
Google & CMU | 揭示 LLMs 在解决视觉任务方面的无限潜力
来源:CVHub

Title: SPAE: Semantic Pyramid AutoEncoder for Multimodal Generation with Frozen LLMs
Paper: https://arxiv.org/pdf/2306.17842.pdf
Code: https://github.com/google-research/magvit/
导读
今天介绍谷歌和卡耐基梅隆大学的一篇最新的多模态研究工作,用于探索 GPT 等 LLMs 在解决视觉任务的潜力。文章方法表明,只要能够将任意非语言的模态,包括但不仅限于图像等,转化为 LLMs 能够理解的“语言”,便能轻松的实现不同模态的对齐,同时也揭示了 GPT 模型在通过上下文学习解决视觉任务方面的杰出能力。本文方法使得 LLMs 能够更好地执行 AIGC 任务且无需进行任何参数更新步骤。
本文主要介绍了一种名为Semantic Pyramid AutoEncoder, (SPAE)的方法,可以使冻结的语言模型(LLMs)能够执行涉及图像或视频等非语言模态的理解和生成任务。SPAE 将原始像素和从 LLM 词汇表中提取的可解释词汇标记(或单词)之间进行转换。生成的标记捕捉了图像重构所需的语义含义和细粒度细节,有效地将视觉内容转化为 LLM 能理解的语言,并赋予其执行各种多模态任务的能力。通过在多样化的图像理解和生成任务上进行上下文学习实验证明了所提方法的有效性。
文中有一个典型的示例如下:

Examples of text-to-image generation on MNIST using the frozen PaLM 2 model.
作者在上下文中提供了 50 张手写图像,并要求 PaLM 2(一个仅接受文本标记训练的模型)来回答需要生成数字图像作为输出的复杂查询。为了实现这一点,文中使用 SPAE 将图像转换为词汇标记并构造提示。然后,我们要求 PaLM 2 根据给定的 prompt 生成合适的答案。最后,我们将答案标记转换回像素空间并将其显示在图中。
请注意,生成的数字图像与上下文中提供的任何示例都不相同,这里事先并没有“泄漏”给模型。可以看出,PaLM 2 是能够理解图像语义,并结合上下文给出所需的答案。虽然并不是很完美,但笔者相信用不了几年,绝大多数 AI 从业者大概率会面临如今“生化环材”般的窘境,即“赢者通吃,强者越强”的局面,现如今大多数 AI 相关的小作坊生存空间势必会被大大挤压。
动机
本文的动机是探索冻结的语言模型(LLMs)在处理非语言模态(如图像或视频)的任务时的潜力。尽管LLMs在自然语言处理任务中取得了显著进展,但将它们应用于图像生成等非语言任务却具有挑战性。现有方法往往需要在语言模型上进行显式训练,限制了其应用范围。因此,本文旨在提出一种方法,使冻结的LLMs能够直接处理非语言模态的任务,而无需针对该模态进行专门训练。
