
No.6 - 时序数据库随笔 - InfluxDB&Flux调试环境搭建
“ 本篇为大家介绍了InfluxDB和Flux的开发调试环境,便于后续对上一篇提到的用户问题进行解决的操作演示。”
01
—
上篇回顾
这是上一篇结尾我们抛出来的InfluxDB社区问题,那么要想解决这个问题,我们首先先建立InfluxDB的开发环境,以源码的方式了解其应用和实现。所以本篇我们为搭建介绍InflxuDB的开发调试环境。
02
—
依赖安装
要想进行InfluxDB的开发调试,我们需要一些基础软件安装(MacOS),如下:
brew
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"go
brew install go@1.15......flux git:(master) ✗ go versiongo version go1.15.9 darwin/am
git
brew install gitgit:(master) ✗ git --versiongit version 2.30.2
bazaar
brew install bazaargit:(master) ✗ bzr versionBazaar (bzr) 2.7.0
rust
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | shmake pkg-config protobuf yarn
brew install make pkg-config protobuf yarngit:(master) ✗ make --versionGNU Make 4.3......
如果上面一切顺利,我们设置一下环境变量 ~/.bash_profile :
export GOPATH=/Users/jincheng/goexport GOROOT=/usr/local/opt/go@1.15/libexecexport PKG_CONFIG=/Users/jincheng/go/bin/pkg-configexport PKG_CONFIG_PATH=$(find /usr/local/Cellar -name 'pkgconfig' -type d | grep lib/pkgconfig | tr '\n' ':' | sed s/.$//)export PATH=$GOROOT/bin:$GOPATH/bin:$PKG_CONFIG_PATH:$PATH
别忘记 source ~/.bash_profile, 我们进入正题,下载源码。
03
—
源码构建
很多时候我们对一项功能的了解,需要对源码有一定的了解,学习InfluxDB我们同样需要源码方式进行。
下载
git clone https://github.com/influxdata/influxdb.git编译
make......make[2]: Leaving directory '/Users/jincheng/work/influxdb/storage/flux'make[1]: Leaving directory '/Users/jincheng/work/influxdb/storage'env GO111MODULE=on go build -tags 'assets' -ldflags "-s -w -X main.commit=eeba0f3268" -o bin/darwin/influx ./cmd/influxenv GO111MODULE=on go build -tags 'assets' -ldflags " -X main.commit=eeba0f3268" -o bin/darwin/influxd ./cmd/influxd
