
[]*T *[]T *[]*T 傻傻分不清楚
 前言
前言
作为一个 Go 语言新手,看到一切”诡异“的代码都会感到好奇;比如我最近看到的几个方法;伪代码如下:
func FindA() ([]*T,error) {
}
func FindB() ([]T,error) {
}
func SaveA(data *[]T) error {
}
func SaveB(data *[]*T) error {
}
相信大部分刚入门 Go 的新手看到这样的代码也是一脸懵逼,其中最让人疑惑的就是:
[]*T
*[]T
*[]*T
这样对切片的声明,先不看后面两种写法;单独看 []*T 还是很好理解的:该切片中存放的是所有 T 的内存地址,会比存放 T 本身来说要更省空间,同时 []*T 在方法内部是可以修改 T 的值,而[]T 是修改不了。
func TestSaveSlice(t *testing.T) {
a := []T{{Name: "1"}, {Name: "2"}}
for _, t2 := range a {
fmt.Println(t2)
}
_ = SaveB(a)
for _, t2 := range a {
fmt.Println(t2)
}
}
func SaveB(data []T) error {
t := data[0]
t.Name = "1233"
return nil
}
type T struct {
Name string
}
比如以上例子打印的是
{1}
{2}
{1}
{2}
只有将方法修改为
func SaveB(data []*T) error {
t := data[0]
t.Name = "1233"
return nil
}
才能修改 T 的值:
&{1}
&{2}
&{1233}
&{2}
下面重点来看看 []*T 与 *[]T 的区别,这里写了两个 append 函数:
func TestAppendA(t *testing.T) {
x:=[]int{1,2,3}
appendA(x)
fmt.Printf("main %v\n", x)
}
func appendA(x []int) {
x[0]= 100
fmt.Printf("appendA %v\n", x)
}
先看第一种,输出是结果是:
appendA [1000 2 3]
main [1000 2 3]
说明在函数传递过程中,函数内部的修改能够影响到外部。
下面我们再看一个例子:
func appendB(x []int) {
x = append(x, 4)
fmt.Printf("appendA %v\n", x)
}
最终结果却是:
