
【性能】零拷贝
零拷贝概念
避免数据拷贝
①避免操作系统内核缓冲区之间进行数据拷贝操作。
②避免操作系统内核和用户应用程序地址空间这两者之间进行数据拷贝操作。
③用户应用程序可以避开操作系统直接访问硬件存储。
④数据传输尽量让 DMA 来做。综合目标
①避免不必要的系统调用和上下文切换。
②需要拷贝的数据可以先被缓存起来。
③对数据进行处理尽量让硬件来做。
需要注意,它不能用于实现了数据加密或者压缩的文件系统上,只有传输文件的原始内容。这类原始内容也包括加密了的文件内容。
传统IO的执行流程
比如想实现一个下载功能,服务端的任务就是:将服务器主机磁盘中的文件从已连接的socket中发出去,关键代码如下:
while((n = read(diskfd, buf, BUF_SIZE)) > 0)write(sockfd, buf , n);
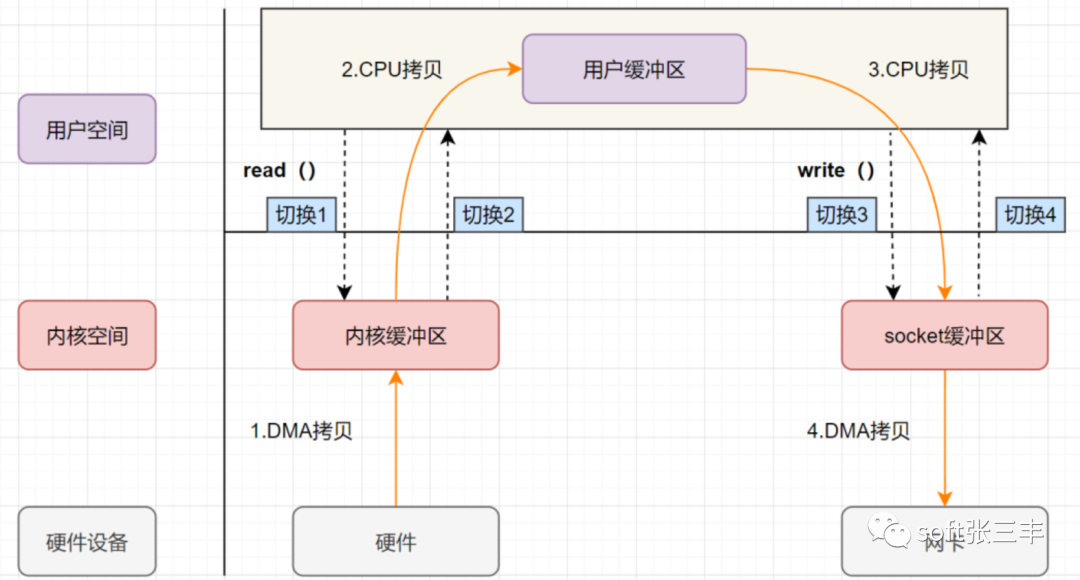
1.应用程序调用read函数,向操作系统发起IO调用,上下文从用户态切换至内核态
2.DMA控制器把数据从磁盘中读取到内核缓冲区
3.CPU把内核缓冲区数据拷贝到用户应用缓冲区,上下文从内核态切换至用户态,此时read函数返回
4.用户应用进程通过write函数,发起IO调用,上下文从用户态切换至内核态
5.CPU将缓冲区的数据拷贝到socket缓冲区
6.DMA控制器将数据从socket缓冲区拷贝到网卡设备,上下文从内核态切换至用户态,此时write函数返回
从流程图中可以看出传统的IO流程包括***4次上下文的切换***,4次拷贝数据(两次CPU拷贝以及两次DMA拷贝)
DMA技术
DMA,英文全称是Direct Memory Access,即直接内存访问。DMA本质上是一块主板上独立的芯片,允许外设设备和内存存储器之间直接进行IO数据传输,其过程不需要CPU的参与。
简单的说它就是帮住CPU转发一下IO请求以及拷贝数据,那为什么需要它呢?其实主要是效率问题。它帮忙CPU做事情,这时候,CPU就可以闲下来去做别的事情,提高了CPU的利用效率。大白话解释就是,CPU老哥太忙太累啦,所以他找了个小弟(名叫DMA) ,替他完成一部分的拷贝工作,这样CPU老哥就能着手去做其他事情。
下面看下DMA具体是做了哪些工作
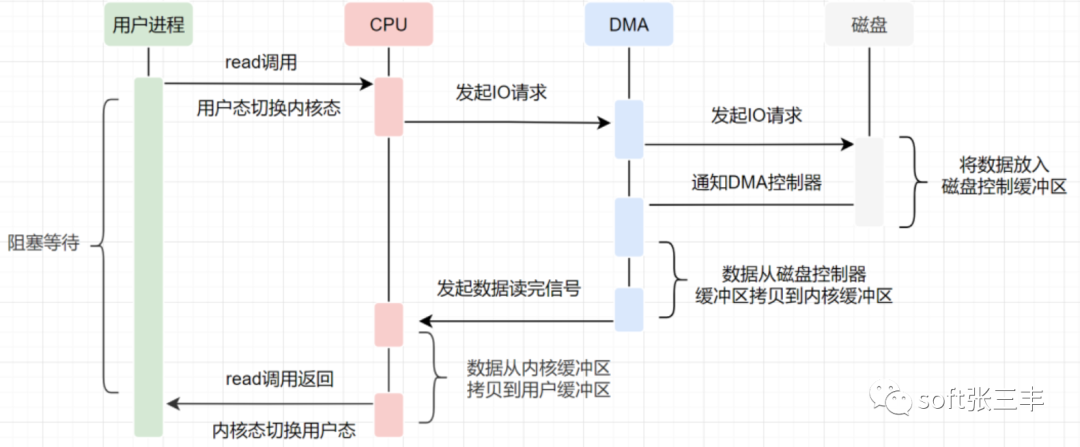
