
Loki 源码分析之日志写入
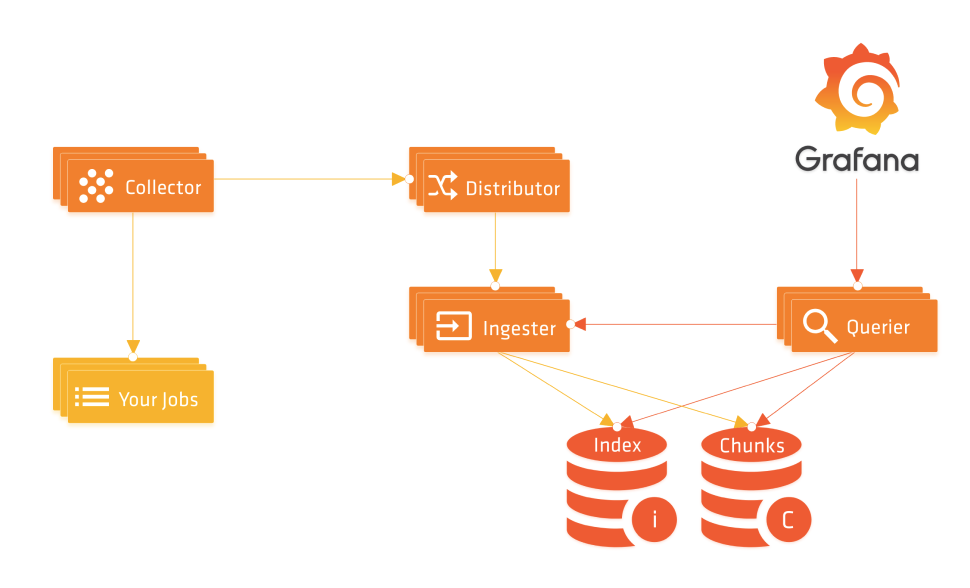 前面我们介绍了 Loki 的一些基本使用配置,但是对 Loki 还是了解不够深入,官方文档写得较为凌乱,而且没有跟上新版本,为了能够对 Loki 有一个更深入的认识,做到有的放矢,这里面我们尝试对 Loki 的源码进行一些简单的分析,由于有很多模块和实现细节,这里我们主要是对核心功能进行分析,希望对大家有所帮助。本文首先对日志的写入过程进行简单分析。
前面我们介绍了 Loki 的一些基本使用配置,但是对 Loki 还是了解不够深入,官方文档写得较为凌乱,而且没有跟上新版本,为了能够对 Loki 有一个更深入的认识,做到有的放矢,这里面我们尝试对 Loki 的源码进行一些简单的分析,由于有很多模块和实现细节,这里我们主要是对核心功能进行分析,希望对大家有所帮助。本文首先对日志的写入过程进行简单分析。
Distributor Push API
Promtail 通过 Loki 的 Push API 接口推送日志数据,该接口在初始化 Distributor 的时候进行初始化,在控制器基础上包装了两个中间件,其中的 HTTPAuthMiddleware 就是获取租户 ID,如果开启了认证配置,则从 X-Scope-OrgID 这个请求 Header 头里面获取,如果没有配置则用默认的 fake 代替。
// pkg/loki/modules.go
func (t *Loki) initDistributor() (services.Service, error) {
......
if t.cfg.Target != All {
logproto.RegisterPusherServer(t.Server.GRPC, t.distributor)
}
pushHandler := middleware.Merge(
serverutil.RecoveryHTTPMiddleware,
t.HTTPAuthMiddleware,
).Wrap(http.HandlerFunc(t.distributor.PushHandler))
t.Server.HTTP.Handle("/api/prom/push", pushHandler)
t.Server.HTTP.Handle("/loki/api/v1/push", pushHandler)
return t.distributor, nil
}
Push API 处理器实现如下所示,首先通过 ParseRequest 函数将 Http 请求转换成 logproto.PushRequest,然后直接调用 Distributor 下面的 Push 函数来推送日志数据:
// pkg/distributor/http.go
// PushHandler 从 HTTP body 中读取一个 snappy 压缩的 proto
func (d *Distributor) PushHandler(w http.ResponseWriter, r *http.Request) {
logger := util_log.WithContext(r.Context(), util_log.Logger)
userID, _ := user.ExtractOrgID(r.Context())
req, err := ParseRequest(logger, userID, r)
......
