
详解最小编译器the-super-tiny-compiler源码
大厂技术 坚持周更 精选好文
较为系统的了解编译器基本工作流程和原理 了解一种设计模式——访问者模式
前言
在日常前端开发中,经常使用ES6+语法,但碍于用户使用的浏览器各不相同,新语法在旧版本浏览器中不支持,此时我们通常会使用babel将其转换成支持度更为广泛的ES5语法,这种“将不识别的语言转换为可识别的语言”过程就叫「编译」,所使用的工具就是编译器。除了babel,常见的编译器还有gcc等。
如果直接就看babel的源码了解编译器怎么工作的,怕是很多人都会望而却步,好在babel的维护者之一 James Kyle 有一个最小编译器的开源项目 the-super-tiny-compiler[1],截止目前超过21.5k stars。项目去掉注释大约200行代码,代码虽少,但足以展现编译器的很多要点,通过学习这个项目,可以对编译原理有一个较系统的理解。
这个编译器的功能是把Lisp语言风格的函数调用转换成C语言风格(不包含所有语法),比如假设我们有add和subtract两个函数,两种语言的风格如下:
| Lisp风格 | C风格 | |
|---|---|---|
| 2 + 2 | (add 2 2) | add(2, 2) |
| 4 - 2 | (subtract 4 2) | subtract(4, 2) |
| 2 + (4 - 2) | (add 2 (subtract 4 2)) | add(2, subtract(4, 2)) |
工作过程
大多数编译器的过程可以分为三个阶段:解析(parsing)、转换(transformation)和代码生成(code generation):
解析:将原始代码转换为一种高度抽象的表示,通常为抽象语法树(AST); 转换:处理高度抽象的表示,转换成编译器最终希望呈现的表示; 代码生成:将处理后的高度抽象表示,转换为新的代码。
解析
通常解析需要经历两个步骤:词法分析(Lexical Analysis)和语法分析(Syntatic Analysis):
词法分析:将原始代码分割一个个令牌(Token),这些令牌通常由代码语言组成,包含数字、标签、标点符号、运算符等任何表示。分割的工具一般称为词法分析器(Tokenizer) 语法分析:将词法分析的令牌,转换成高度抽象的表示(如抽象语法树,AST),这个表示描述了代码语句中每一个片段以及他们之间的关系。转换的工具一般称为语法分析器(Parser)
接下来我们以(add 2 (subtract 4 2))为例:
词法分析器
词法分析器输出的结果大致如下:
[
{ type: 'paren', value: '(' },
{ type: 'name', value: 'add' },
{ type: 'number', value: '2' },
{ type: 'paren', value: '(' },
{ type: 'name', value: 'subtract' },
{ type: 'number', value: '4' },
{ type: 'number', value: '2' },
{ type: 'paren', value: ')' },
{ type: 'paren', value: ')' },
]
想到得到这样的结果,就需要拆分输入,并进行匹配。
/**
* 词法分析器
* @param input 代码字符串
* @returns token列表
*/
function tokenizer(input) {
// 输入字符串处理的索引
let current = 0;
// token列表
let tokens = [];
// 遍历字符串,解析token
while (current < input.length) {
let char = input[current];
// 匹配左括号
if (char === '(') {
// type 为 'paren',value 为左圆括号的对象
tokens.push({
type: 'paren',
value: '(',
});
// current 自增
current++;
// 结束本次循环,进入下一次循环
continue;
}
// 匹配右括号
if (char === ')') {
// type 为 'paren',value 为右圆括号的对象
tokens.push({
type: 'paren',
value: ')',
});
current++;
continue;
}
let WHITESPACE = /\s/;
// 正则匹配空白字符,跳过空白字符
if (WHITESPACE.test(char)) {
current++;
continue;
}
// 匹配如下数字
// (add 123 456)
// ^^^ ^^^
let NUMBERS = /[0-9]/;
// 正则匹配数字
if (NUMBERS.test(char)) {
let value = '';
// 匹配连续数字,作为value
while (NUMBERS.test(char)) {
value += char;
char = input[++current];
}
// type 为 'number',value 为数字字符串
tokens.push({
type: 'number',
value,
});
continue;
}
// 匹配如下字符串,以""包裹
// (concat "foo" "bar")
// ^^^ ^^^
if (char === '"') {
let value = '';
// 跳过左双引号
char = input[++current];
// 获取双引号之间的所有字符串
while (char !== '"') {
value += char;
char = input[++current];
