【Python私活案例】200元:Python实现批量文件的检测和解压缩
来活了!来活了!在学习群中灌水时发现蚂蚁老师发布的任务需求中有个200大洋的大活没人接单,还等什么,赶紧盘它!!!
一、需求分析
接活后的第一步肯定都是进行需求分析,来看看金主的需求是什么样子的吧,
简单梳理一下关键点:
输入两个信息:一个文件夹路径、一个TXT文件。文件夹中是7z压缩包文件,TXT中是需要解压的文件名称; 找到TXT中的7z文件,解压并删除压缩包,同时需要使用多线程/多进程,提高解压效率; TXT文件中没有找到压缩包的文件名,需要输出一个TXT。 打包成exe可执行文件
二、思路整理
由于需要解压的文件非常多,非常大,需求方暂时还没办法提供测试用例,那么先按自己的理解把主要功能给实现一下先:
虽说需求中要求用递归处理子文件夹下的文件,但是,如果先用os模块的walk功能,先遍历一遍文件夹下所有的文件(包括子文件夹),似乎效果也是一样的,所以,先考虑用遍历,至于要不要递归,等有了具体测试用例了再说; 要输出没有找到压缩包的文件名,那就把需要解压的文件名与遍历后文件夹后获取的压缩包文件名进行匹配,分成两个list,找到压缩包的和没找到压缩包的; 对找到压缩包的文件的进行并发解压(这里必须赞一下蚂蚁老师,在需求里面直接把思路给出来了,后面就一码平川了^_^) 最后,将没找到压缩包的文件输出到TXT中。 最后的最后,再打包成exe可执行文件,搞定!!!
不过,思路是理好了,但是不会解压缩7z文件、不会打包exe,多线程用的少,只有半桶水肿么办?没关系!!!有蚂蚁老师做后盾,把老师的教学视频(Python并发编程,用多线程加速程序运行)拿出来复习复习,再加上万能的百度,没有搞不定的事情,加油奥利给!带薪学习我们的动力是杠杠滴~~~
三、代码实现
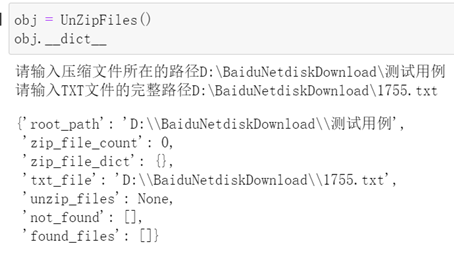
初始化类
class UnZipFiles:
def __init__(self):
self.root_path = input('请输入压缩文件所在的路径') # 根目录
self.zip_file_count = 0 # 初始化zip文件的个数
self.zip_file_dict = {} # 根目录中所有的7z文件字典,其中key为去除扩展名后的文件名,value为list格式,为7z文件的完整路径
self.txt_file = input('请输入TXT文件的完整路径') # 需要解压的TXT文件完整路径
self.unzip_files = None # 读取txt_file后解析的需要解压缩的文件list
self.not_found = [] # 没有找到的需要解压的文件list
self.found_files = [] # 有找到的需要解压的文件list
先初始化一个类,把后续需要用到的属性进行定义。分步执行情况:
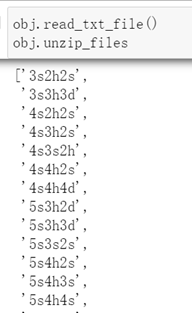
实现读取TXT文件创建需要解压文件名列表的方法
def read_txt_file(self, code='utf-8'):
"""
读取TXT文件,生成需要解压的文件list
:param code: 读取文件使用的编码格式
"""
with open(self.txt_file, 'r', encoding=code) as fin:
self.unzip_files = fin.read().split('\n')
分步执行情况:
实现读取根目录下所有文件并创建字典的方法
def get_all_zip_files(self):
"""
使用os.walk模块遍历根目录下的所有7z文件,生成zip_file_dict
"""
for path, dirnames, filenames in os.walk(self.root_path):
for filename in filenames:
if filename.endswith('.7z') and not filename.startswith('~'):
self.zip_file_count += 1
full_path = os.path.join(path, filename)
filename = filename.replace('.7z', '')
if filename in self.zip_file_dict.keys():
self.zip_file_dict[filename].append(full_path)
else:
self.zip_file_dict[filename] = [full_path]
这里使用os.walk方式,遍历根目录下所有文件,创建一个压缩文件的字典,key使用去除扩展名后的文件名以便于TXT里的文件名进行匹配。这里特别说一下,第一稿的时候,在往字典值的list里append值时,居然犯了低级错误,写成了“self.zip_file_dict[filename] = self.zip_file_dict[filename].append(full_path)”,要知道append是直接修改了list,并没有返回值,导致出现重名文件的时候出错;然后脑抽筋一直没有反应过来,调试了半天......(宝宝心里苦)
分步执行情况:
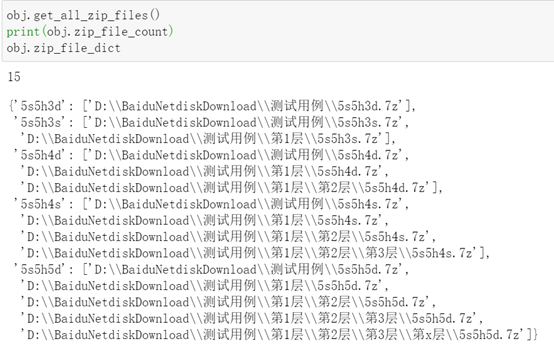
检查文件,分成找到的和没找到的两份