_, err = d.Push(r.Context(), req)
......
}
func ParseRequest(logger gokit.Logger, userID string, r *http.Request) (*logproto.PushRequest, error) {
var body lokiutil.SizeReader
contentEncoding := r.Header.Get(contentEnc)
switch contentEncoding {
case "":
body = lokiutil.NewSizeReader(r.Body)
case "snappy":
body = lokiutil.NewSizeReader(r.Body)
case "gzip":
gzipReader, err := gzip.NewReader(r.Body)
if err != nil {
return nil, err
}
defer gzipReader.Close()
body = lokiutil.NewSizeReader(gzipReader)
default:
return nil, fmt.Errorf("Content-Encoding %q not supported", contentEncoding)
}
contentType := r.Header.Get(contentType)
var req logproto.PushRequest
......
switch contentType {
case applicationJSON:
var err error
if loghttp.GetVersion(r.RequestURI) == loghttp.VersionV1 {
err = unmarshal.DecodePushRequest(body, &req)
} else {
err = unmarshal_legacy.DecodePushRequest(body, &req)
}
if err != nil {
return nil, err
}
default:
// When no content-type header is set or when it is set to
// `application/x-protobuf`: expect snappy compression.
if err := util.ParseProtoReader(r.Context(), body, int(r.ContentLength), math.MaxInt32, &req, util.RawSnappy); err != nil {
return nil, err
}
}
return &req, nil
}
首先我们先了解下 PushRequest 的结构,PushRequest 就是一个 Stream 集合:
// pkg/logproto/logproto.pb.go
type PushRequest struct {
Streams []Stream `protobuf:"bytes,1,rep,name=streams,proto3,customtype=Stream" json:"streams"`
}
// pkg/logproto/types.go
// Stream 流包含一个唯一的标签集,作为一个字符串,然后还包含一组日志条目
type Stream struct {
Labels string `protobuf:"bytes,1,opt,name=labels,proto3" json:"labels"`
Entries []Entry `protobuf:"bytes,2,rep,name=entries,proto3,customtype=EntryAdapter" json:"entries"`
}
// Entry 是一个带有时间戳的日志条目
type Entry struct {
Timestamp time.Time `protobuf:"bytes,1,opt,name=timestamp,proto3,stdtime" json:"ts"`
Line string `protobuf:"bytes,2,opt,name=line,proto3" json:"line"`
}


然后查看 Distributor 下的 Push 函数实现:
// pkg/distributor/distributor.go
// Push 日志流集合
func (d *Distributor) Push(ctx context.Context, req *logproto.PushRequest) (*logproto.PushResponse, error) {
// 获取租户ID
userID, err := user.ExtractOrgID(ctx)
......
// 首先把请求平铺成一个样本的列表
streams := make([]streamTracker, 0, len(req.Streams))
keys := make([]uint32, 0, len(req.Streams))
var validationErr error
validatedSamplesSize := 0
validatedSamplesCount := 0
validationContext := d.validator.getValidationContextFor(userID)
for _, stream := range req.Streams {
// 解析日志流标签
stream.Labels, err = d.parseStreamLabels(validationContext, stream.Labels, &stream)
......
n := 0
for _, entry := range stream.Entries {
// 校验一个日志Entry实体
if err := d.validator.ValidateEntry(validationContext, stream.Labels, entry); err != nil {
validationErr = err
continue
}
stream.Entries[n] = entry
n++
// 校验成功的样本大小和个数
validatedSamplesSize += len(entry.Line)
validatedSamplesCount++
}
// 去掉校验失败的实体
stream.Entries = stream.Entries[:n]
if len(stream.Entries) == 0 {
continue
}
// 为当前日志流生成用于hash换的token值
keys = append(keys, util.TokenFor(userID, stream.Labels))
streams = append(streams, streamTracker{
stream: stream,
})
}
if len(streams) == 0 {
return &logproto.PushResponse{}, validationErr
}
now := time.Now()
// 每个租户有一个限速器,判断可以正常传输的日志大小是否应该被限制
if !d.ingestionRateLimiter.AllowN(now, userID, validatedSamplesSize) {
// 返回429表明客户端被限速了
......
