
看一遍就理解:MVCC原理详解

源 / 文/
前言
MVCC实现原理是一道非常高频的面试题,最近技术讨论群的小伙伴一直在讨论,趁着国庆节有空,我们一起来聊聊。
1. 相关数据库知识点回顾
1.1 什么是数据库事务,为什么要有事务
事务,由一个有限的数据库操作序列构成,这些操作要么全部执行,要么全部不执行,是一个不可分割的工作单位。
假如A转账给B 100 元,先从A的账户里扣除 100 元,再在 B 的账户上加上 100 元。如果扣完A的100元后,还没来得及给B加上,银行系统异常了,最后导致A的余额减少了,B的余额却没有增加。所以就需要事务,将A的钱回滚回去,就是这么简单。
为什么要有事务呢? 就是为了保证数据的最终一致性。
1.2 事务包括哪几个特性?
事务四个典型特性,即ACID,原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)。
原子性:事务作为一个整体被执行,包含在其中的对数据库的操作要么全部都执行,要么都不执行。 一致性:指在事务开始之前和事务结束以后,数据不会被破坏,假如A账户给B账户转10块钱,不管成功与否,A和B的总金额是不变的。 隔离性:多个事务并发访问时,事务之间是相互隔离的,一个事务不应该被其他事务干扰,多个并发事务之间要相互隔离。。 持久性:表示事务完成提交后,该事务对数据库所作的操作更改,将持久地保存在数据库之中。
1.3 事务并发存在的问题
事务并发会引起脏读、不可重复读、幻读问题。
1.3.1 脏读
如果一个事务读取到了另一个未提交事务修改过的数据,我们就称发生了脏读现象。
假设现在有两个事务A、B:
假设现在A的余额是100,事务A正在准备查询Jay的余额 事务B先扣减Jay的余额,扣了10,但是还没提交 最后A读到的余额是90,即扣减后的余额

因为事务A读取到事务B未提交的数据,这就是脏读。
1.3.2 不可重复读
同一个事务内,前后多次读取,读取到的数据内容不一致
假设现在有两个事务A和B:
事务A先查询Jay的余额,查到结果是100 这时候事务B 对Jay的账户余额进行扣减,扣去10后,提交事务 事务A再去查询Jay的账户余额发现变成了90

事务A被事务B干扰到了!在事务A范围内,两个相同的查询,读取同一条记录,却返回了不同的数据,这就是不可重复读。
1.3.3 幻读
如果一个事务先根据某些搜索条件查询出一些记录,在该事务未提交时,另一个事务写入了一些符合那些搜索条件的记录(如insert、delete、update),就意味着发生了幻读。
假设现在有两个事务A、B:
事务A先查询id大于2的账户记录,得到记录id=2和id=3的两条记录 这时候,事务B开启,插入一条id=4的记录,并且提交了 事务A再去执行相同的查询,却得到了id=2,3,4的3条记录了。

事务A查询一个范围的结果集,另一个并发事务B往这个范围中插入新的数据,并提交事务,然后事务A再次查询相同的范围,两次读取到的结果集却不一样了,这就是幻读。
1.4 四大隔离级别
为了解决并发事务存在的脏读、不可重复读、幻读等问题,数据库大叔设计了四种隔离级别。分别是读未提交,读已提交,可重复读,串行化(Serializable)。
1.4.1 读未提交
读未提交隔离级别,只限制了两个数据不能同时修改,但是修改数据的时候,即使事务未提交,都是可以被别的事务读取到的,这级别的事务隔离有脏读、重复读、幻读的问题;
1.4.2 读已提交
读已提交隔离级别,当前事务只能读取到其他事务提交的数据,所以这种事务的隔离级别解决了脏读问题,但还是会存在重复读、幻读问题;
1.4 3 可重复读
可重复读隔离级别,限制了读取数据的时候,不可以进行修改,所以解决了重复读的问题,但是读取范围数据的时候,是可以插入数据,所以还会存在幻读问题;
1.4.4 串行化
事务最高的隔离级别,在该级别下,所有事务都是进行串行化顺序执行的。可以避免脏读、不可重复读与幻读所有并发问题。但是这种事务隔离级别下,事务执行很耗性能。
1.4.5 四大隔离级别,都会存在哪些并发问题呢
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 读未提交 | √ | √ | √ |
| 读已提交 | × | √ | √ |
| 可重复读 | × | × | √ |
| 串行化 | × | × | × |
1.5 数据库是如何保证事务的隔离性的呢?