}
// 跳过右双引号
char = input[++current];
// type 为 'string',value 为字符串参数
tokens.push({
type: 'string',
value,
});
continue;
}
// 匹配函数名
// (add 2 4)
// ^^^
let LETTERS = /[a-z]/i;
// 只包含小写字母
if (LETTERS.test(char)) {
let value = '';
// 获取连续字符
while (LETTERS.test(char)) {
value += char;
char = input[++current];
}
// type 为 'name',value 为函数名
tokens.push({
type: 'name',
value,
});
continue;
}
// 无法识别的字符,抛出错误提示
throw new TypeError(`I dont know what this character is: ${char}`);
}
// 返回词法分析器token列表
return tokens;
}
语法分析器
词法分析完成后,还需要经过语法分析器,将token列表转成如下的抽象语法树(AST):
{
type: 'Program',
body: [
{
type: 'CallExpression',
name: 'add',
params: [
{
type: 'NumberLiteral',
value: '2',
},
{
type: 'CallExpression',
name: 'subtract',
params: [
{
type: 'NumberLiteral',
value: '4',
},
{
type: 'NumberLiteral',
value: '2',
},
],
},
],
},
],
}
语法分析器的实现逻辑如下:
/**
* 语法分析器
* @param {*} tokens token列表
* @returns 抽象语法树 AST
*/
function parser(tokens) {
// token列表索引
let current = 0;
// 采用递归的方式遍历token列表
function walk() {
// 获取当前 token
let token = tokens[current];
// 数字类token
if (token.type === 'number') {
current++;
// 生成 NumberLiteral 节点
return {
type: 'NumberLiteral',
value: token.value,
};
}
// 字符串类token
if (token.type === 'string') {
current++;
// 生成 StringLiteral 节点
return {
type: 'StringLiteral',
value: token.value,
};
}
// 函数名
if (token.type === 'paren' && token.value === '(') {
// 跳过左括号,获取下一个 token 作为函数名
token = tokens[++current];
let node = {
type: 'CallExpression',
name: token.value,
params: [],
};
token = tokens[++current];
// 以前面的词法分析结果为例,有两个右圆括号,表示有嵌套的函数
//
// [
// { type: 'paren', value: '(' },
// { type: 'name', value: 'add' },
// { type: 'number', value: '2' },
// { type: 'paren', value: '(' },
// { type: 'name', value: 'subtract' },
// { type: 'number', value: '4' },
// { type: 'number', value: '2' },
// { type: 'paren', value: ')' }, <<< 右圆括号
// { type: 'paren', value: ')' } <<< 右圆括号
// ]
//
// 遇到嵌套的 `CallExpressions` 时,我们使用 `walk` 函数来增加 `current` 变量
//
// 即右圆括号前的内容就是参数
while (token.type !== 'paren' || (token.type === 'paren' && token.value !== ')')) {
// 递归遍历参数
node.params.push(walk());
token = tokens[current];
}
// 跳过右括号
current++;
return node;
}
// 无法识别的字符,抛出错误提示
throw new TypeError(token.type);
}
// AST的根节点
let ast = {
type: 'Program',
body: [],
};
// 填充ast.body
while (current < tokens.length) {
ast.body.push(walk());
}
// 返回AST
return ast;
}
转换
通过上面的例子可以看到,AST中有许多相似type类型的节点,这些节点包含若干其他属性,用于描述AST的其他信息。当转换AST的时候,我们可以直接添加、移动、替换原始AST上的这些节点(同种语言下的操作),也可以根据原始AST生成一个全新的AST(不同种语言)。
本编译器的目标是两种语言风格之间的转换,故需要生成一个全新的AST。
