
这可能是一份最完整的 RabbitMQ 总结!

- 前言 -
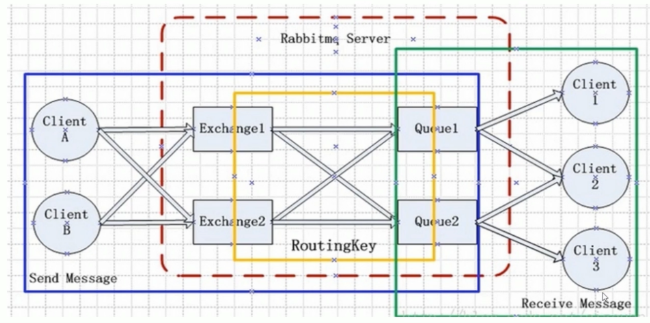
- AMQP 协议 -
- Exchange -
- 消息如何保证 100 %投递 -
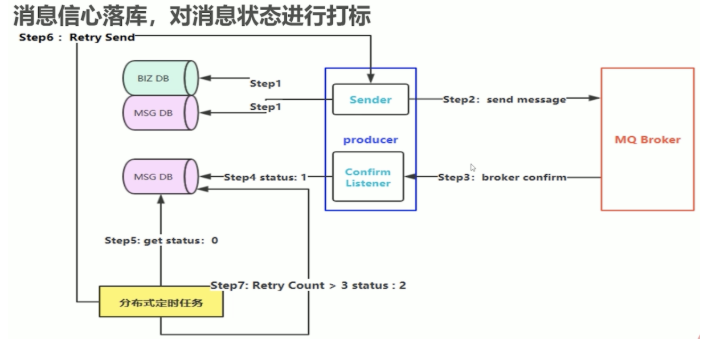
什么是生产端的可靠性投递?
可靠性投递保障方案
消息幂等性
我对一个动作进行操作,我们肯能要执行 100 次 1000 次,对于这 1000 次执行的结果都必须一样的。比如单线程方式下执行 update count-1 的操作执行一千次结果都是一样的。
所以,这个更新操作就是一个幂等的,如果是在并发不做线程安全的处理的情况下 update 一千次操作结果可能就不是一样的,所以并发情况下的 update 操作就不是一个幂等的操作。对应到消息队列上来,就是我们即使收到了多条一样的消息,也和消费一条消息效果是一样的。
高并发的情况下如何避免消息重复消费
唯一 id +加指纹码,利用数据库主键去重。 优点:实现简单; 缺点:高并发下有数据写入瓶颈。 利用 Redis 的原子性来实习。 使用 Redis 进行幂等是需要考虑的问题。
是否进行数据库落库,落库后数据和缓存如何做到保证幂等(Redis 和数据库如何同时成功同时失败)? 如果不进行落库,都放在 Redis 中,如何设计 Redis 和数据库的同步策略?还有放在缓存中就能百分之百的成功吗?
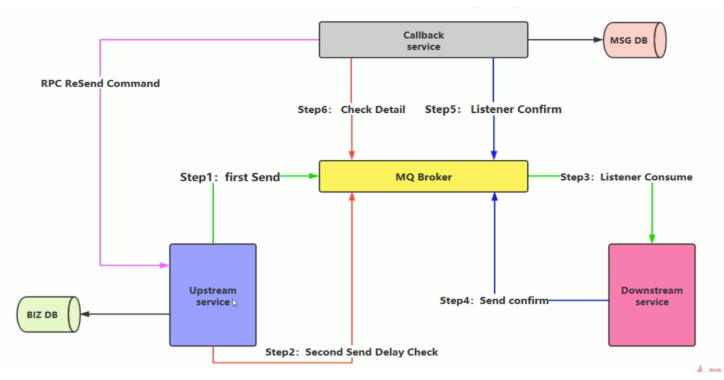
confirm 确认消息、Return 返回消息
消息的确认,指生产者收到投递消息后,如果 Broker 收到消息就会给我们 的生产者一个应答,生产者接受应答来确认 Broker 是否收到消息。
如何实现confirm确认消息
在 Channel 上开启确认模式:channel.confirmSelect(); 在 Channel 上添加监听:addConfirmListener,监听成功和失败的结果,具体结果对消息进行重新发送或者记录日志。
Return 消息机制
- 消费端自定义监听 -
消费端限流
假设我们有个场景,首先,我们有个 RabbitMQ 服务器上有上万条消息未消费,然后我们随便打开一个消费者客户端,会出现:巨量的消息瞬间推送过来,但是我们的消费端无法同时处理这么多数据。
RabbitMQ 提供了一种 qos(服务质量保证)的功能,即非自动确认消息的前提下,如果有一定数目的消息(通过 consumer 或者 Channel 设置 qos)未被确认,不进行新的消费。
void basicQOS(unit prefetchSize,ushort prefetchCount,Boolean global)方法。
prefetchSize:0 单条消息的大小限制。0 就是不限制,一般都是不限制。 prefetchCount: 设置一个固定的值,告诉 rabbitMQ 不要同时给一个消费者推送多余 N 个消息,即一旦有 N 个消息还没有 ack,则 consumer 将block 掉,直到有消息 ack。 global:truefalse 是否将上面的设置用于 channel,也是就是说上面设置的限制是用于 channel 级别的还是 consumer 的级别的。
消费端ack与重回队列
消费端进行消费的时候,如果由于业务异常我们可以进行日志的记录,然后进行补偿!(也可以加上最大努力次数的尝试) 如果由于服务器宕机等严重问题,那我们就需要手动进行ack保证消费端的消费成功!
