
国内大模型首批牌照发放!彻底爆了
| 首批大模型牌照今日发放
8月31日讯,8家企业通过《生成式人工智能服务管理暂行办法》备案,百度、字节跳动、商汤、中科院旗下紫东太初、百川智能、智谱华章等8个企业/机构的大模型位列第一批名单,可正式上线面向公众提供服务,国内大模型将迎来新一波热潮。
作为AI爱好者,除了体验各类五花八门的大模型在线服务外,并不能够真正接触到模型本身,在新一波的AI浪潮当中怎么样才能深度参与,了解大模型的底层原理,动手搭建和训练自己的大模型。
开源社区为我们提供了一个绝佳的选项,目前全球最强大的开源模型就是Llama2。
| 初识Llama2:全球最强开源大模型
Llama2是当前全球范围内最强的开源大模型,在推理、编程、对话和知识测试等许多基准测试中效果显著优于MPT、Falcon以及第一代LLaMA等开源大语言模型,也第一次媲美商用GPT-3.5,在一众开源模型中独树一帜。
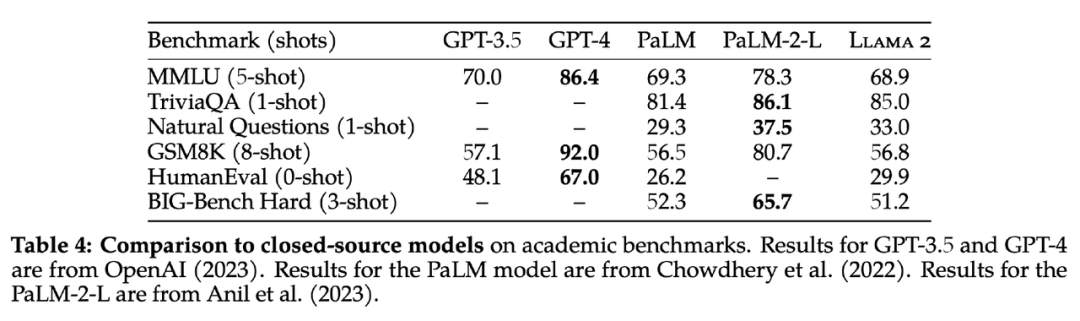
但是Llama2中文预训练数据的比例非常少,仅占0.13%,这也导致了原版Llama2的中文能力较弱。
| 如何突破Llama2中文能力极限?
从中文预训练开始,持续迭代升级
🎯大规模的中文数据预训练
为了增强Llama2的中文能力,可以采用大规模的中文数据进行持续预训练,例如:百科、书籍、博客、新闻、公告、小说、代码、专业论文等。
📚更高效的中文词表