数据库是通过加锁,来实现事务的隔离性的。这就好像,如果你想一个人静静,不被别人打扰,你就可以在房门上加上一把锁。
加锁确实好使,可以保证隔离性。比如串行化隔离级别就是加锁实现的。但是频繁的加锁,导致读数据时,没办法修改,修改数据时,没办法读取,大大降低了数据库性能。
那么,如何解决加锁后的性能问题的?
答案就是,MVCC多版本并发控制!它实现读取数据不用加锁,可以让读取数据同时修改。修改数据时同时可读取。
2. 什么是 MVCC?
MVCC,即Multi-Version Concurrency Control (多版本并发控制)。它是一种并发控制的方法,一般在数据库管理系统中,实现对数据库的并发访问,在编程语言中实现事务内存。
通俗的讲,数据库中同时存在多个版本的数据,并不是整个数据库的多个版本,而是某一条记录的多个版本同时存在,在某个事务对其进行操作的时候,需要查看这一条记录的隐藏列事务版本id,比对事务id并根据事物隔离级别去判断读取哪个版本的数据。
数据库隔离级别读已提交、可重复读 都是基于MVCC实现的,相对于加锁简单粗暴的方式,它用更好的方式去处理读写冲突,能有效提高数据库并发性能。
3. MVCC实现的关键知识点
3.1 事务版本号
事务每次开启前,都会从数据库获得一个自增长的事务ID,可以从事务ID判断事务的执行先后顺序。这就是事务版本号。
3.2 隐式字段
对于InnoDB存储引擎,每一行记录都有两个隐藏列trx_id、roll_pointer,如果表中没有主键和非NULL唯一键时,则还会有第三个隐藏的主键列row_id。
| 列名 | 是否必须 | 描述 |
|---|---|---|
| row_id | 否 | 单调递增的行ID,不是必需的,占用6个字节。 |
| trx_id | 是 | 记录操作该数据事务的事务ID |
| roll_pointer | 是 | 这个隐藏列就相当于一个指针,指向回滚段的undo日志 |
3.3 undo log
undo log,回滚日志,用于记录数据被修改前的信息。在表记录修改之前,会先把数据拷贝到undo log里,如果事务回滚,即可以通过undo log来还原数据。

可以这样认为,当delete一条记录时,undo log 中会记录一条对应的insert记录,当update一条记录时,它记录一条对应相反的update记录。
undo log有什么用途呢?