如上我们发现会生成两个二进制文件,一个是influxd服务,一个是influx的客户端。
下载依赖
go clean -modcache && go mod tidy && go mod vendor执行完如上命令会在项目目录下生成一个vendor目录,里面下载了go.mod里面配置的项目所有依赖。
04
—
GoLand运行调试
GoLand是进行Go开发调试的IDE工具,我们后面关于InfluxDB源码部分分享就在GoLand环境中进行。
IDE配置
在GoLand中进行InfluxDB的开发调试,需要简单的配置一下,GOROOT/GOPATH/Go Modules ,如图:
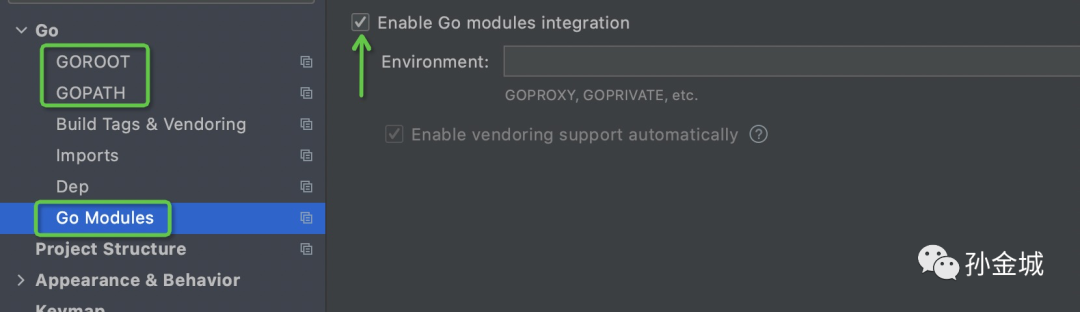
其中GOROOT/GOPATH和~/.bash_profile保持一致。
运行主服务
运行 influxd/main.go ,出现如下界面证明已经influxd的服务已经启动成功,并在8086端口监听。
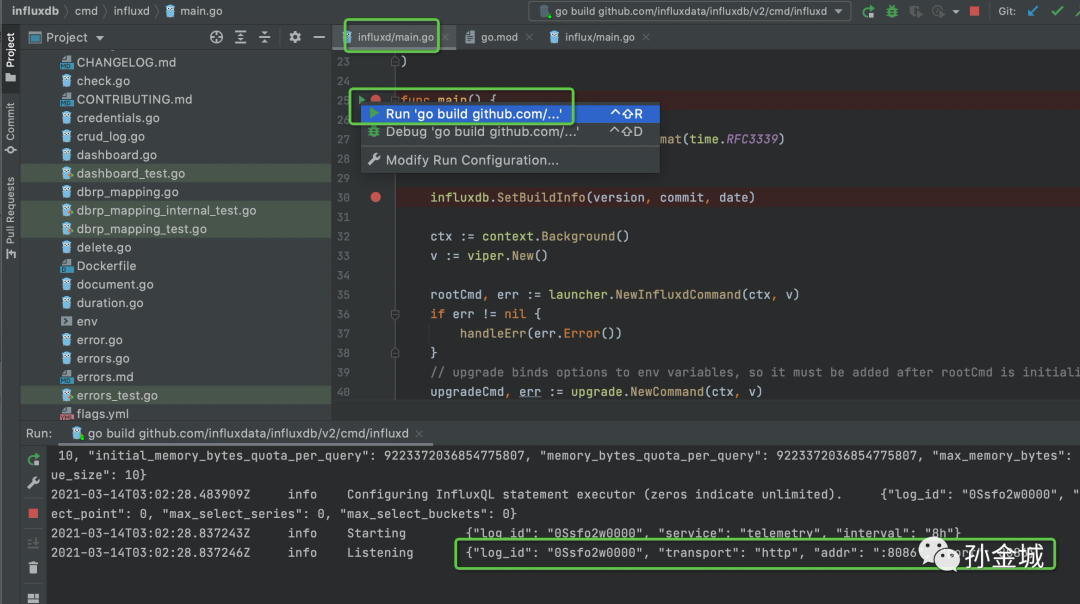
如果一切顺利,那么服务监听在8086端口。
调试主服务
我们如果看看源代码的执行路径,往往我们期望debug的方式运行 influxd/main.go ,如果出现debug启动出现如下错误,说明我们的环境变量没有在IDE中生效:
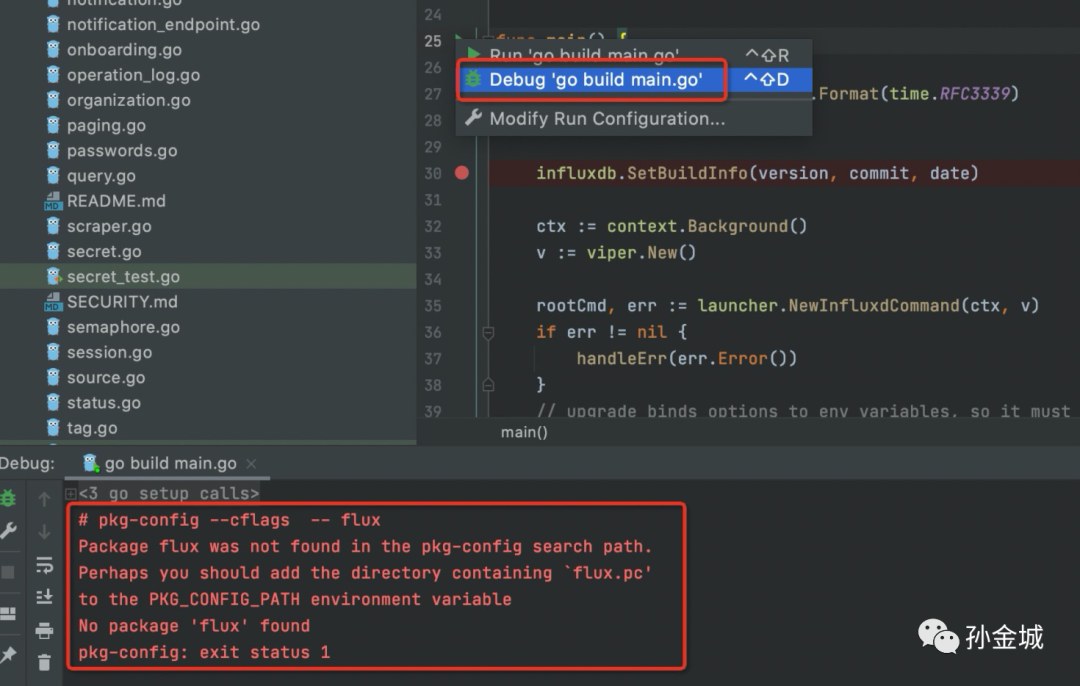
如上情况我们可以创建或者在~/.zshrc中增加一行配置让 ~/.bash_profile配置生效。
source ~/.bash_profile然后重启电脑,再试一下。如果顺利,我们设置一下断点,可以类似界面如下:
