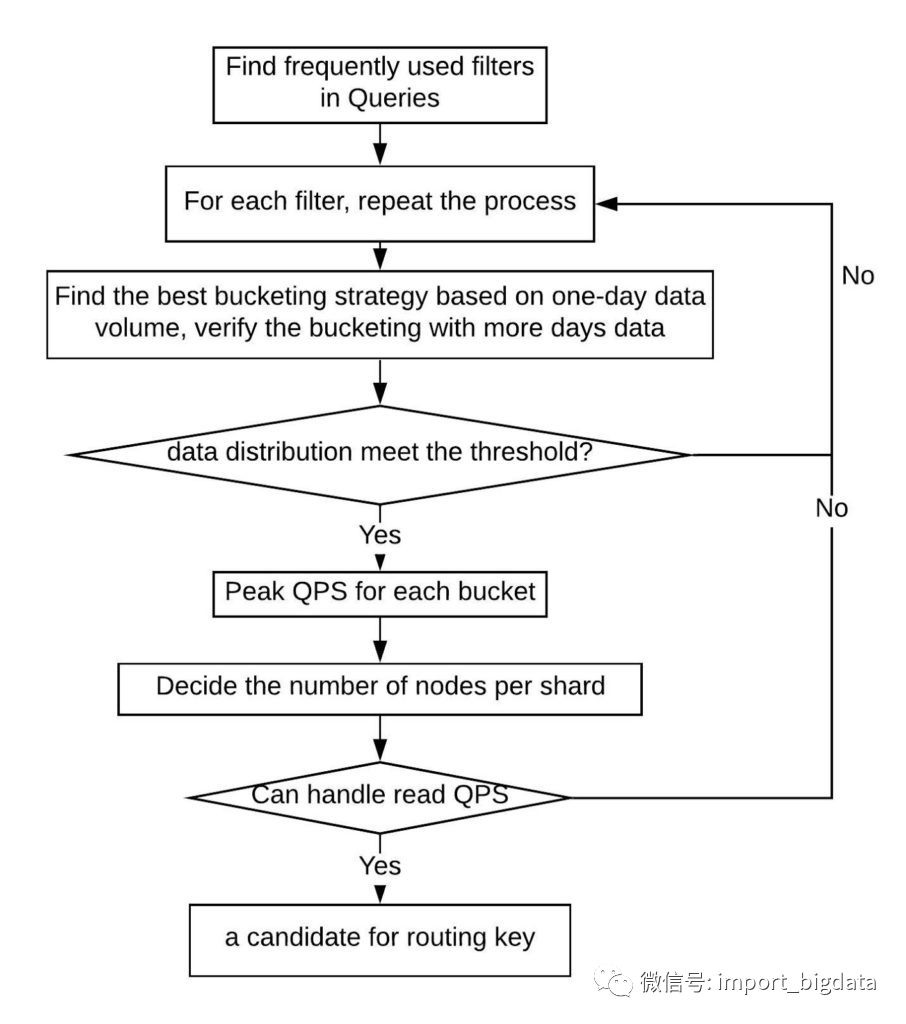
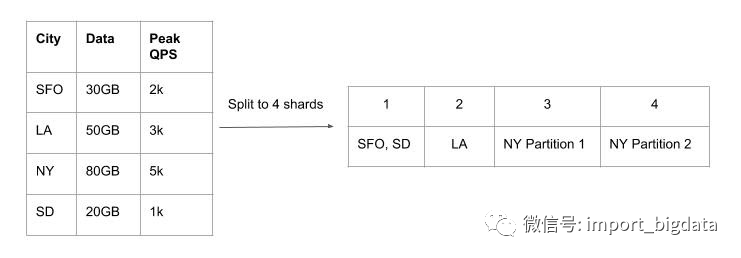
每个分片的峰值 Write QPS <= 3000 QPS
每个分片的数据大小 <= 60 GB
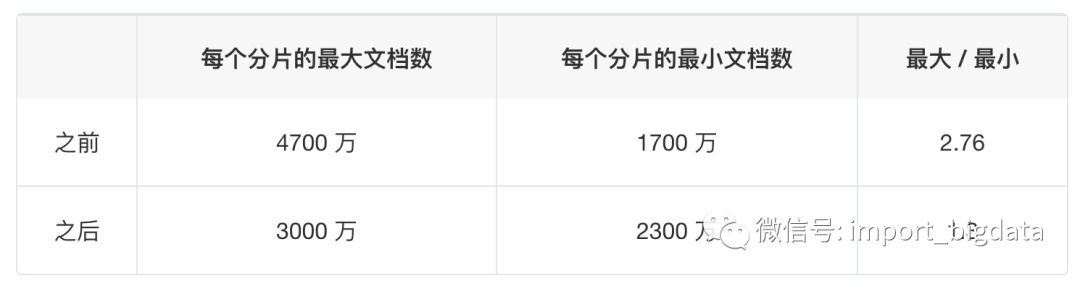
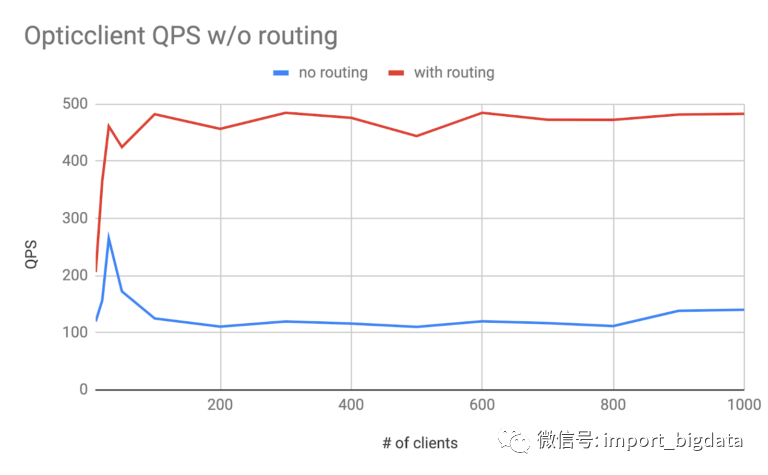
supply_geodriver的一些优化结果。相对于需求数据源(存储乘客请求),文档数量更多,数据大小更大。