return nil, httpgrpc.Errorf(http.StatusTooManyRequests, validation.RateLimitedErrorMsg, int(d.ingestionRateLimiter.Limit(now, userID)), validatedSamplesCount, validatedSamplesSize)
}
const maxExpectedReplicationSet = 5 // typical replication factor 3 plus one for inactive plus one for luck
var descs [maxExpectedReplicationSet]ring.InstanceDesc
samplesByIngester := map[string][]*streamTracker{}
ingesterDescs := map[string]ring.InstanceDesc{}
for i, key := range keys {
// ReplicationSet 描述了一个指定的键与哪些 Ingesters 进行对话,以及可以容忍多少个错误
// 根据 label hash 到 hash 环上获取对应的 ingester 节点,一个节点可能有多个对等的 ingester 副本来做 HA
replicationSet, err := d.ingestersRing.Get(key, ring.Write, descs[:0], nil, nil)
......
// 最小成功的实例树
streams[i].minSuccess = len(replicationSet.Ingesters) - replicationSet.MaxErrors
// 可容忍的最大故障实例数
streams[i].maxFailures = replicationSet.MaxErrors
// 将 Stream 按对应的 ingester 进行分组
for _, ingester := range replicationSet.Ingesters {
// 配置每个 ingester 副本对应的日志流数据
samplesByIngester[ingester.Addr] = append(samplesByIngester[ingester.Addr], &streams[i])
ingesterDescs[ingester.Addr] = ingester
}
}
tracker := pushTracker{
done: make(chan struct{}),
err: make(chan error),
}
tracker.samplesPending.Store(int32(len(streams)))
// 循环Ingesters
for ingester, samples := range samplesByIngester {
// 让ingester并行处理通过hash环对应的日志流列表
go func(ingester ring.InstanceDesc, samples []*streamTracker) {
......
// 将日志流样本数据下发给对应的 ingester 节点
d.sendSamples(localCtx, ingester, samples, &tracker)
}(ingesterDescs[ingester], samples)
}
......
}
Push 函数的核心就是根据日志流的标签来计算一个 Token 值,根据这个 Token 值去哈希环上获取对应的处理日志的 Ingester 实例,然后并行通过 Ingester 处理日志流数据,通过 sendSamples 函数为单个 ingester 去发送日志样本数据:
// pkg/distributor/distributor.go
func (d *Distributor) sendSamples(ctx context.Context, ingester ring.InstanceDesc, streamTrackers []*streamTracker, pushTracker *pushTracker) {
err := d.sendSamplesErr(ctx, ingester, streamTrackers)
......
}
func (d *Distributor) sendSamplesErr(ctx context.Context, ingester ring.InstanceDesc, streams []*streamTracker) error {
// 根据 ingester 地址获取 client
c, err := d.pool.GetClientFor(ingester.Addr)
......
// 重新构造 PushRequest
req := &logproto.PushRequest{
Streams: make([]logproto.Stream, len(streams)),
}
for i, s := range streams {
req.Streams[i] = s.stream
}
// 通过 Ingester 客户端请求数据
_, err = c.(logproto.PusherClient).Push(ctx, req)
......
}
Ingester 写入日志
Ingester 客户端中的 Push 函数实际上就是一个 gRPC 服务的客户端:
// pkg/ingester/ingester.go
// Push 实现 logproto.Pusher.
func (i *Ingester) Push(ctx context.Context, req *logproto.PushRequest) (*logproto.PushResponse, error) {
// 获取租户ID
instanceID, err := user.ExtractOrgID(ctx)
......
