作者:Dario Radecic,Medium 高质技术博主 编译:颂贤一般的 AI 课程会介绍很多如何通过参数优化来提高机器学习模型准确性的方法,然而这些方法通常都存在一定的局限性。这是因为我们常常忽视了现代机器学习一个非常重要的核心——数据。如果我们没有处理好训练数据没,上百个小时的时间都会被浪费在调整一个低质量数据训练出来的模型上,模型的准确度很容易就会低于预期,而这和模型调优是没有太大关系的。怎样才能避免这样的问题呢?粗略地看,其实每个AI项目都由两部分组成:模型和数据。对于代码这部分,我们总能使用第三方库来尽可能地提高代码质量,但从来没有人告诉我们该如何充分提升数据的质量。这就是本文想要介绍的新思路:以数据为中心的AI。究竟什么是以数据为中心的AI?数据的数量与质量到底哪一个优先级更高?哪里可以找到好的数据集?这些问题本文都将带大家探讨。
什么是以数据为中心的AI?
既然AI由模型和数据两部分组成,那么我们可以想到有两种基本思路来指导我们的机器学习:
以模型为中心: 通过改进模型来提升表现
以数据为中心: 通过改进数据来提升表现
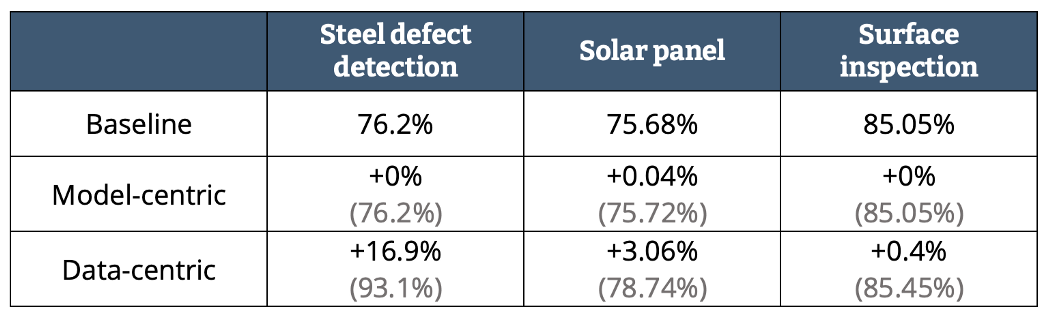
其实,以数据为中心的AI(data-centric AI)这一概念是吴恩达(Andrew Ng)的发明。吴恩达早前在油管上做了一次直播问答,专门讲解了什么是以数据为中心的AI。他提出,最近发表的学术论文中,99%都是在谈论模型,只有1%是以数据为中心的。其中有一句话特别值得注意:“别再花太多心思在模型优化上了”(your model architecture is good enough)。吴恩达何出此言呢?ResNet, VGG, EfficientNet等学术界各路天才的种种智慧结晶,已经让我们现在能够接触到的模型架构变得非常强大了。试图再站在这些巨人的肩膀上改善她们的工作只能达到杯水车薪的效果。不过,以模型为中心的思路的确更适合那些喜欢钻研理论的人,她们可以直接把手头的知识应用到具体场景中提升模型性能。而且,以数据为中心的思路听起来并不讨巧,谁会喜欢每天乐此不疲地给数据做标注呢?然而事实证明,我们能做到的大部分性能提升都是通过以数据为中心的方法实现的。吴恩达在他的演讲中就展示了下面这组数据:图1 — 基线、模型中心、数据中心性能比较(作者制图) 即使我们对钢铁缺陷这些事情没有什么了解,模型性能在数字上的显著提升我们是看得见的。我们可以看到,以模型为中心的方法对基线的改进不是零就是接近零,而且这种方法往往需要花费从业者数百小时的时间。总结而言,我们可以得出一个很重要的经验教训:不要试图和一屋子的博士比智商。在想要改进模型之前,我们要首先确保手头上的数据质量是一流的。


 下载APP
下载APP