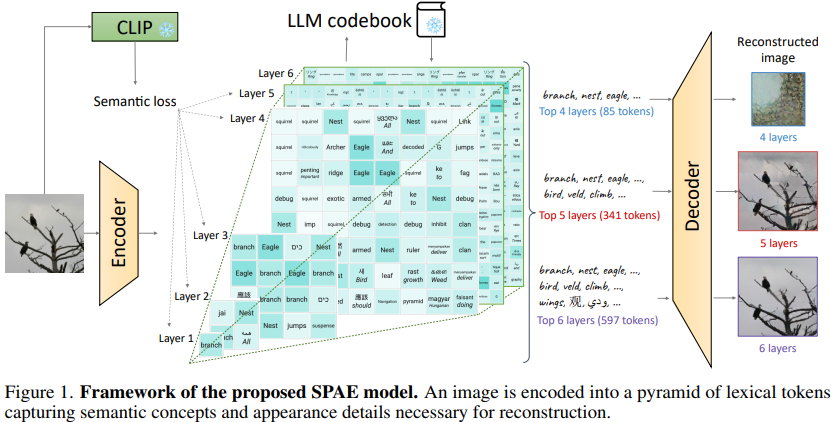
为了实现这一目标,文中提出了Semantic Pyramid AutoEncoder(SPAE)方法,如上图所示。SPAE 通过将原始像素转换为LLM词汇表中的可解释词汇标记,实现了非语言模态和语言模态之间的转换。这些标记不仅捕捉了图像的语义含义,还保留了图像重构所需的细节。SPAE的设计使得我们可以动态调整标记的长度,以适应不同的任务要求。
通过采用上下文学习的方法,在不更新LLMs的任何参数的情况下,验证了SPAE的有效性。实验证明,SPAE使得冻结的LLMs能够成功生成图像内容,并在图像理解任务中超过了当前最先进方法的性能。这表明SPAE方法具有潜力使冻结的LLMs在跨模态任务中发挥出色,并拓展了LLMs的应用领域。
方法
本文旨在将图像或其他非语言模态(如视频或音频)建模为LLMs可以理解的语言序列。为了实现这一目标,论文借助 SPAE 方法生成一个带有可动态调整长度的词汇序列,同时携带丰富的语义和保留用于信号重构的细节。为了通过上下文学习与冻结的 LLMs 合作,额外引入了一种渐进式的上下文去噪方法来促进图像生成。
Semantic Pyramid AutoEncoder
简单来说,SPAE 模型扩展了主流的多模态框架——VQ-VAE,其包括一个编码器、一个量化器和一个解码器。其中,CNN 编码器用于将图像 I 映射到连续的嵌入 Z 中,其中 Z 的每个元素 z 经过量化器,被分配到 codebook 中最近的条目,从而得到量化嵌入表示。其次,CNN 解码器接收量化嵌入作为输入,并生成重构的图像。SPAE 与传统的 VQ-VAE 方法的设计差异在于,SPAE 生成的词汇标记按金字塔结构排列,上层包含语义概念,下层包含越来越精细的外观细节。
此外,为了鼓励使用概念相关的标记,引入了语义损失。生成词汇标记使用了预训练的 LLM 的 codebook 中,并在训练过程中 keep freezed 住。金字塔结构被设计为集中语义概念在金字塔的上层,这样可以用较少的标记数量表示语义概念。
Progressive In-Context Denoising

为了验证方法在冻结的 LLMs 上的可行性,本文采用了上下文学习的极端设置。通过一个渐进的上下文去噪方法,逐步生成图像内容。该方法将生成过程分为多个步骤,每一步生成一小段序列。根据前面已经生成的序列条件,采样下一个序列片段。为了应对分布偏移和序列长度过长的问题,引入了渐进式的生成和上下文去噪。
具体地,首先使用自回归(AR)方法生成前几个标记层,然后使用非自回归(NAR)方法生成剩余的标记层。这种生成方法保证了在每个片段内部是自回归的,但不同片段之间是条件无关的。在上下文去噪方面,为了使生成不仅仅是复制上下文,通过在标记空间中对上下文图像进行随机扰动来产生噪声,然后将扰动后的图像作为条件输入进行图像生成。