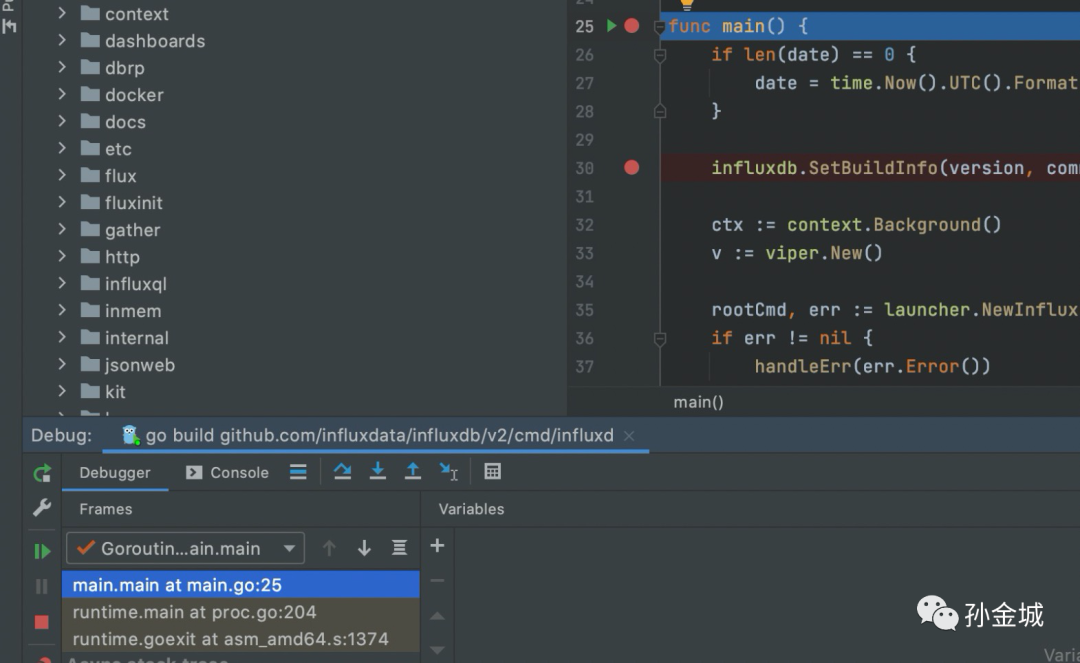
如果一切顺利,那么调试模式下的服务也是监听8086端口。
05
—
操作测试
好的,服务启动了,下面我们利用客户端继续数据操作的测试。上面编译的时候大家发现其实我们会生成2个二进制可执行文件,一个是influxd,一个是influx。我们刚才debug启动了influxd的服务,我们同样可以启动influx的客户端,进行数据操作,客户端我们之间运行可执行文件(如果你愿意也可以IDE启动)。
初始化
:upper:]' '[:lower:]')/influx setup \--username iot \--password 2021iotdb \--org org \--bucket iot \--retention 1h \--token where-were-going-we-dont-need-roads \--forceConfig default has been stored in /Users/jincheng/.influxdbv2/configs.User Organization Bucketiot org iot
如上执行成功表明我们完成了setup,创建了名为 iot 的bucket,在v2中bucket相当于v1中的database。
插入数据
bin/$(uname -s | tr '[:upper:]' '[:lower:]')/influx write --bucket iot --precision s "m v=2 $(date +%s)"bin/$(uname -s | tr '[:upper:]' '[:lower:]')/influx write --bucket iot --precision s "m