def check_files(self):
"""
检查文件,遍历unzip_files,与zip_file_dict的key匹配,有找到的放入found_files,没找到的放入not_found
"""
for file in set(self.unzip_files): # 为预防TXT文件中存在重复文件名,用set集合去重一下
if file in self.zip_file_dict.keys():
for x in self.zip_file_dict[file]:
self.found_files.append(x)
else:
self.not_found.append(file)
这里主要需要考虑存在不同文件夹中出现同名压缩包的情形。分步执行情况:
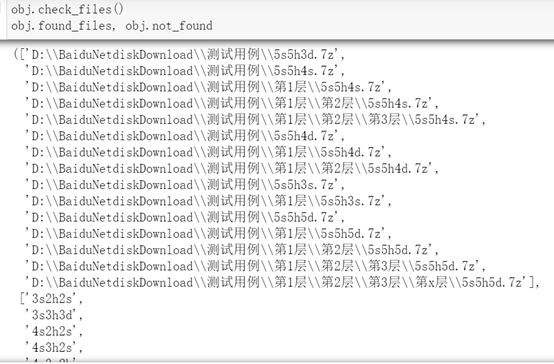
实现一个单独解压7z文件的方法
def upzip_file(self, file_full_path):
"""
对单个7z文件进行解压缩,解压缩后的文件,放置在原7z文件所在路径下,解压成功后,删除7z文件
:param file_full_path: 需要传入完整的文件路径
:return: True or False
"""
if is_7zfile(file_full_path):
try:
start_time = time.time()
with SevenZipFile(file_full_path, mode='r') as sevenZ_f:
sevenZ_f.extractall(os.path.split(file_full_path)[0]) # 解压到与压缩包相同的目录下
os.remove(file_full_path) # 解压成功后删除文件
end_time = time.time()
print(f'解压缩{file_full_path}文件成功,用时{round(end_time-start_time, 4)}秒')
except Exception as e:
print('Error when uncompress file! info: ', e)
return False
else:
return True
else:
print('This is not a true 7z file!')
return False
这一段是带薪学习的成果了,主要Ctrl C + Ctrl V(^_^感谢万能的百度)。不过其实理解起来也不难,使用了py7zr这个库来解压7z压缩包,先判断是否7z文件,再进行解压,成功返回True,否则False。
进行批量并发解压缩
def run_unzip(self, max_workers=10):
"""
开启多线程进行解压缩
:param max_workers: 开启的最大线程数,默认10个
"""
with ThreadPoolExecutor(max_workers=max_workers) as pool:
futures = [pool.submit(self.upzip_file, file) for file in self.found_files]
蚂蚁老师的教程(Python并发编程,用多线程加速程序运行)里学(抄)来的。
分步执行情况:

输出没有匹配到压缩包的文件名,格式为TXT文件
def write_not_found_file(self):
"""
当存在没有找到的解压文件时,写入文件,文件存放在与txt_file相同的目录下,命名为not_found_fifle.txt
"""
if len(self.not_found) > 0:
txt_path = self.txt_file.replace('.txt', '_not_found.txt') # 将原TXT文件的完整路径进行修改,增加“_not_found”部分作为输出TXT文件的文件名
with open(txt_path, 'w', encoding='utf-8') as fout:
fout.write('\n'.join(self.not_found))
按顺序执行各个方法
def run_program(self, code='utf-8', max_workers=10):
"""
按顺序运行程序
:param code: 读取txt_file的编码格式,默认utf-8
:param max_workers: 开启的线程数,默认10线程
"""
start = time.time()
self.read_txt_file(code) # 读取txt文件,生成unzip_files
self.get_all_zip_files() # 获取根目录下所有的7z文件字典
self.check_files() # 检查upzip_files是否都在字典中
self.run_unzip(max_workers) # 开启多线程进行解压缩
self.write_not_found_file() # 写入未找到的文件
end = time.time()
cost_time = end - start
print(f'txt文件中共有{len(self.unzip_files)}个文件名,其中{len(self.unzip_files)-len(self.not_found)}个在文件夹中找到{len(self.found_files)}个7z文件,{len(self.not_found)}个没有找到7z文件,注文件夹中共有{self.zip_file_count}个7z文件,不重复文件名共{len(self.zip_file_dict.keys())}个')