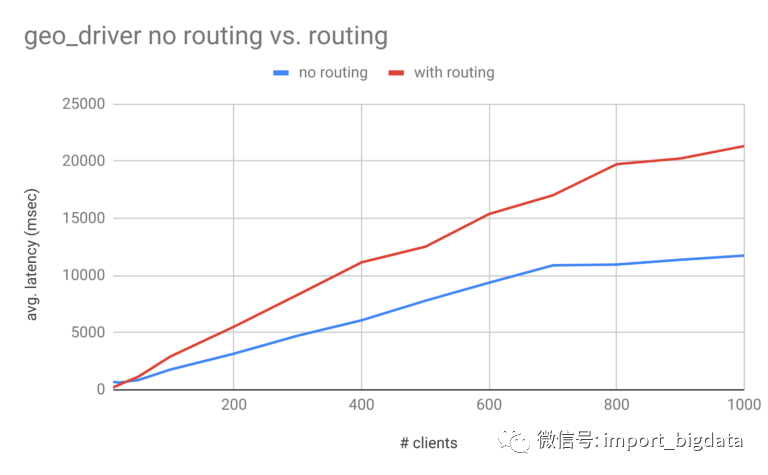
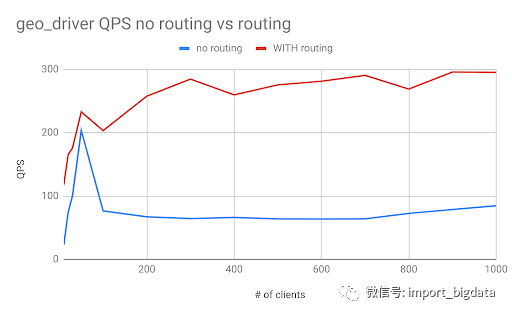
supply_status。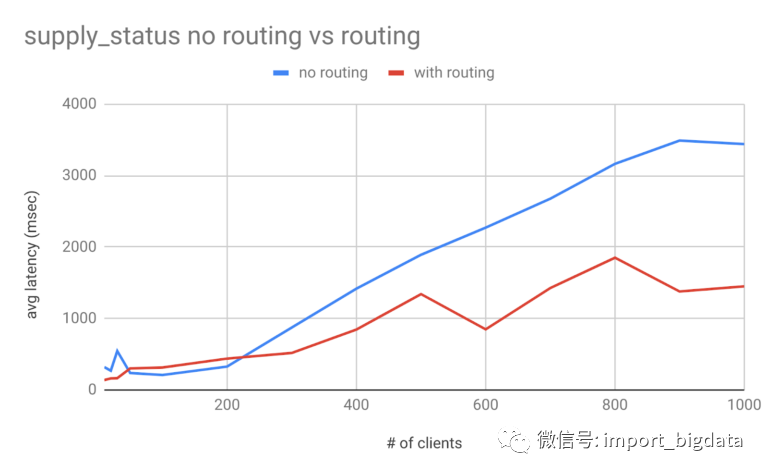
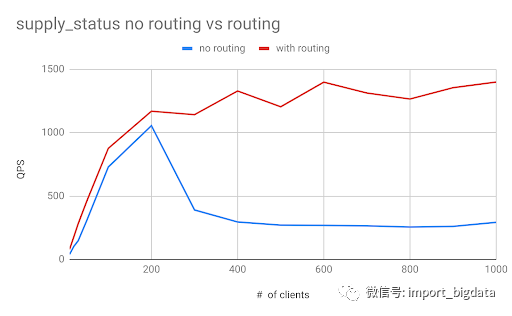
基于查询模式和签名的缓存

data source、granularity、by、filter、aggregations、bucketBy、sort、limit、having等。