事务回滚时,保证原子性和一致性。 用于MVCC快照读。
3.4 版本链
多个事务并行操作某一行数据时,不同事务对该行数据的修改会产生多个版本,然后通过回滚指针(roll_pointer),连成一个链表,这个链表就称为版本链。如下:
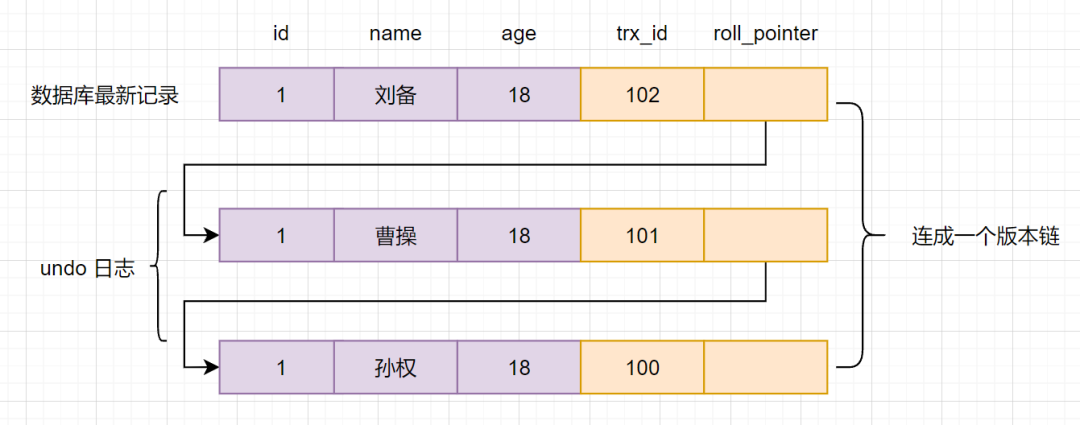
其实,通过版本链,我们就可以看出事务版本号、表格隐藏的列和undo log它们之间的关系。我们再来小分析一下。
假设现在有一张core_user表,表里面有一条数据,id为1,名字为孙权:
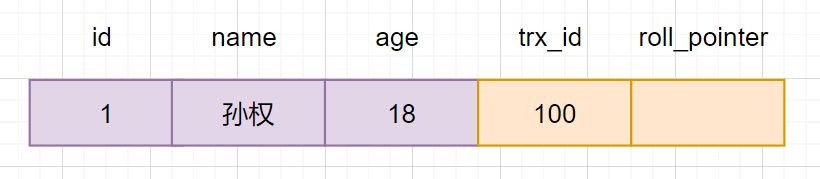
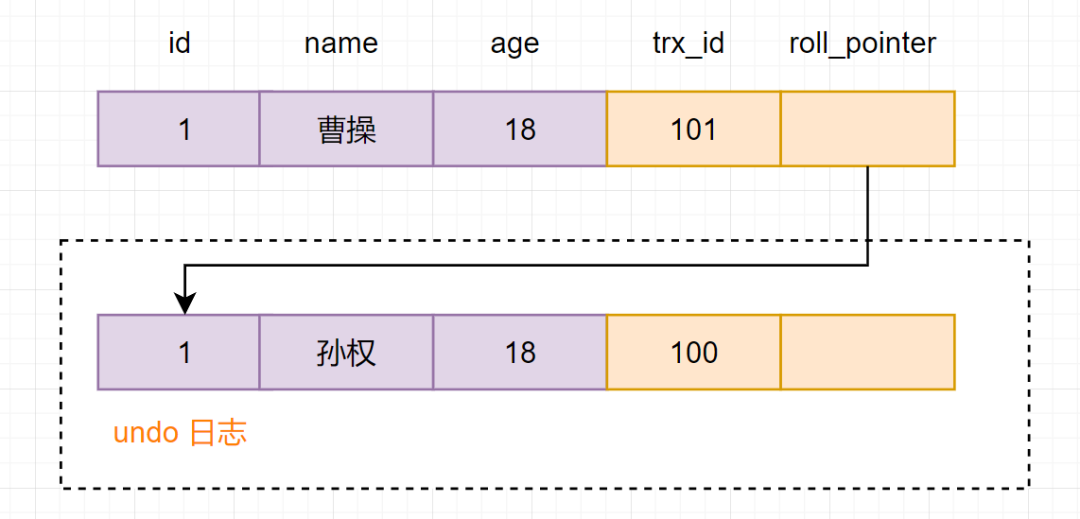
现在开启一个事务A:对core_user表执行 update core_user set name ="曹操" where id=1,会进行如下流程操作
首先获得一个事务ID=100 把core_user表修改前的数据,拷贝到undo log 修改core_user表中,id=1的数据,名字改为曹操 把修改后的数据事务Id=101改成当前事务版本号,并把roll_pointer指向undo log数据地址。
3.5 快照读和当前读
快照读: 读取的是记录数据的可见版本(有旧的版本)。不加锁,普通的select语句都是快照读,如:
select * from core_user where id > 2;
当前读:读取的是记录数据的最新版本,显式加锁的都是当前读
select * from core_user where id > 2 for update;
select * from account where id>2 lock in share mode;
3.6 Read View
Read View是什么呢? 它就是事务执行SQL语句时,产生的读视图。实际上在innodb中,每个SQL语句执行前都会得到一个Read View。 Read View有什么用呢? 它主要是用来做可见性判断的,即判断当前事务可见哪个版本的数据~
Read View是如何保证可见性判断的呢?我们先看看Read view 的几个重要属性
m_ids:当前系统中那些活跃(未提交)的读写事务ID, 它数据结构为一个List。 min_limit_id:表示在生成Read View时,当前系统中活跃的读写事务中最小的事务id,即m_ids中的最小值。 max_limit_id:表示生成Read View时,系统中应该分配给下一个事务的id值。 creator_trx_id: 创建当前Read View的事务ID