v=168 $(date +%s)"bin/$(uname -s | tr '[:upper:]' '[:lower:]')/influx write --bucket iot --precision s "n v=222 $(date +%s)"
如上我们插入了3条数据,接下来我们查询一下。
查询数据
bin/$(uname -s | tr '[:upper:]' '[:lower:]')/influx query 'from(bucket:"iot") |> range(start:-1h)'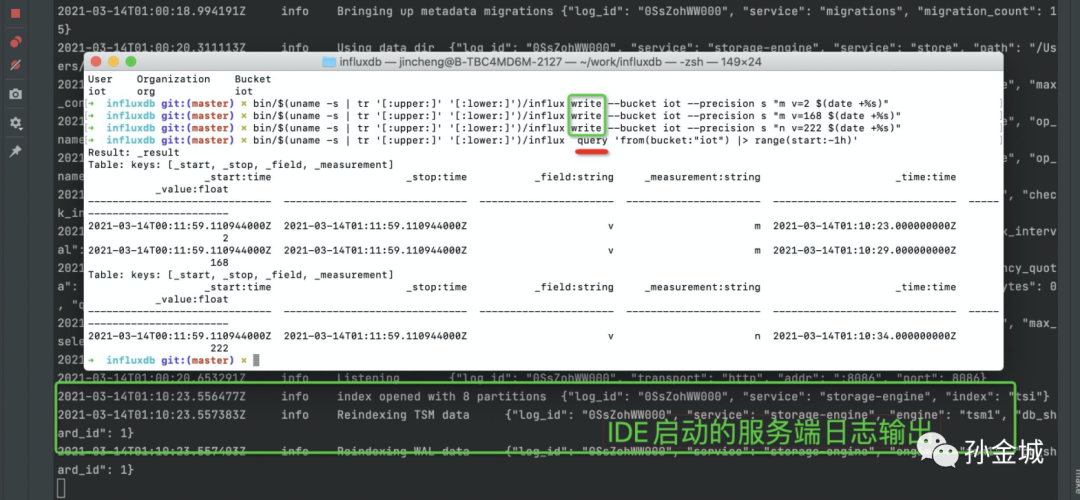
执行之后,我们会查询到刚才插入的数据,同时IDE中调试模式启动的influxd服务也会打印相应的日志信息。
上面是简单查询记录,下面我们在进行一下聚合计算:
bin/$(uname -s | tr '[:upper:]' '[:lower:]')/influx query 'from(bucket:"iot") |> range(start:-1h) |> sum()'
到此,我们InfluxDB的调试模式启动服务,客户端创建bucket,插入数据和查询数据就有了一个直观的印象。
06
—
Flux查询语言
上面我利用influx客户端进行query命令,其实执行的是Flux的查询语言,Flux是influxDB社区提供的新的查询语言,那么Flux是否可以在IDE中进行运行和调试呢?当然!我们对Flux的开发调试环境搭建一下,并且对查询操作进行演示。
下载&编译
git clone https://github.com/influxdata/flux.git...make...go clean -modcache && go mod tidy && go mod vendor