在定义签名时,只使用以下字段:datasource、granularity、by、filter、aggregations、bucketBy、sort、limit。查询签名由这些字段生成,并对每个字段进行排序。rider_sessions(样本数据集)的一些基准测试结果: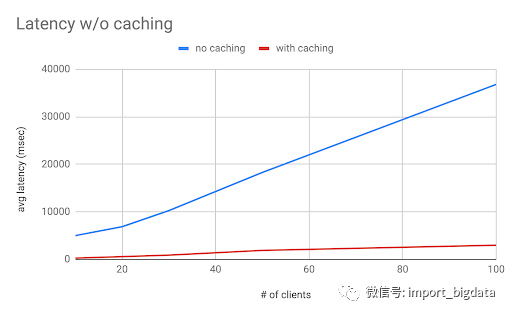
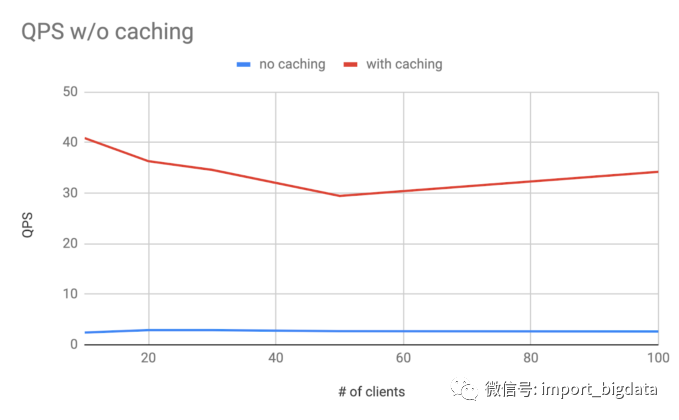