Read view 匹配条件规则如下:
如果数据事务ID trx_id < min_limit_id,表明生成该版本的事务在生成Read View前,已经提交(因为事务ID是递增的),所以该版本可以被当前事务访问。如果 trx_id>= max_limit_id,表明生成该版本的事务在生成ReadView后才生成,所以该版本不可以被当前事务访问。如果 min_limit_id =
(1).如果 m_ids包含trx_id,则代表Read View生成时刻,这个事务还未提交,但是如果数据的trx_id等于creator_trx_id的话,表明数据是自己生成的,因此是可见的。(2)如果 m_ids包含trx_id,并且trx_id不等于creator_trx_id,则Read View生成时,事务未提交,并且不是自己生产的,所以当前事务也是看不见的;(3).如果 m_ids不包含trx_id,则说明你这个事务在Read View生成之前就已经提交了,修改的结果,当前事务是能看见的。
4. MVCC实现原理分析
4.1 查询一条记录,基于MVCC,是怎样的流程
获取事务自己的版本号,即事务ID 获取Read View 查询得到的数据,然后Read View中的事务版本号进行比较。 如果不符合Read View的可见性规则, 即就需要Undo log中历史快照; 最后返回符合规则的数据
InnoDB 实现MVCC,是通过Read View+ Undo Log 实现的,Undo Log 保存了历史快照,Read View可见性规则帮助判断当前版本的数据是否可见。
4.2 读已提交(RC)隔离级别,存在不可重复读问题的分析历程
创建core_user表,插入一条初始化数据,如下:
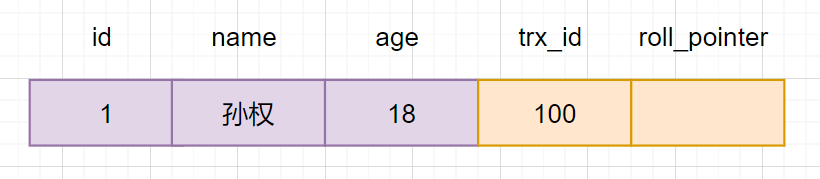
隔离级别设置为读已提交(RC),事务A和事务B同时对core_user表进行查询和修改操作。
事务A: select * fom core_user where id=1
事务B: update core_user set name =”曹操”
执行流程如下:
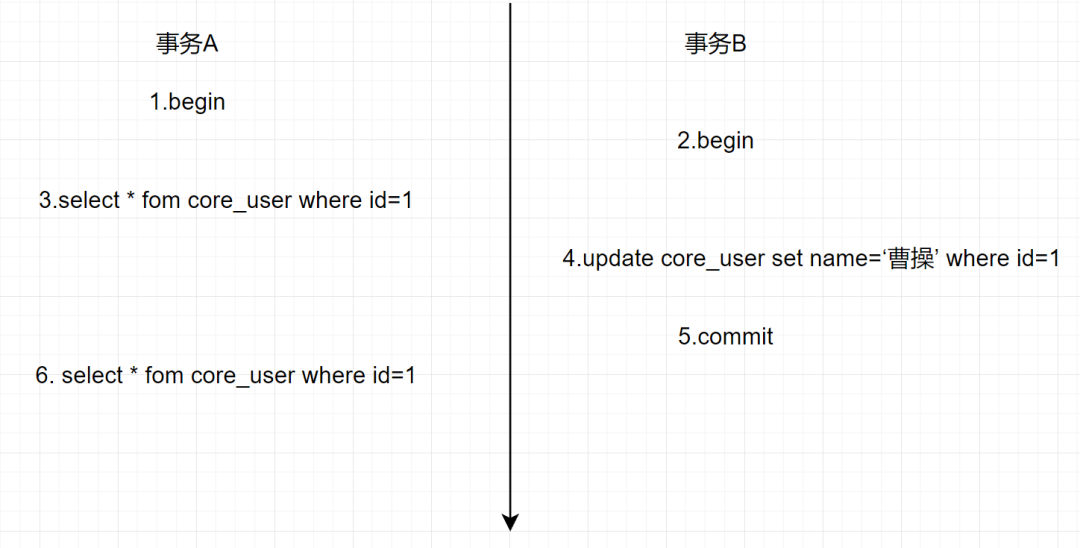
最后事务A查询到的结果是,name=曹操的记录,我们基于MVCC,来分析一下执行流程:
(1). A开启事务,首先得到一个事务ID为100
(2).B开启事务,得到事务ID为101
(3).事务A生成一个Read View,read view对应的值如下