// 根据租户ID获取 instance 对象
instance := i.getOrCreateInstance(instanceID)
// 直接调用 instance 对象 Push 数据
err = instance.Push(ctx, req)
return &logproto.PushResponse{}, err
}
instance 下的 Push 函数:
// pkg/ingester/instance.go
func (i *instance) Push(ctx context.Context, req *logproto.PushRequest) error {
record := recordPool.GetRecord()
record.UserID = i.instanceID
defer recordPool.PutRecord(record)
i.streamsMtx.Lock()
defer i.streamsMtx.Unlock()
var appendErr error
for _, s := range req.Streams {
// 获取一个 stream 对象
stream, err := i.getOrCreateStream(s, false, record)
if err != nil {
appendErr = err
continue
}
// 真正用于数据处理的是 stream 对象中的 Push 函数
if _, err := stream.Push(ctx, s.Entries, record); err != nil {
appendErr = err
continue
}
}
......
return appendErr
}
func (i *instance) getOrCreateStream(pushReqStream logproto.Stream, lock bool, record *WALRecord) (*stream, error) {
if lock {
i.streamsMtx.Lock()
defer i.streamsMtx.Unlock()
}
// 如果 streams 中包含当前标签列表对应的 stream 对象,则直接返回
stream, ok := i.streams[pushReqStream.Labels]
if ok {
return stream, nil
}
// record 只在重放 WAL 时为 nil
// 我们不希望在重放 WAL 后丢掉数据
// 为 instance 降低 stream 流限制
var err error
if record != nil {
// 限流器判断
// AssertMaxStreamsPerUser 确保与当前输入的流数量没有达到限制
err = i.limiter.AssertMaxStreamsPerUser(i.instanceID, len(i.streams))
}
......
// 解析日志流标签集
labels, err := logql.ParseLabels(pushReqStream.Labels)
......
// 获取对应标签集的指纹
fp := i.getHashForLabels(labels)
// 重新实例化一个 stream 对象,这里还会维护日志流的倒排索引
sortedLabels := i.index.Add(client.FromLabelsToLabelAdapters(labels), fp)
stream = newStream(i.cfg, fp, sortedLabels, i.metrics)
// 将stream设置到streams中去
i.streams[pushReqStream.Labels] = stream
i.streamsByFP[fp] = stream
// 当重放 wal 的时候 record 是 nil (我们不希望在重放时重写 wal entries).
if record != nil {
record.Series = append(record.Series, tsdb_record.RefSeries{
Ref: uint64(fp),
Labels: sortedLabels,
})
} else {
// 如果 record 为 nil,这就是一个 WAL 恢复
i.metrics.recoveredStreamsTotal.Inc()
}
......
i.addTailersToNewStream(stream)
return stream, nil
}
这个里面涉及到 WAL 这一块的设计,比较复杂,我们可以先看 stream 下面的 Push 函数实现,主要就是将收到的 []Entry 先 Append 到内存中的 Chunk 流([]chunkDesc) 中:
// pkg/ingester/stream.go
func (s *stream) Push(ctx context.Context, entries []logproto.Entry, record *WALRecord) (int, error) {
s.chunkMtx.Lock()
defer s.chunkMtx.Unlock()
var bytesAdded int
prevNumChunks := len(s.chunks)
var lastChunkTimestamp time.Time
// 如果之前的 chunks 列表为空,则创建一个新的 chunk
if prevNumChunks == 0 {
s.chunks = append(s.chunks, chunkDesc{
chunk: s.NewChunk(),
})
chunksCreatedTotal.Inc()
} else {
// 获取最新一个chunk的日志时间戳
_, lastChunkTimestamp = s.chunks[len(s.chunks)-1].chunk.Bounds()
}
var storedEntries []logproto.Entry
failedEntriesWithError := []entryWithError{}
for i := range entries {
// 如果这个日志条目与我们最后 append 的一行的时间戳和内容相匹配,则忽略它
if entries[i].Timestamp.Equal(s.lastLine.ts) && entries[i].Line == s.lastLine.content {
continue
}
// 最新的一个 chunk
chunk := &s.chunks[len(s.chunks)-1]
// 如果当前chunk已经关闭 或者 已经达到设置的最大 Chunk 大小
if chunk.closed || !chunk.chunk.SpaceFor(&entries[i]) || s.cutChunkForSynchronization(entries[i].Timestamp, lastChunkTimestamp, chunk, s.cfg.SyncPeriod, s.cfg.SyncMinUtilization) {
// 如果 chunk 没有更多的空间,则调用 Close 来以确保 head block 中的数据都被切割和压缩。
err := chunk.chunk.Close()
......
chunk.closed = true
......