消息重回队列
重回队列就是为了对没有处理成功的消息,把消息重新投递给 broker! 实际应用中一般都不开启重回队列。
TTL队列/消息
TTL time to live 生存时间。
支持消息的过期时间,在消息发送时可以指定。 支持队列过期时间,在消息入队列开始计算时间,只要超过了队列的超时时间配置,那么消息就会自动的清除。
死信队列
死信队列:DLX,Dead-Letter-Exchange
消息被拒绝(basic.reject/basic.nack)同时requeue=false(不重回队列); TTL过期; 队列达到最大长度。
DLX也是一个正常的Exchange,和一般的Exchange没有任何的区别,他能在任何的队列上被指定,实际上就是设置某个队列的属性。 当这个队列出现死信的时候,RabbitMQ就会自动将这条消息重新发布到Exchange上去,进而被路由到另一个队列。可以监听这个队列中的消息作相应的处理,这个特性可以弥补rabbitMQ以前支持的immediate参数的功能。
设置 Exchange 和 Queue,然后进行绑定;
Exchange: dlx.exchange(自定义的名字);
queue: dlx.queue(自定义的名字);
routingkey: #(#表示任何routingkey出现死信都会被路由过来);
然后正常的声明交换机、队列、绑定,只是我们在队列上加上一个参数:
arguments.put("x-dead-letter-exchange","dlx.exchange")。
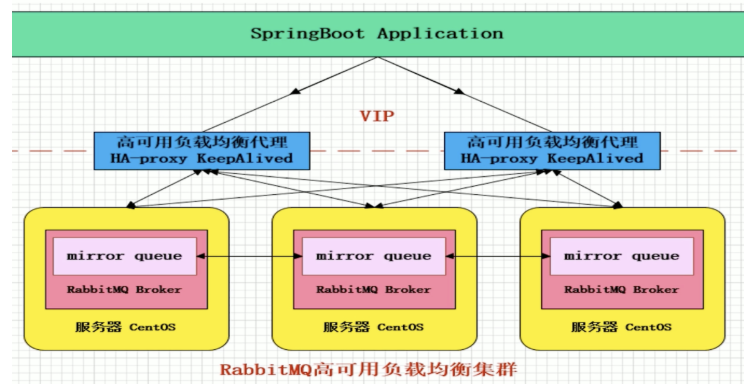
- RabbitMQ 集群模式 -
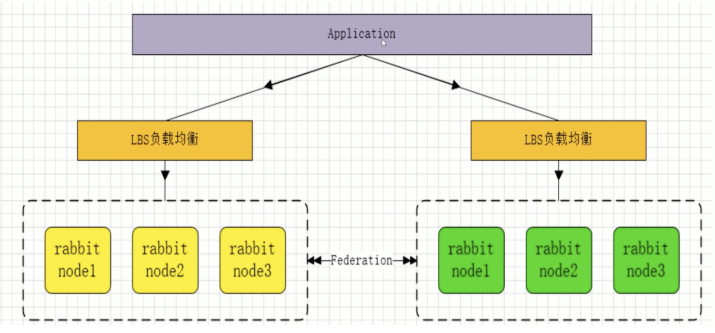
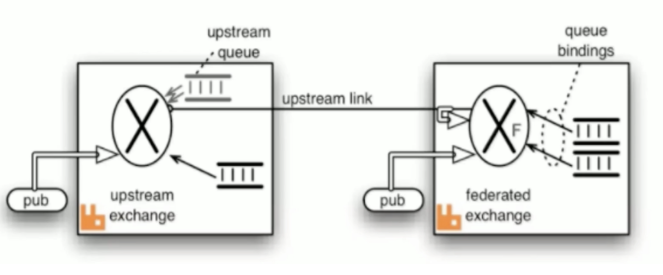
federation 插件是一个不需要构建 Cluster,而在 Brokers 之间传输消息的高性能插件,federation 可以在 brokers 或者 cluster 之间传输消息,连接的双方可以使用不同的 users 或者 virtual host 双方也可以使用不同版本的 erlang 或者 rabbitMQ 版本。federation 插件可以使用 AMQP 协议作为通讯协议,可以接受不连续的传输。
HAProxy 是一款提供高可用性、负载均衡以及基于 TCP (第四层)和 HTTP(第七层)应用的代理软件,支持虚拟主机,它是免费、快速并且可靠的一种解决方案。HAProxy 特别适用于那些负载特大的 web 站点,这些站点通常又需要会话保持或七层处理。HAProxy 运行在时下的硬件上,完全可以支持数以万计的并发连接。并且它的运行模式使得它可以很简单安全的整合进您当前的架构中同时可以保护你的 web 服务器不被暴露到网络上。
HAProxy 性能为何这么好?
keepAlive
KeepAlived 软件主要通过 VRRP 协议实现高可用功能。VRRP 是 Virtual Router RedundancyProtocol (虚拟路由器冗余协议)的缩写,VRRP 出现的目的就是为了解决静态路由单点故障问题的,它能够保证当个别节点宕机时,整个网络可以不间断地运行所以,Keepalived 方面具有配置管理 LVS 的功能,同时还具有对 LVS 下面节点进行健康检查的功能,另一方面也可实现系统网络服务的高可用功能。
1、管理 LVS 负载均衡软件;
2、实现 LVS 集群节点的健康检查中;
3、作为系统网络服务的高可用性(failover)。
Keepalived如何实现高可用
Redundancy Protocol ,虚拟路由器冗余协议)来实现的。
来源:https://segmentfault.com/a/1190000022387211
版权申明:内容来源网络,版权归原创者所有。除非无法确认,我们都会标明作者及出处,如有侵权烦请告知,我们会立即删除并表示歉意。谢谢!

评论