| 变量 | 值 |
|---|---|
| m_ids | 100,101 |
| max_limit_id | 102 |
| min_limit_id | 100 |
| creator_trx_id | 100 |
然后回到版本链:开始从版本链中挑选可见的记录:
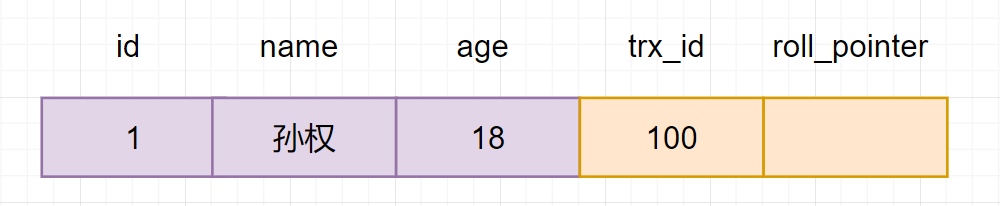
由图可以看出,最新版本的列name的内容是孙权,该版本的trx_id值为100。开始执行read view可见性规则校验:
min_limit_id(100)=creator_trx_id = trx_id =100;
由此可得,trx_id=100的这个记录,当前事务是可见的。所以查到是name为孙权的记录。
(4). 事务B进行修改操作,把名字改为曹操。把原数据拷贝到undo log,然后对数据进行修改,标记事务ID和上一个数据版本在undo log的地址。
(5) 提交事务
(6) 事务A再次执行查询操作,新生成一个Read View,Read View对应的值如下
| 变量 | 值 |
|---|---|
| m_ids | 100 |
| max_limit_id | 102 |
| min_limit_id | 100 |
| creator_trx_id | 100 |
然后再次回到版本链:从版本链中挑选可见的记录:
从图可得,最新版本的列name的内容是曹操,该版本的trx_id值为101。开始执行Read View可见性规则校验:
min_limit_id(100)=但是,trx_id=101,不属于m_ids集合
因此,trx_id=101这个记录,对于当前事务是可见的。所以SQL查询到的是name为曹操的记录。
综上所述,在读已提交(RC)隔离级别下,同一个事务里,两个相同的查询,读取同一条记录(id=1),却返回了不同的数据(第一次查出来是孙权,第二次查出来是曹操那条记录),因此RC隔离级别,存在不可重复读并发问题。
4.3 可重复读(RR)隔离级别,解决不可重复读问题的分析
在RR隔离级别下,是如何解决不可重复读问题的呢?我们一起再来看下,
还是4.2小节那个流程,还是这个事务A和事务B,如下:
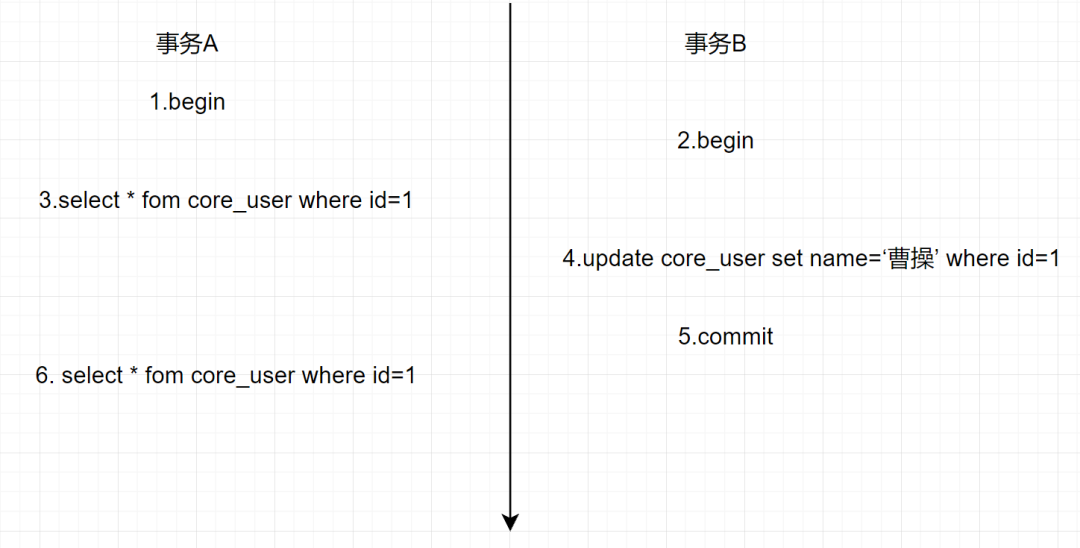
4.3.1 不同隔离级别下,Read View的工作方式不同
实际上,各种事务隔离级别下的Read view工作方式,是不一样的,RR可以解决不可重复读问题,就是跟Read view工作方式有关。