// Append 一个新的 Chunk
s.chunks = append(s.chunks, chunkDesc{
chunk: s.NewChunk(),
})
chunk = &s.chunks[len(s.chunks)-1]
lastChunkTimestamp = time.Time{}
}
// 往 chunk 里面 Append 日志数据
if err := chunk.chunk.Append(&entries[i]); err != nil {
failedEntriesWithError = append(failedEntriesWithError, entryWithError{&entries[i], err})
} else {
// 存储添加到 chunk 中的日志数据
storedEntries = append(storedEntries, entries[i])
// 配置最后日志行的数据
lastChunkTimestamp = entries[i].Timestamp
s.lastLine.ts = lastChunkTimestamp
s.lastLine.content = entries[i].Line
// 累计大小
bytesAdded += len(entries[i].Line)
}
chunk.lastUpdated = time.Now()
}
if len(storedEntries) != 0 {
// 当重放 wal 的时候 record 将为 nil(我们不希望在重放的时候重写wal日志条目)
if record != nil {
record.AddEntries(uint64(s.fp), storedEntries...)
}
// 后续是用与tail日志的处理
......
}
......
// 如果新增了chunks
if len(s.chunks) != prevNumChunks {
memoryChunks.Add(float64(len(s.chunks) - prevNumChunks))
}
return bytesAdded, nil
}
Chunk 其实就是多条日志构成的压缩包,将日志压成 Chunk 的可以直接存入对象存储, 一个 Chunk 到达指定大小之前会不断 Append 新的日志到里面,而在达到大小之后, Chunk 就会关闭等待持久化(强制持久化也会关闭 Chunk, 比如关闭 ingester 实例时就会关闭所有的 Chunk 并持久化)。Chunk 的大小控制很重要:
假如 Chunk 容量过小: 首先是导致压缩效率不高,同时也会增加整体的 Chunk 数量, 导致倒排索引过大,最后, 对象存储的操作次数也会变多, 带来额外的性能开销 假如 Chunk 过大: 一个 Chunk 的 open 时间会更长, 占用额外的内存空间, 同时, 也增加了丢数据的风险,Chunk 过大也会导致查询读放大
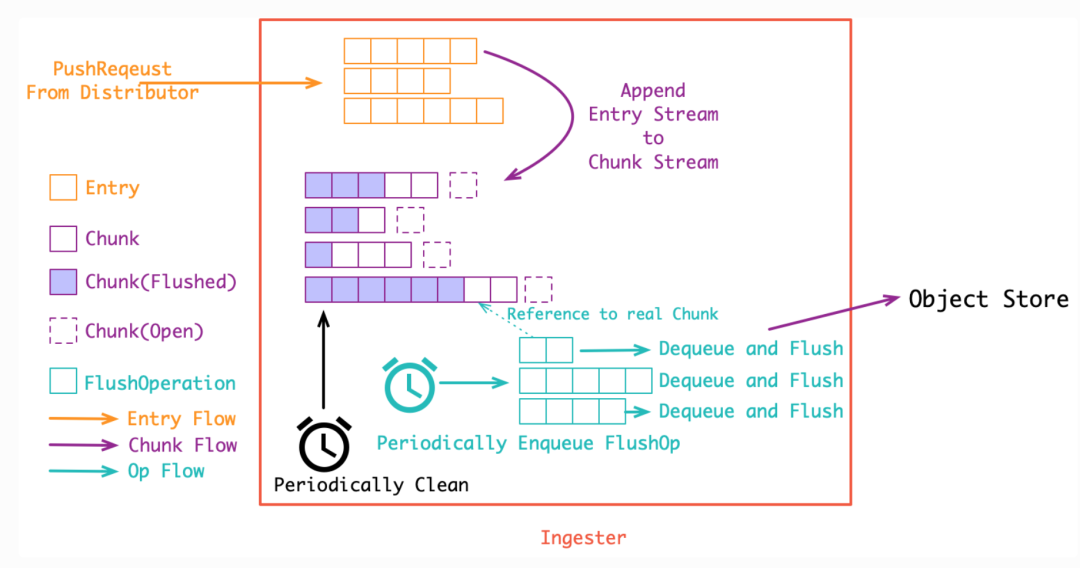
(图片来源: https://aleiwu.com/post/grafana-loki/)
在将日志流追加到 Chunk 中过后,在 Ingester 初始化时会启动两个循环去处理 Chunk 数据,分别从 chunks 数据取出存入优先级队列,另外一个循环定期检查从内存中删除已经持久化过后的数据。
首先是 Ingester 中定义了一个 flushQueues 属性,是一个优先级队列数组,该队列中存放的是 flushOp:
// pkg/ingester/ingester.go
type Ingester struct {
services.Service
......