GoLand 运行
我们需要配置flux的命令,为 repl,然后运行,如下:
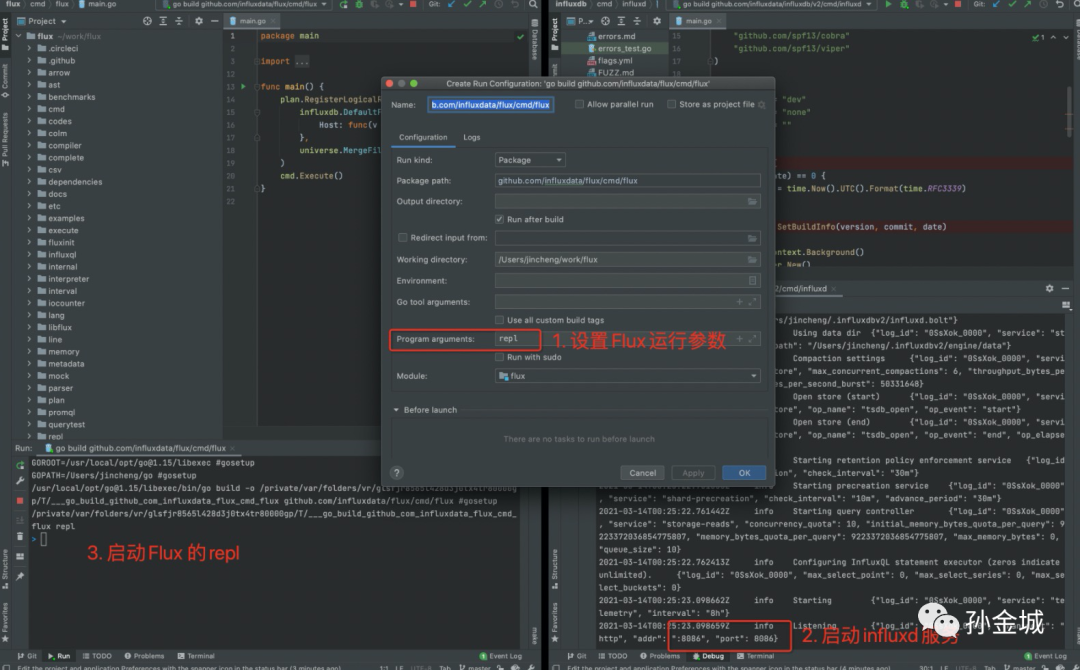
启动repl之后,我们可以进行数据处理操作,如下图:
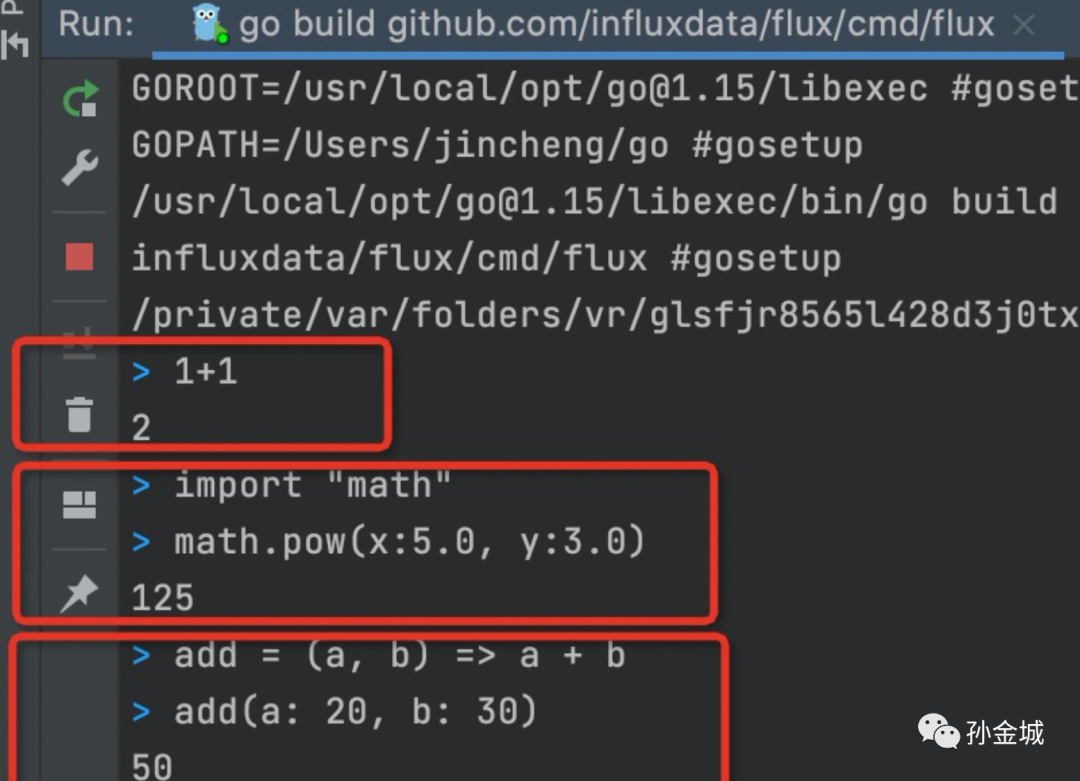
查询数据
Flux可以直接和InfluxDB服务连接,进行数据查询,上面我们在influx客户端输入的查询语句其实就是Flux查询语言,那么我们当然可以在Flux中进行数据查询,我们启动Flux repl,进行查询如下:如下:
import "influxdata/influxdb"data = influxdb.from(bucket:"iot") |> range(start:-1h) |> sum()data |> yield()
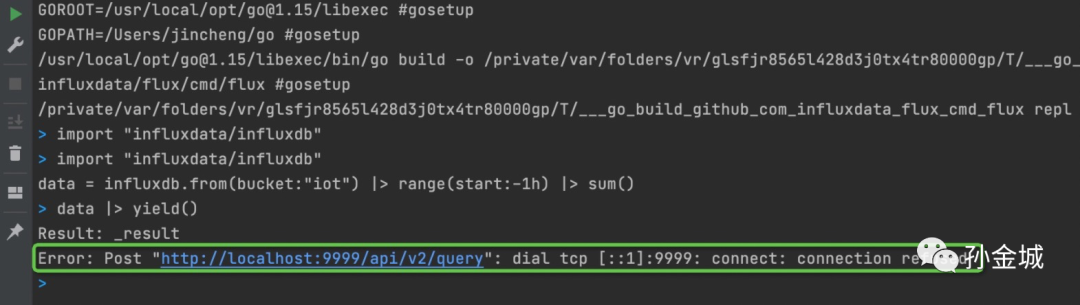
如图,发生了错误,原因是Flux去尝试连接influxdb的9999端口服务,不过我们上面看到我们的服务是监听8086了,所以我们要修改一下默认端口(这就是源码debug的好处了)。
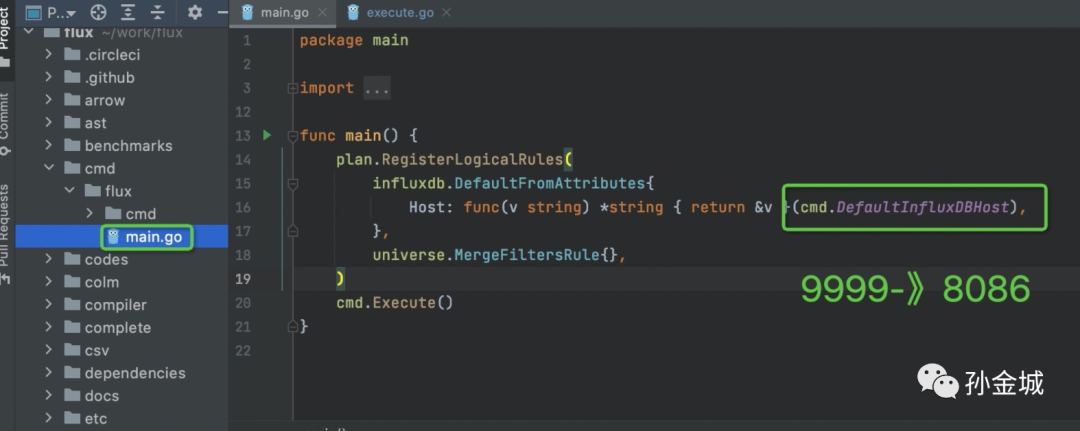
修改端口之后,我们发现连接已经建立,但是权限还有问题,如下:
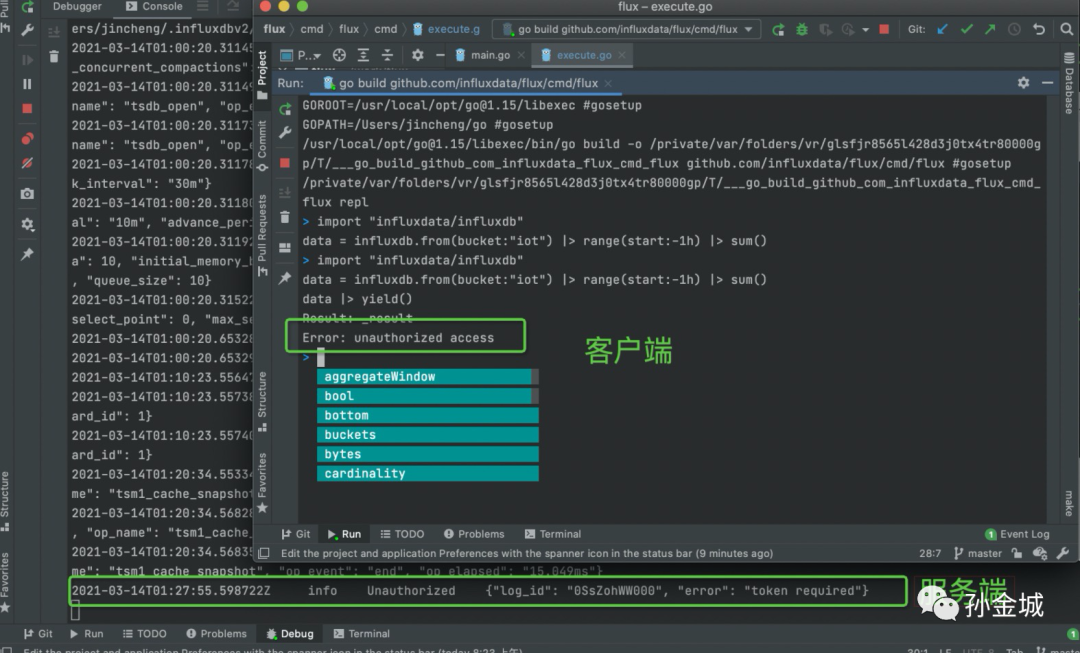
这个就需要我们连接的Token信息,如下:
cat ~/.influxdbv2/configs 
我们读取数据时候携带token和org信息,如下:
import "influxdata/influxdb"data = influxdb.from(bucket:"iot", token:"where-were-going-we-dont-need-roads", org:"org") |> range(start:-1h) |> sum()data |> yield()
