
前端抱怨API响应慢,怎么办?
来源:juejin.cn/post/6936063402640932878
分析API的耗时是将API的总耗时拆分为不同的部分,清晰的知道是什么原因导致耗时过高。我们借助不同的工具,在不同的网络环境下进行耗时分析,从而提出相应的优化建议。
请求发送过慢导致耗时增加;
DNS解析过慢导致耗时增加;
恶劣的网络环境导致耗时增加;
一直在排队导致响应过慢;
服务端响应过慢导致耗时增加;
响应体积过大导致耗时增加;
等等……
一般从感官上觉得API接口响应慢,大部分人会直接归结于服务端处理慢,其实是不合理的。通过在内网环境下的API耗时分析和外网环境下的API耗时分析的对比,一般会认识到原因所在。
通过浏览器的开发者工具分析
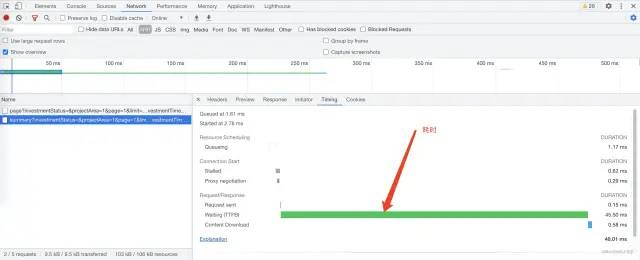
重点关注指标Waiting (TTFB),TTFB代表第一个字节到达的时间。此时间包括一次往返延迟和服务器准备响应所花费的时间。可以近似的认为是服务端耗时。
如果网络情况不好或者响应数据过大,则Content Download耗时会长一些,这时候应该考虑压缩响应.
Timing
开发者工具中Network中显示了当前页中调用的网络资源,点击资源可以查看资源的详情,其中Timing是资源调用时的耗时情况。
Queueing. 【排队中】浏览器在以下情况下将请求排队:有更高优先级的请求. 已为该来源打开了六个 TCP连接,这是限制。仅适用于HTTP/1.0和HTTP/1.1.浏览器正在磁盘缓存中短暂分配空间. Stalled. 【停滞】该请求可能由于排队中描述的任何原因而停止.Proxy negotiation. 【代理协商】浏览器正在与代理服务器协商请求.Request sent. 【发送请求】该请求正在发送.Waiting (TTFB). 【等待中】浏览器正在等待响应的第一个字节。TTFB代表第一个字节到达的时间。此时间包括一次往返延迟和服务器准备响应所花费的时间.Content Download. 【响应内容下载】浏览器正在接收响应.
其他可能出现的
DNS Lookup. 【DNS】浏览器正在解析请求的IP地址.Initial connection. 【初始化连接】浏览器正在建立连接,包括TCP握手/重试和协商SSL.
通过httpstat工具分析
httpstat git地址:
https://github.com/reorx/httpstat
如果是在Linux服务器上进行调用,则可以使用httpstat。
安装
直接下载脚本
wget https://raw.githubusercontent.com/reorx/httpstat/master/httpstat.py
通过pip
pip install httpstat
Mac
brew install httpstat
使用
httpstat可以使用cURL的参数。
httpstat www.baidu.com httpstat 127.0.0.1/post -X POST --data-urlencode "id=1" -v
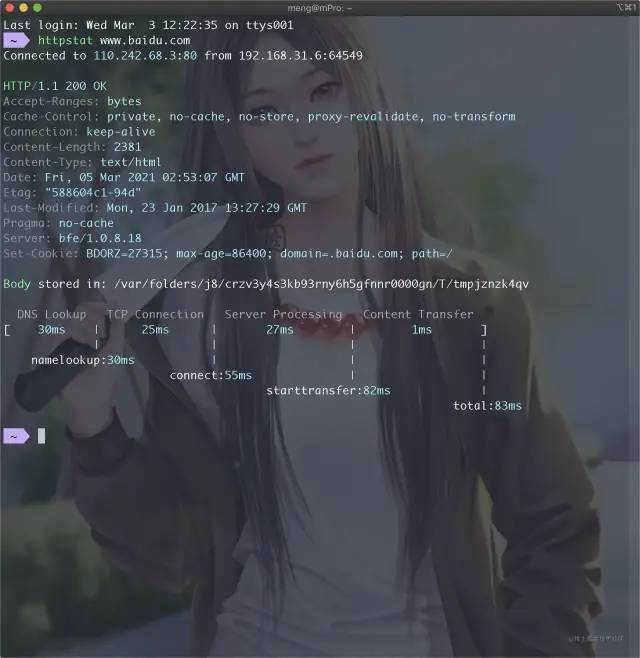
Server Processing可以近似的认为是服务端耗时。
服务端到底慢在哪里?
