
黑科技!漫画文字自动翻译
点击上方“AI算法与图像处理”,选择加"星标"或“置顶”
重磅干货,第一时间送达
【CSDN 编者按】相信不少漫画迷都曾为了追漫画特地去学习外语,学外语的时候很累,看漫画的时候很爽。现在,东京大学两位博士研发了漫画文字自动翻译的一个工具,追漫再也不累了!
最近,由东京大学 Mantra 团队、雅虎(日本)等机构联合发布的《Towards Fully Automated Manga Translation 实现漫画全自动翻译》论文,引发了学界和二次元界的关注。
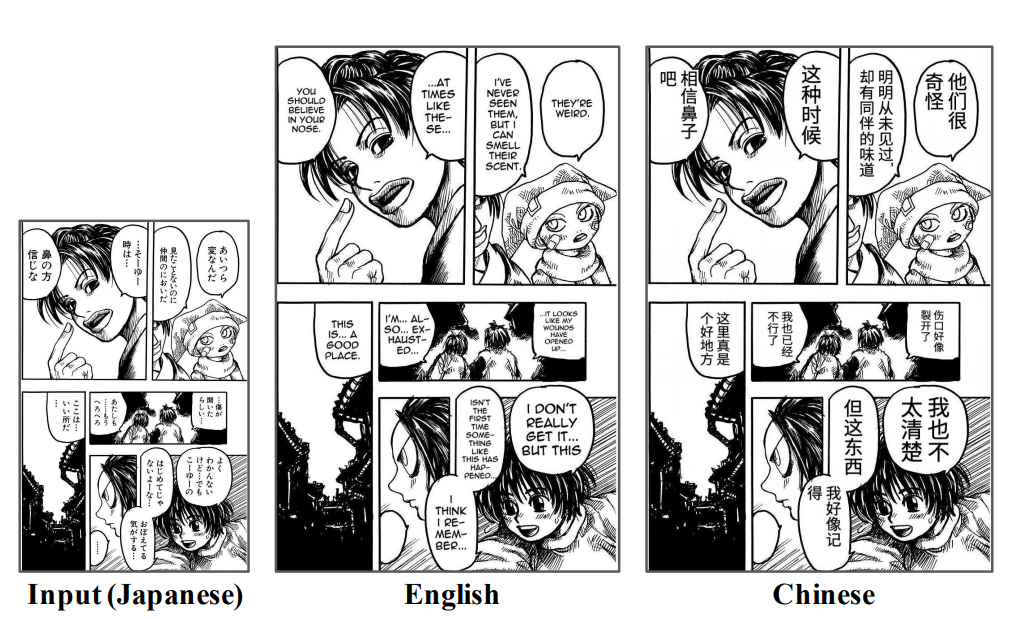
如图所示:左一为日文原版,自动化输出英文版(右二)和中文版(右一)
Mantra 团队成功地实现了将漫画的中的对话、气氛词、标签等文字自动识别,并做到了区分角色、联系上下文,最后将翻译文字准确替换、嵌入气泡区域。
有了这个翻译神器,估计翻译组、追漫的小伙伴们都该偷着乐了。
发论文、公开数据集、商业化一条龙
在科研方面,目前该篇论文已经被 AAAI 2021 接收,研究团队还开源了一个包含五部不同风格(幻想、爱情、战斗、悬疑、生活)的漫画,所组成的翻译评估数据集。
OpenMantra 漫画翻译评估数据集
论文地址:https://arxiv.org/abs/2012.14271
数据格式:带注释的 JSON 文件和原始图像
数据内容:1593 个句子、848 个场景、214 页漫画
数据大小:36.8 MB
更新时间:2020 年 12 月 7 日
下载地址:https://hyper.ai/datasets/14137
在产品化方面,Mantra 计划上线封装好的自动翻译引擎,不仅面向出版社提供漫画的自动化翻译与发行服务,也会发布面向个人用户的服务。