appendA [1 2 3 4]
main [1 2 3]
没有影响到外部。
而当我们再调整一下会发现又有所不同:
func TestAppendC(t *testing.T) {
x:=[]int{1,2,3}
appendC(&x)
fmt.Printf("main %v\n", x)
}
func appendC(x *[]int) {
*x = append(*x, 4)
fmt.Printf("appendA %v\n", x)
}
最终的结果:
appendA &[1 2 3 4]
main [1 2 3 4]
可以发现如果传递切片的指针时,使用 append 函数追加数据时会影响到外部。
在分析上面三种情况之前,我们先来了解下 slice 的数据结构。
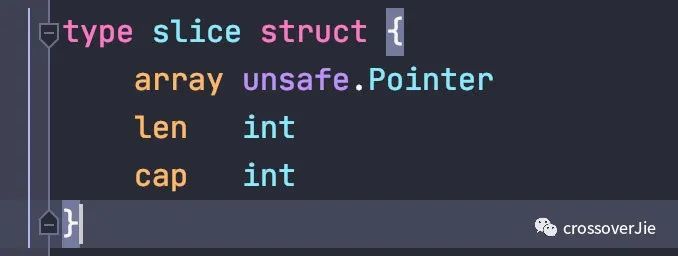
直接查看源码会发现 slice 其实就是一个结构体,只是不能直接对外访问。
源码地址
runtime/slice.go
其中有三个重要的属性:
| 属性 | 含义 |
|---|---|
| array | 底层存放数据的数组,是一个指针。 |
| len | 切片长度 |
| cap | 切片容量 cap>=len |
提到切片就不得不想到数组,可以这么理解:
切片是对数组的抽象,而数组则是切片的底层实现。
其实通过切片这个名字也不难看出,它就是从数组中切了一部分;相对于数组的固定大小,切片可以根据实际使用情况进行扩容。
所以切片也可以通过对数组"切一刀"获得:
x1:=[6]int{0,1,2,3,4,5}
x2 := x[1:4]
fmt.Println(len(x2), cap(x2))
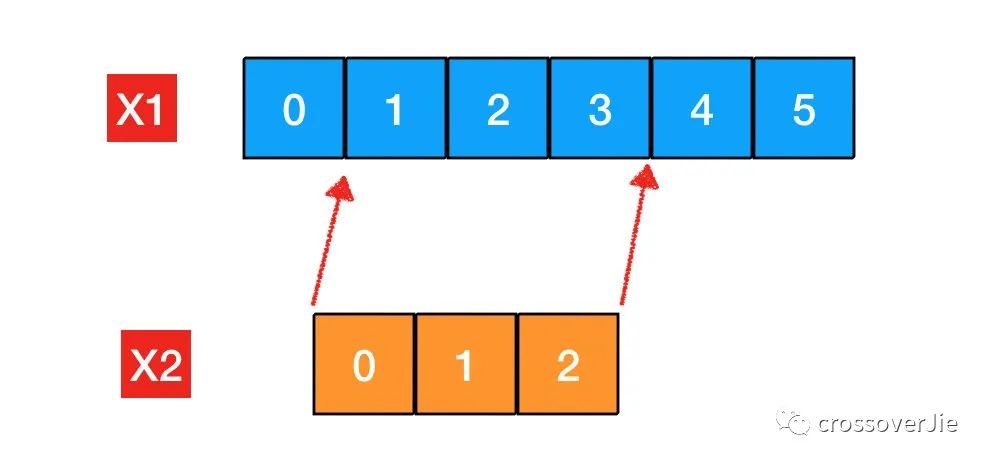
其中 x1 的长度与容量都是6。
x2 的长度与容量则为3和5。
- x2 的长度很容易理解。
- 容量等于5可以理解为,当前这个切片最多可以使用的长度。
因为切片 x2 是对数组 x1 的引用,所以底层数组排除掉左边一个没有被引用的位置则是该切片最大的容量,也就是5。
同一个底层数组
以刚才的代码为例:
func TestAppendA(t *testing.T) {
x:=[]int{1,2,3}
appendA(x)
fmt.Printf("main %v\n", x)
}
func appendA(x []int) {
x[0]= 100
fmt.Printf("appendA %v\n", x)
}
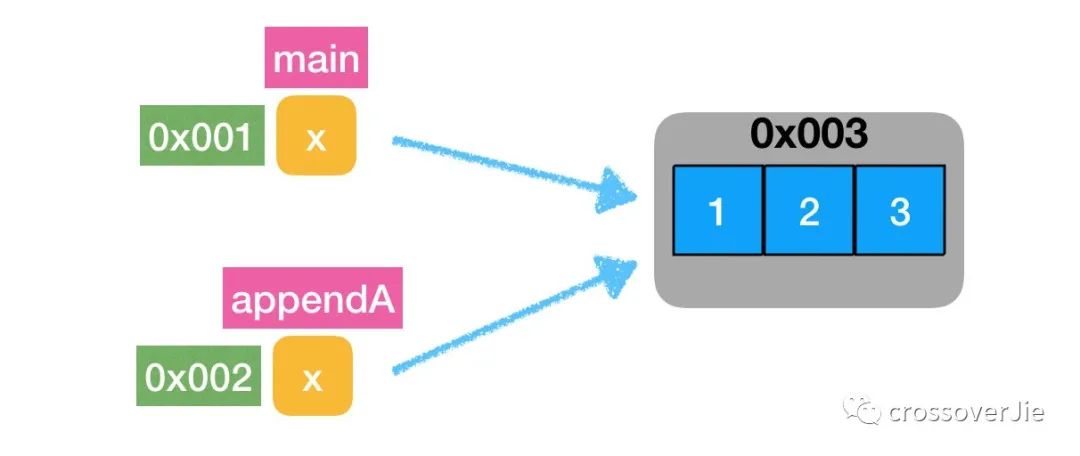
在函数传递过程中,main 中的 x 与 appendA 函数中的 x 切片所引用的是同个数组。
