
动漫界的ImageNet来了!人脸数据集AnimeCeleb,240万张图片生成「萌萌哒」动漫脸

新智元报道
新智元报道
编辑:小咸鱼
【新智元导读】韩国科学技术院最近的一项研究提出了一个大规模的动漫人脸数据集AnimeCeleb,以促进动漫人脸领域的研究。AnimeCeleb内含240万张图片,全部依赖于3D模型渲染,堪称动漫人脸数据集的ImageNet。
想看看全球首富马斯克变成二次元的样子吗?
当当当当!

图片来源:https://huggingface.co/spaces/akhaliq/AnimeGANv2
怎么还有一丝妩媚呢?
近日,在huggingface社区上,最强动漫风格迁移模型AnimeGAN的迭代版AnimeGANv2上线了一个体验demo出来。
多年来,动漫角色与人类同行,扮演着挚爱的朋友,在日常生活中给很多人以情感安慰。
随着他们的流行,动漫角色已经不局限于娱乐行业或营销领域,计算机视觉和图形学的最新进展进一步加速了角色的广泛传播,为个人创作者轻松设计自己的角色并在公共在线平台上展示他们的作品铺平了道路。
其中,动漫角色设计和深度学习相结合的作品也越来越多。
不过,虽然基于深度学习的人脸生成GAN取得了显著的成功,但这些模型仍然局限于真实人脸的领域。
而由于缺乏动漫风的人脸数据集,动漫人脸生成领域的工作目前还不够深入。
大规模的动漫人脸数据集
大规模的动漫人脸数据集
韩国科学技术院最近的一项研究提出了一个大规模的动漫人脸数据集AnimeCeleb,以促进动漫人脸领域的研究。

https://arxiv.org/pdf/2111.07640.pdf
为了简化动漫人脸数据集的生成过程,他们通过可控的合成动漫模型,基于一个开放的三维软件和一个注释系统构建了一个半自动管道,可以构建大规模动漫人脸数据集,包括具有丰富注释的多姿态和多风格动漫人脸。

AnimeCeleb的随机抽样例子
并且实验表明,该数据集适用于各种与动漫相关的任务,例如头部重现和着色。
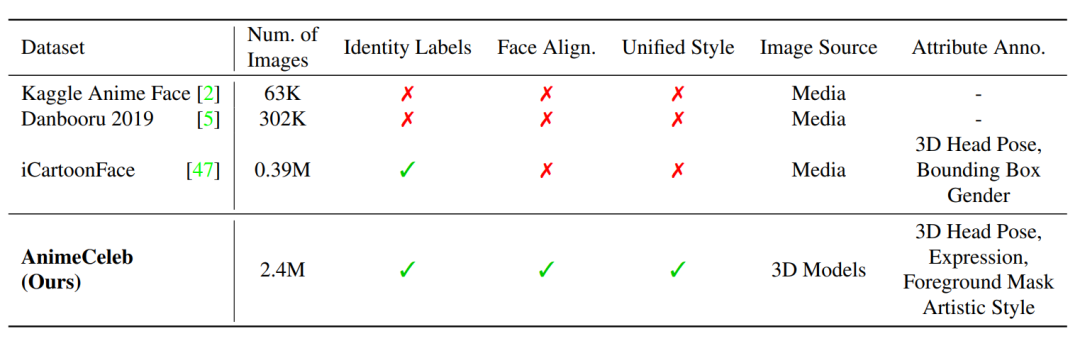
与公开的现有动漫人脸数据集相比,AnimeCeleb内含240万张图片,全部依赖于3D模型渲染来构建动漫人脸数据集。
这确保了大规模数据集包含详细的注释以及具有相同身份的多姿态图像。此外,考虑到不同的绘画方式,动漫还包含多种风格。
这简直就是动漫人脸数据集的ImageNet呀!
如何制作?
如何制作?
那这样庞大的动漫人脸数据集是如何制作出来的呢?
第一步,数据收集(A.1)。在过滤掉不合适的外观动漫模型后,总共获得了3613个可用的三维动漫模型。
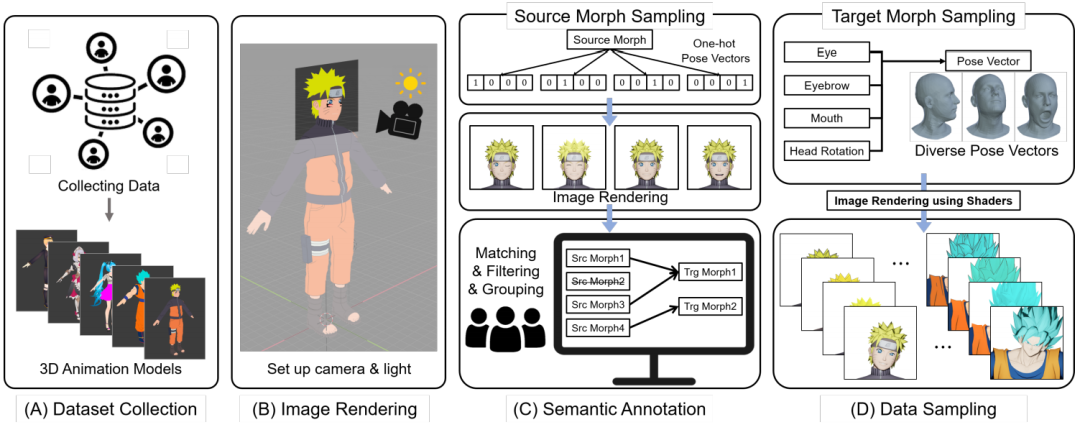
数据集生成管道概述
第二步,3D动漫模型描述(A.2)。收集的3D动漫模型不仅包含动漫角色的完整身体信息,如3D网格、骨骼和纹理组件,还包含可以改变3D模型外观的变形量。
为每个变形量指定一个标量值,我们可以改变3D模型的相关属性(例如,张开/闭上嘴,张开/闭上眼睛)。

