
Spark数据倾斜问题解决方案全面总结
摘要
本文结合实例详细阐明了Spark数据倾斜的几种场景以及对应的解决方案,包括避免数据源倾斜,调整并行度,使用自定义Partitioner,使用Map侧Join代替Reduce侧Join,给倾斜Key加上随机前缀等。
为何要处理数据倾斜(Data Skew)
什么是数据倾斜
对Spark/Hadoop这样的大数据系统来讲,数据量大并不可怕,可怕的是数据倾斜。
何谓数据倾斜?数据倾斜指的是,并行处理的数据集中,某一部分(如Spark或Kafka的一个Partition)的数据显著多于其它部分,从而使得该部分的处理速度成为整个数据集处理的瓶颈。
对于分布式系统而言,理想情况下,随着系统规模(节点数量)的增加,应用整体耗时线性下降。如果一台机器处理一批大量数据需要120分钟,当机器数量增加到三时,理想的耗时为120 / 3 = 40分钟,如下图所示

但是,上述情况只是理想情况,实际上将单机任务转换成分布式任务后,会有overhead,使得总的任务量较之单机时有所增加,所以每台机器的执行时间加起来比单台机器时更大。这里暂不考虑这些overhead,假设单机任务转换成分布式任务后,总任务量不变。 但即使如此,想做到分布式情况下每台机器执行时间是单机时的1 / N,就必须保证每台机器的任务量相等。不幸的是,很多时候,任务的分配是不均匀的,甚至不均匀到大部分任务被分配到个别机器上,其它大部分机器所分配的任务量只占总得的小部分。比如一台机器负责处理80%的任务,另外两台机器各处理10%的任务,如下图所示
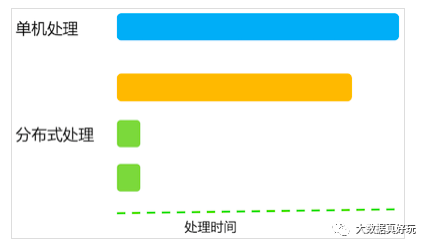
在上图中,机器数据增加为三倍,但执行时间只降为原来的80%,远低于理想值。
数据倾斜的危害
从上图可见,当出现数据倾斜时,小量任务耗时远高于其它任务,从而使得整体耗时过大,未能充分发挥分布式系统的并行计算优势。 另外,当发生数据倾斜时,部分任务处理的数据量过大,可能造成内存不足使得任务失败,并进而引进整个应用失败。
数据倾斜是如何造成的
在Spark中,同一个Stage的不同Partition可以并行处理,而具有依赖关系的不同Stage之间是串行处理的。假设某个Spark Job分为Stage 0和Stage 1两个Stage,且Stage 1依赖于Stage 0,那Stage 0完全处理结束之前不会处理Stage 1。而Stage 0可能包含N个Task,这N个Task可以并行进行。如果其中N-1个Task都在10秒内完成,而另外一个Task却耗时1分钟,那该Stage的总时间至少为1分钟。换句话说,一个Stage所耗费的时间,主要由最慢的那个Task决定。
由于同一个Stage内的所有Task执行相同的计算,在排除不同计算节点计算能力差异的前提下,不同Task之间耗时的差异主要由该Task所处理的数据量决定。
Stage的数据来源主要分为如下两类
从数据源直接读取。如读取HDFS,Kafka
读取上一个Stage的Shuffle数据
如何缓解/消除数据倾斜
避免数据源的数据倾斜 ———— 读Kafka
以Spark Stream通过DirectStream方式读取Kafka数据为例。由于Kafka的每一个Partition对应Spark的一个Task(Partition),所以Kafka内相关Topic的各Partition之间数据是否平衡,直接决定Spark处理该数据时是否会产生数据倾斜。
如《Kafka设计解析(一)- Kafka背景及架构介绍》一文所述,Kafka某一Topic内消息在不同Partition之间的分布,主要由Producer端所使用的Partition实现类决定。如果使用随机Partitioner,则每条消息会随机发送到一个Partition中,从而从概率上来讲,各Partition间的数据会达到平衡。此时源Stage(直接读取Kafka数据的Stage)不会产生数据倾斜。
但很多时候,业务场景可能会要求将具备同一特征的数据顺序消费,此时就需要将具有相同特征的数据放于同一个Partition中。一个典型的场景是,需要将同一个用户相关的PV信息置于同一个Partition中。此时,如果产生了数据倾斜,则需要通过其它方式处理。
避免数据源的数据倾斜 ———— 读文件
原理
Spark以通过textFile(path, minPartitions)方法读取文件时,使用TextFileFormat。
对于不可切分的文件,每个文件对应一个Split从而对应一个Partition。此时各文件大小是否一致,很大程度上决定了是否存在数据源侧的数据倾斜。另外,对于不可切分的压缩文件,即使压缩后的文件大小一致,它所包含的实际数据量也可能差别很多,因为源文件数据重复度越高,压缩比越高。反过来,即使压缩文件大小接近,但由于压缩比可能差距很大,所需处理的数据量差距也可能很大。
此时可通过在数据生成端将不可切分文件存储为可切分文件,或者保证各文件包含数据量相同的方式避免数据倾斜。
对于可切分的文件,每个Split大小由如下算法决定。其中goalSize等于所有文件总大小除以minPartitions。而blockSize,如果是HDFS文件,由文件本身的block大小决定;如果是Linux本地文件,且使用本地模式,由fs.local.block.size决定。
protected long computeSplitSize(long goalSize, long minSize, long blockSize) {
