
深入解析Apache Pulsar系列(一):客户端消息确认


导语
在 Apache Pulsar 中,为了避免消息的重复投递,消费者进行消息确认是非常重要的一步。当一条消息被消费者消费后,需要消费者发送一个Ack请求给Broker,Broker才会认为这条消息被真正消费掉。被标记为已经消费的消息,后续不会再次重复投递给消费者。在这篇文章中,我们会介绍Pulsar中消息确认的模式,以及正常消息确认在Broker侧是如何实现的。
作者简介
林琳
腾讯云中间件专家工程师
Apache Pulsar PMC,《深入解析Apache Pulsar》作者。目前专注于中间件领域,在消息队列和微服务方向具有丰富的经验。负责 CKafka、TDMQ的设计与开发工作,目前致力于打造稳定、高效和可扩展的基础组件与服务。

确认消息的模式
在了解Pulsar消息确认模式之前,我们需要先了解一些前置知识 —— Pulsar中的订阅以及游标(Cursor)。Pulsar中有多种消费模式,如:Share、Key_share、Failover等等,无论用户使用哪种消费模式都会创建一个订阅。订阅分为持久订阅和非持久订阅,对于持久订阅,Broker上会有一个持久化的Cursor,即Cursor的元数据被记录在ZooKeeper。Cursor以订阅(或称为消费组)为单位,保存了当前订阅已经消费到哪个位置了。因为不同消费者使用的订阅模式不同,可以进行的Ack行为也不一样。总体来说可以分为以下几种Ack场景:
1. 单条消息确认(Acknowledge)
和其他的一些消息系统不同,Pulsar支持一个Partition被多个消费者消费。假设消息1、2、3发送给了Consumer-A,消息4、5、6发送给了Consumer-B,而Consumer-B又消费的比较快,先Ack了消息4,此时Cursor中会单独记录消息4为已Ack状态。如果其他消息都被消费,但没有被Ack,并且两个消费者都下线或Ack超时,则Broker会只推送消息1、2、3、5、6,已经被Ack的消息4不会被再次推送。
2. 累积消息确认(AcknowledgeCumulative)
假设Consumer接受到了消息1、2、3、4、5,为了提升Ack的性能,Consumer可以不分别Ack 5条消息,只需要调用AcknowledgeCumulative,然后把消息5传入,Broker会把消息5以及之前的消息全部标记为已Ack。
3. 累积消息确认(AcknowledgeCumulative)
这种消息确认模式,调用的接口和单条消息的确认一样,但是这个能力需要Broker开启配置项AcknowledgmentAtBatchIndexLevelEnabled。当开启后,Pulsar可以支持只Ack一个Batch里面的某些消息。假设Consumer拿到了一个批消息,里面有消息1、2、3,如果不开启这个选项,我们只能消费整个Batch再Ack,否则Broker会以批为单位重新全部投递一次。前面介绍的选项开启之后,我们可以通过Acknowledge方法来确认批消息中的单条消息。
4. 否定应答(NegativeAcknowledge)
客户端发送一个RedeliverUnacknowledgedMessages命令给Broker,明确告知Broker,当前Consumer无法消费这条消息,消息将会被重新投递。