print(f'成功解压{len(self.found_files)}个7z文件,有{len(self.not_found)}个文件没有找到')
input(f'cost_time:{cost_time}秒,按回车键退出窗口')
执行情况:
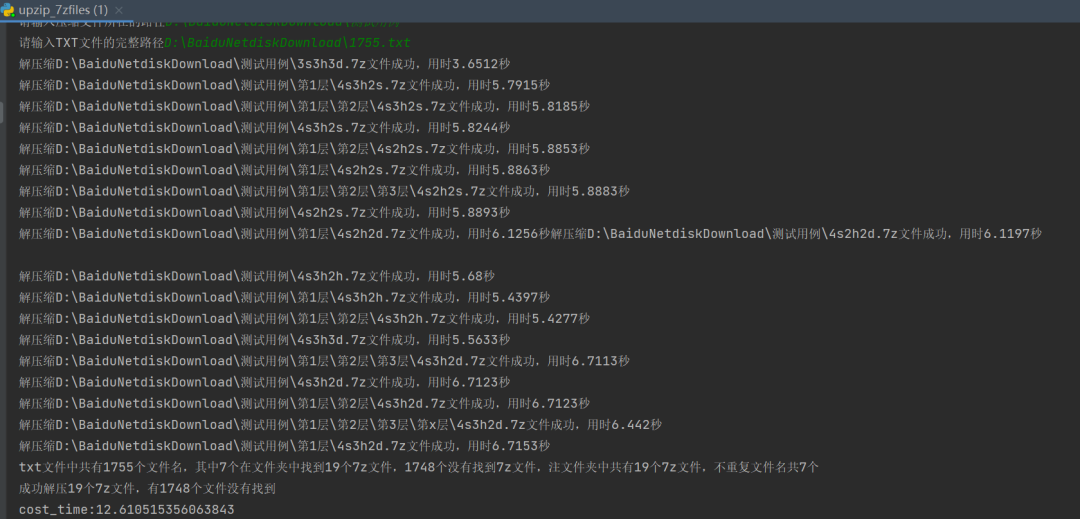
四、完整代码
import os
from py7zr import is_7zfile, SevenZipFile
from concurrent.futures import ThreadPoolExecutor
import time
class UnZipFiles:
def __init__(self):
self.root_path = input('请输入压缩文件所在的路径') # 根目录
self.zip_file_count = 0 # 初始化zip文件的个数
self.zip_file_dict = {} # 根目录中所有的7z文件字典,其中key为去除扩展名后的文件名,value为list格式,为7z文件的完整路径
self.txt_file = input('请输入TXT文件的完整路径') # 需要解压的TXT文件完整路径
self.unzip_files = None # 读取txt_file后解析的需要解压缩的文件list
self.not_found = [] # 没有找到的需要解压的文件list
self.found_files = [] # 有找到的需要解压的文件list
def read_txt_file(self, code='utf-8'):
"""
读取TXT文件,生成需要解压的文件list
:param code: 读取文件使用的编码格式
"""
with open(self.txt_file, 'r', encoding=code) as fin:
self.unzip_files = fin.read().split('\n')
def get_all_zip_files(self):
"""
使用os.walk模块遍历根目录下的所有7z文件,生成zip_file_dict
"""
for path, dirnames, filenames in os.walk(self.root_path):
for filename in filenames:
if filename.endswith('.7z') and not filename.startswith('~'):
self.zip_file_count += 1
full_path = os.path.join(path, filename)
filename = filename.replace('.7z', '')
if filename in self.zip_file_dict.keys():
self.zip_file_dict[filename].append(full_path)
else:
self.zip_file_dict[filename] = [full_path]
def check_files(self):
"""
检查文件,遍历unzip_files,与zip_file_dict的key匹配,有找到的放入found_files,没找到的放入not_found
"""
for file in set(self.unzip_files): #为预防TXT文件中存在重复的文件名,加个set集合去重
if file in self.zip_file_dict.keys():
for x in self.zip_file_dict[file]:
self.found_files.append(x)
else:
self.not_found.append(file)
def upzip_file(self, file_full_path):
"""
对单个7z文件进行解压缩,解压缩后的文件,放置在原7z文件所在路径下,解压成功后,删除7z文件
:param file_full_path: 需要传入完整的文件路径
:return: True or False
"""
if is_7zfile(file_full_path):
try:
start_time = time.time()
with SevenZipFile(file_full_path, mode='r') as sevenZ_f:
sevenZ_f.extractall(os.path.split(file_full_path)[0])
os.remove(file_full_path)
end_time = time.time()
print(f'解压缩{file_full_path}文件成功,用时{round(end_time-start_time, 4)}秒')
except Exception as e:
print('Error when uncompress file! info: ', e)
return False
else:
return True
else:
print('This is not a true 7z file!')