return Math.max(minSize, Math.min(goalSize, blockSize));
}
默认情况下各Split的大小不会太大,一般相当于一个Block大小(在Hadoop 2中,默认值为128MB),所以数据倾斜问题不明显。如果出现了严重的数据倾斜,可通过上述参数调整。
案例
现通过脚本生成一些文本文件,并通过如下代码进行简单的单词计数。为避免Shuffle,只计单词总个数,不须对单词进行分组计数。
SparkConf sparkConf = new SparkConf()
.setAppName("ReadFileSkewDemo");
JavaSparkContext javaSparkContext = new JavaSparkContext(sparkConf);
long count = javaSparkContext.textFile(inputFile, minPartitions)
.flatMap((String line) -> Arrays.asList(line.split(" ")).iterator()).count();
System.out.printf("total words : %s", count);
javaSparkContext.stop();
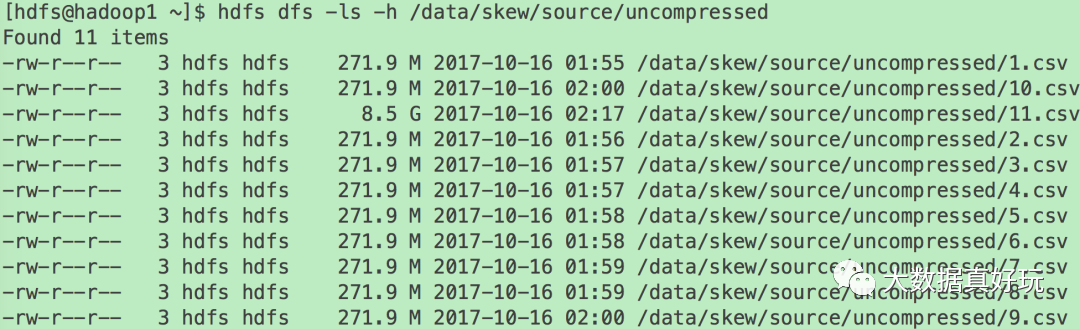
总共生成如下11个csv文件,其中10个大小均为271.9MB,另外一个大小为8.5GB。
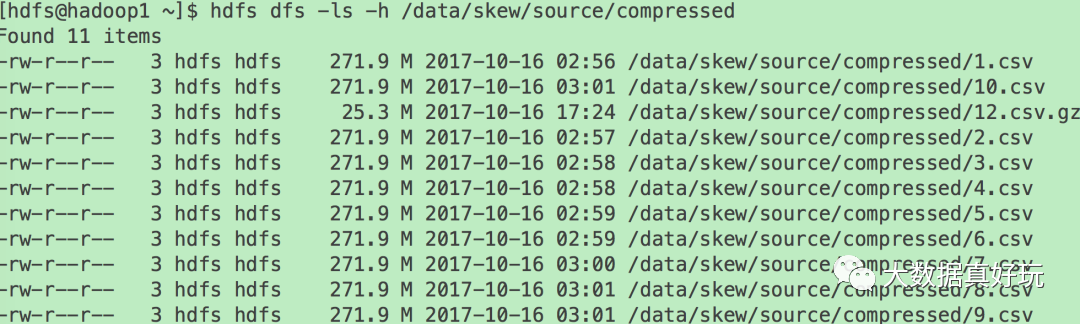
之后将8.5GB大小的文件使用gzip压缩,压缩后大小仅为25.3MB。
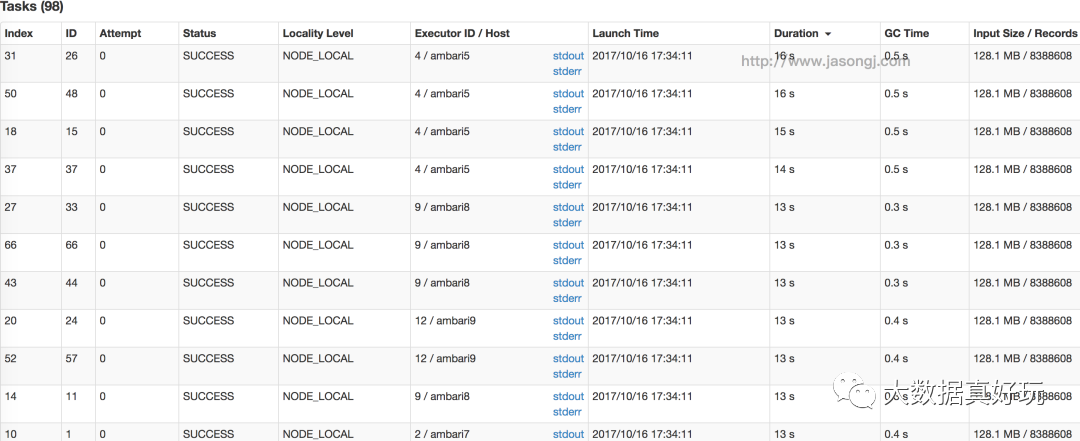
使用如上代码对未压缩文件夹进行单词计数操作。Split大小为 max(minSize, min(goalSize, blockSize) = max(1 B, min((271.9 10+8.5 1024) / 1 MB, 128 MB) = 128MB。无明显数据倾斜。
使用同样代码对包含压缩文件的文件夹进行同样的单词计数操作。未压缩文件的Split大小仍然为128MB,而压缩文件(gzip压缩)由于不可切分,且大小仅为25.3MB,因此该文件作为一个单独的Split/Partition。虽然该文件相对较小,但是它由8.5GB文件压缩而来,包含数据量是其它未压缩文件的32倍,因此处理该Split/Partition/文件的Task耗时为4.4分钟,远高于其它Task的10秒。
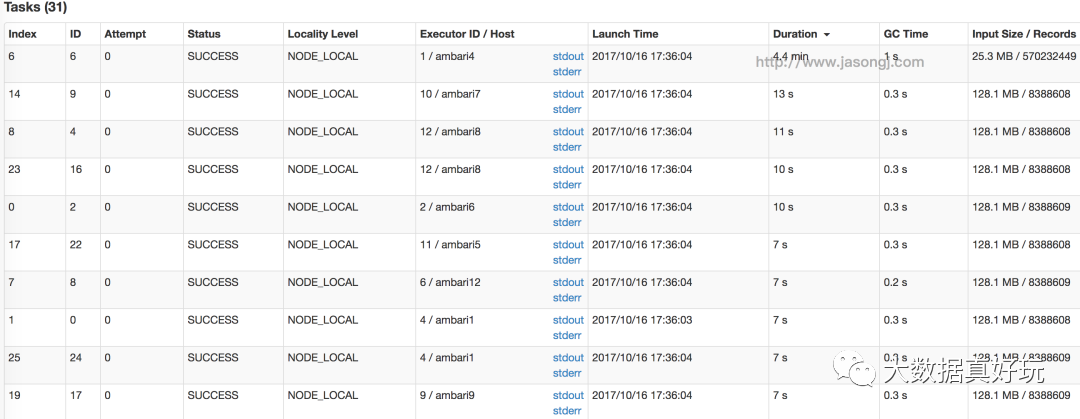
由于上述gzip压缩文件大小为25.3MB,小于128MB的Split大小,不能证明gzip压缩文件不可切分。现将minPartitions从默认的1设置为229,从而目标Split大小为max(minSize, min(goalSize, blockSize) = max(1 B, min((271.9 * 10+25.3) / 229 MB, 128 MB) = 12 MB。如果gzip压缩文件可切分,则所有Split/Partition大小都不会远大于12。反之,如果仍然存在25.3MB的Partition,则说明gzip压缩文件确实不可切分,在生成不可切分文件时需要如上文所述保证各文件数量大大致相同。
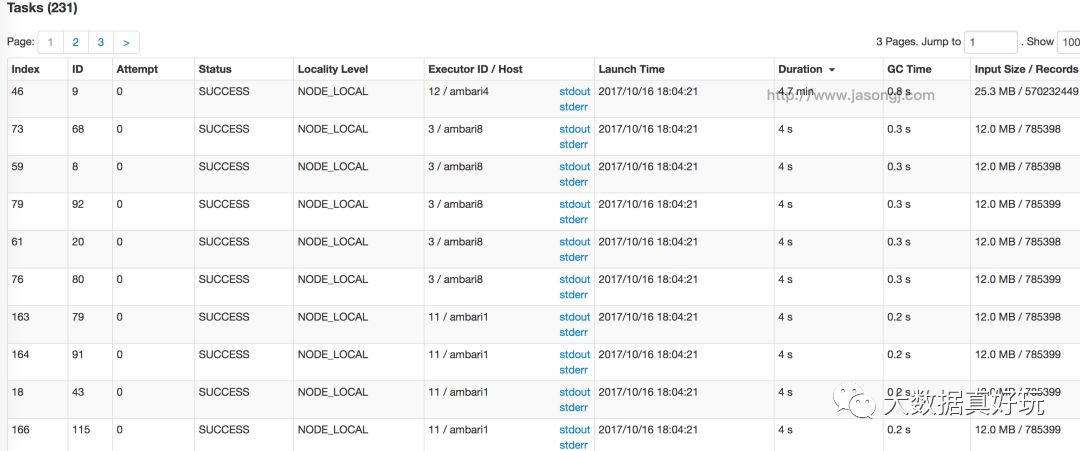
如下图所示,gzip压缩文件对应的Split/Partition大小为25.3MB,其它Split大小均为12MB左右。而该Task耗时4.7分钟,远大于其它Task的4秒。
总结
适用场景 数据源侧存在不可切分文件,且文件内包含的数据量相差较大。
解决方案 尽量使用可切分的格式代替不可切分的格式,或者保证各文件实际包含数据量大致相同。
优势 可撤底消除数据源侧数据倾斜,效果显著。
劣势 数据源一般来源于外部系统,需要外部系统的支持。
调整并行度分散同一个Task的不同Key
原理
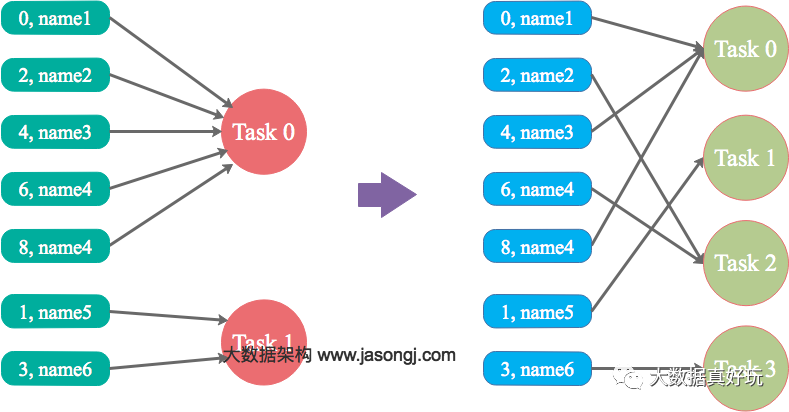
Spark在做Shuffle时,默认使用HashPartitioner(非Hash Shuffle)对数据进行分区。如果并行度设置的不合适,可能造成大量不相同的Key对应的数据被分配到了同一个Task上,造成该Task所处理的数据远大于其它Task,从而造成数据倾斜。
如果调整Shuffle时的并行度,使得原本被分配到同一Task的不同Key发配到不同Task上处理,则可降低原Task所需处理的数据量,从而缓解数据倾斜问题造成的短板效应。
案例
现有一张测试表,名为student_external,内有10.5亿条数据,每条数据有一个唯一的id值。现从中取出id取值为9亿到10.5亿的共1.5亿条数据,并通过一些处理,使得id为9亿到9.4亿间的所有数据对12取模后余数为8(即在Shuffle并行度为12时该数据集全部被HashPartition分配到第8个Task),其它数据集对其id除以100取整,从而使得id大于9.4亿的数据在Shuffle时可被均匀分配到所有Task中,而id小于9.4亿的数据全部分配到同一个Task中。处理过程如下
INSERT OVERWRITE TABLE test
SELECT CASE WHEN id < 940000000 THEN (9500000 + (CAST (RAND() * 8 AS INTEGER)) * 12 )