1.用户应用程序调read函数,向操作系统发起IO调用,进入阻塞状态等待数据返回。
2.CPU接到指令后,对DMA控制器发起指令调度。
3.DMA收到请求后,将请求发送给磁盘。
4.磁盘将数据放入磁盘控制缓冲区并通知DMA。
5.DMA将数据从磁盘控制器缓冲区拷贝到内核缓冲区。
6.DMA向CPU发送数据读完的信号,CPU负责将数据从内核缓冲区拷贝到用户缓冲区。
7.用户应用进程由内核态切回用户态,解除阻塞状态。
java提供的零拷贝方式
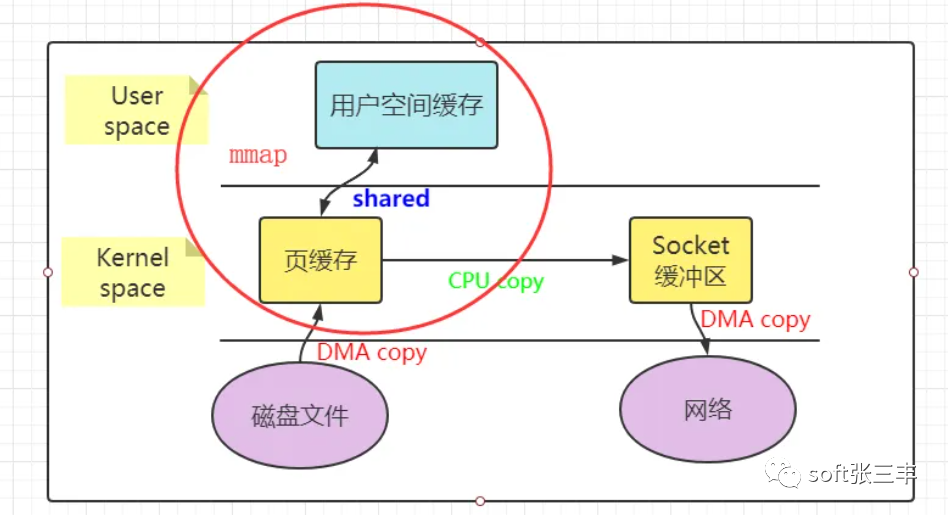
mmap
public class MmapTest {public static void main(String[] args) {try {FileChannel readChannel = FileChannel.open(Paths.get("./jay.txt"), StandardOpenOption.READ);MappedByteBuffer data = readChannel.map(FileChannel.MapMode.READ_ONLY, 0, 1024 * 1024 * 40);FileChannel writeChannel = FileChannel.open(Paths.get("./siting.txt"), StandardOpenOption.WRITE, StandardOpenOption.CREATE);//数据传输writeChannel.write(data);readChannel.close();writeChannel.close();}catch (Exception e){System.out.println(e.getMessage());}}}
为SIGBUS信号建立信号处理程序
当遇到SIGBUS信号时,信号处理程序简单地返回,write系统调用在被中断之前会返回已经写入的字节数,并且errno会被设置成success,但是这是一种糟糕的处理办法,因为你并没有解决问题的实质核心。使用文件租借锁
通常我们使用这种方法,在文件描述符上使用租借锁,我们为文件向内核申请一个租借锁,当其它进程想要截断这个文件时,内核会向我们发送一个实时的RT_SIGNAL_LEASE信号,告诉我们内核正在破坏你加持在文件上的读写锁。这样在程序访问非法内存并且被SIGBUS杀死之前,你的write系统调用会被中断。write会返回已经写入的字节数,并且置errno为success。