遍历器
针对AST这类“树状”的结构,可以采用深度优先的方式遍历。以上面的AST为例,遍历过程如下:
Program 类型 - 从 AST 的根节点开始 CallExpression (add) - 进入 Program 节点 body 属性的第一个子元素 NumberLiteral (2) - 进入 CallExpression (add) 节点 params 属性的第一个子元素 CallExpression (subtract) - 进入 CallExpression (add) 节点 params 属性的第二个子元素 NumberLiteral (4) - 进入 CallExpression (subtract) 节点 params 属性的第一个子元素 NumberLiteral (2) - 进入 CallExpression (subtract) 节点 params 属性的第二个子元素
对于本编译器而言,上述的节点类型已经足够,即「访问者」所需要提供的能力已经足够。
访问者对象
通过访问者模式,可以很好地分离行为和数据,实现解耦。在本编译器中,可以创建一个类似下面的“访问者”对象,它能够提供访问各种数据类型的方法。
var visitor = {
NumberLiteral() {},
CallExpression() {},
}
当遍历AST的时,一旦匹配“进入”(enter)到特定类型的节点,就调用访问者提供的方法。同时为了保证访问者能够拿到当前节点信息,我们需要将当前节点和父节点传入。
var visitor = {
NumberLiteral(node, parent) {},
CallExpression(node, parent) {},
}
但是也存在需要退出的情况,还是以上面的AST为例:
- Program
- CallExpression
- NumberLiteral
- CallExpression
- NumberLiteral
- NumberLiteral
当深度遍历的时候,可能会进入叶子节点,此时我们就需要“退出”(exit)这个分支。当我们沿着树深度遍历时,每个节点会存在两种操作,一种是“进入”(enter),一种是“退出”(exit)。
-> Program (enter)
-> CallExpression (enter)
-> Number Literal (enter)
<- Number Literal (exit)
-> Call Expression (enter)
-> Number Literal (enter)
<- Number Literal (exit)
-> Number Literal (enter)
<- Number Literal (exit)
<- CallExpression (exit)
<- CallExpression (exit)
<- Program (exit)
为了满足这样的操作,就需要继续改造访问者对象,最终大致如下:
const visitor = {
NumberLiteral: {
enter(node, parent) {},
exit(node, parent) {},
},
CallExpression: {
enter(node, parent) {},
exit(node, parent) {},
},
};
转换器
结合上述遍历器和访问者对象的描述,转换函数大致如下:
/**
* 遍历器
* @param {*} ast 语法抽象树
* @param {*} visitor 访问者对象
*/
function traverser(ast, visitor) {
// 遍历数组中的节点
function traverseArray(array, parent) {
array.forEach(child => {
traverseNode(child, parent);
});
}
// 遍历节点,参数为当前节点及其父节点
function traverseNode(node, parent) {
// 获取访问者对象上对应的方法
let methods = visitor[node.type];
// 执行访问者的 enter 方法
if (methods && methods.enter) {
methods.enter(node, parent);
}
switch (node.type) {
// 根节点
case 'Program':
traverseArray(node.body, node);
break;
// 函数调用
case 'CallExpression':
traverseArray(node.params, node);
break;
// 数值和字符串,不用处理
case 'NumberLiteral':
case 'StringLiteral':
break;
// 无法识别的字符,抛出错误提示
default:
throw new TypeError(node.type);
}
if (methods && methods.exit) {
methods.exit(node, parent);
}
}
// 开始遍历
traverseNode(ast, null);
}
/**
* 转换器
* @param {*} ast 抽象语法树
* @returns 新AST
*/
function transformer(ast) {
// 创建一个新 AST
let newAst = {
type: 'Program',
body: [],
};
// 通过 _context 引用,更新新旧节点
ast._context = newAst.body;
// 使用遍历器遍历原始 AST
traverser(ast, {
// 数字节点,直接原样插入新AST
NumberLiteral: {
enter(node, parent) {
