
云原生消息、事件、流超融合平台——RocketMQ 5.0 初探

前言:本文整理自 RocketMQ x EventMesh OpenDay 金融通演讲内容
今天分享的主题是云原生消息事件流超融合平台 RocketMQ 5.0 初探,内容主要分为三个部分:
RocketMQ 发展历程
Aliware
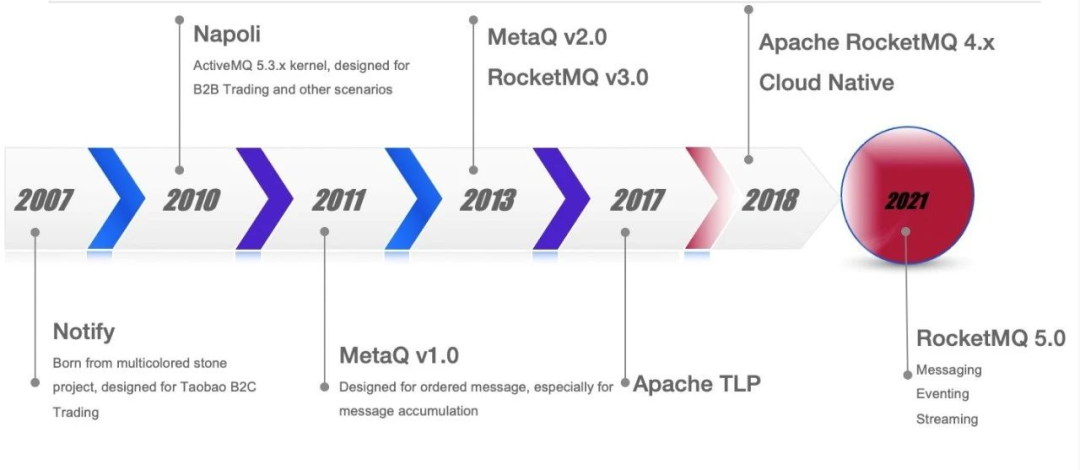
RocketMQ 4 回顾
Aliware


RocketMQ5.0 概览
Aliware



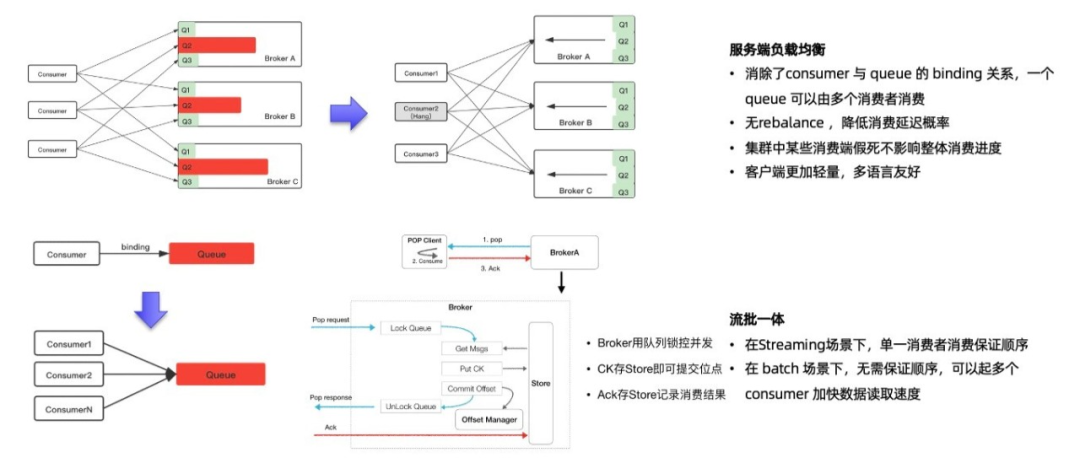
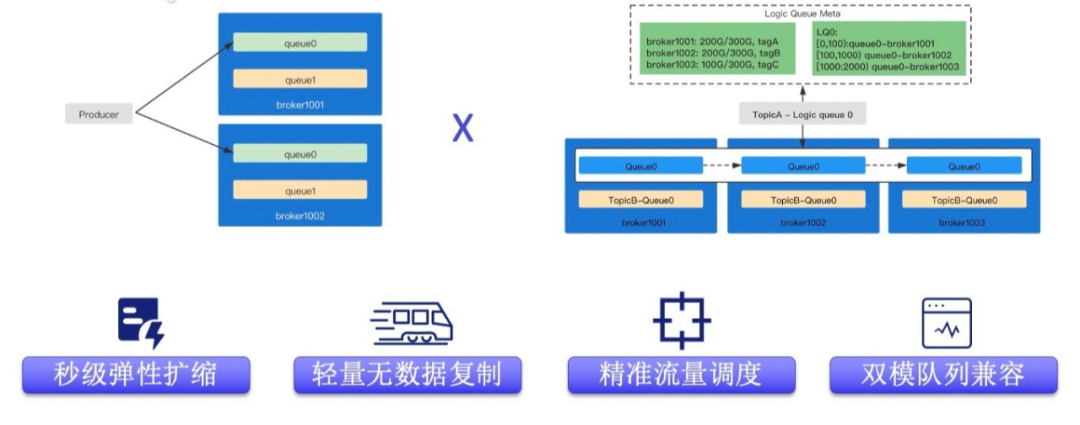

RcoketMQ 5.0 Landscape
Aliware
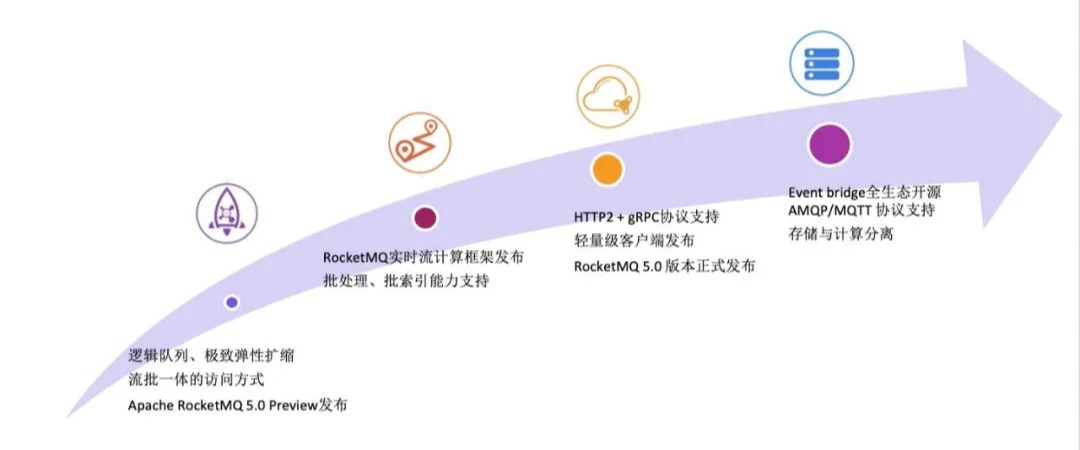
推荐阅读:
欢迎关注微信公众号:互联网全栈架构,收取更多有价值的信息。
评论