// 每个 flush 线程一个队列,指纹用来选择队列
flushQueues []*util.PriorityQueue // 优先级队列数组
flushQueuesDone sync.WaitGroup
......
}
// pkg/ingester/flush.go
// 优先级队列中存放的数据
type flushOp struct {
from model.Time
userID string
fp model.Fingerprint
immediate bool
}
在初始化 Ingester 的时候会根据传递的 ConcurrentFlushes 参数来实例化 flushQueues 的大小:
// pkg/ingester/ingester.go
func New(cfg Config, clientConfig client.Config, store ChunkStore, limits *validation.Overrides, configs *runtime.TenantConfigs, registerer prometheus.Registerer) (*Ingester, error) {
......
i := &Ingester{
......
flushQueues: make([]*util.PriorityQueue, cfg.ConcurrentFlushes),
......
}
......
i.Service = services.NewBasicService(i.starting, i.running, i.stopping)
return i, nil
}
然后通过 services.NewBasicService 实例化 Service 的时候指定了服务的 Starting、Running、Stopping 3 个状态,在其中的 staring 状态函数中会启动协程去消费优先级队列中的数据
// pkg/ingester/ingester.go
func (i *Ingester) starting(ctx context.Context) error {
// todo,如果开启了 WAL 的处理
......
// 初始化 flushQueues
i.InitFlushQueues()
......
// 启动循环检查chunk数据
i.loopDone.Add(1)
go i.loop()
return nil
}
初始化 flushQueues 实现如下所示,其中 flushQueuesDone 是一个 WaitGroup,根据配置的并发数量并发执行 flushLoop 操作:
// pkg/ingester/flush.go
func (i *Ingester) InitFlushQueues() {
i.flushQueuesDone.Add(i.cfg.ConcurrentFlushes)
for j := 0; j < i.cfg.ConcurrentFlushes; j++ {
// 为每个协程构造一个优先级队列
i.flushQueues[j] = util.NewPriorityQueue(flushQueueLength)
go i.flushLoop(j)
}
}
每一个优先级队列循环消费数据:
// pkg/ingester/flush.go
func (i *Ingester) flushLoop(j int) {
......
for {
// 从队列中根据优先级取出数据
o := i.flushQueues[j].Dequeue()
if o == nil {
return
}
op := o.(*flushOp)
// 执行真正的刷新用户序列数据
err := i.flushUserSeries(op.userID, op.fp, op.immediate)
......
// 如果退出时刷新失败了,把失败的操作放回到队列中去。
if op.immediate && err != nil {
op.from = op.from.Add(flushBackoff)
i.flushQueues[j].Enqueue(op)
}
}
}
刷新用户的序列操作,也就是要保存到存储中去:
// pkg/ingester/flush.go
// 根据用户ID刷新用户日志序列
func (i *Ingester) flushUserSeries(userID string, fp model.Fingerprint, immediate bool) error {
instance, ok := i.getInstanceByID(userID)
......