ELSE CAST(id/100 AS INTEGER)
END,
name
FROM student_external
WHERE id BETWEEN 900000000 AND 1050000000;
通过上述处理,一份可能造成后续数据倾斜的测试数据即以准备好。接下来,使用Spark读取该测试数据,并通过groupByKey(12)对id分组处理,且Shuffle并行度为12。代码如下
public class SparkDataSkew {
public static void main(String[] args) {
SparkSession sparkSession = SparkSession.builder()
.appName("SparkDataSkewTunning")
.config("hive.metastore.uris", "thrift://hadoop1:9083")
.enableHiveSupport()
.getOrCreate();
Dataset<Row> dataframe = sparkSession.sql( "select * from test");
dataframe.toJavaRDD()
.mapToPair((Row row) -> new Tuple2<Integer, String>(row.getInt(0),row.getString(1)))
.groupByKey(12)
.mapToPair((Tuple2<Integer, Iterable<String>> tuple) -> {
int id = tuple._1();
AtomicInteger atomicInteger = new AtomicInteger(0);
tuple._2().forEach((String name) -> atomicInteger.incrementAndGet());
return new Tuple2<Integer, Integer>(id, atomicInteger.get());
}).count();
sparkSession.stop();
sparkSession.close();
}
}
本次实验所使用集群节点数为4,每个节点可被Yarn使用的CPU核数为16,内存为16GB。使用如下方式提交上述应用,将启动4个Executor,每个Executor可使用核数为12(该配置并非生产环境下的最优配置,仅用于本文实验),可用内存为12GB。
spark-submit --queue ambari --num-executors 4 --executor-cores 12 --executor-memory 12g --class com.jasongj.spark.driver.SparkDataSkew --master yarn --deploy-mode client SparkExample-with-dependencies-1.0.jar
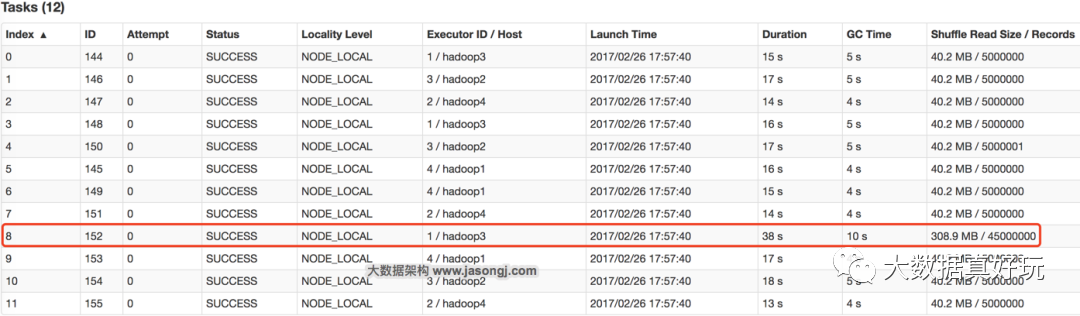
GroupBy Stage的Task状态如下图所示,Task 8处理的记录数为4500万,远大于(9倍于)其它11个Task处理的500万记录。而Task 8所耗费的时间为38秒,远高于其它11个Task的平均时间(16秒)。整个Stage的时间也为38秒,该时间主要由最慢的Task 8决定。
在这种情况下,可以通过调整Shuffle并行度,使得原来被分配到同一个Task(即该例中的Task 8)的不同Key分配到不同Task,从而降低Task 8所需处理的数据量,缓解数据倾斜。
通过groupByKey(48)将Shuffle并行度调整为48,重新提交到Spark。新的Job的GroupBy Stage所有Task状态如下图所示。
从上图可知,记录数最多的Task 20处理的记录数约为1125万,相比于并行度为12时Task 8的4500万,降低了75%左右,而其耗时从原来Task 8的38秒降到了24秒。
在这种场景下,调整并行度,并不意味着一定要增加并行度,也可能是减小并行度。如果通过groupByKey(11)将Shuffle并行度调整为11,重新提交到Spark。新Job的GroupBy Stage的所有Task状态如下图所示。
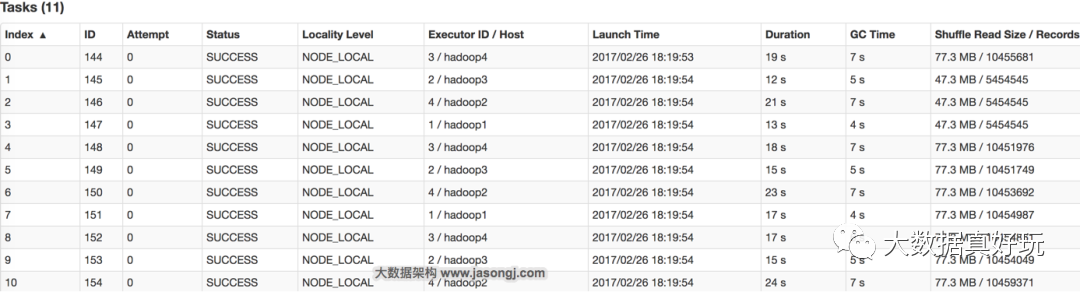
从上图可见,处理记录数最多的Task 6所处理的记录数约为1045万,耗时为23秒。处理记录数最少的Task 1处理的记录数约为545万,耗时12秒。
总结
适用场景 大量不同的Key被分配到了相同的Task造成该Task数据量过大。
解决方案 调整并行度。一般是增大并行度,但有时如本例减小并行度也可达到效果。
优势 实现简单,可在需要Shuffle的操作算子上直接设置并行度或者使用spark.default.parallelism设置。如果是Spark SQL,还可通过SET spark.sql.shuffle.partitions=[num_tasks]设置并行度。可用最小的代价解决问题。一般如果出现数据倾斜,都可以通过这种方法先试验几次,如果问题未解决,再尝试其它方法。
劣势 适用场景少,只能将分配到同一Task的不同Key分散开,但对于同一Key倾斜严重的情况该方法并不适用。并且该方法一般只能缓解数据倾斜,没有彻底消除问题。从实践经验来看,其效果一般。