具体的实现步骤,Mantra 研究团队在论文《Towards Fully Automated Manga Translation 实现漫画全自动翻译》中进行了详细的解释。

定位文字
在实现漫画自动化翻译的第一步,就是提取文字区域。
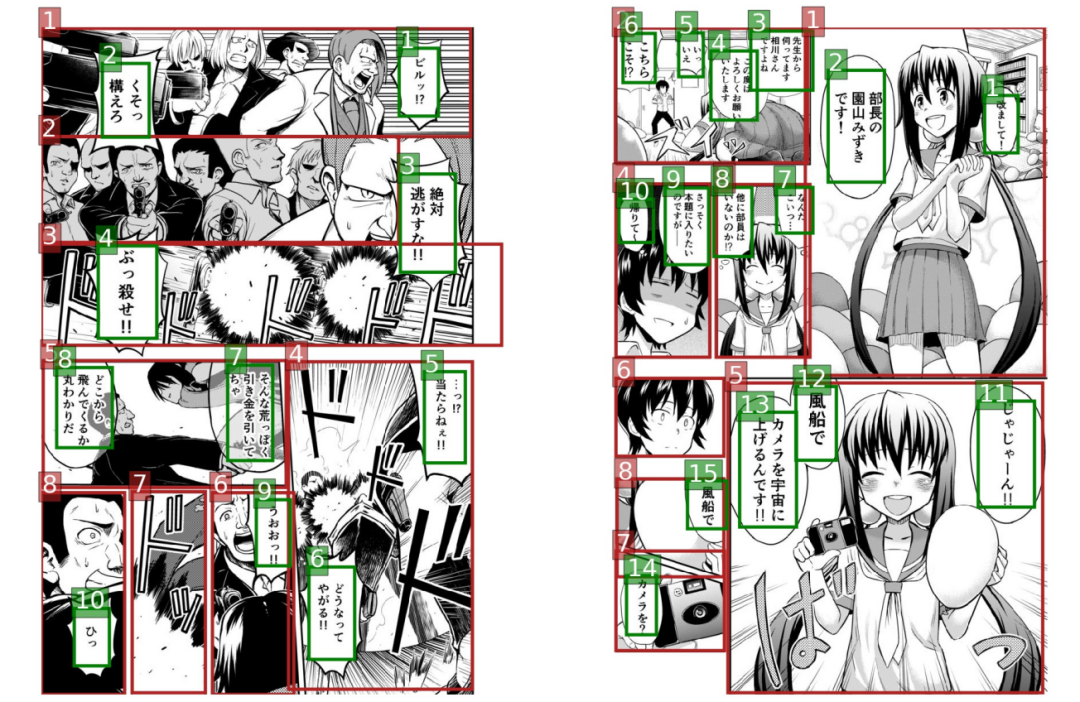
但由于漫画的特殊性,来自不同角色的对话、效果拟声词、文字标注等等,都会展现在一幅漫画图片里,漫画师会用气泡、不同的字体、夸张的字体来展现不同效果的文字。
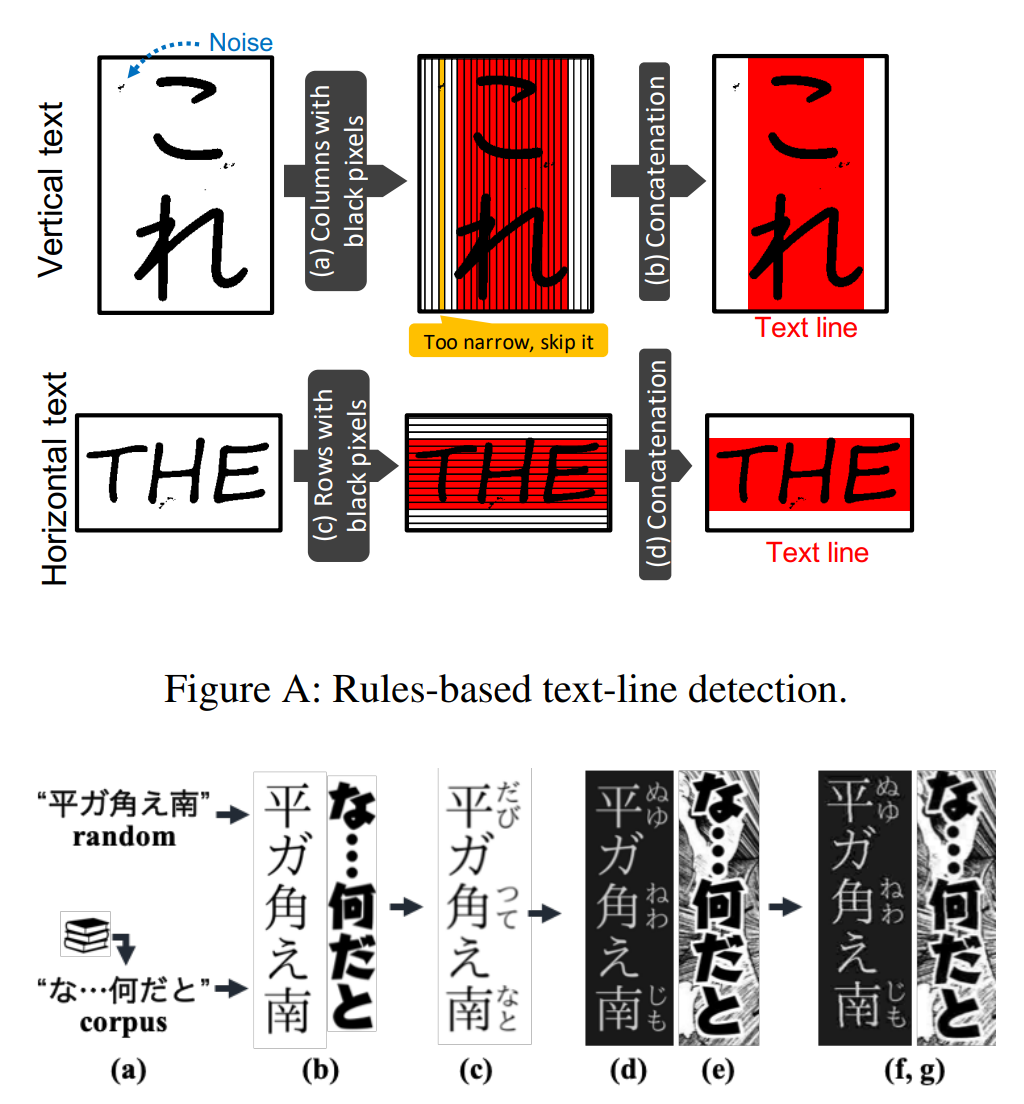
漫画中的手绘、异形文字的识别成为了难点
研究团队发现,由于漫画中的这些各种字体和手绘样式,即使使用最先进的OCR 系统(例如 Google Cloud Vision API),在漫画文本上的表现很不理想。
因此,团队开发了针对漫画优化的文本识别模块,通过检测文本行和识别每个文本行的字符来实现对异形文字的识别。

内容识别
在漫画中,最常见的文字就是角色之间的对话,对话文字气泡还会被切割成多块。
这就要求自动化机器翻译需要准确区分角色,还得联系上下文注意主语的衔接、避免重复,这都对机器翻译提出了更高的要求。
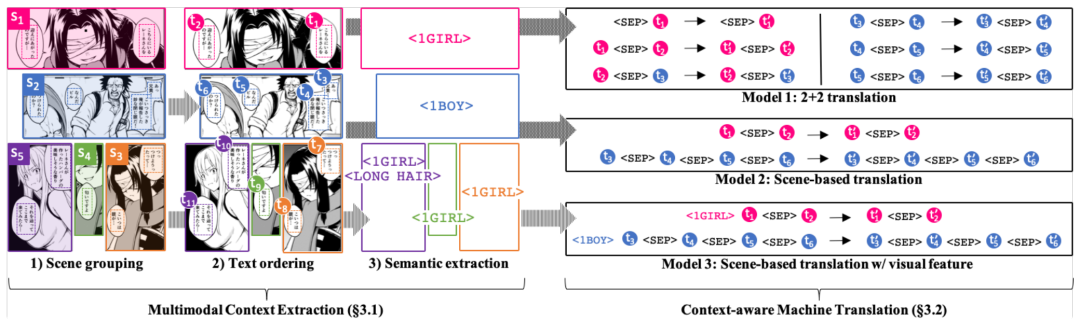
点击放大查看场景分类、文本顺序和情感识别流程
在这一步中,要通过上下文感知、情感识别等方式来实现,在上下文感知中,Mantra 团队用了文本分组、文本阅读顺序、提取视觉语义三种方式,实现了多模态的上下文感知。

自动嵌字
Mantra 这一自动化引擎,不仅能够区分角色、联系上下文准确翻译以外,还很好地解决了漫画翻译中的耗时最久、人力成本最高的环节——嵌字。
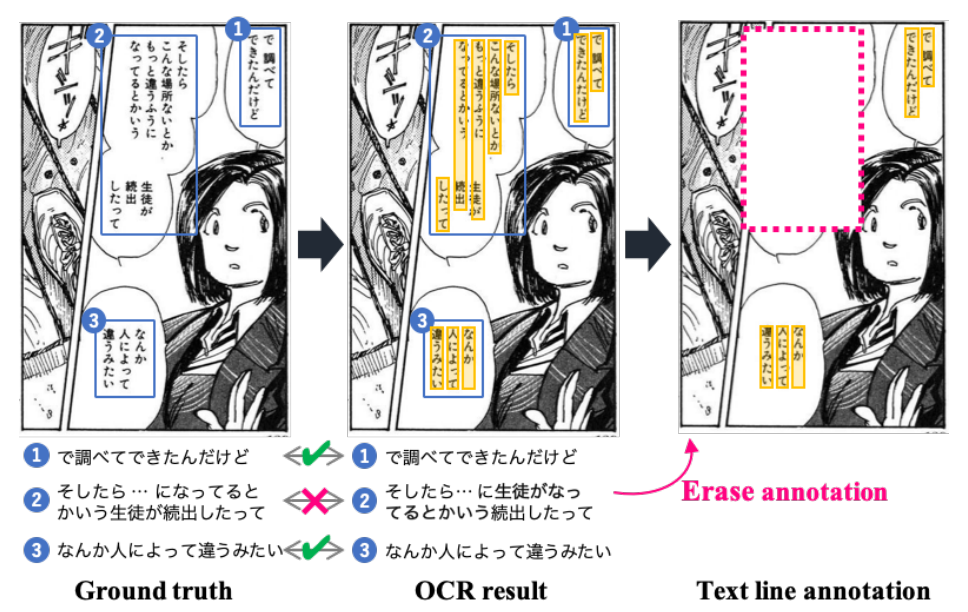
在嵌字这一环节中,首先要擦除嵌字区域,再进行嵌字,由于日文、中文、英文字符的形态、拼写、组合、连读方式都不一样,所以这一环节的难度也尤其大。