rider_sessions的查询都很麻烦,所以我们将在其他数据源上进行更多的测试,以验证我们得到的结果。supply_status的缓存统计如图 22 所示。可以看出,supply_status的命中率在 80% 以上。命中率 QPS 在 50 左右,而设置 QPS 在 10 左右。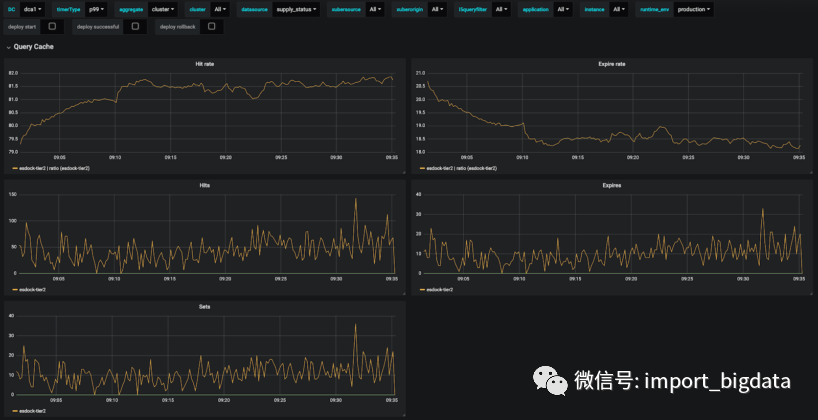
supply_status的缓存命中率很高,命中 QPS 在 50 左右,而设置 QPS 在 10 左右demand_jobs如图 23 所示。命中率为 80%。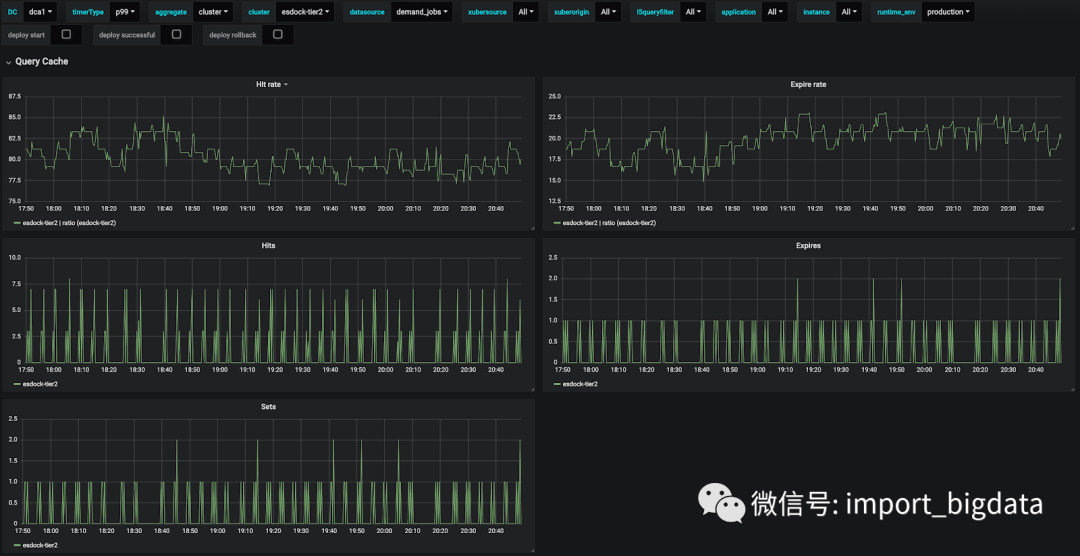