我们应该在mmap文件之前加锁,并且在操作完文件后解锁if(fcntl(diskfd, F_SETSIG, RT_SIGNAL_LEASE) == -1) {perror("kernel lease set signal");return -1;}/* l_type can be F_RDLCK F_WRLCK 加锁*//* l_type can be F_UNLCK 解锁*/if(fcntl(diskfd, F_SETLEASE, l_type)){perror("kernel lease set type");return -1;}
sendfile
public class SendFileTest {public static void main(String[] args) {try {FileChannel readChannel = FileChannel.open(Paths.get("./jay.txt"), StandardOpenOption.READ);long len = readChannel.size();long position = readChannel.position();FileChannel writeChannel = FileChannel.open(Paths.get("./siting.txt"), StandardOpenOption.WRITE, StandardOpenOption.CREATE);//数据传输readChannel.transferTo(position, len, writeChannel);readChannel.close();writeChannel.close();} catch (Exception e) {System.out.println(e.getMessage());}}}
从2.1版内核开始,Linux引入了sendfile来简化操作:
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);
系统调用sendfile()在代表输入文件的描述符in_fd和代表输出文件的描述符out_fd之间传送文件内容(字节)。描述符out_fd必须指向一个套接字,而in_fd指向的文件必须是可以mmap的。这些局限限制了sendfile的使用,使sendfile只能将数据从文件传递到套接字上,反之则不行。使用sendfile不仅减少了数据拷贝的次数,还减少了上下文切换,数据传送始终只发生在kernel space。
在我们调用sendfile时,如果有其它进程截断了文件会发生什么呢?假设我们没有设置任何信号处理程序,sendfile调用仅仅返回它在被中断之前已经传输的字节数,errno会被置为success。如果我们在调用sendfile之前给文件加了锁,sendfile的行为仍然和之前相同,我们还会收到RT_SIGNAL_LEASE的信号。
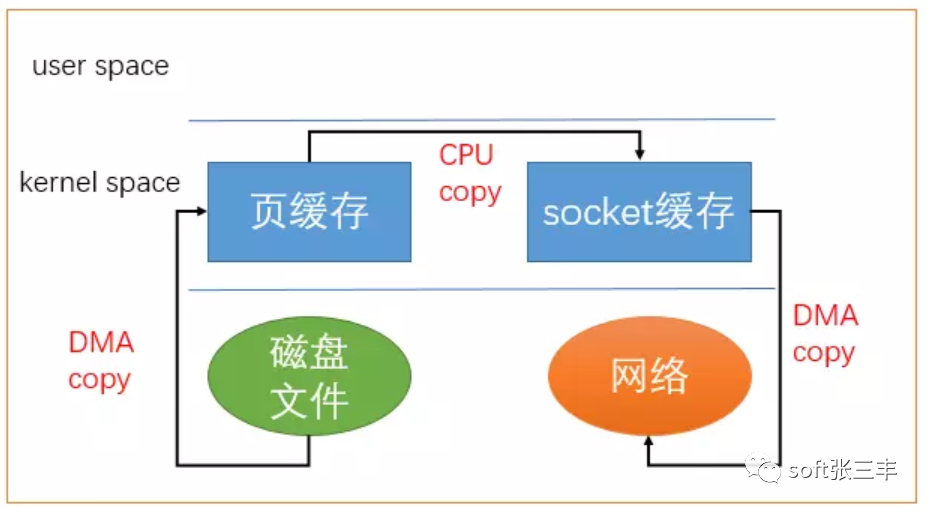
目前为止,我们已经减少了数据拷贝的次数了,但是仍然存在一次拷贝,就是页缓存到socket缓存的拷贝。那么能不能把这个拷贝也省略呢?
借助于硬件上的帮助,我们是可以办到的。之前我们是把页缓存的数据拷贝到socket缓存中,实际上,我们仅仅需要把缓冲区描述符传到socket缓冲区,再把数据长度传过去,这样DMA控制器直接将页缓存中的数据打包发送到网络中就可以了。
总结一下,sendfile系统调用利用DMA引擎将文件内容拷贝到内核缓冲区去,然后将带有文件位置和长度信息的缓冲区描述符添加socket缓冲区去,这一步不会将内核中的数据拷贝到socket缓冲区中,DMA引擎会将内核缓冲区的数据拷贝到协议引擎中去,避免了最后一次拷贝。不过这一种收集拷贝功能是需要硬件以及驱动程序支持的。
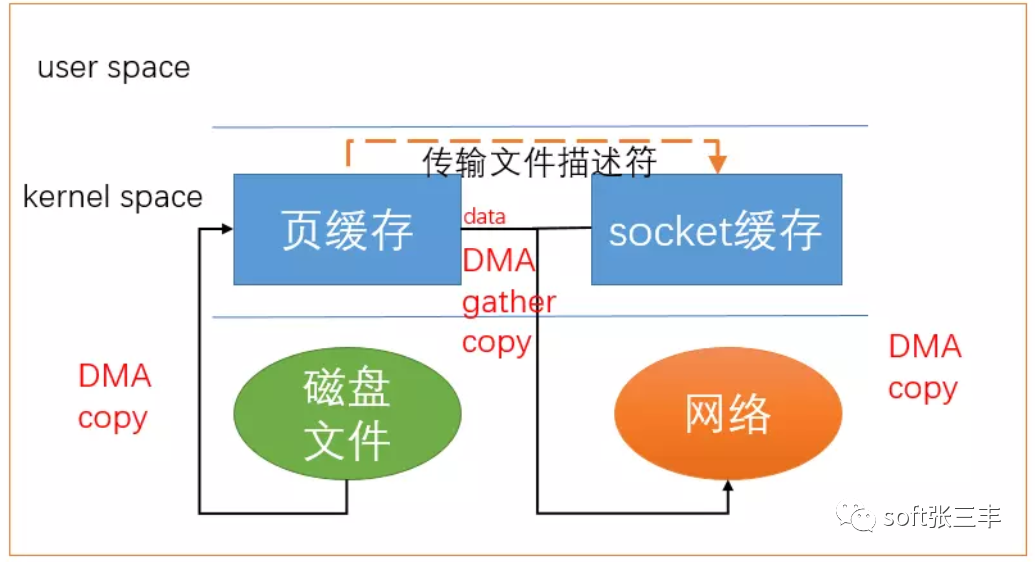
无论是传统的 I/O 方式,还是引入了零拷贝之后,2 次 DMA copy是都少不了的。因为两次 DMA 都是依赖硬件完成的。所以,所谓的零拷贝,都是为了减少 CPU copy 及减少了上下文的切换。
下图展示了各种零拷贝技术的对比图:

Netty 的零拷贝
主要包含三个方面:
(1)Netty 的接收和发送 ByteBuffer 采用 DIRECT BUFFERS ,使用堆外直接内存进行 Socket 读写,不需要进行字节缓冲区的二次拷贝。如果使用传统的堆内存 ( HEAP BUFFERS)进行 Socket 读写, JVM 会将堆内存 Buffer 拷贝一份到直接内 存中,然后才写入 Socket 中。相比于堆外直接内存,消息在发送过程中多了一次缓 冲区的内存拷贝。