在这一步中,需要进行:页面匹配→检测文本框→文字气泡的像素统计→拆分连接的气泡→语言间的对齐→文字识别→上下文提取。

实验: 数据集与模型测试
在论文中的实验部分,Mantra 团队提到目前并没有包含多种语言的漫画数据集,所以他们创建了 OpenMantra(已开源) 和 PubManga 数据集,其中OpenMantra 用于评估机器翻译,包含 1593 个句子、848 个场景画面和 214 页漫画,Mantra 团队已经请专业翻译人员将数据集翻译成英文和中文。
OpenMantra 漫画翻译评估数据集(同上文)
论文地址:https://arxiv.org/abs/2012.14271
数据格式:带注释的 JSON 文件和原始图像
数据内容:1593 个句子、848 个场景、214 页漫画
数据大小:36.8 MB
更新时间:2020 年 12 月 7 日
下载地址:https://hyper.ai/datasets/14137
PubManga 数据集用于评估构建的语料库,该数据集包含注释:
文本和框架的边框
日语和英语的文本(字符序列)
框架和文本的阅读顺序
为了训练模型,团队准备了 842097 对日文、英文版的漫画页面,共 3979205 对日语-英语的句子。具体的方法可以阅读论文,最终的模型效果评估由人工完成,Mantra 团队邀请了五位专业的日文-英文翻译人员,以专业的翻译评估程序给句子打分。

项目背后:有趣的灵魂一起学习
目前该篇论文已经被 AAAI 2021 收录,产品化的工作也在稳步推进中,从 Mantra 团队的推特中,我们看到已经有不少漫画成功使用了 Mantra 进行自动化机器翻译。
这样的宝藏项目,是由两位东京大学的博士生完成的,CEO石和祥之介 (Shonosuke Ishiwatari),CTO 日南凉太(Ryota Hinami) 同在东京大学博士毕业,在 2020 年创立了 Mantra 团队。


