
DeepMind又出大招!新算法MuZero登顶Nature,AI离人类规划又近了一步

极市导读
与AlphaZero相比,MuZero多了玩Atari的功能,这一突破进展引起科研人员的广泛关注。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
近日,DeepMind一篇关于MuZero的论文“Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model”在Nature发表。与AlphaZero相比,MuZero多了玩Atari的功能,这一突破进展引起科研人员的广泛关注。

MuZero通过DQN算法,仅使用像素和游戏分数作为输入就可以在Atari视频游戏中达到人类的水平。相对于围棋、国际象棋、日本将棋,Atari游戏的规则与动态变化未知且复杂。
AlphaGo在2016年的围棋比赛中以4-1击败了围棋世界冠军李世石;AlphaGo Zero,可以从零通过自我对弈训练,仅在知道基本游戏规则的情况下,第二年在性能上超过了AlphaGo;AlphaZero于2017年通过对AlphaGo Zero进行一般化,可以将其应用于其他游戏,包括国际象棋和日本将棋。
而据Nature报道,尽管每步进行的树搜索计算量较少,但MuZero在玩围棋方面被证明比AlphaZero稍好。
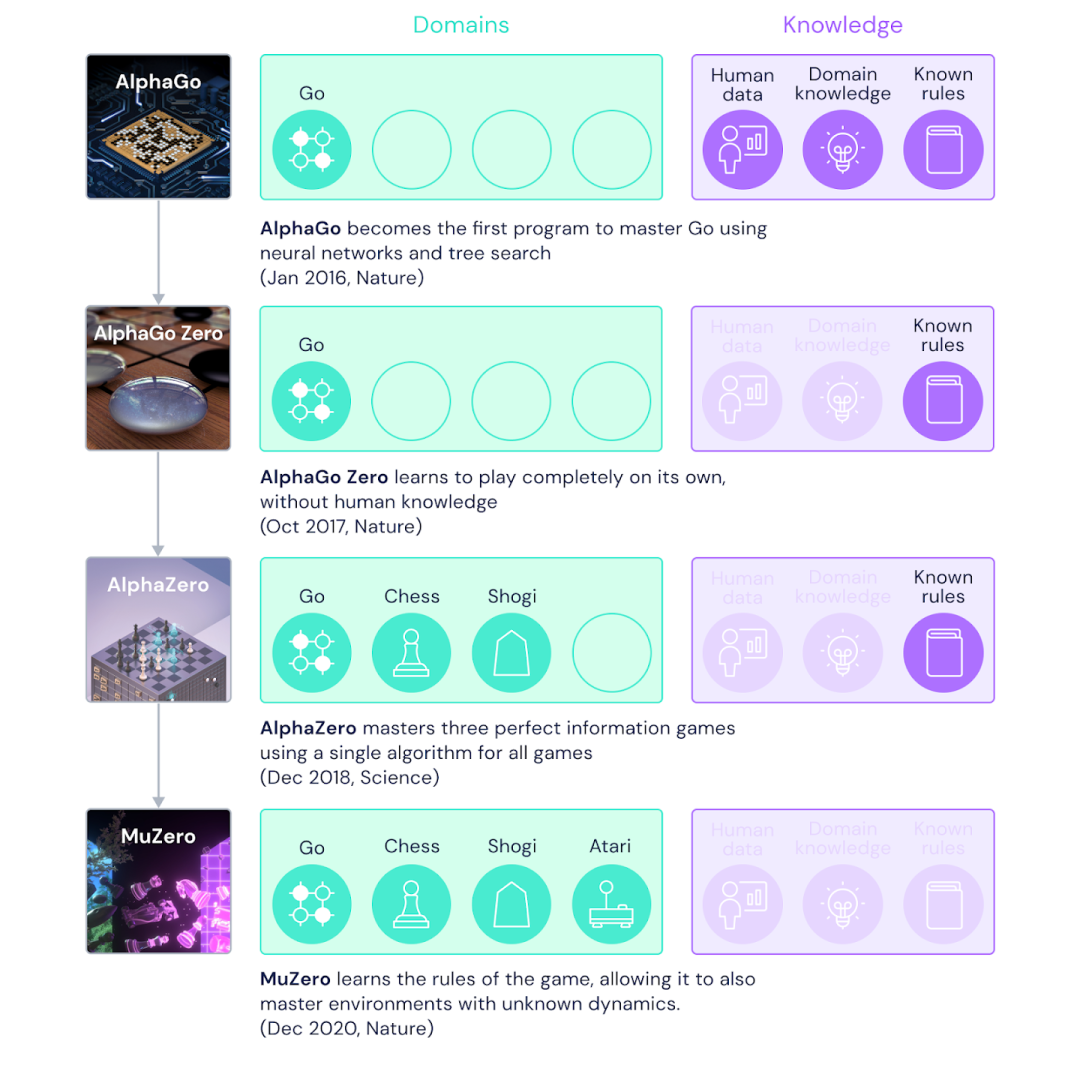 图注:DeepMind游戏AI的进化。
图注:DeepMind游戏AI的进化。
以研究AI打扑克出名的FAIR研究科学家Noam Brown对MuZero评价道:
当前人们对游戏AI的主要批评是:模型不能对现实世界中相互作用进行准确建模。MuZero优雅而令人信服地克服了这个问题(适用于完美信息游戏)。我认为,这是可以与AlphaGo和AlphaZero相提并论的重大突破!