在读已提交(RC)隔离级别下,同一个事务里面,每一次查询都会产生一个新的Read View副本,这样就可能造成同一个事务里前后读取数据可能不一致的问题(不可重复读并发问题)。
| begin | |
|---|---|
| select * from core_user where id =1 | 生成一个Read View |
| / | / |
| / | / |
| select * from core_user where id =1 | 生成一个Read View |
在可重复读(RR)隔离级别下,一个事务里只会获取一次read view,都是副本共用的,从而保证每次查询的数据都是一样的。
| begin | |
|---|---|
| select * from core_user where id =1 | 生成一个Read View |
| / | |
| / | |
| select * from core_user where id =1 | 共用一个Read View副本 |
4.3.2 实例分析
我们穿越下,回到刚4.2的例子,然后执行第2个查询的时候:
事务A再次执行查询操作,复用老的Read View副本,Read View对应的值如下
| 变量 | 值 |
|---|---|
| m_ids | 100,101 |
| max_limit_id | 102 |
| min_limit_id | 100 |
| creator_trx_id | 100 |
然后再次回到版本链:从版本链中挑选可见的记录:
从图可得,最新版本的列name的内容是曹操,该版本的trx_id值为101。开始执行read view可见性规则校验:
min_limit_id(100)=因为m_ids{100,101}包含trx_id(101),
并且creator_trx_id (100) 不等于trx_id(101)
所以,trx_id=101这个记录,对于当前事务是不可见的。这时候呢,版本链roll_pointer跳到下一个版本,trx_id=100这个记录,再次校验是否可见:
min_limit_id(100)=因为m_ids{100,101}包含trx_id(100),
并且creator_trx_id (100) 等于trx_id(100)
所以,trx_id=100这个记录,对于当前事务是可见的,所以两次查询结果,都是name=孙权的那个记录。即在可重复读(RR)隔离级别下,复用老的Read View副本,解决了不可重复读的问题。
4.4 网络江湖传说,MVCC是否解决了幻读问题呢?