自定义Partitioner
原理
使用自定义的Partitioner(默认为HashPartitioner),将原本被分配到同一个Task的不同Key分配到不同Task。
案例
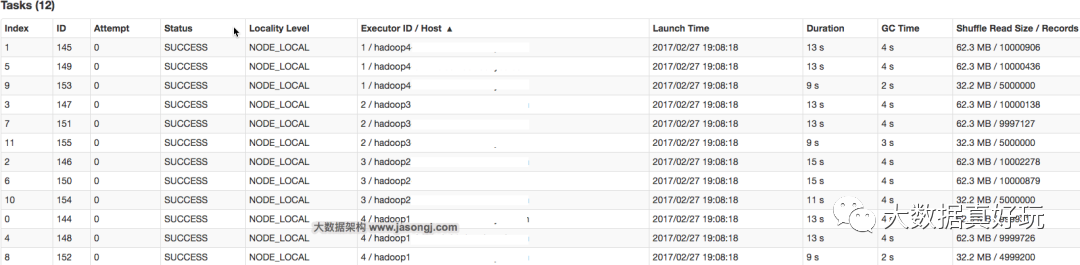
以上述数据集为例,继续将并发度设置为12,但是在groupByKey算子上,使用自定义的Partitioner(实现如下)
.groupByKey(new Partitioner() {
@Override
public int numPartitions() {
return 12;
}
@Override
public int getPartition(Object key) {
int id = Integer.parseInt(key.toString());
if(id >= 9500000 && id <= 9500084 && ((id - 9500000) % 12) == 0) {
return (id - 9500000) / 12;
} else {
return id % 12;
}
}
})
由下图可见,使用自定义Partition后,耗时最长的Task 6处理约1000万条数据,用时15秒。并且各Task所处理的数据集大小相当。
总结
适用场景 大量不同的Key被分配到了相同的Task造成该Task数据量过大。
解决方案 使用自定义的Partitioner实现类代替默认的HashPartitioner,尽量将所有不同的Key均匀分配到不同的Task中。
优势 不影响原有的并行度设计。如果改变并行度,后续Stage的并行度也会默认改变,可能会影响后续Stage。
劣势 适用场景有限,只能将不同Key分散开,对于同一Key对应数据集非常大的场景不适用。效果与调整并行度类似,只能缓解数据倾斜而不能完全消除数据倾斜。而且需要根据数据特点自定义专用的Partitioner,不够灵活。
将Reduce side Join转变为Map side Join
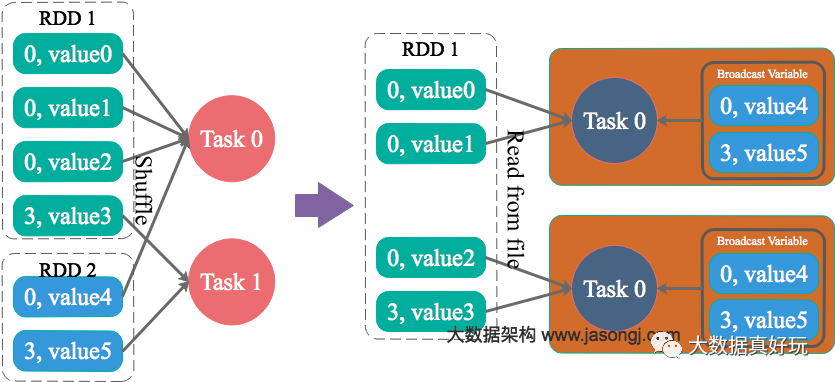
原理 通过Spark的Broadcast机制,将Reduce侧Join转化为Map侧Join,避免Shuffle从而完全消除Shuffle带来的数据倾斜。
案例
通过如下SQL创建一张具有倾斜Key且总记录数为1.5亿的大表test。
INSERT OVERWRITE TABLE test
SELECT CAST(CASE WHEN id < 980000000 THEN (95000000 + (CAST (RAND() * 4 AS INT) + 1) * 48 )
ELSE CAST(id/10 AS INT) END AS STRING),
name
FROM student_external
WHERE id BETWEEN 900000000 AND 1050000000;
使用如下SQL创建一张数据分布均匀且总记录数为50万的小表test_new。
INSERT OVERWRITE TABLE test_new
SELECT CAST(CAST(id/10 AS INT) AS STRING),
name
FROM student_delta_external
WHERE id BETWEEN 950000000 AND 950500000;
直接通过Spark Thrift Server提交如下SQL将表test与表test_new进行Join并将Join结果存于表test_join中。
INSERT OVERWRITE TABLE test_join
SELECT test_new.id, test_new.name
FROM test
JOIN test_new
ON test.id = test_new.id;
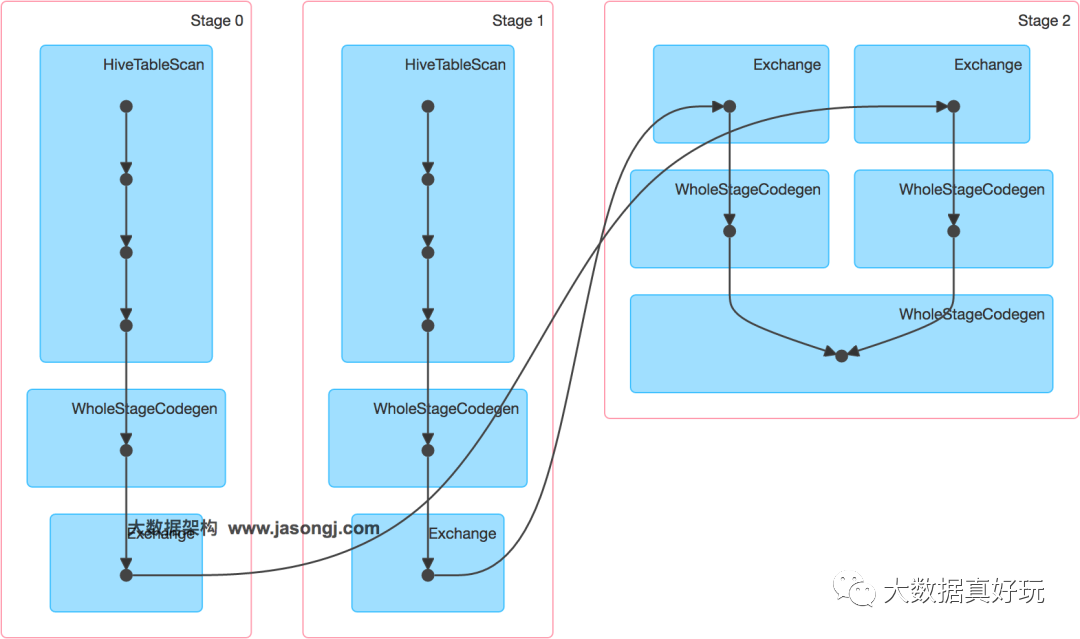
该SQL对应的DAG如下图所示。从该图可见,该执行过程总共分为三个Stage,前两个用于从Hive中读取数据,同时二者进行Shuffle,通过最后一个Stage进行Join并将结果写入表test_join中。
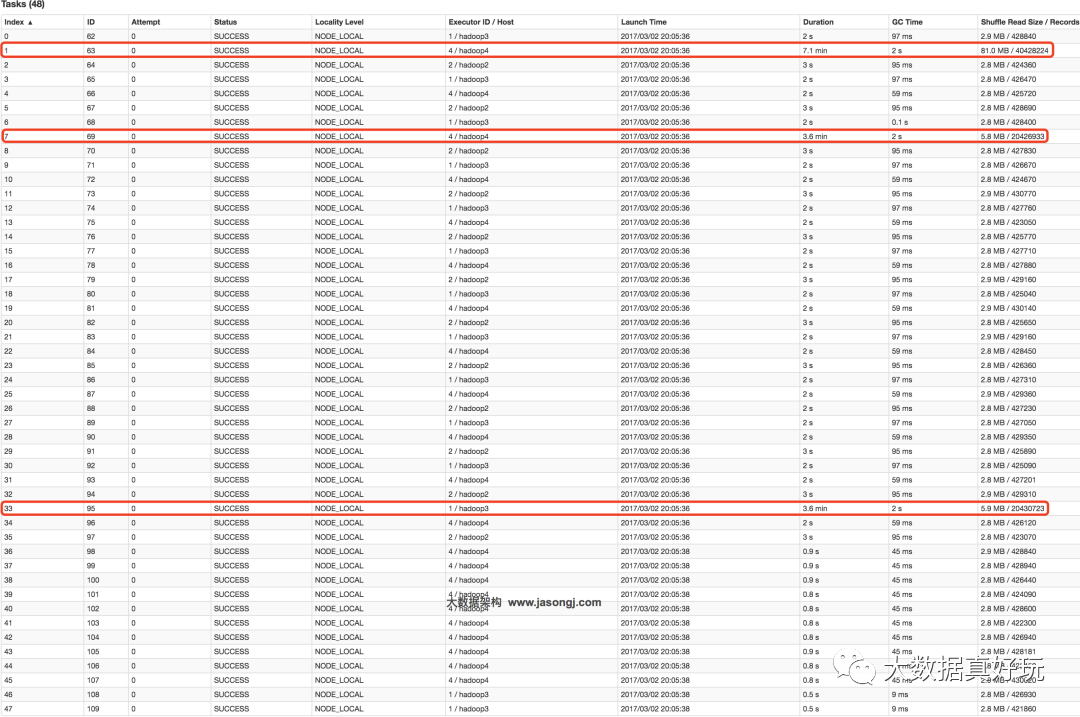
从下图可见,Join Stage各Task处理的数据倾斜严重,处理数据量最大的Task耗时7.1分钟,远高于其它无数据倾斜的Task约2秒的耗时。
接下来,尝试通过Broadcast实现Map侧Join。实现Map侧Join的方法,并非直接通过CACHE TABLE test_new将小表test_new进行cache。现通过如下SQL进行Join。
CACHE TABLE test_new;
INSERT OVERWRITE TABLE test_join
SELECT test_new.id, test_new.name
FROM test
JOIN test_new
ON test.id = test_new.id;
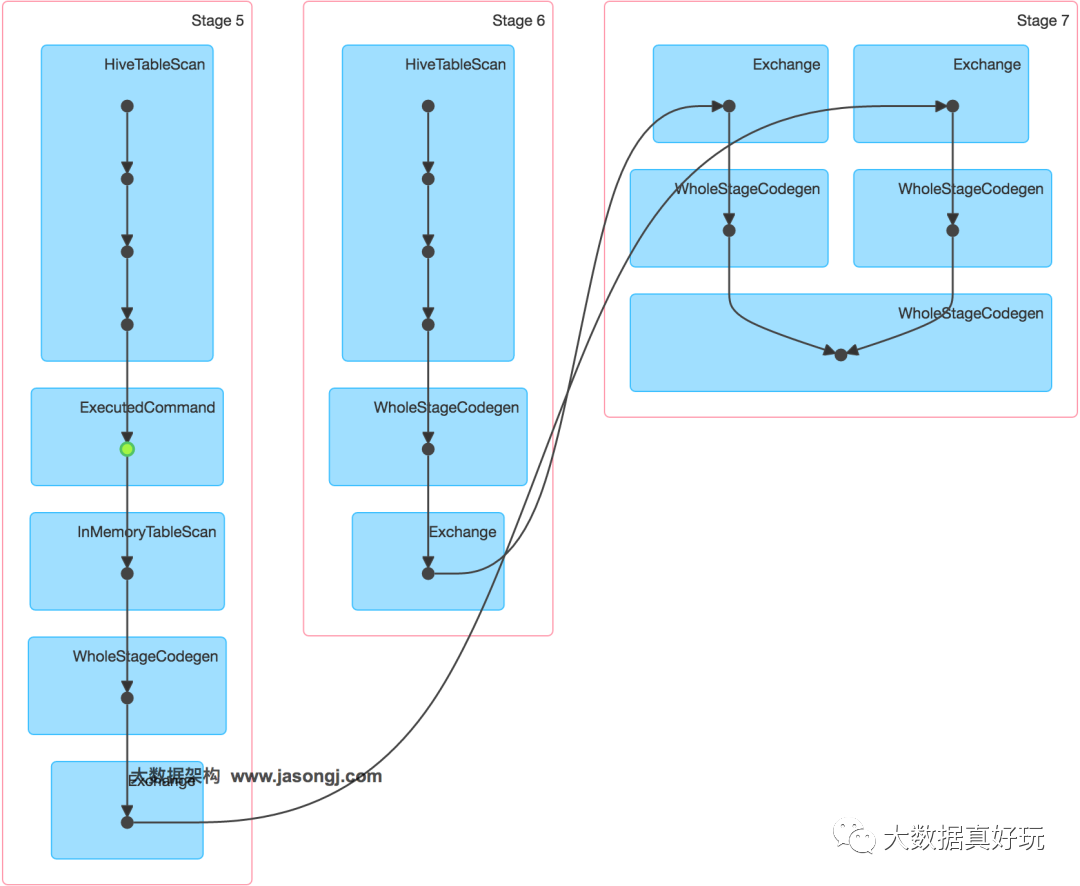
通过如下DAG图可见,该操作仍分为三个Stage,且仍然有Shuffle存在,唯一不同的是,小表的读取不再直接扫描Hive表,而是扫描内存中缓存的表。
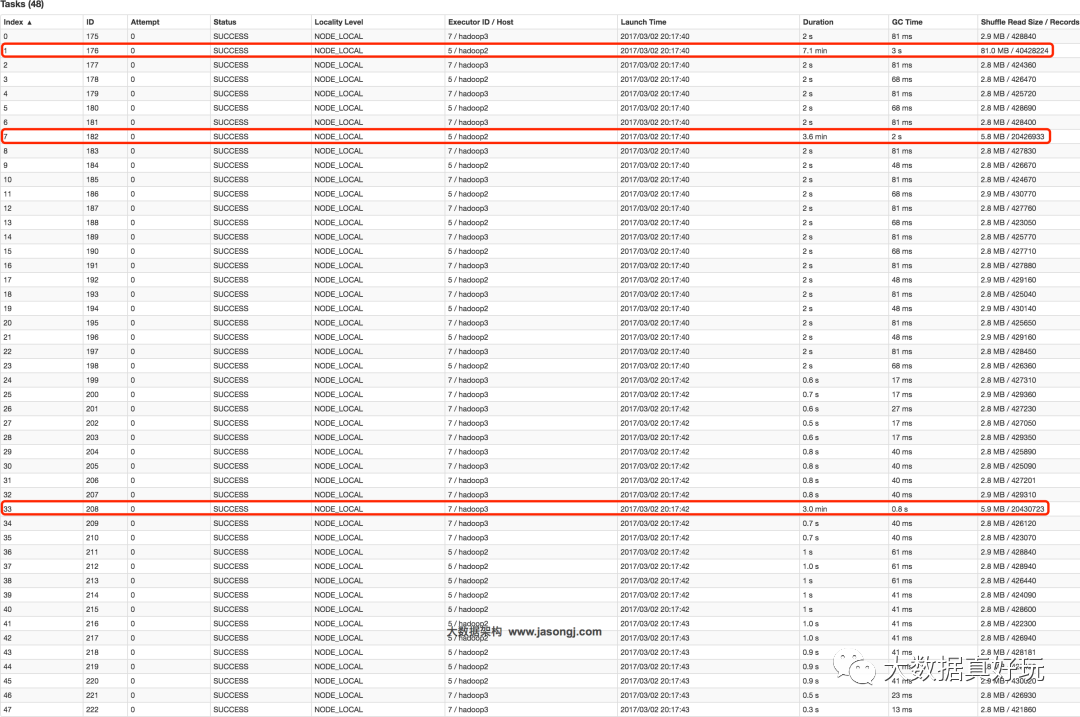