打印耗时日志?
StopWatch stopWatch = new StopWatch();
stopWatch.start();
// ...
stopWatch.stop();
LOGGER.info("[某某某业务] - [Time:{}ms]", stopWatch.getLastTaskTimeMillis());
脑子瞬间一热就会使用的方法,简单直接,但是如果定位不准确,你可能要加很多这种日志。
还是用火焰图吧
让软件执行情况可视化,是性能分析、调试的利器
火焰图的生成工具很多,比如Async Profiler、linux-perl,网上也有很多关于这方面的介绍,IDEA也集成Async Profiler,这个很方便。
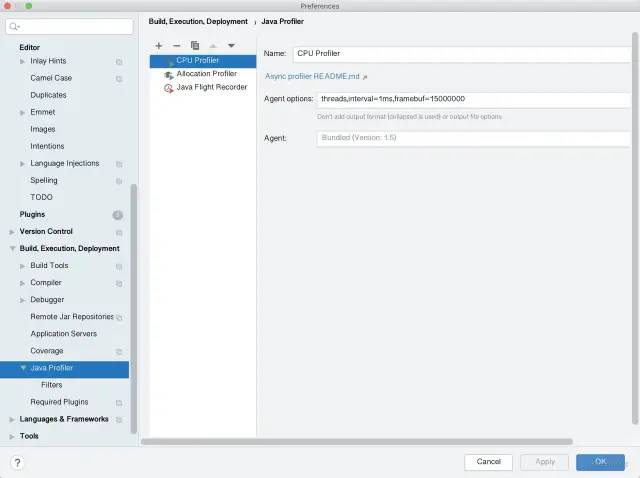
IntelliJ IDEA中的火焰图
打开火焰图
如果没有开启,则点击+号,进行添加。
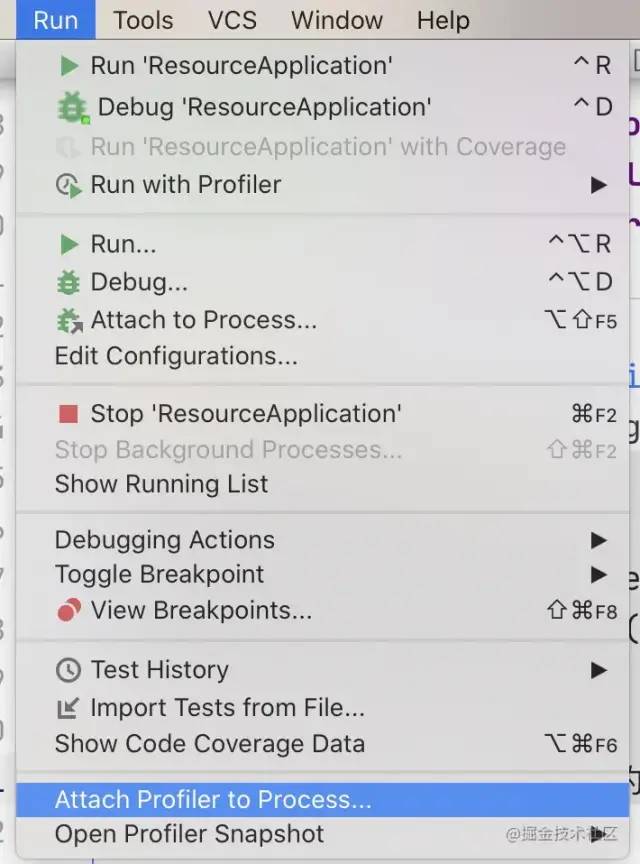
选择程序进行火焰图的分析
可以选择一个已经运行中的java程序进行分析,输出火焰图。
直接使用Async Profiler更简单
async-profiler git地址[1]
安装
从git上直接下载。
解压下可用。
简单使用
执行命令。
./profiler.sh -d 10 -f /tmp/flamegraph.svg
./profiler.sh -e itimer -d 10 -f /tmp/flamegraph.svg
可以通过-e来指定cpu、alloc、lock、wall、itimer、ClassName.methodName。
cpu:在这种模式下,profiler收集堆栈跟踪样本,包括Java方法、本机调用、JVM代码和内核函数。alloc:可以将探查器配置为收集分配最大堆内存的调用站点,而不是检测消耗CPU的代码。即检查当前分配内存最多的地方。lock:满足的锁定尝试,包括Java对象监视器和可重入锁。