所以在函数中对 x[0]=100,main函数中也能获取到。
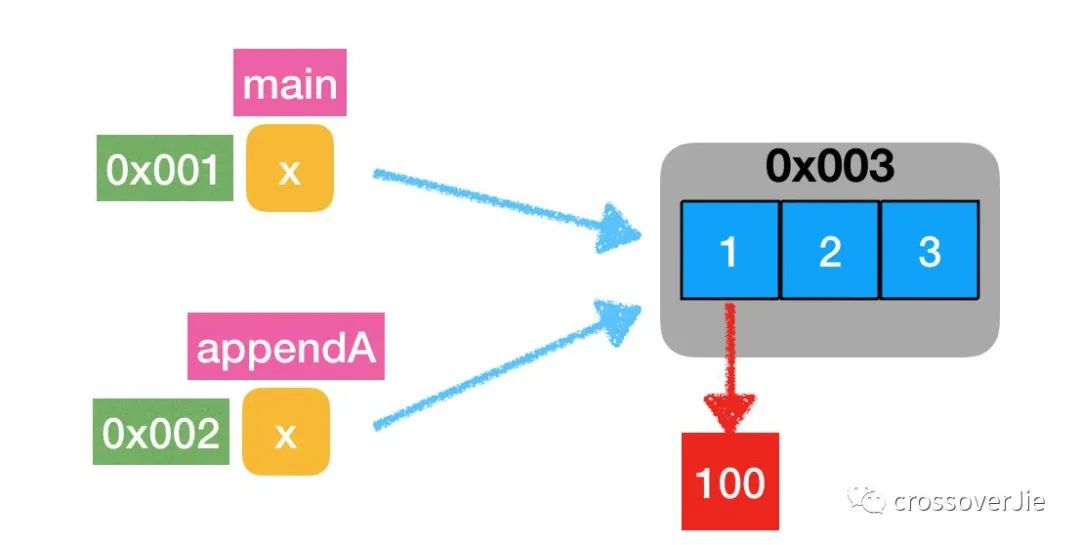
本质上修改的就是同一块内存数据。
值传递带来的误会
在上述例子中,在 appendB 中调用 append 函数追加数据后会发现 main 函数中并没有受到影响,这里我稍微调整了一下示例代码:
func TestAppendB(t *testing.T) {
//x:=[]int{1,2,3}
x := make([]int, 3,5)
x[0] = 1
x[1] = 2
x[2] = 3
appendB(x)
fmt.Printf("main %v len=%v,cap=%v\n", x,len(x),cap(x))
}
func appendB(x []int) {
x = append(x, 444)
fmt.Printf("appendB %v len=%v,cap=%v\n", x,len(x),cap(x))
}
主要是修改了切片初始化方式,使得容量大于了长度,具体原因后续会说明。
输出结果如下:
appendB [1 2 3 444] len=4,cap=5
main [1 2 3] len=3,cap=5
main 函数中的数据看样子确实没有受到影响;但细心的朋友应该会注意到 appendB 函数中的 x 在 append() 之后长度 +1 变为了4。
而在 main 函数中长度又变回了3.
这个细节区别就是为什么 append() "看似" 没有生效的原因;至于为什么要说“看似”,再次调整了代码:
func TestAppendB(t *testing.T) {
//x:=[]int{1,2,3}
x := make([]int, 3,5)
x[0] = 1
x[1] = 2
x[2] = 3
appendB(x)
fmt.Printf("main %v len=%v,cap=%v\n", x,len(x),cap(x))
y:=x[0:cap(x)]
fmt.Printf("y %v len=%v,cap=%v\n", y,len(y),cap(y))
}
在刚才的基础之上,以 append 之后的 x 为基础再做了一个切片;该切片的范围为 x 所引用数组的全部数据。
再来看看执行结果如何:
appendB [1 2 3 444] len=4,cap=5
main [1 2 3] len=3,cap=5
y [1 2 3 444 0] len=5,cap=5
会神奇的发现 y 将所有数据都打印出来,在 appendB 函数中追加的数据其实已经写入了数组中,但为什么 x 本身没有获取到呢?