并且数据倾斜仍然存在。如下图所示,最慢的Task耗时为7.1分钟,远高于其它Task的约2秒。
正确的使用Broadcast实现Map侧Join的方式是,通过SET spark.sql.autoBroadcastJoinThreshold=104857600;将Broadcast的阈值设置得足够大。
再次通过如下SQL进行Join。
SET spark.sql.autoBroadcastJoinThreshold=104857600;
INSERT OVERWRITE TABLE test_join
SELECT test_new.id, test_new.name
FROM test
JOIN test_new
ON test.id = test_new.id;
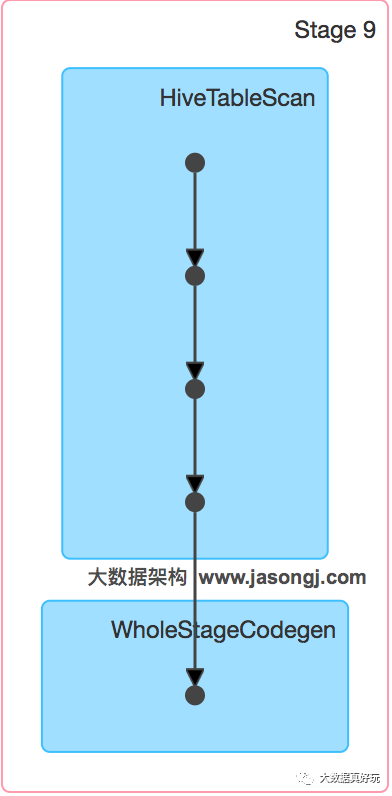
通过如下DAG图可见,该方案只包含一个Stage。
并且从下图可见,各Task耗时相当,无明显数据倾斜现象。并且总耗时为1.5分钟,远低于Reduce侧Join的7.3分钟。
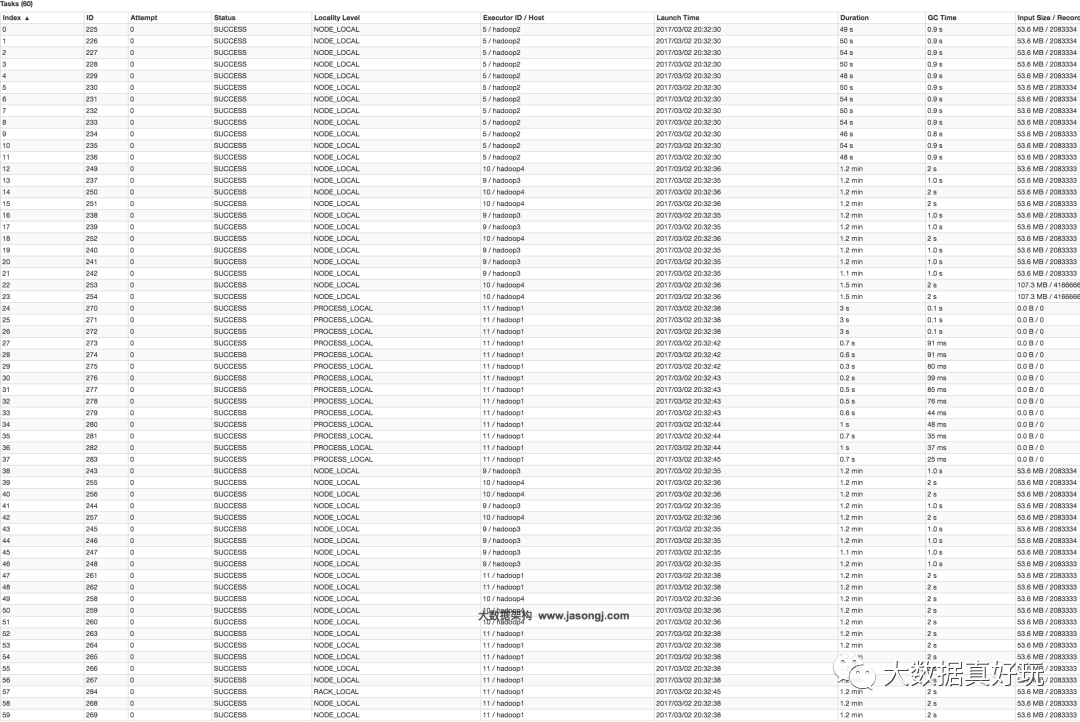
总结
适用场景 参与Join的一边数据集足够小,可被加载进Driver并通过Broadcast方法广播到各个Executor中。
解决方案 在Java/Scala代码中将小数据集数据拉取到Driver,然后通过Broadcast方案将小数据集的数据广播到各Executor。或者在使用SQL前,将Broadcast的阈值调整得足够大,从而使用Broadcast生效。进而将Reduce侧Join替换为Map侧Join。
优势 避免了Shuffle,彻底消除了数据倾斜产生的条件,可极大提升性能。
劣势 要求参与Join的一侧数据集足够小,并且主要适用于Join的场景,不适合聚合的场景,适用条件有限。
为skew的key增加随机前/后缀
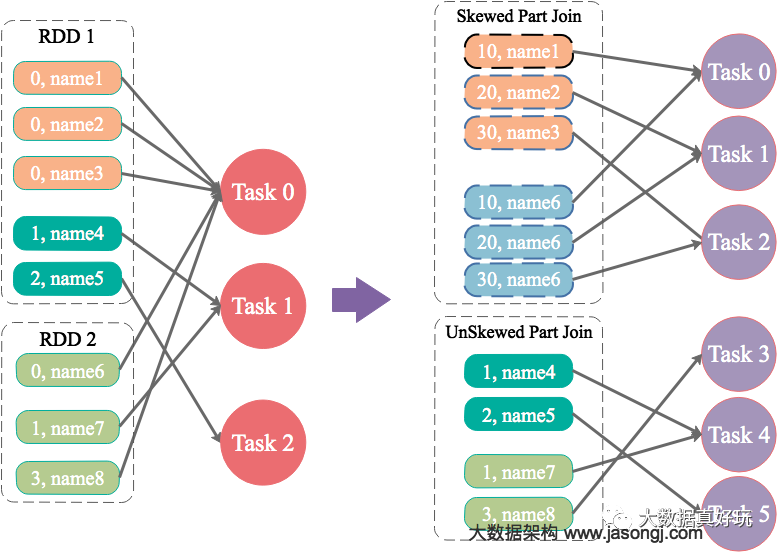
原理 为数据量特别大的Key增加随机前/后缀,使得原来Key相同的数据变为Key不相同的数据,从而使倾斜的数据集分散到不同的Task中,彻底解决数据倾斜问题。Join另一则的数据中,与倾斜Key对应的部分数据,与随机前缀集作笛卡尔乘积,从而保证无论数据倾斜侧倾斜Key如何加前缀,都能与之正常Join。
案例
通过如下SQL,将id为9亿到9.08亿共800万条数据的id转为9500048或者9500096,其它数据的id除以100取整。从而该数据集中,id为9500048和9500096的数据各400万,其它id对应的数据记录数均为100条。这些数据存于名为test的表中。
对于另外一张小表test_new,取出50万条数据,并将id(递增且唯一)除以100取整,使得所有id都对应100条数据。
INSERT OVERWRITE TABLE test
SELECT CAST(CASE WHEN id < 908000000 THEN (9500000 + (CAST (RAND() * 2 AS INT) + 1) * 48 )
ELSE CAST(id/100 AS INT) END AS STRING),
name
FROM student_external
WHERE id BETWEEN 900000000 AND 1050000000;
INSERT OVERWRITE TABLE test_new
SELECT CAST(CAST(id/100 AS INT) AS STRING),
name
FROM student_delta_external
WHERE id BETWEEN 950000000 AND 950500000;
通过如下代码,读取test表对应的文件夹内的数据并转换为JavaPairRDD存于leftRDD中,同样读取test表对应的数据存于rightRDD中。通过RDD的join算子对leftRDD与rightRDD进行Join,并指定并行度为48。
public class SparkDataSkew{
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf();
sparkConf.setAppName("DemoSparkDataFrameWithSkewedBigTableDirect");
sparkConf.set("spark.default.parallelism", String.valueOf(parallelism));
JavaSparkContext javaSparkContext = new JavaSparkContext(sparkConf);
JavaPairRDD<String, String> leftRDD = javaSparkContext.textFile("hdfs://hadoop1:8020/apps/hive/warehouse/default/test/")
.mapToPair((String row) -> {
String[] str = row.split(",");
return new Tuple2<String, String>(str[0], str[1]);
});
JavaPairRDD<String, String> rightRDD = javaSparkContext.textFile("hdfs://hadoop1:8020/apps/hive/warehouse/default/test_new/")