// 根据instance和fp指纹数据获取需要刷新的chunks
chunks, labels, chunkMtx := i.collectChunksToFlush(instance, fp, immediate)
......
// 执行真正的刷新 chunks 操作
err := i.flushChunks(ctx, fp, labels, chunks, chunkMtx)
......
}
// 收集需要刷新的 chunks
func (i *Ingester) collectChunksToFlush(instance *instance, fp model.Fingerprint, immediate bool) ([]*chunkDesc, labels.Labels, *sync.RWMutex) {
instance.streamsMtx.Lock()
// 根据指纹数据获取 stream
stream, ok := instance.streamsByFP[fp]
instance.streamsMtx.Unlock()
if !ok {
return nil, nil, nil
}
var result []*chunkDesc
stream.chunkMtx.Lock()
defer stream.chunkMtx.Unlock()
// 循环所有chunks
for j := range stream.chunks {
// 判断是否应该刷新当前chunk
shouldFlush, reason := i.shouldFlushChunk(&stream.chunks[j])
if immediate || shouldFlush {
// 确保不再对该块进行写操作(如果没有关闭,则设置为关闭状态)
if !stream.chunks[j].closed {
stream.chunks[j].closed = true
}
// 如果该 chunk 还没有被成功刷新,则刷新这个块
if stream.chunks[j].flushed.IsZero() {
result = append(result, &stream.chunks[j])
......
}
}
}
return result, stream.labels, &stream.chunkMtx
}
下面是判断一个具体的 chunk 是否应该被刷新的逻辑:
// pkg/ingester/flush.go
func (i *Ingester) shouldFlushChunk(chunk *chunkDesc) (bool, string) {
// chunk关闭了也应该刷新了
if chunk.closed {
if chunk.synced {
return true, flushReasonSynced
}
return true, flushReasonFull
}
// chunk最后更新的时间超过了配置的 chunk 空闲时间 MaxChunkIdle
if time.Since(chunk.lastUpdated) > i.cfg.MaxChunkIdle {
return true, flushReasonIdle
}
// chunk的边界时间操过了配置的 chunk 最大时间 MaxChunkAge
if from, to := chunk.chunk.Bounds(); to.Sub(from) > i.cfg.MaxChunkAge {
return true, flushReasonMaxAge
}
return false, ""
}
真正将 chunks 数据刷新保存到存储中是 flushChunks 函数实现的:
// pkg/ingester/flush.go
func (i *Ingester) flushChunks(ctx context.Context, fp model.Fingerprint, labelPairs labels.Labels, cs []*chunkDesc, chunkMtx sync.Locker) error {
......
wireChunks := make([]chunk.Chunk, len(cs))
// 下面的匿名函数用于生成保存到存储中的chunk数据
err = func() error {
chunkMtx.Lock()
defer chunkMtx.Unlock()
for j, c := range cs {
if err := c.chunk.Close(); err != nil {
return err
}
firstTime, lastTime := loki_util.RoundToMilliseconds(c.chunk.Bounds())
ch := chunk.NewChunk(
userID, fp, metric,
chunkenc.NewFacade(c.chunk, i.cfg.BlockSize, i.cfg.TargetChunkSize),
firstTime,
lastTime,
)
chunkSize := c.chunk.BytesSize() + 4*1024 // size + 4kB should be enough room for cortex header
start := time.Now()
if err := ch.EncodeTo(bytes.NewBuffer(make([]byte, 0, chunkSize))); err != nil {
return err
}
wireChunks[j] = ch
}
return nil
}()
// 通过 store 接口保存 chunk 数据
if err := i.store.Put(ctx, wireChunks); err != nil {
return err
}
......
chunkMtx.Lock()
defer chunkMtx.Unlock()
for i, wc := range wireChunks {
// flush 成功,写入刷新时间
cs[i].flushed = time.Now()
// 下是一些监控数据更新
......