其次需要对Llama2模型的词表进行深度优化,在保留原始的数学和英文字符的基础上,基于大规模的中文文本扩充中文词表,增加emoji符号😊,这样可以提升中文编解码速度。
⭐自适应上下文扩展
Llama2模型默认支持4K上下文,可以利用位置插值PI和Neural Tangent Kernel (NTK)方法,经过微调将上下文长度扩增到32K。
基于以上核心技术,Llama中文社区一直致力于Llama2中文能力的突破。
| 与技术爱好者共同前行
Llama中文社区Github突破 4.6K star
Llama中文社区在GitHub的技术分享涵盖数据获取、模型部署、微调、推理和评估等方面。无论您是专业人士还是技术爱好者,都可以获得开源代码和全方位支持。
这个开源共享的理念驱使着我们不断迈进,将创新的火花传递给每一个有志于技术发展的人。
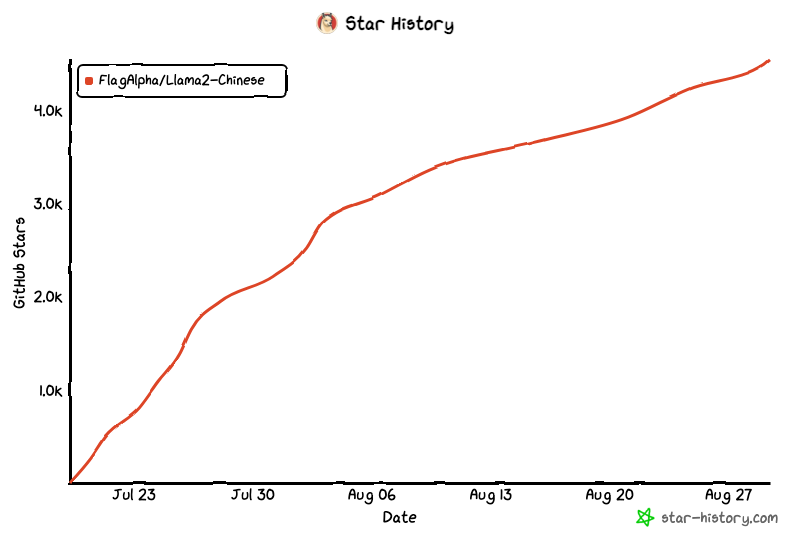
社区在线体验超过1万名用户
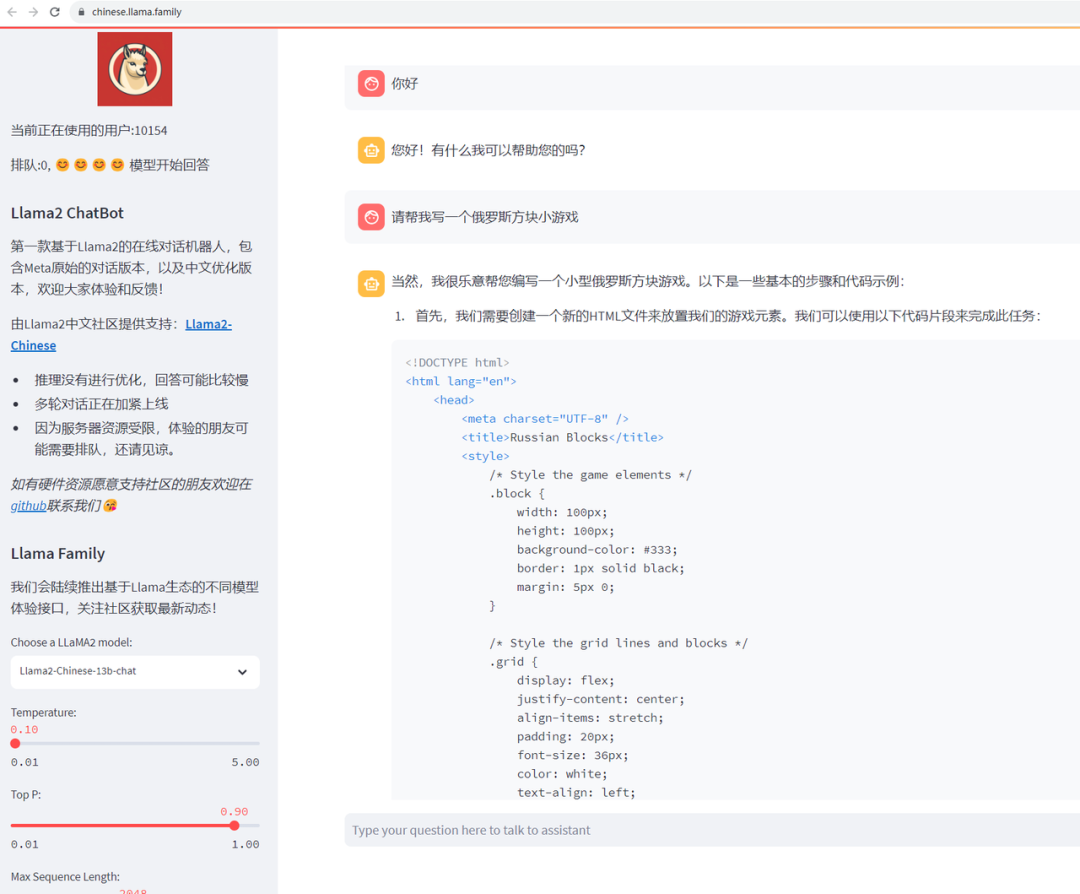
要部署大型模型,强大的算力是不可或缺的,而社区正是为此打造了一个开放的大模型体验平台。平台不仅包括原生的Meta Llama2,还有社区经过微调的中文Llama2,同时涵盖了最新的CodeLlama模型。
社区的目标是让每个人都能轻松感受到最前沿的Llama模型,无论是从事技术研究,还是纯粹的好奇探索,都能在这个平台上体验。
体验链接:https://chinese.llama.family