.mapToPair((String row) -> {
String[] str = row.split(",");
return new Tuple2<String, String>(str[0], str[1]);
});
leftRDD.join(rightRDD, parallelism)
.mapToPair((Tuple2<String, Tuple2<String, String>> tuple) -> new Tuple2<String, String>(tuple._1(), tuple._2()._2()))
.foreachPartition((Iterator<Tuple2<String, String>> iterator) -> {
AtomicInteger atomicInteger = new AtomicInteger();
iterator.forEachRemaining((Tuple2<String, String> tuple) -> atomicInteger.incrementAndGet());
});
javaSparkContext.stop();
javaSparkContext.close();
}
}
从下图可看出,整个Join耗时1分54秒,其中Join Stage耗时1.7分钟。

通过分析Join Stage的所有Task可知,在其它Task所处理记录数为192.71万的同时Task 32的处理的记录数为992.72万,故它耗时为1.7分钟,远高于其它Task的约10秒。这与上文准备数据集时,将id为9500048为9500096对应的数据量设置非常大,其它id对应的数据集非常均匀相符合。
现通过如下操作,实现倾斜Key的分散处理
将leftRDD中倾斜的key(即9500048与9500096)对应的数据单独过滤出来,且加上1到24的随机前缀,并将前缀与原数据用逗号分隔(以方便之后去掉前缀)形成单独的leftSkewRDD
将rightRDD中倾斜key对应的数据抽取出来,并通过flatMap操作将该数据集中每条数据均转换为24条数据(每条分别加上1到24的随机前缀),形成单独的rightSkewRDD
将leftSkewRDD与rightSkewRDD进行Join,并将并行度设置为48,且在Join过程中将随机前缀去掉,得到倾斜数据集的Join结果skewedJoinRDD
将leftRDD中不包含倾斜Key的数据抽取出来作为单独的leftUnSkewRDD
对leftUnSkewRDD与原始的rightRDD进行Join,并行度也设置为48,得到Join结果unskewedJoinRDD
通过union算子将skewedJoinRDD与unskewedJoinRDD进行合并,从而得到完整的Join结果集
具体实现代码如下
public class SparkDataSkew{
public static void main(String[] args) {
int parallelism = 48;
SparkConf sparkConf = new SparkConf();
sparkConf.setAppName("SolveDataSkewWithRandomPrefix");
sparkConf.set("spark.default.parallelism", parallelism + "");
JavaSparkContext javaSparkContext = new JavaSparkContext(sparkConf);
JavaPairRDD<String, String> leftRDD = javaSparkContext.textFile("hdfs://hadoop1:8020/apps/hive/warehouse/default/test/")
.mapToPair((String row) -> {
String[] str = row.split(",");
return new Tuple2<String, String>(str[0], str[1]);
});
JavaPairRDD<String, String> rightRDD = javaSparkContext.textFile("hdfs://hadoop1:8020/apps/hive/warehouse/default/test_new/")
.mapToPair((String row) -> {
String[] str = row.split(",");
return new Tuple2<String, String>(str[0], str[1]);
});
String[] skewedKeyArray = new String[]{"9500048", "9500096"};
Set<String> skewedKeySet = new HashSet<String>();
List<String> addList = new ArrayList<String>();
for(int i = 1; i <=24; i++) {
addList.add(i + "");
}
for(String key : skewedKeyArray) {
skewedKeySet.add(key);
}
Broadcast<Set<String>> skewedKeys = javaSparkContext.broadcast(skewedKeySet);