parent._context.push({
type: 'NumberLiteral',
value: node.value,
});
},
},
// 字符串节点,直接原样插入新AST
StringLiteral: {
enter(node, parent) {
parent._context.push({
type: 'StringLiteral',
value: node.value,
});
},
},
// 函数调用
CallExpression: {
enter(node, parent) {
// 创建不同的AST节点
let expression = {
type: 'CallExpression',
callee: {
type: 'Identifier',
name: node.name,
},
arguments: [],
};
// 同样通过 _context 引用参数,供子节点使用
node._context = expression.arguments;
// 顶层函数调用本质上是一个语句,写成特殊节点 `ExpressionStatement`
if (parent.type !== 'CallExpression') {
expression = {
type: 'ExpressionStatement',
expression,
};
}
parent._context.push(expression);
},
},
});
return newAst;
}
(add 2 (subtract 4 2))的 AST 经过该转换器之后,就转变成下面的新 AST :
{
type: 'Program',
body: [
{
type: 'ExpressionStatement',
expression: {
type: 'CallExpression',
callee: {
type: 'Identifier',
name: 'add',
},
arguments: [
{
type: 'NumberLiteral',
value: '2',
},
{
type: 'CallExpression',
callee: {
type: 'Identifier',
name: 'subtract',
},
arguments: [
{
type: 'NumberLiteral',
value: '4',
},
{
type: 'NumberLiteral',
value: '2',
},
],
},
],
},
},
],
};
代码生成
有时候这个阶段的工作会和转换阶段有重叠,但一般而言主要还是根据AST输出对应代码。
代码生成有几种不同的方式,有些编译器会复用之前的token,有些会创建对立的代码表示,以便于线性输出代码。
代码生成器需要知道如何“打印”AST中所有类型的节点,然后递归调用自身,直到遍历完AST,所有代码转换成字符串。
/**
* 代码生成器
* @param {*} node AST 中的 body 节点
* @returns 代码字符串
*/
function codeGenerator(node) {
// 判断节点类型
switch (node.type) {
// 根节点,递归 body 节点列表
case 'Program':
return node.body.map(codeGenerator).join('\n');
// 表达式,处理表达式内容,以分好结尾
case 'ExpressionStatement':
return `${codeGenerator(node.expression)};`;
// 函数调用,添加左右括号,参数用逗号隔开
case 'CallExpression':
return `${codeGenerator(node.callee)}(${node.arguments.map(codeGenerator).join(', ')})`;
// 标识符,数值,直接输出
case 'Identifier':
return node.name;
case 'NumberLiteral':
return node.value;
// 字符串,用双引号包起来
case 'StringLiteral':
return `"${node.value}"`;
// 无法识别的字符,抛出错误提示
default:
throw new TypeError(node.type);
}
}
编译器
上述流程就是编译器工作的三个基本步骤就是如下:
输入字符 -> 词法分析 -> 令牌(Token) -> 语法分析 -> 抽象语法树(AST) 抽象语法树(AST)-> 转换器 -> 新AST 新AST -> 代码生成器 -> 输出字符
/**
* 编译器
* @param {*} input 代码字符串
* @returns 代码字符串
*/
function compiler(input) {
let tokens = tokenizer(input);
let ast = parser(tokens);
let newAst = transformer(ast);
let output = codeGenerator(newAst);
return output;
}

虽然不同编译器的目的不同,步骤会有些许区别,但万变不离其宗,以上基本能让读者对编译器有个较为系统的认识。
拓展
polyfill
babel是一个编译器,默认只用于转换js语法,而不会转换新语法提供的API,比如Promise、Generator等,此时我们就需要使用polyfill来兼容这些新语法,其工作原理大致如下:
(function (window) {
if (window.incompatibleFeature) {
return window.incompatibleFeature;
} else {