通过采用这些方法,本文成功地实现了冻结的LLMs在图像生成任务上的应用,验证了在上下文学习的极端设置下,冻结的LLMs可以生成图像内容的可行性。
实验
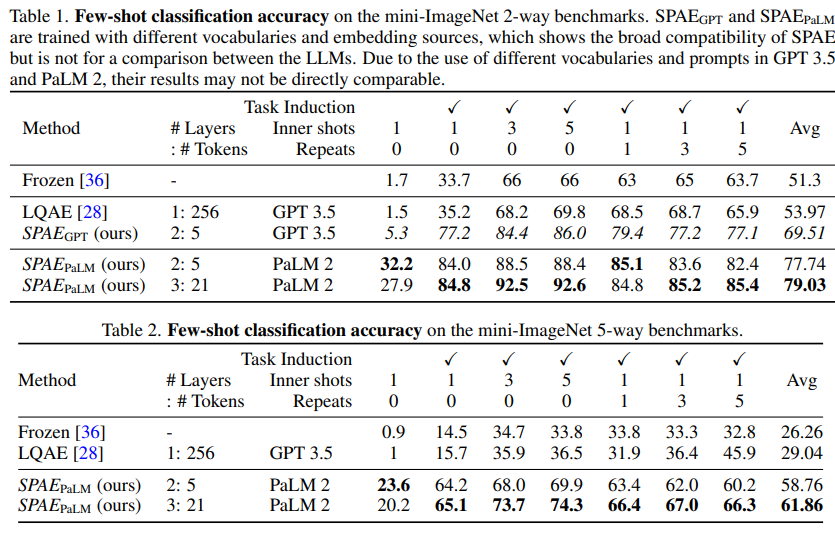
少样本分类迁移能力

在实验部分,首先介绍了条件图像生成任务。通过使用整数作为条件,范围从1到9,定义了一个简单的条件图像生成设置,旨在探索冻结的LLMs的插值能力。目标图像通过不同的图像转换(如亮度、对比度、饱和度和颜色)创建。图中展示了图像1-4和6-9作为上下文输入,生成图像5,模型在可变属性上进行插值。
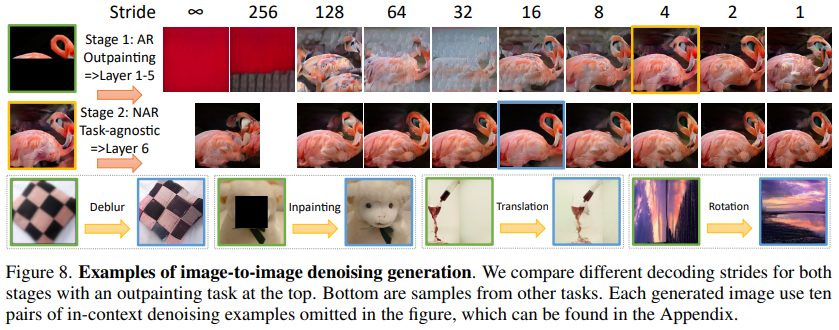
接下来,转向更具挑战性的图像生成任务,即通过条件图像生成目标图像。图中展示了条件图像生成任务的示例,如图像外部填充、去模糊、修补、位置转换、旋转等。为了完成每个任务的图像生成,使用了10对带有不同扰动率(从50%到20%)的上下文去噪示例,如第3.2节所述。图中的顶行比较了使用不同解码步长生成图像的结果,但使用相同的上下文示例。采用无限步长的单步解码无法生成合理的图像,这标志着我们提出的渐进生成技术的重要性。在第一阶段,通过较小的步长(最低为4)观察到了质量的改善。然而,步长为1时由于上下文的丢失而不够理想。在第二阶段,由于任务更简单,大多数试验都生成了合理的图像,我们采用步长16来平衡效率和质量。
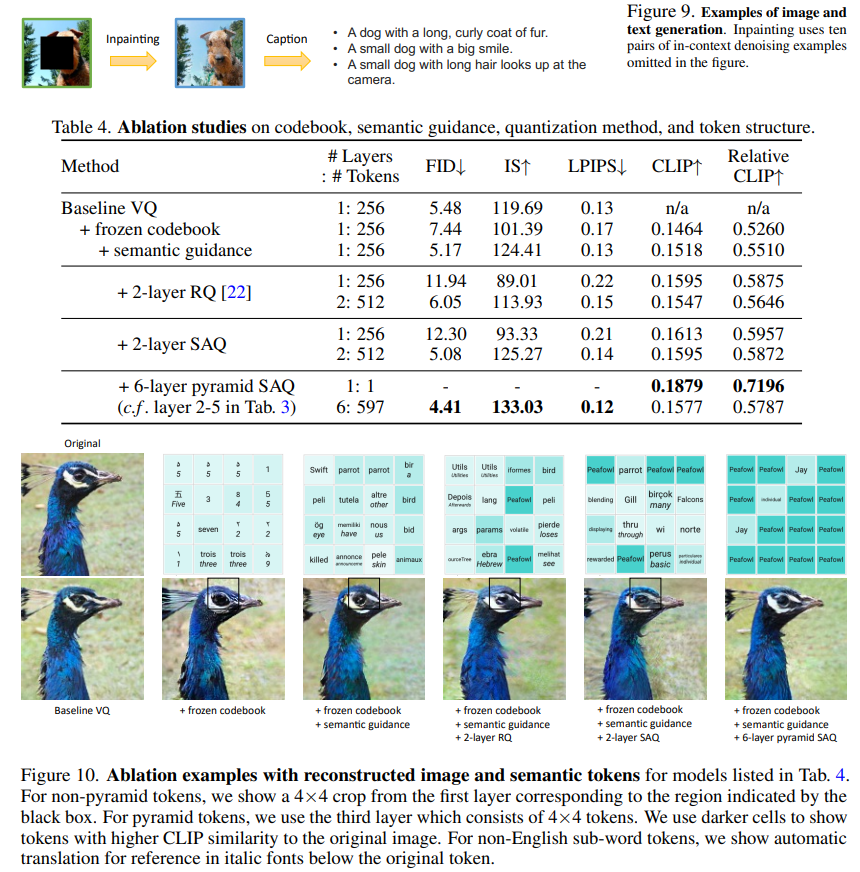
最后,展示了一项任务,要求单个LLM生成图像和文本。首先,通过上下文去噪对图像的中心区域进行修复,然后为生成的图像创建标题。
总的来说,这些实验结果展示了本文方法在图像生成和图像与文本生成任务上的应用。通过使用冻结的LLMs和上下文学习的方法,成功地生成了具有条件的图像,并实现了在单个模型中生成图像和文本的能力。
总结
本文通过提出一种新方法 SPAE,揭示了冻结的大型语言模型(LLMs)在处理涉及图像和视频的多模态理解和生成任务中的潜力,而无需对这些模态进行显式训练。SPAE 通过将视觉内容和具有丰富语义意义的可变长度的词汇标记之间进行转换来实现这一目标。研究结果显示了利用LLMs丰富的知识和推理能力在计算机视觉领域的巨大潜力,超越了仅限于语言任务的限制。
然而,模型的上下文学习能力仍然会受到可接受序列长度的显著限制。虽然实验结果表明图像生成的可行性,但生成的图像质量和多样性仍远远落后于最近训练于配对图像和文本数据的文本到图像模型。因此,在学习上下文和能力方面与最近专门针对文本到图像(例如Stable Diffusion)或图像到文本的专门训练模型相比。仍存在相当大的差距。