(2)Netty 提供了组合 Buffer 对象,可以聚合多个 ByteBuffer 对象,用户可以像操作一个 Buffer 那样方便的对组合 Buffer 进行操作,避免了传统通过内存拷贝的方式 将几个 小 Buffer 合并成一个大的 Buffer 。
(3)Netty 的文件传输采用了 transferTo 方法,它可以直接将文件缓冲区的数据发送到目标 Channel ,避免了传统通过循环 write 方式导致的内存拷贝问题。
零拷贝机制是Netty高性能的一个原因,之前都是说netty的线程模型,责任链,说说netty底层的优化,优化就是netty自己的一个缓冲区。
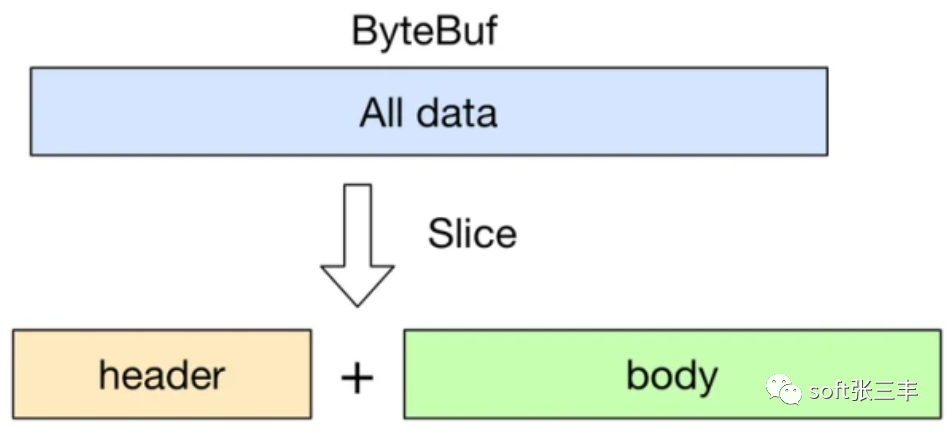
(一)Netty自己的ByteBuf
介绍
ByteBuf 是为解决 ByteBuffer的问题和满足网络应用程序开发人员的日常需求而设计的。
对比JDK byteBuffer的缺点
无法动态扩容
长度是固定的,不能动态扩展和收缩,当数据大于ByteBuffer容量时,会发生索引越界异常。
API 使用复杂
读写的时候需要手工调用flip()和rewind()等方法,使用时需要非常谨慎的考虑这些API,否则容出现错误。
Netty的ByteBuf 操作
ByteBuf三个重要属性:capacity容量,readerIndex读取位置,writerIndex 写入位置。提供了两个指针变量来支持顺序和写操作,分别是读操作readerIndex 和写操作writeIndex。
常见的方法定义
随机访问索引 getByte
顺序读 read*
顺序写 write*
清除已读内容discardReadBytes
清除缓冲区 clear
搜索操作
标记和重置
引用计数和释放
缓冲区是如何被两个指针分割成三个区域的
discardable bytes 已读可丢弃区域
readable bytes 可读区域
writable bytes 待写区域
ByteBuf 动态扩容
capacity 默认值:256字节,最大值:Integer.MAX_VALUE(2GB)
write 方法调用时,通过AbstractByteBuf.ensureWritable进行检查。
容量计算方法:AbstractByteBufAllocator.calculateNewCapacity(新capacity的最小要求,capacity最大值)