window.incompatibleFeature = function () {
// 兼容代码
};
}
})(window);
访问者模式
定义
表示一个作用于某对象结构中的各元素的操作。它使你可以在不改变各元素类的前提下定义作用于这些元素的新操作。本质是将行为与数据解耦,根据访问者不同,所展示的行为也不同。
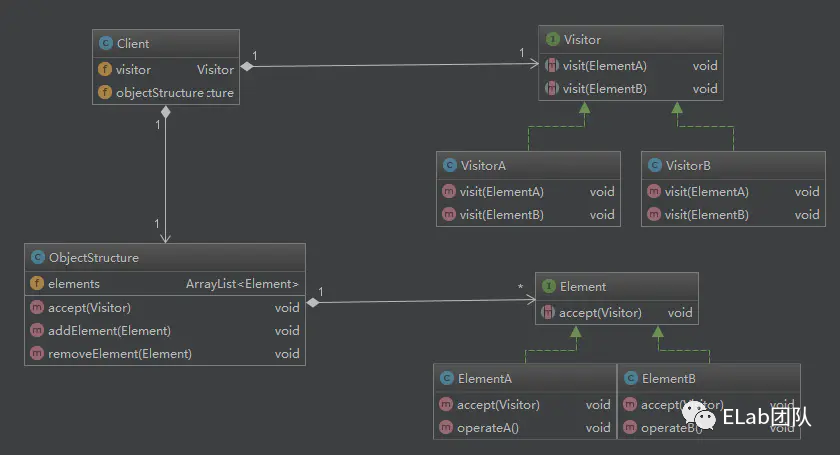
Visitor: 接口或者抽象类,定义了对每个 Element 访问的行为,它的参数就是被访问的元素,它的方法个数理论上与元素的个数是一样的,因此,访问者模式要求元素的类型要稳定,如果经常添加、移除元素类,必然会导致频繁地修改 Visitor 接口,如果出现这种情况,则说明不适合使用访问者模式。 ConcreteVisitor: 具体的访问者,它需要给出对每一个元素类访问时所产生的具体行为。 Element: 元素接口或者抽象类,它定义了一个接受访问者(accept)的方法,其意义是指每一个元素都要可以被访问者访问。 ElementA、ElementB: 具体的元素类,它提供接受访问的具体实现,而这个具体的实现,通常情况下是使用访问者提供的访问该元素类的方法。 ObjectStructure: 定义当中所提到的对象结构,对象结构是一个抽象表述,它内部管理了元素集合,并且可以迭代这些元素提供访问者访问。
例子
编译器中使用的是“访问者对象”,下面以“访问者类”为例:
定义一组设备
class Keyboard {
accept(computerPartVisitor) {
computerPartVisitor.visit(this);
}
}
class Monitor {
accept(computerPartVisitor) {
computerPartVisitor.visit(this);
}
}
class Mouse {
accept(computerPartVisitor) {
computerPartVisitor.visit(this);
}
}
定义电脑为一种设备,同时集成了其他设备
class Computer {
constructor(){
this.parts = [new Mouse(), new Keyboard(), new Monitor()];
}
accept(computerPartVisitor) {
for (let i = 0; i < this.parts.length; i++) {
this.parts[i].accept(computerPartVisitor);
}
computerPartVisitor.visit(this);
}
}
定义访问者接口
class ComputerPartDisplayVisitor{
visit(device) {
console.log(`Displaying ${device.constructor.name}.`);
}
}
在使用的时候都只需要用设备接受新的访问者即可实现对应访问者的功能
const computer = new Computer();
computer.accept(new ComputerPartDisplayVisitor());
/**
* output:
* Displaying Mouse.
* Displaying Keyboard.
* Displaying Monitor.
* Displaying Computer.
*/
优点
符合单一职责原则:凡是适用访问者模式的场景中,元素类中需要封装在访问者中的操作必定是与元素类本身关系不大且是易变的操作,使用访问者模式一方面符合单一职责原则,另一方面,因为被封装的操作通常来说都是易变的,所以当发生变化时,就可以在不改变元素类本身的前提下,实现对变化部分的扩展。 扩展性良好:元素类可以通过接受不同的访问者来实现对不同操作的扩展。 使得数据结构和作用于结构上的操作解耦,使得操作集合可以独立变化。
适用情况
对象结构比较稳定,但经常需要在此对象结构上定义新的操作。 需要对一个对象结构中的对象进行很多不同的并且不相关的操作,而需要避免这些操作“污染”这些对象的类,也不希望在增加新操作时修改这些类。
参考文档
https://github.com/jamiebuilds/the-super-tiny-compiler
有史以来最小的编译器源码解析[2]
https://developer.51cto.com/art/202106/668215.htm
访问者模式一篇就够了[3]
参考资料
the-super-tiny-compiler: https://github.com/jamiebuilds/the-super-tiny-compiler
[2]有史以来最小的编译器源码解析: https://segmentfault.com/a/1190000016402699
[3]访问者模式一篇就够了: https://www.jianshu.com/p/1f1049d0a0f4
❤️ 谢谢支持
以上便是本次分享的全部内容,希望对你有所帮助^_^
喜欢的话别忘了 分享、点赞、收藏 三连哦~。
欢迎关注公众号 全栈前端精选 收货大厂一手好文章~
我们来自字节跳动,是旗下大力教育前端部门,负责字节跳动教育全线产品前端开发工作。
我们围绕产品品质提升、开发效率、创意与前沿技术等方向沉淀与传播专业知识及案例,为业界贡献经验价值。包括但不限于性能监控、组件库、多端技术、Serverless、可视化搭建、音视频、人工智能、产品设计与营销等内容。
欢迎感兴趣的同学在评论区或使用内推码内推到作者部门拍砖哦 🤪
字节跳动校/社招投递链接: https://job.toutiao.com/s/YSqdt8q
内推码:5UJF23C

不可多得的 Babel 小抄

深入对比 eslint 插件 和 babel 插件的异同点

《从 0 到 1 手写 babel》思路分享