Mantra CEO 石和祥之介(上)和 CTO 日南凉太(下)
CEO 石和祥之介,是东京大学信息科学系本科 2010 级入学,博士毕业于 2019 年。他主要专注于自然语言处理领域的研究和开发,包括机器翻译和字典生成,也是本篇论文的第二作者。
值得一提的是,石和祥之介的研究经验丰富,不仅曾经在 CMU 交流访学,还曾于 2016-17 年在位于北京的微软亚洲研究院实习半年,当时他在 MSRA 首席研究员刘树杰团队从事 NLC (Natural Language Computing) 自然语言计算的研究。
CTO 日南凉太石和祥之介同年入学,专注于图像识别领域。在 2016-17 年同期和石和祥之介,一同在微软亚洲研究院实习。
这样的一对技能互补的小伙伴,完成了 Mantra 的大部分工作,是不是从发量到成果都很让人羡慕呢?
如果想了解更多关于 Mantra 的信息,大家可以访问论文(https://arxiv.org/abs/2012.14271)、项目官网(https://mantra.co.jp/)或下载数据集(https://hyper.ai/datasets/14137),进一步研究。
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:终身受益的编程指南:Google编程风格指南
在「AI算法与图像处理」公众号后台回复:c++,即可下载。历经十年考验,最权威的编程规范!
下载3 CVPR2020 在「AI算法与图像处理」公众号后台回复:CVPR2020,即可下载1467篇CVPR 2020论文 个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称
觉得不错就点亮在看吧