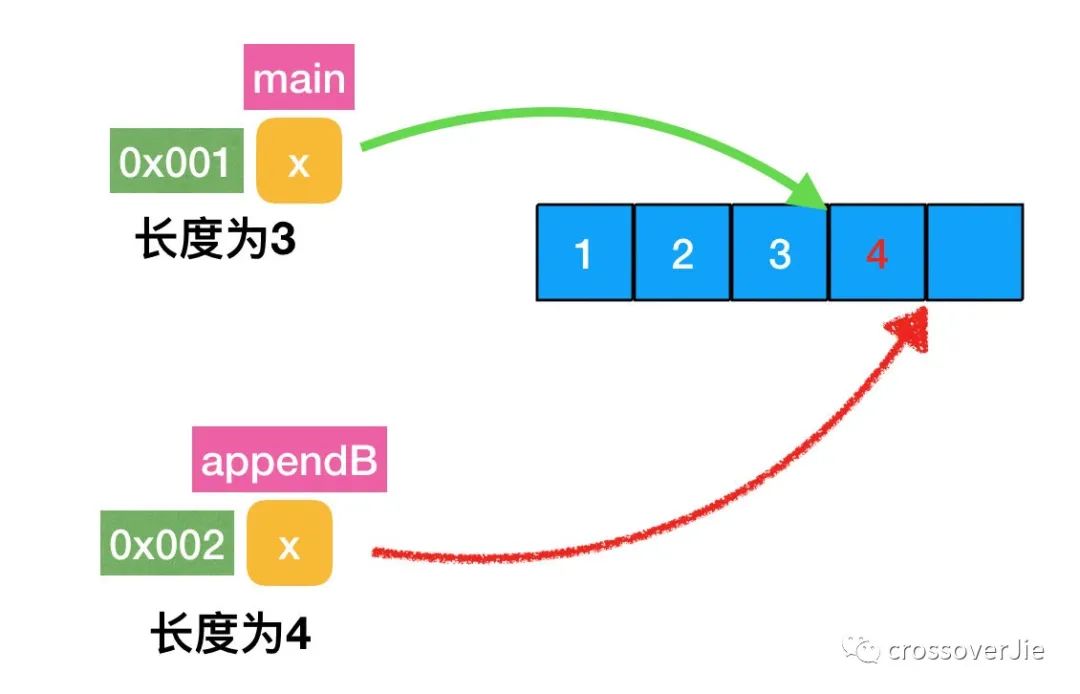
看图就很容易理解了:
- 在
appendB中确实是对原始数组追加了数据,同时长度也增加了。 - 但由于是值传递,所以
slice这个结构体即便是修改了长度为4,也只是对复制的那个对象修改了长度,main中的长度依然为3. - 由于底层数组是同一个,所以基于这个底层数组重新生成了一个完整长度的切片便能看到追加的数据了。
所以这里本质的原因是因为 slice 是一个结构体,传递的是值,不管方法里如何修改长度也不会影响到原有的数据(这里指的是长度和容量这两个属性)。
切片扩容
还有一个需要注意:
刚才特意提到这里的例子稍有改变,主要是将切片的容量设置超过了数组的长度;
如果不做这个特殊设置会怎么样呢?
func TestAppendB(t *testing.T) {
x:=[]int{1,2,3}
//x := make([]int, 3,5)
x[0] = 1
x[1] = 2
x[2] = 3
appendB(x)
fmt.Printf("main %v len=%v,cap=%v\n", x,len(x),cap(x))
y:=x[0:cap(x)]
fmt.Printf("y %v len=%v,cap=%v\n", y,len(y),cap(y))
}
func appendB(x []int) {
x = append(x, 444)
fmt.Printf("appendB %v len=%v,cap=%v\n", x,len(x),cap(x))
}
输出结果:
appendB [1 2 3 444] len=4,cap=6
main [1 2 3] len=3,cap=3
y [1 2 3] len=3,cap=3
这时会发现 main 函数中的 y 切片数据也没有发生变化,这是为什么呢?