demand_jobs的缓存命中率在 80% 左右,命中有一些峰值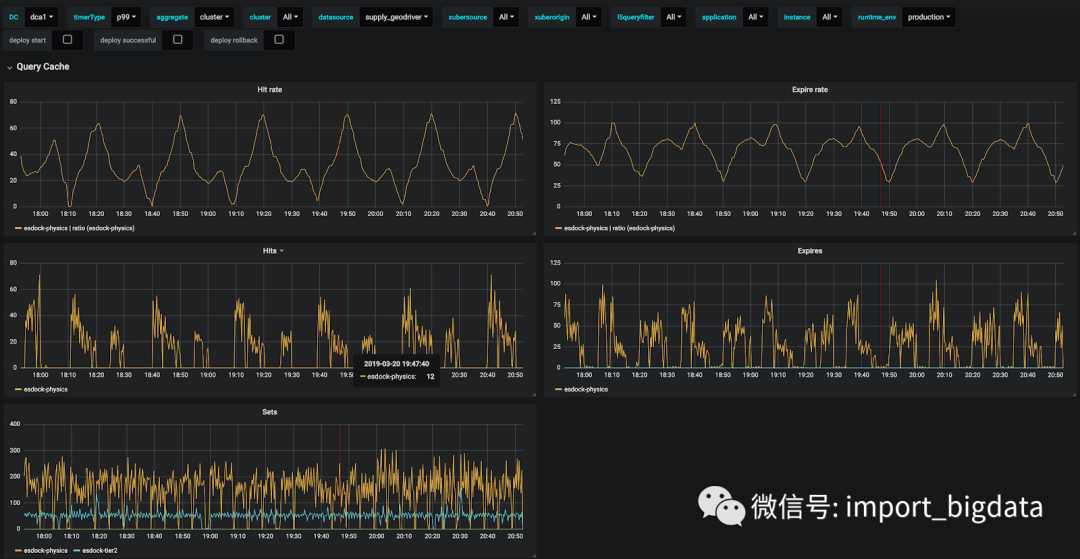
supply_geodriver的缓存命中率在 30% 左右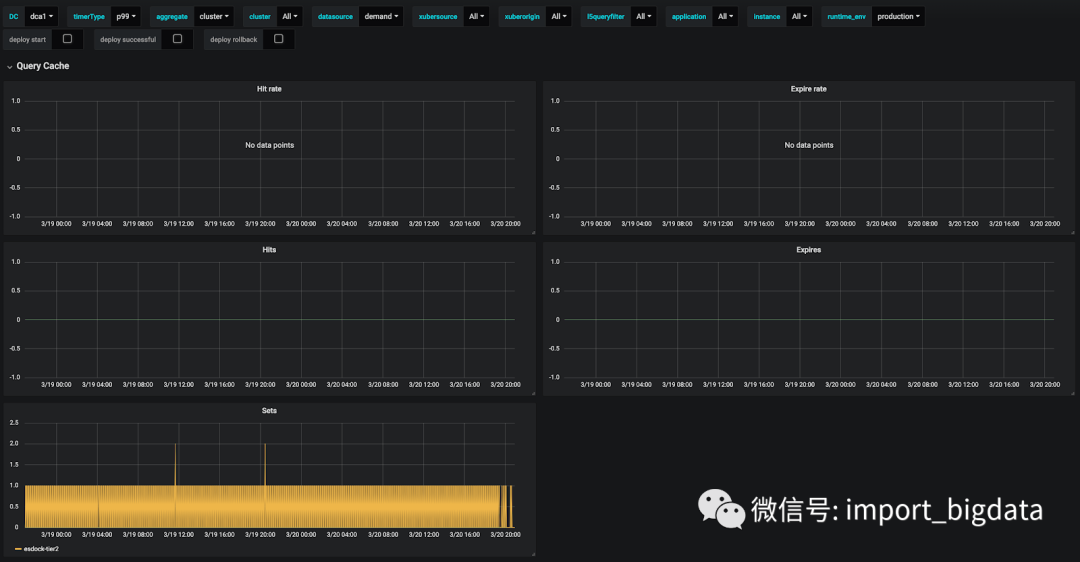
合并索引
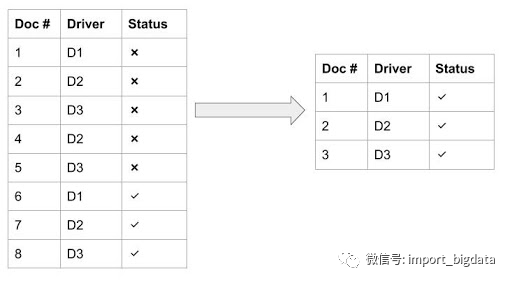
处理繁重的查询
分割查询:分割查询将多个索引查询成多个小查询,可以限制任意时刻查询的分片数量。