并不是所有的订阅模式下都能用上述这些Ack行为,例如:Shared或者Key_shared模式下就不支持累积消息确认(AcknowledgeCumulative)。因为在Shared或者Key_shared模式下,前面的消息不一定是被当前Consumer消费的,如果使用AcknowledgeCumulative,会把别人的消息也一起确认掉。订阅模式与消息确认之间的关系如下所示:
订阅模式 | 单条Ack | 累积Ack | 批量消息中单个Ack |
Exclusive | 支持 | 支持 | 支持 |
Shared | 支持 | 不支持 | 支持 |
Failover | 支持 | 支持 | 支持 |
Key_Shared | 支持 | 不支持 | 支持 |
Acknowledge与AcknowledgeCumulative的实现
Acknowledge与AcknowledgeCumulative接口不会直接发送消息确认请求给Broker,而是把请求转交给AcknowledgmentsGroupingTracker处理。这是我们要介绍的Consumer里的第一个Tracker,它只是一个接口,接口下有两个实现,一个是持久化订阅的实现,另一个是非持久化订阅的实现。由于非持久化订阅的Tracker实现都是空,即不做任何操作,因此我们只介绍持久化订阅的实现——PersistentAcknowledgmentsGroupingTracker。
在Pulsar中,为了保证消息确认的性能,并避免Broker接收到非常高并发的Ack请求,Tracker中默认支持批量确认,即使是单条消息的确认,也会先进入队列,然后再一批发往Broker。我们在创建Consumer时可以设置参数AcknowledgementGroupTimeMicros,如果设置为0,则Consumer每次都会立即发送确认请求。所有的单条确认(IndividualAck)请求会先放入一个名为PendingIndividual Acks的Set,默认是每100ms或者堆积的确认请求超过1000,则发送一批确认请求。
消息确认的请求最终都是异步发送出去,如果Consumer设置了需要回执(Receipt),则会返回一个CompletableFuture,成功或失败都能通过Future感知到。默认都是不需要回执的,此时直接返回一个已经完成的CompletableFuture。
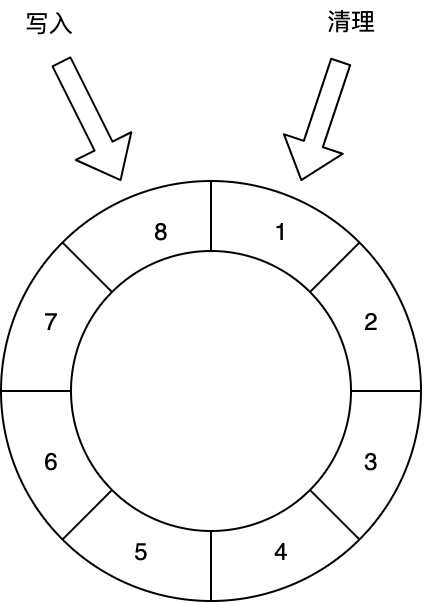
对于Batch消息中的单条确认(IndividualBatchAck),用一个名为PendingIndividualBatchIndexAcks的Map进行保存,而不是普通单条消息的Set。这个Map的Key是Batch消息的MessageId,Value是一个BitSet,记录这批消息里哪些需要Ack。使用BitSet能大幅降低保存消息Id的能存占用,1KB能记录8192个消息是否被确认。由于BitSet保存的内容都是0和1,因此可以很方便地保存在堆外,BitSet对象也做了池化,可以循环使用,不需要每次都创建新的,对内存非常友好。
如下图所示,只用了8位,就表示了Batch里面8条消息的Ack情况,下图表示EntryId为0、2、5、6、7的Entry都被确认了,确认的位置会被置为1:

对于累计确认(CumulativeAck)实现方式就更简单了,Tracker中只保存最新的确认位置点即可。例如,现在Tracker中保存的CumulativeAck位置为5:10,代表该订阅已经消费到LedgerId=5,EntryId=10的这条消息上了。后续又Ack了一个5:20,则直接替换前面的5:10为5:20即可。
最后就是Tracker的Flush,所有的确认最终都需要通过触发Flush方法发送到Broker,无论是哪种确认,Flush时创建的都是同一个命令并发送给Broker,不过传参中带的AckType会不一样。
NegativeAcknowledge的实现
否定应答和其他消息确认一样,不会立即请求Broker,而是把请求转交给NegativeAcksTracker进行处理。Tracker中记录着每条消息以及需要延迟的时间。Tracker复用了PulsarClient的时间轮,默认是33ms左右一个时间刻度进行检查,默认延迟时间是1分钟,抽取出已经到期的消息并触发重新投递。Tracker主要存在的意义是为了合并请求。另外如果延迟时间还没到,消息会暂存在内存,如果业务侧有大量的消息需要延迟消费,还是建议使用ReconsumeLater接口。NegativeAck唯一的好处是,不需要每条消息都指定时间,可以全局设置延迟时间。
未确认消息的处理
如果消费者获取到消息后一直不Ack会怎么样?这要分两种情况,第一种是业务侧已经调用了Receive方法,或者已经回调了正在异步等待的消费者,此时消息的引用会被保存进UnAckedMessageTracker,这是Consumer里的第三个Tracker。UnAckedMessageTracker中维护了一个时间轮,时间轮的刻度根据AckTimeout、TickDurationInMs这两个参数生成,每个刻度时间=AckTimeout / TickDurationInMs。新追踪的消息会放入最后一个刻度,每次调度都会移除队列头第一个刻度,并新增一个刻度放入队列尾,保证刻度总数不变。每次调度,队列头刻度里的消息将会被清理,UnAckedMessageTracker会自动把这些消息做重投递。
重投递就是客户端发送一个RedeliverUnacknowledgedMessages命令给Broker。每一条推送给消费者但是未Ack的消息,在Broker侧都会有一个集合来记录(PengdingAck),这是用来避免重复投递的。触发重投递后,Broker会把对应的消息从这个集合里移除,然后这些消息就可以再次被消费了。注意,当重投递时,如果消费者不是Share模式是无法重投递单条消息的,只能把这个消费者所有已经接收但是未ack的消息全部重新投递。下图是一个时间轮的简单示例:
另外一种情况就是消费者做了预拉取,但是还没调用过任何Receive方法,此时消息会一直堆积在本地队列。预拉取是客户端SDK的默认行为,会预先拉取消息到本地,我们可以在创建消费者时通过ReceiveQueueSize参数来控制预拉取消息的数量。Broker侧会把这些已经推送到Consumer本地的消息记录为PendingAck,并且这些消息也不会再投递给别的消费者,且不会Ack超时,除非当前Consumer被关闭,消息才会被重新投递。Broker侧有一个Redelivery Tracker接口,暂时的实现是内存追踪(InMemoryRedeliveryTracker)。这个Tracker会记录消息到底被重新投递了多少次,每条消息推送给消费者时,会先从Tracker的哈希表中查询一下重投递的次数,和消息一并推送给消费者。
由上面的逻辑我们可以知道,创建消费者时设置的Receive QueueSize真的要慎重,避免大量的消息堆积在某一个Consumer的本地预拉取队列,而其他Consumer又没有消息可消费。
PulsarClient上可以设置启用ConsumerStatsRecorder,启用后,消费者会在固定间隔会打印出当前消费者的metrics信息,例如:本地消息堆积量、接受的消息数等,方便业务排查性能问题。
后记
Pulsar中的设计细节非常多,由于篇幅有限,作者会整理一系列的文章进行技术分享,敬请期待。如果各位希望系统性地学习Pulsar,可以购买作者出版的新书《深入解析Apache Pulsar》。

扫描上方二维码了解详情
One More Thing
目前,腾讯云消息队列 TDMQ (Tencent Distributed Message Queue)已上线,TDMQ是腾讯基于 Apache Pulsar 自研的一个云原生消息中间件系列,其中包含兼容Pulsar、RabbitMQ、RocketMQ 等协议的消息队列子产品,得益于其底层计算与存储分离的架构,TDMQ 具备良好的弹性伸缩以及故障恢复能力。欢迎大家查看并使用:
https://cloud.tencent.com/product/tdmq
往期
推荐
《ZooKeeper系列文章:ZooKeeper 源码和实践揭秘(一)》
《Kratos技术系列|从Kratos设计看Go微服务工程实践》
《Pulsar技术系列 - 深度解读Pulsar Schema》
《Apache Pulsar事务机制原理解析|Apache Pulsar 技术系列》

扫描下方二维码关注本公众号,
了解更多微服务、消息队列的相关信息!
解锁超多鹅厂周边!


点个在看你最好看