现实世界混乱而复杂,没有人给我们提供有关其运作方式的规则手册。但是人类有能力制定下一步的计划和策略。我们第一次真正拥有了这样的系统,能够建立自己对世界运作方式的理解,并利用这种理解来进行这种复杂的预见性规划,我们以前也在AlphaZero上实现过类似的能力。MuZero可以从零开始,仅通过反复试验就可以发现世界规则,并使用这些规则来实现超人的表现。

1 关于MuZero
 论文地址:https://arxiv.org/pdf/1911.08265.pdf
论文地址:https://arxiv.org/pdf/1911.08265.pdf价值:当前处境的好坏程度 策略:所能采取的最佳行动 奖励:最后一个动作的好坏程度
 图注:如何使用Monte Carlo树搜索与Muzero神经网络进行规划。Muzero从游戏的当前位置开始(动画顶部的示意图),使用表示功能(H)将观察内容映射到神经网络使用的嵌入(S0)。此外,Muzero使用动态函数(G)和预测函数(F)来考虑下一步要采取的动作序列(A),并选择最佳动作。
图注:如何使用Monte Carlo树搜索与Muzero神经网络进行规划。Muzero从游戏的当前位置开始(动画顶部的示意图),使用表示功能(H)将观察内容映射到神经网络使用的嵌入(S0)。此外,Muzero使用动态函数(G)和预测函数(F)来考虑下一步要采取的动作序列(A),并选择最佳动作。 图注:MuZero使用其在与环境互动时所收集的经验训练神经网络。这类经验包括对环境的观察和奖励,以及在决定最佳行动时进行的搜索结果。
图注:MuZero使用其在与环境互动时所收集的经验训练神经网络。这类经验包括对环境的观察和奖励,以及在决定最佳行动时进行的搜索结果。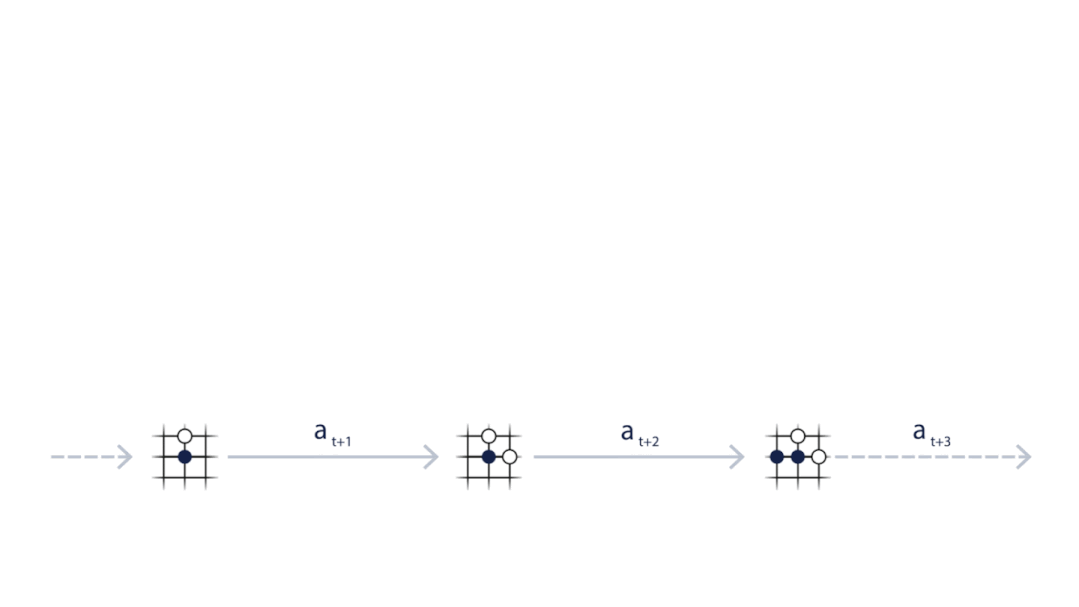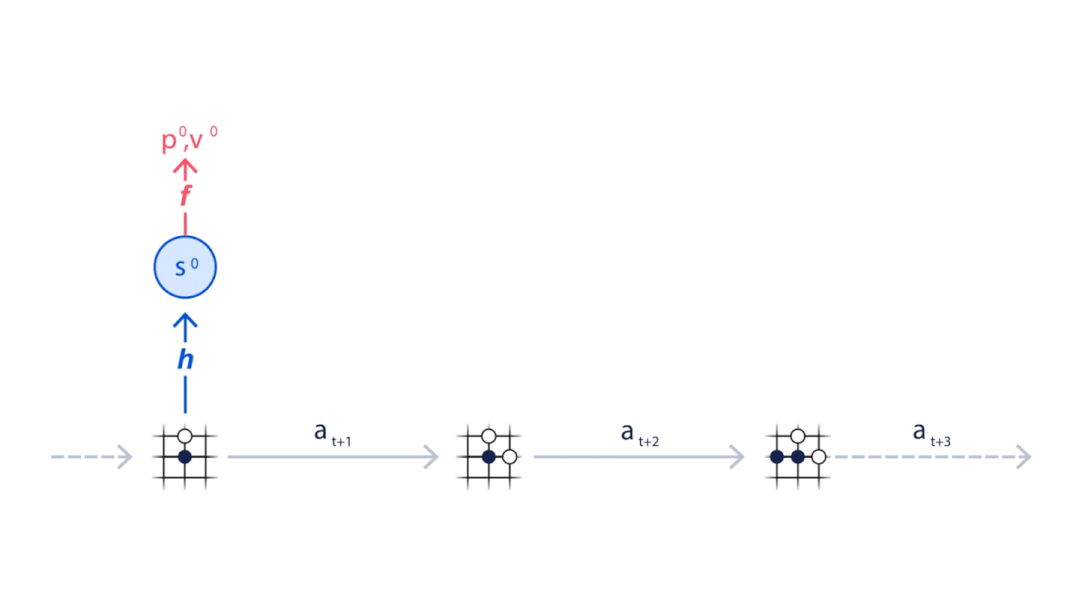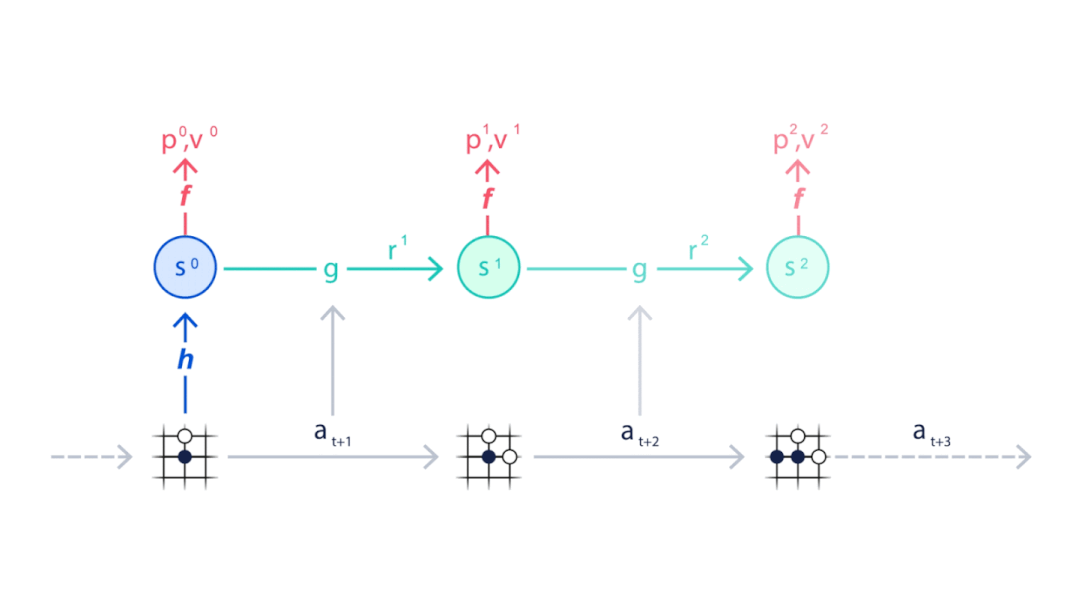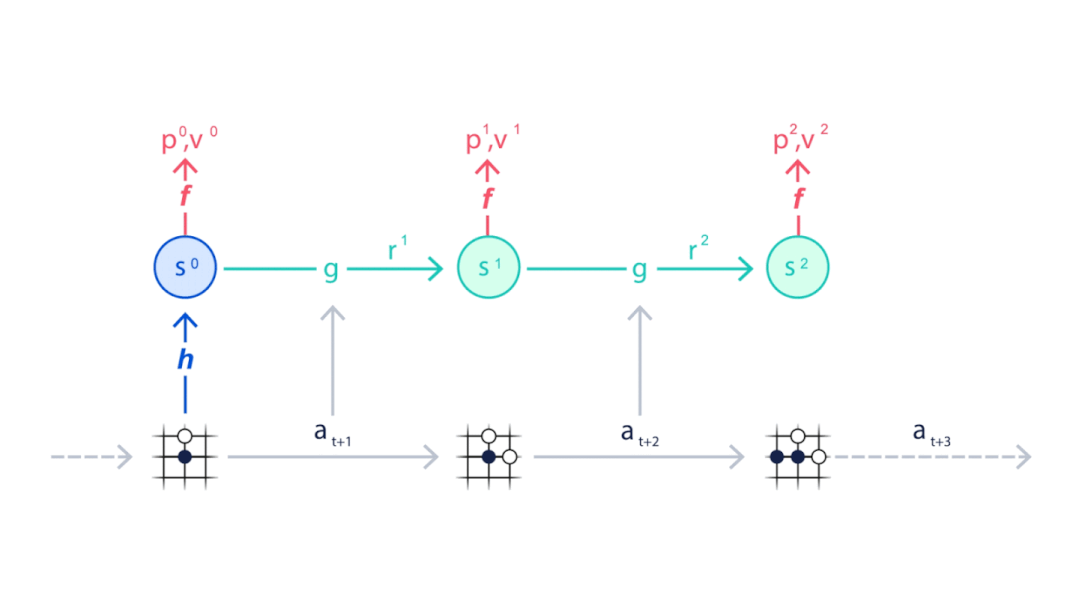 