Broadcast<List<String>> addListKeys = javaSparkContext.broadcast(addList);
JavaPairRDD<String, String> leftSkewRDD = leftRDD
.filter((Tuple2<String, String> tuple) -> skewedKeys.value().contains(tuple._1()))
.mapToPair((Tuple2<String, String> tuple) -> new Tuple2<String, String>((new Random().nextInt(24) + 1) + "," + tuple._1(), tuple._2()));
JavaPairRDD<String, String> rightSkewRDD = rightRDD.filter((Tuple2<String, String> tuple) -> skewedKeys.value().contains(tuple._1()))
.flatMapToPair((Tuple2<String, String> tuple) -> addListKeys.value().stream()
.map((String i) -> new Tuple2<String, String>( i + "," + tuple._1(), tuple._2()))
.collect(Collectors.toList())
.iterator()
);
JavaPairRDD<String, String> skewedJoinRDD = leftSkewRDD
.join(rightSkewRDD, parallelism)
.mapToPair((Tuple2<String, Tuple2<String, String>> tuple) -> new Tuple2<String, String>(tuple._1().split(",")[1], tuple._2()._2()));
JavaPairRDD<String, String> leftUnSkewRDD = leftRDD.filter((Tuple2<String, String> tuple) -> !skewedKeys.value().contains(tuple._1()));
JavaPairRDD<String, String> unskewedJoinRDD = leftUnSkewRDD.join(rightRDD, parallelism).mapToPair((Tuple2<String, Tuple2<String, String>> tuple) -> new Tuple2<String, String>(tuple._1(), tuple._2()._2()));
skewedJoinRDD.union(unskewedJoinRDD).foreachPartition((Iterator<Tuple2<String, String>> iterator) -> {
AtomicInteger atomicInteger = new AtomicInteger();
iterator.forEachRemaining((Tuple2<String, String> tuple) -> atomicInteger.incrementAndGet());
});
javaSparkContext.stop();
javaSparkContext.close();
}
}
从下图可看出,整个Join耗时58秒,其中Join Stage耗时33秒。

通过分析Join Stage的所有Task可知
由于Join分倾斜数据集Join和非倾斜数据集Join,而各Join的并行度均为48,故总的并行度为96
由于提交任务时,设置的Executor个数为4,每个Executor的core数为12,故可用Core数为48,所以前48个Task同时启动(其Launch时间相同),后48个Task的启动时间各不相同(等待前面的Task结束才开始)
由于倾斜Key被加上随机前缀,原本相同的Key变为不同的Key,被分散到不同的Task处理,故在所有Task中,未发现所处理数据集明显高于其它Task的情况
实际上,由于倾斜Key与非倾斜Key的操作完全独立,可并行进行。而本实验受限于可用总核数为48,可同时运行的总Task数为48,故而该方案只是将总耗时减少一半(效率提升一倍)。如果资源充足,可并发执行Task数增多,该方案的优势将更为明显。在实际项目中,该方案往往可提升数倍至10倍的效率。
总结
适用场景 两张表都比较大,无法使用Map则Join。其中一个RDD有少数几个Key的数据量过大,另外一个RDD的Key分布较为均匀。
解决方案 将有数据倾斜的RDD中倾斜Key对应的数据集单独抽取出来加上随机前缀,另外一个RDD每条数据分别与随机前缀结合形成新的RDD(相当于将其数据增到到原来的N倍,N即为随机前缀的总个数),然后将二者Join并去掉前缀。然后将不包含倾斜Key的剩余数据进行Join。最后将两次Join的结果集通过union合并,即可得到全部Join结果。
优势 相对于Map则Join,更能适应大数据集的Join。如果资源充足,倾斜部分数据集与非倾斜部分数据集可并行进行,效率提升明显。且只针对倾斜部分的数据做数据扩展,增加的资源消耗有限。