网络江湖有个传说,说MVCC的RR隔离级别,解决了幻读问题,我们来一起分析一下。
4.4.1 RR级别下,一个快照读的例子,不存在幻读问题
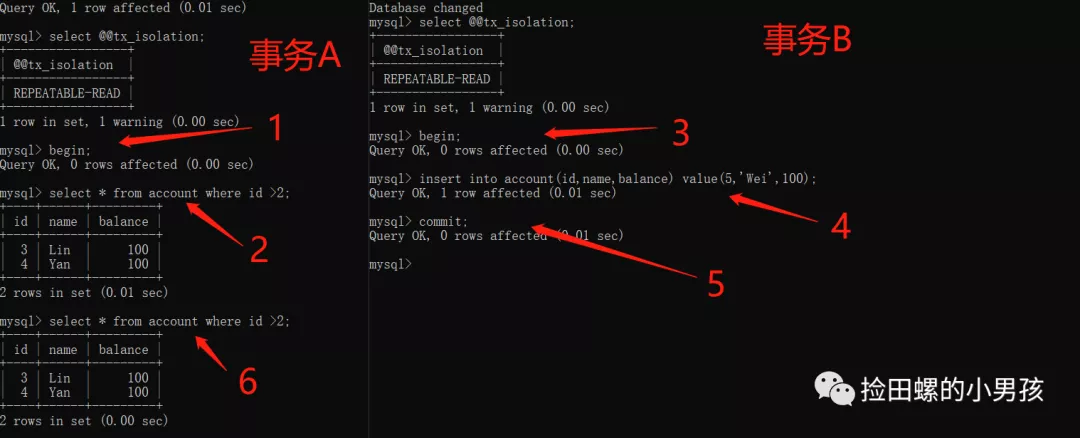
由图可得,步骤2和步骤6查询结果集没有变化,看起来RR级别是已经解决幻读问题啦~
4.4.2 RR级别下,一个当前读的例子
假设现在有个account表,表中有4条数据,RR级别。
开启事务A,执行当前读,查询id>2的所有记录。 再开启事务B,插入id=5的一条数据。
流程如下:
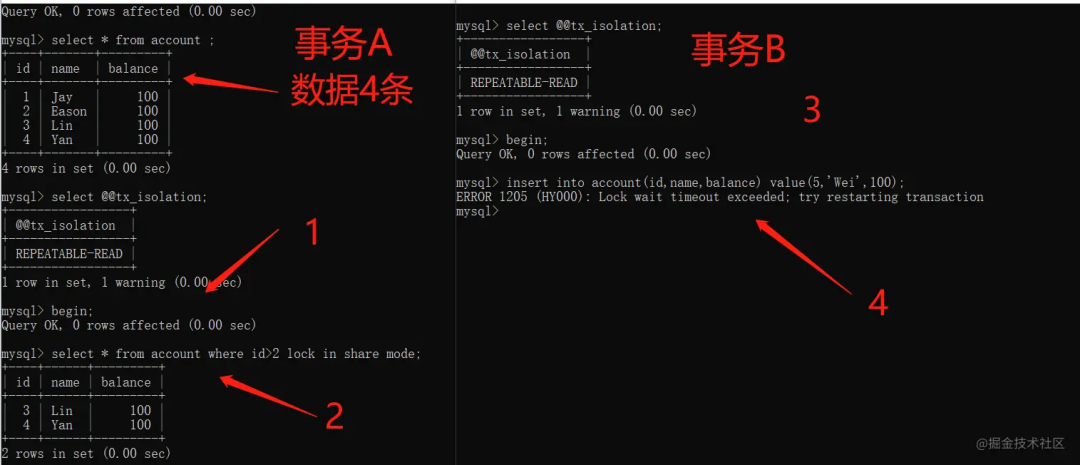
显然,事务B执行插入操作时,阻塞了~因为事务A在执行select ... lock in share mode(当前读)的时候,不仅在id = 3,4 这2条记录上加了锁,而且在id > 2这个范围上也加了间隙锁。
因此,我们可以发现,RR隔离级别下,加锁的select, update, delete等语句,会使用间隙锁+ 临键锁,锁住索引记录之间的范围,避免范围间插入记录,以避免产生幻影行记录,那就是说RR隔离级别解决了幻读问题?