}
return nil
}
chunk 数据被写入到存储后,还有有一个协程会去定时清理本地的这些 chunk 数据,在上面的 Ingester 的 staring 函数中最后有一个 go i.loop(),在这个 loop() 函数中会每隔 FlushCheckPeriod(默认 30s,可以通过 --ingester.flush-check-period 进行配置)时间就会去去调用 sweepUsers 函数进行垃圾回收:
// pkg/ingester/ingester.go
func (i *Ingester) loop() {
defer i.loopDone.Done()
flushTicker := time.NewTicker(i.cfg.FlushCheckPeriod)
defer flushTicker.Stop()
for {
select {
case <-flushTicker.C:
i.sweepUsers(false, true)
case <-i.loopQuit:
return
}
}
}
sweepUsers 函数用于执行将日志流数据加入到优先级队列中,并对没有序列的用户进行垃圾回收:
// pkg/ingester/flush.go
// sweepUsers 定期执行 flush 操作,并对没有序列的用户进行垃圾回收
func (i *Ingester) sweepUsers(immediate, mayRemoveStreams bool) {
instances := i.getInstances()
for _, instance := range instances {
i.sweepInstance(instance, immediate, mayRemoveStreams)
}
}
func (i *Ingester) sweepInstance(instance *instance, immediate, mayRemoveStreams bool) {
instance.streamsMtx.Lock()
defer instance.streamsMtx.Unlock()
for _, stream := range instance.streams {
i.sweepStream(instance, stream, immediate)
i.removeFlushedChunks(instance, stream, mayRemoveStreams)
}
}
// must hold streamsMtx
func (i *Ingester) sweepStream(instance *instance, stream *stream, immediate bool) {
stream.chunkMtx.RLock()
defer stream.chunkMtx.RUnlock()
if len(stream.chunks) == 0 {
return
}
// 最新的chunk
lastChunk := stream.chunks[len(stream.chunks)-1]
// 判断是否应该被flush
shouldFlush, _ := i.shouldFlushChunk(&lastChunk)
// 如果只有一个chunk并且不是强制持久化切最新的chunk还不应该被flush,则直接返回
if len(stream.chunks) == 1 && !immediate && !shouldFlush {
return
}
// 根据指纹获取用与处理的优先级队列索引
flushQueueIndex := int(uint64(stream.fp) % uint64(i.cfg.ConcurrentFlushes))
firstTime, _ := stream.chunks[0].chunk.Bounds()
// 加入到优先级队列中去
i.flushQueues[flushQueueIndex].Enqueue(&flushOp{
model.TimeFromUnixNano(firstTime.UnixNano()), instance.instanceID,
stream.fp, immediate,
})
}
// 移除已经flush过后的chunks数据
func (i *Ingester) removeFlushedChunks(instance *instance, stream *stream, mayRemoveStream bool) {
now := time.Now()
stream.chunkMtx.Lock()
defer stream.chunkMtx.Unlock()
prevNumChunks := len(stream.chunks)
var subtracted int
for len(stream.chunks) > 0 {
// 如果chunk还没有被刷新到存储 或者 chunk被刷新到存储到现在的时间还没操过 RetainPeriod(默认15分钟,可以通过--ingester.chunks-retain-period 进行配置)则忽略
if stream.chunks[0].flushed.IsZero() || now.Sub(stream.chunks[0].flushed) < i.cfg.RetainPeriod {
break
}
subtracted += stream.chunks[0].chunk.UncompressedSize()
// 删除引用,以便该块可以被垃圾回收起来
stream.chunks[0].chunk = nil
// 移除chunk
stream.chunks = stream.chunks[1:]
}
......
// 如果stream中的所有chunk都被清空了,则清空该 stream 的相关数据
if mayRemoveStream && len(stream.chunks) == 0 {
delete(instance.streamsByFP, stream.fp)
delete(instance.streams, stream.labelsString)
instance.index.Delete(stream.labels, stream.fp)
......
}
}
关于存储或者查询等模块的实现在后文再继续探索,包括 WAL 的实现也较为复杂。
K8S 进阶训练营

 点击屏末 | 阅读原文 | 即刻学习
点击屏末 | 阅读原文 | 即刻学习