return False
def run_unzip(self, max_workers=10):
"""
开启多线程进行解压缩
:param max_workers: 开启的最大线程数,默认10个
"""
with ThreadPoolExecutor(max_workers=max_workers) as pool:
futures = [pool.submit(self.upzip_file, file) for file in self.found_files]
def write_not_found_file(self):
"""
当存在没有找到的解压文件时,写入文件,文件存放在与txt_file相同的目录下,命名为not_found_fifle.txt
"""
if len(self.not_found) > 0:
# txt_path = os.path.split(self.txt_file)[0]
txt_path = self.txt_file.replace('.txt', '_not_found.txt')
with open(txt_path, 'w', encoding='utf-8') as fout:
fout.write('\n'.join(self.not_found))
def run_program(self, code='utf-8', max_workers=10):
"""
按顺序运行程序
:param code: 读取txt_file的编码格式,默认utf-8
:param max_workers: 开启的线程数,默认10线程
"""
start = time.time()
self.read_txt_file(code) # 读取txt文件,生成unzip_files
self.get_all_zip_files() # 获取根目录下所有的7z文件字典
self.check_files() # 检查upzip_files是否都在字典中
self.run_unzip(max_workers) # 开启多线程进行解压缩
self.write_not_found_file() # 写入未找到的文件
end = time.time()
cost_time = end - start
print(f'txt文件中共有{len(self.unzip_files)}个文件名,其中{len(self.unzip_files)-len(self.not_found)}个在文件夹中找到{len(self.found_files)}个7z文件,{len(self.not_found)}个没有找到7z文件,注文件夹中共有{self.zip_file_count}个7z文件,不重复文件名共{len(self.zip_file_dict.keys())}个')
print(f'成功解压{len(self.found_files)}个7z文件,有{len(self.not_found)}个文件没有找到')
input(f'cost_time:{cost_time}秒,按回车键退出窗口')
if __name__ == '__main__':
obj = UnZipFiles()
obj.run_program()
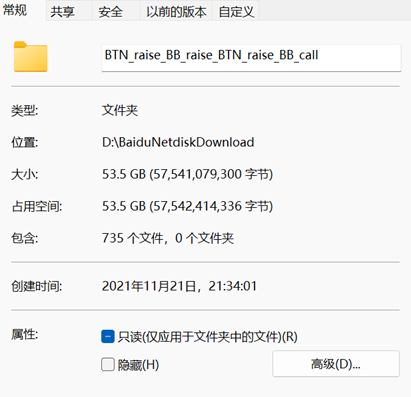
使用代码跑了一个需求方给的一个示例文件夹,里面上千个7z文件,下载并解压了其中735个,已经解压出53.5G的文件,几乎撑爆我的笔记本硬盘,只好放弃后续测试了。
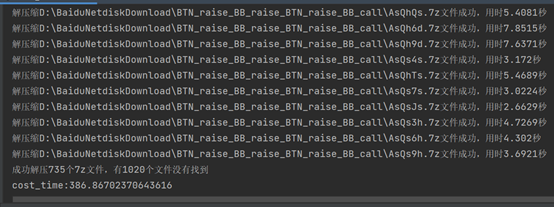
五、打包成exe可执行文件
功能成功实现之后就可以打包成exe可执行文件了,这个部分使用到了pyinstaller,虽然一开始不会,但是查阅了一些文档后,还是很简单的,网络上有很多教程就不重复写了,唯一需要注意的是:如果希望打包出来的exe执行文件尽可能的小,那么就需要创建虚拟环境,引入最少的包。个人试了一下,在anaconda环境下打包出来215M,在虚拟环境下只安装需要的包打包只有9M。
交稿
等待回复的空余时间,给蚂蚁老师投个稿,挣点稿费改善生活......不不不,我这是为了总结经验、加深印象、稳固知识......
晒单
最后还是要晒一下单,小金库又充实了,距离财富自由又迈进了一小步^_^