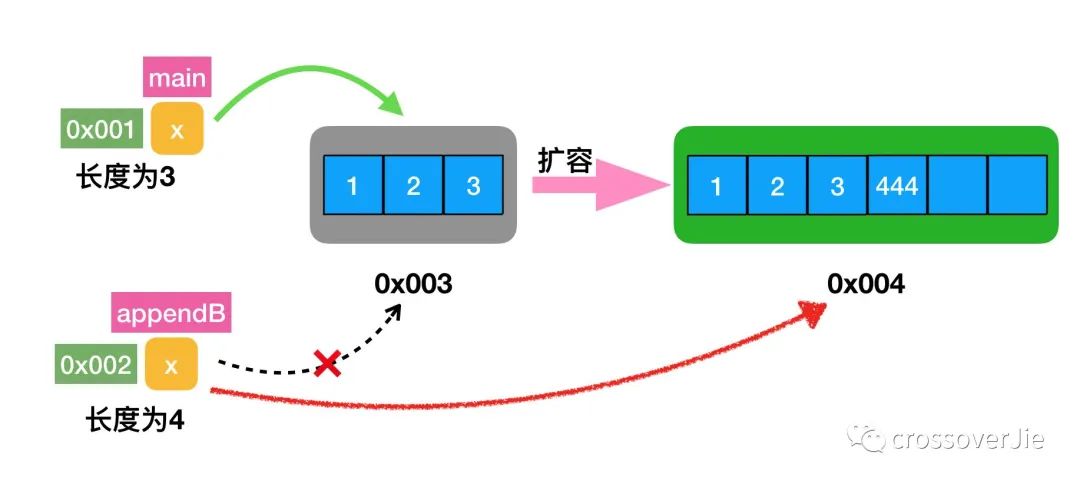
这是因为初始化 x 切片时长度和容量都为3,当在 appendB 函数中追加数据时,会发现没有位置了。
这时便会进行扩容:
- 将老数据复制一份到新的数组中。
- 追加数据。
- 将新的数据内存地址返回给
appendB中的 x .
同样的由于是值传递,所以 appendB 中的切片换了底层数组对 main 函数中的切片没有任何影响,也就导致最终 main 函数的数据没有任何变化了。
传递切片指针
有没有什么办法即便是在扩容时也能对外部产生影响呢?
func TestAppendC(t *testing.T) {
x:=[]int{1,2,3}
appendC(&x)
fmt.Printf("main %v len=%v,cap=%v\n", x,len(x),cap(x))
}
func appendC(x *[]int) {
*x = append(*x, 4)
fmt.Printf("appendC %v\n", x)
}
输出结果为:
appendC &[1 2 3 4]
main [1 2 3 4] len=4,cap=6
这时外部的切片就能受到影响了,其实原因也很简单;
刚才也说了,因为 slice 本身是一个结构体,所以当我们传递指针时,就和平时自定义的 struct 在函数内部通过指针修改数据原理相同。
最终在 appendC 中的 x 的指针指向了扩容后的结构体,因为传递的是 main 函数中 x 的指针,所以同样的 main 函数中的 x 也指向了该结构体。
所以总结一下:
- 切片是对数组的抽象,同时切片本身也是一个结构体。
- 参数传递时函数内部与外部引用的是同一个数组,所以对切片的修改会影响到函数外部。
- 如果发生扩容,情况会发生变化,同时扩容会导致数据拷贝;所以要尽量预估切片大小,避免数据拷贝。
- 对切片或数组重新生成切片时,由于共享的是同一个底层数组,所以数据会互相影响,这点需要注意。
- 切片也可以传递指针,但场景很少,还会带来不必要的误解;建议值传值就好,长度和容量占用不了多少内存。
相信使用过切片会发现非常类似于 Java 中的 ArrayList,同样是基于数组实现,也会扩容发生数据拷贝;这样看来语言只是上层使用的选择,一些通用的底层实现大家都差不多。
这时我们再看标题中的 []*T *[]T *[]*T 就会发现这几个并没有什么联系,只是看起来很像容易唬人。
更多推荐内容
↓
《Go 中的 channel 与 Java BlockingQueue 的本质区别》
《为自己搭建一个分布式 IM(即时通讯) 系统》