速率限制:识别重度查询模式并限制重度查询的速率,可以提高集群的性能。
缓存或创建滚动表:对于一些命中率较高的查询,可以考虑使用缓存或滚动表来提高性能。
迁移到 Hive/Presto:对于批量使用的情况,有些可能会迁移到 Hive/Presto。
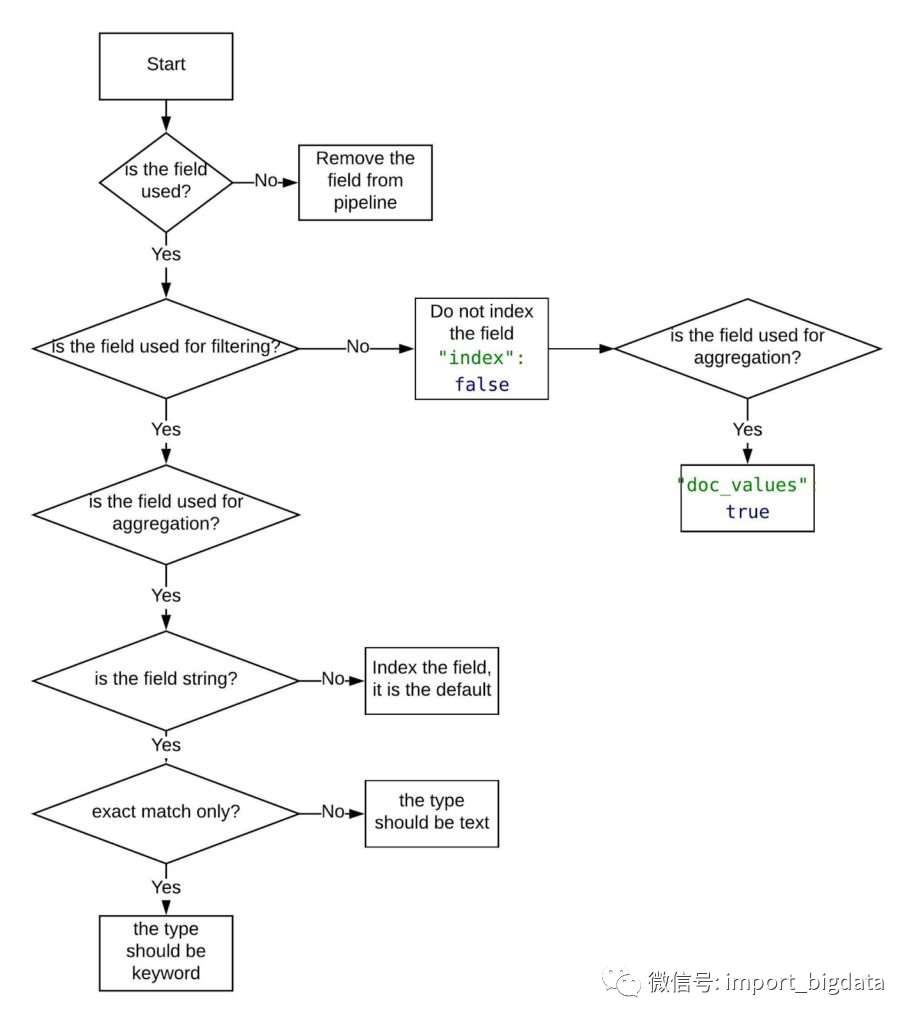
索引模板优化
是否使用?
是否用于过滤?
是否用于聚合?
是否需要模糊搜索?
分片优化
界定索引范围
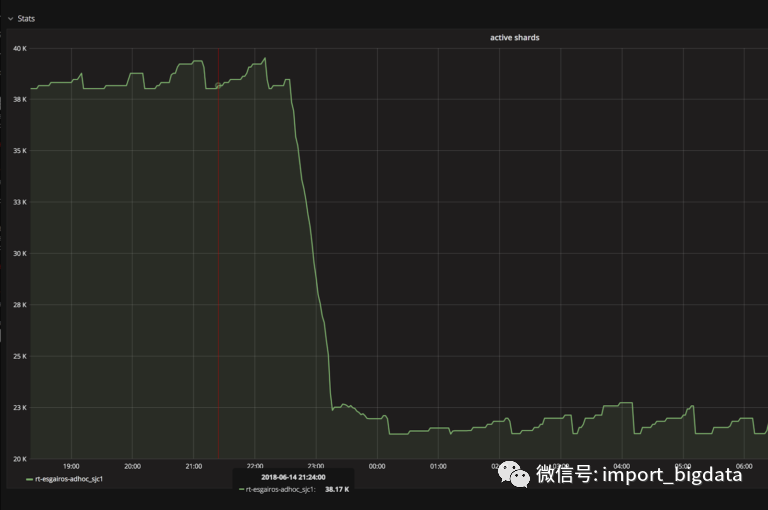
清除未使用的数据
未来工作