图注:在训练过程中,模型与所收集的经验一同被取消,在每个步骤中预测先前保存的信息:价值函数V预测所观察到的奖励之和(U),策略估计(P)预测之前所进行的搜索,奖励估计R则预测最后观察到的奖励(U)。
图注:在训练过程中,模型与所收集的经验一同被取消,在每个步骤中预测先前保存的信息:价值函数V预测所观察到的奖励之和(U),策略估计(P)预测之前所进行的搜索,奖励估计R则预测最后观察到的奖励(U)。2 Muzero的性能
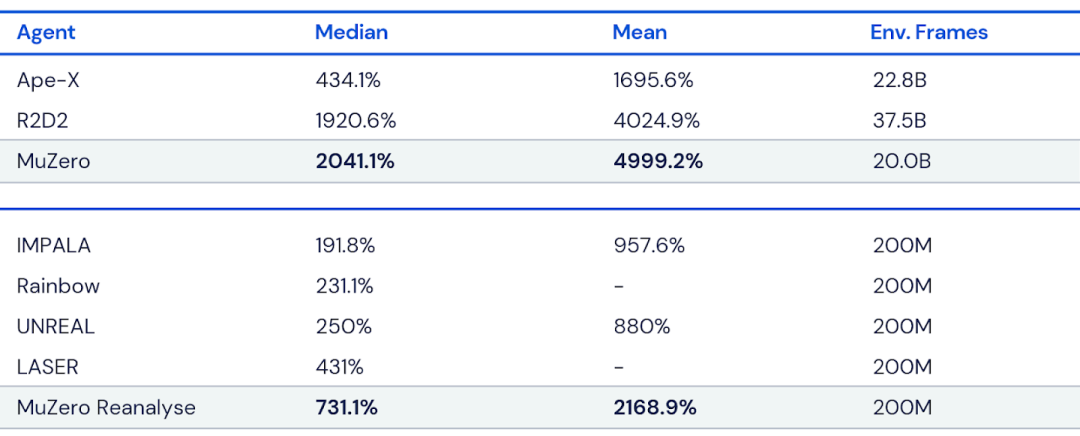 图注:在训练中分别使用2亿帧或200亿帧的MuZero在Atari套件上的性能。MuZero在两个方面都实现了新的SOTA。所有得分均根据人类测试的性能(100%)进行了归一化,每个实验设置的最佳结果以粗体显示。