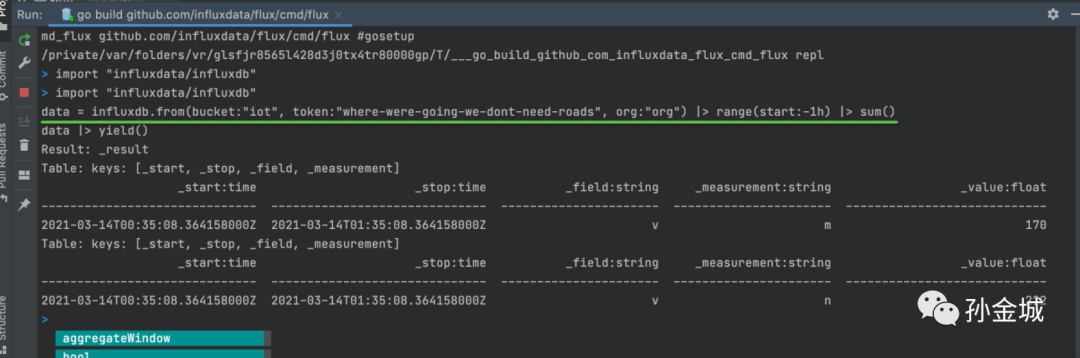
好,到这里我们Flux读取InfluxDB数据部分也有了一个直观的了解。
07
—
InfluxDB&Flux社区贡献
目前看InflxdbV2版本的贡献者并不多,我在源码构建的时候发现的这些默认端口问题都是influx社区待改进的patch,我也提交了相关的PRs。
For InfluxDB: https://github.com/influxdata/influxdb/pull/20809
For Flux: https://github.com/influxdata/flux/pull/3514
BTW:如何贡献社区?见到问题就解决,不以善小而不为!祝你好运!
阿里招聘
时序数据库开发岗位
(P7/P8/P9)
(长期有效)
职位描述:
1. 精通Java/Scala编程
2. 精通常用数据结构和算法应用,具备良好的、精益求精的设计思维,每一个bit都是客户/技术价值。
3. 了解Hadoop/Flink/Spark等计算框架和熟悉HBase/LevelDB/RocksDB等主流NoSQL数据库,深入理解其实现原理和架构优势劣势;
4. 具备分布式系统的设计和应用的经历,能对分布式常用技术进行应用和改进者优先;
5. 有开源社区贡献,并成为Flink/Spark/Druid/OpenTSDB/InfluxDB/IoTDB等社区的Committer/PMC者优先;
6. 要具备良好的团队协作能力,良好的沟通表达能力,和对正确事情持之以恒的韧性和耐力。
来!让我看到你的简历,因为成就你的不仅仅是能力,更是雷厉风行的执行力!