在社区大牛们的共同努力下,我们在短期内取得了非凡成绩。
| 中文能力跻身全球前十
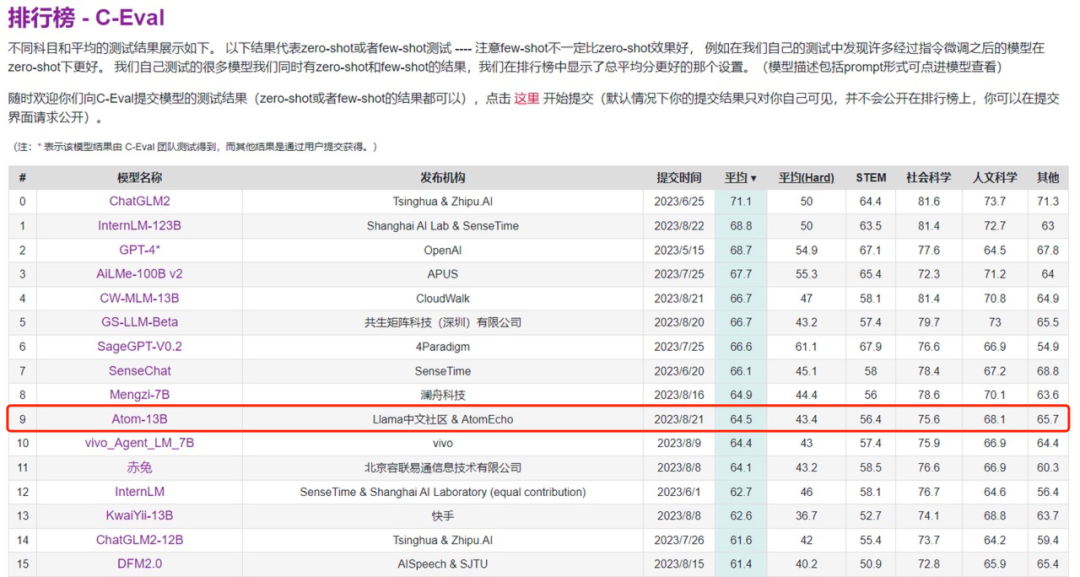
基于Llama2大模型,Llama中文社区与原子回声携手合作,共同铸就了原子大模型Atom-13B。
在权威的大模型评测榜单C-Eval的考验中,Atom-13B以出色的表现脱颖而出,荣登前十名(截至8月21日评测提交时间),成为中文大模型的佼佼者,距离GPT-4中文能力评分仅有微小差距,相差4分。
| 作为一个AI技术爱好者
想学习全球前十的大模型如何训练?
想学习大模型基础理论?
想结合自身需求训练行业大模型?
想同社区技术大佬一起成长?
社区领航计划为有志成为大模型大牛的同学,提供了丰富的课程,从大模型理论体系到实战操作,无论是大模型小白还是研究专家,都能从中获得最大的收获。
领航计划第一期已圆满结束,收获了社区同学的热烈好评:

部分优秀同学证书展示:

更多详情见:https://llama.family/course
应社区同学的热烈要求,我们现开启领航计划第二期报名:
领航计划第二期开启报名
每位同学不仅能学习课程,还能享受如下 ”7TOP“ 领航权益:


扫描下方二维码立即报名
在Llama中文社区,我们携手共进,引领人工智能的未来,在领航计划与顶级大牛一同开启你的大模型之旅!👇
加入Llama中文社区
让我们共同促进中文大模型的发展
一起迈向AGI!
以上内容包含广告