图注:在训练中分别使用2亿帧或200亿帧的MuZero在Atari套件上的性能。MuZero在两个方面都实现了新的SOTA。所有得分均根据人类测试的性能(100%)进行了归一化,每个实验设置的最佳结果以粗体显示。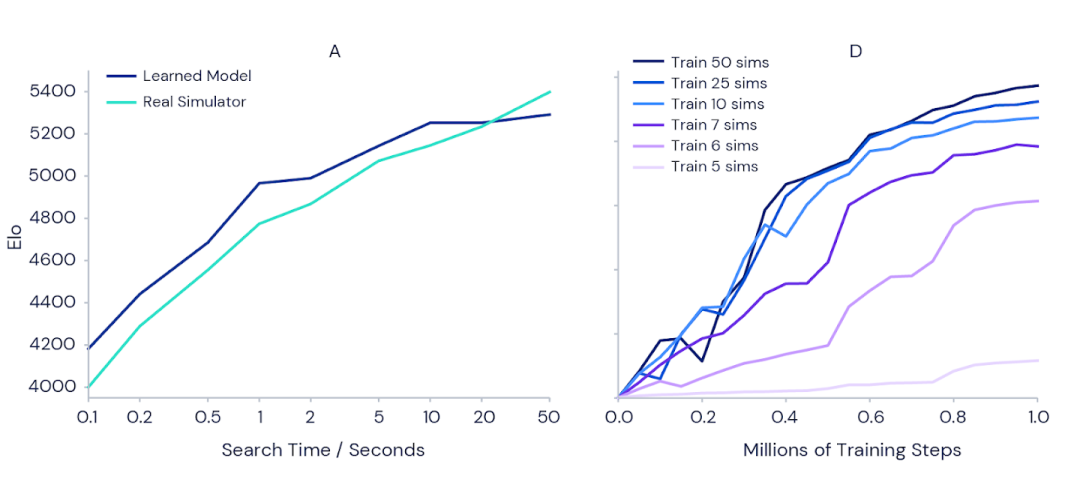 图注:(左)随着规划每次动作的时间的增加,MuZero的围棋能力显着增加。注意MuZero的缩放比例几乎完美地匹配了可以访问完美模拟器的AlphaZero。(右)在训练期间,Atari Games Pac-Man的得分也随着每次行动的规划量而增加。图中每条曲线都显示了一个不同设置的训练运行,MuZero允许考虑每次行动的规划数量不同。
图注:(左)随着规划每次动作的时间的增加,MuZero的围棋能力显着增加。注意MuZero的缩放比例几乎完美地匹配了可以访问完美模拟器的AlphaZero。(右)在训练期间,Atari Games Pac-Man的得分也随着每次行动的规划量而增加。图中每条曲线都显示了一个不同设置的训练运行,MuZero允许考虑每次行动的规划数量不同。参考链接:
推荐阅读

评论