劣势 如果倾斜Key非常多,则另一侧数据膨胀非常大,此方案不适用。而且此时对倾斜Key与非倾斜Key分开处理,需要扫描数据集两遍,增加了开销。
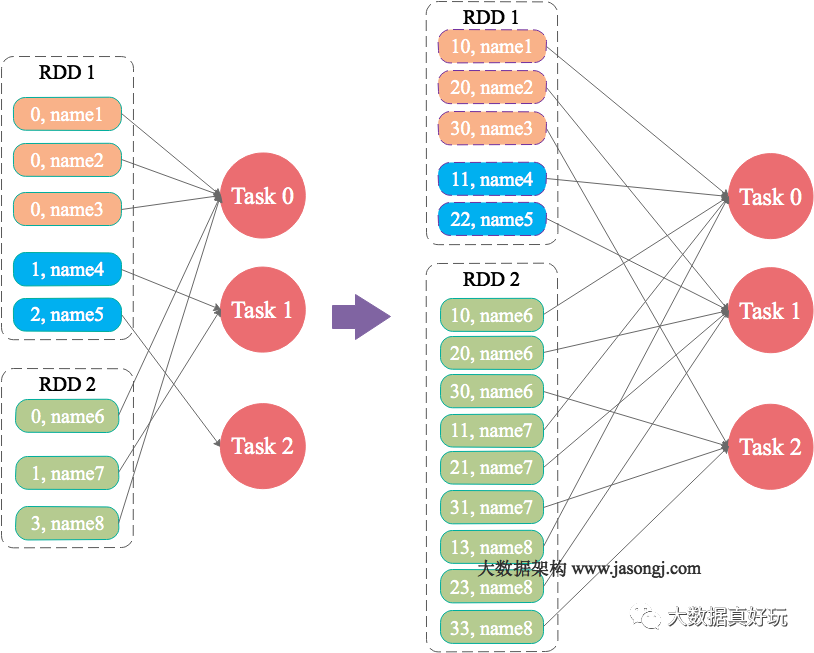
大表随机添加N种随机前缀,小表扩大N倍
原理
如果出现数据倾斜的Key比较多,上一种方法将这些大量的倾斜Key分拆出来,意义不大。此时更适合直接对存在数据倾斜的数据集全部加上随机前缀,然后对另外一个不存在严重数据倾斜的数据集整体与随机前缀集作笛卡尔乘积(即将数据量扩大N倍)。
案例
这里给出示例代码,读者可参考上文中分拆出少数倾斜Key添加随机前缀的方法,自行测试。
public class SparkDataSkew {
public static void main(String[] args) {
SparkConf sparkConf = new SparkConf();
sparkConf.setAppName("ResolveDataSkewWithNAndRandom");
sparkConf.set("spark.default.parallelism", parallelism + "");
JavaSparkContext javaSparkContext = new JavaSparkContext(sparkConf);
JavaPairRDD<String, String> leftRDD = javaSparkContext.textFile("hdfs://hadoop1:8020/apps/hive/warehouse/default/test/")
.mapToPair((String row) -> {
String[] str = row.split(",");
return new Tuple2<String, String>(str[0], str[1]);
});
JavaPairRDD<String, String> rightRDD = javaSparkContext.textFile("hdfs://hadoop1:8020/apps/hive/warehouse/default/test_new/")
.mapToPair((String row) -> {
String[] str = row.split(",");
return new Tuple2<String, String>(str[0], str[1]);
});
List<String> addList = new ArrayList<String>();
for(int i = 1; i <=48; i++) {
addList.add(i + "");
}
Broadcast<List<String>> addListKeys = javaSparkContext.broadcast(addList);
JavaPairRDD<String, String> leftRandomRDD = leftRDD.mapToPair((Tuple2<String, String> tuple) -> new Tuple2<String, String>(new Random().nextInt(48) + "," + tuple._1(), tuple._2()));
JavaPairRDD<String, String> rightNewRDD = rightRDD
.flatMapToPair((Tuple2<String, String> tuple) -> addListKeys.value().stream()
.map((String i) -> new Tuple2<String, String>( i + "," + tuple._1(), tuple._2()))
.collect(Collectors.toList())
.iterator()
);
JavaPairRDD<String, String> joinRDD = leftRandomRDD
.join(rightNewRDD, parallelism)
.mapToPair((Tuple2<String, Tuple2<String, String>> tuple) -> new Tuple2<String, String>(tuple._1().split(",")[1], tuple._2()._2()));
joinRDD.foreachPartition((Iterator<Tuple2<String, String>> iterator) -> {
AtomicInteger atomicInteger = new AtomicInteger();
iterator.forEachRemaining((Tuple2<String, String> tuple) -> atomicInteger.incrementAndGet());
});
javaSparkContext.stop();
javaSparkContext.close();
}
}
总结
适用场景 一个数据集存在的倾斜Key比较多,另外一个数据集数据分布比较均匀。
优势 对大部分场景都适用,效果不错。
劣势 需要将一个数据集整体扩大N倍,会增加资源消耗。
总结
对于数据倾斜,并无一个统一的一劳永逸的方法。更多的时候,是结合数据特点(数据集大小,倾斜Key的多少等)综合使用上文所述的多种方法。