wall:告诉async-profiler在给定的时间内对所有线程平均采样,而不管线程状态如何: 运行、休眠或阻塞。例如,在分析应用程序启动时间时,这可能会有所帮助。。ClassName.methodName:ClassName.methodName选项使用给定的Java方法,以便使用堆栈跟踪记录此方法的所有调用。cpu:在这种模式下,profiler收集堆栈跟踪样本,包括Java方法、本机调用、JVM代码和内核函数。

在浏览器中打开file:///tmp/flamegraph.svg,并找到调用的API,我这里调用的是ProjectManageController中的findProject方法。
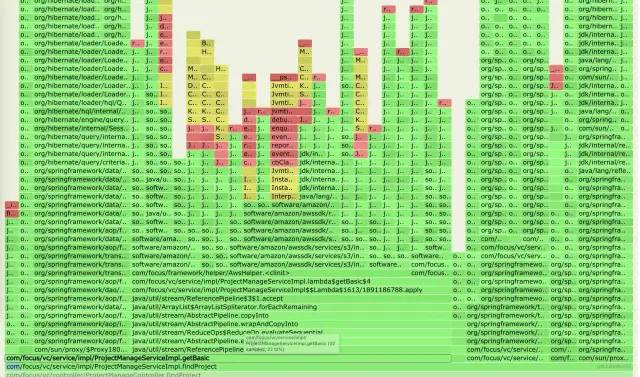
根据长度可以看出该方法中调用方法的耗时情况,这样我们就知道耗时主要集中在什么地方。
PS:如果方法名被编译掉了,那么可以在java启动时加入-XX:+PreserveFramePointer
做更多的工作
用户体验的优化是一个长期而艰巨的过程,为了衡量我们网站的性能是否良好,我们有更多的工作需要去做。通常,会在底层自定义一些以用户为中心的指标,比如Server-Timing[2]。
参考资料
https://github.com/jvm-profiling-tools/async-profiler: https://link.juejin.cn?target=https%3A%2F%2Fgithub.com%2Fjvm-profiling-tools%2Fasync-profiler
[2]https://w3c.github.io/server-timing/: https://link.juejin.cn?target=https%3A%2F%2Fw3c.github.io%2Fserver-timing%2F
程序汪资料链接
卧槽!字节跳动《算法中文手册》火了,完整版 PDF 开放下载!
卧槽!阿里大佬总结的《图解Java》火了,完整版PDF开放下载!
欢迎添加程序汪个人微信 itwang009 进粉丝群或围观朋友圈