目标变形的可视化示例(前四列)和三维头部旋转(最后一列)
第三步,图像渲染(B)。为了从3D动漫模型中自动采样动漫人脸图像的过程,他们新开发了一个2D人脸图像生成系统,该系统建立在支持3D模型可视化、操作和渲染的开源3D计算机图形软件Blender上。
第四步,语义标注(C)。语义标注步骤的目标是识别面部表情相关的形态,并根据语义准确和统一的命名约定对形态进行标注。重要的是,这使我们能够在对面部表情相关的变形进行采样时,对所有3D动漫模型应用一致的姿势采样策略。
最后一步,数据采样(D)。对于采样,随机采样人脸的每个部分(即眼睛、眉毛和嘴)的目标变形被应用于三维动漫模型。通过从均匀分布[0,1]中独立采样来确定形变的幅度。
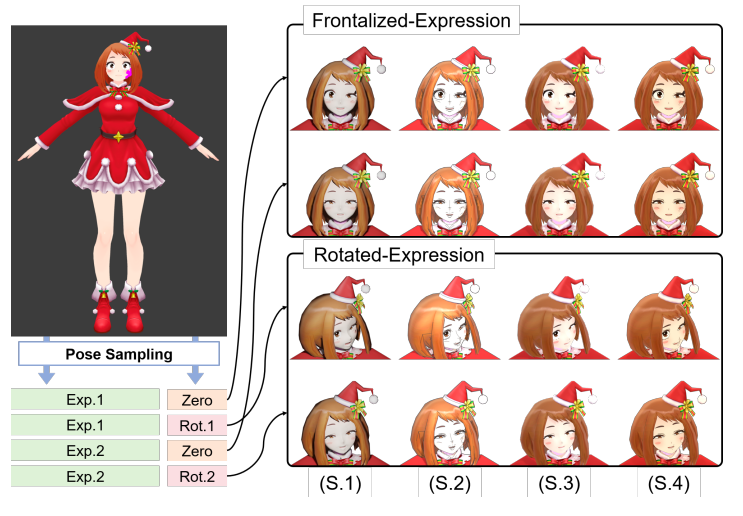
采样数据示例
实验结果
实验结果
在任务选择过程中,研究人员重点展示了对动漫相关任务的适用性和动漫跨身份头像重现结果。
头像重现任务旨在将动漫风格从风格驱动图像转移到源图像,同时保留源身份。由于AnimeCeleb属性包含多个相同身份的图像,他们实现了两个代表性的基线:FOMM和PIRenderer。
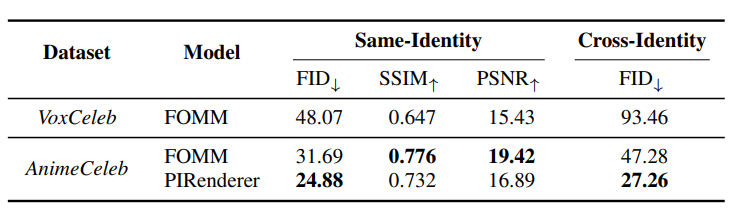
头像重现的定量结果。显然,在AnimeCeleb上训练优于在VoxCeleb上训练。
结果显而易见,在AnimeCeleb测试集上测试时,在AnimeCeleb上训练的模型优于在VoxCeleb上训练的基线模型。
域外(Out-of-Domain)动漫头像重现结果也非常棒。

给定来自Waifu数据集的源图像(第1列)和来自AnimeCeleb的驱动图像(第2列),仅使用AnimeCeleb训练的FOMM和PIRenderer都成功地将驱动图像的风格转移到源图像。
研究人员还用AnimeCeleb训练模型去发现样本中语义一致的部分,比如:整体面部、头部和颌骨等等。

动漫人脸语义分割结果,训练好的模型能够识别不同图像中的一致语义。
在动漫领域,自动着色是动漫创作者在劳动密集型绘画过程中减少工作量的重要任务。使用经过训练的彩色化模型,创作者能够获得给定草图图像的彩色化图像。
使用用AnimeCeleb训练的基线,可以绘制出良好的动漫角色草图图像,自动生成彩色化输出。

通过参考域内和域外图像,用AnimeCeleb训练的Pix2Pix成功输出彩色图像。
在未来的工作中,AnimeCeleb还会进一步被扩展,以在多视图环境中提供更多样的面部表情。
参考资料:
https://arxiv.org/pdf/2111.07640.pdf https://twitter.com/ak92501/status/1460436967905280002