4.4.3 这种特殊场景,似乎有幻读问题
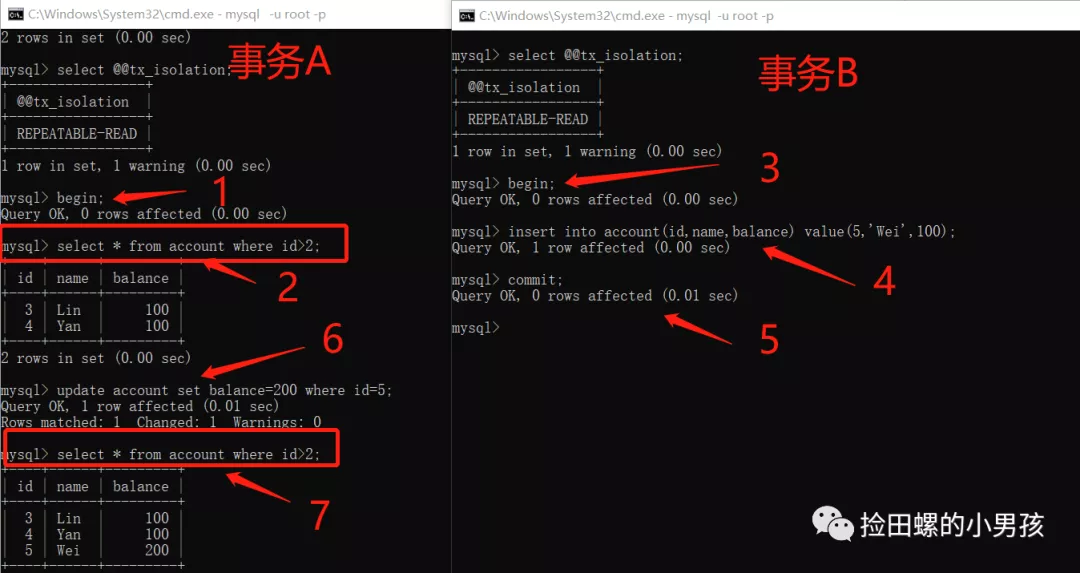
其实,上图事务A中,多加了update account set balance=200 where id=5;这步操作,同一个事务,相同的sql,查出的结果集不同了,这个结果,就符合了幻读的定义~
这个问题,亲爱的朋友,你觉得它算幻读问题吗,所以RR隔离级别,还是存在幻读问题吧?欢迎大家评论区留言哈。
数据库基础(四)Innodb MVCC实现原理: https://zhuanlan.zhihu.com/p/52977862
推荐阅读
大学城情侣宾馆花样真多,荷尔蒙的味道!
程序员踩点上下班,被HR约谈,网友:错了吗?
男女洗澡前后区别,太形象了!
END





顶级程序员:topcoding
做最好的程序员社区:Java后端开发、Python、大数据、AI
一键三连「分享」、「点赞」和「在看」