根据新的capacity的最小值要求,对应有两套计算方法
没超过4兆:从64字节开发,每次增加一倍,直至计算出来的newCapacity满足新容量最小要求。示例:当前大小256,已写250,继续写10字节数据,需要的容量最小要求是261,则新容量是6422*2=512
超过4兆:新容量 = 新容量最小要求/4兆 * 4兆 +4兆
示例:当前大小3兆,已写3兆,继续写2兆数据,需要的容量最小要求是5兆, 则新容量是9兆(不能超过最大值)
选择合适的 ByteBuf 实现
在实际使用中都是通过 ByteBufAllocator 分配器进行申请,同时分配器具有内存管理的功能。
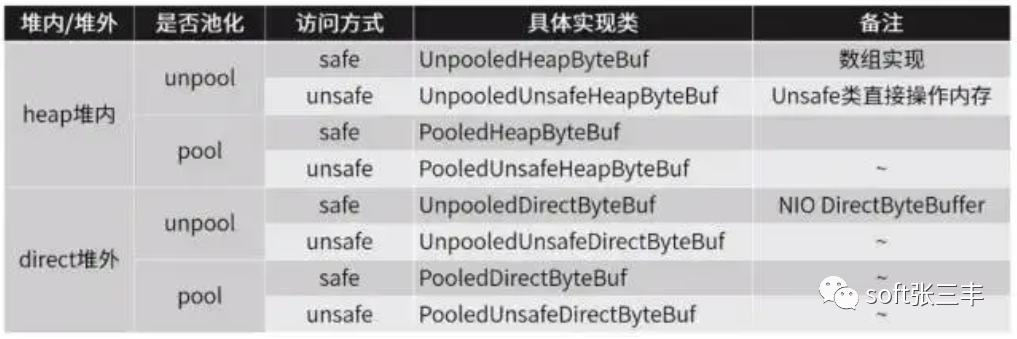
unsafe 用到了 Unsafe 工具类,Unsafe 是 Java 保留的一个底层工具包,safe 则没有用到 unsafe 工具类。
unsafe 意味着不安全的操作,但是更底层的操作会带来性能提升和特殊功能,Netty 中会尽力使用 unsafe。
Java 语言很重要的特性是“一次编写导出运行”,所以它针对底层的内存或其他操作,做了很多封装。而 unsafe 提供了一系列操作底层的方法,可能会导致不兼容或者不可知的异常。
unpool 每次申请缓冲区时会新建一个,并不会复用,使用 Unpooled 工具类可以创建 unpool 的缓冲区。
Netty 没有给出很便捷的 pool 类型的缓冲区的创建方法。使用 ChannelConfig.getAllocator() 时,获取到的分配器是默认支持内存复用的。
pooledByteBuf对象、内存
PoolThreadCache: PooledByteBufAllocator 实例维护了一个线程变量。
多种分类的MemoryRegionCache数组用作内存缓存,MemoryRegionCache内部是链表,队列里面存Chunk。
Pool Chunk里面维护了内存引用,内存复用的做法就是把buf的memory指向Chunck的memory。
Netty 的零拷贝机制,是一种应用层的实现。
拷贝方式
一般的数组合并,会创建一个大的数组,然后将需要合并的数组放进去。
Netty 的 CompositeButyBuf 将多个 ByteBuf 合并为一个逻辑上的 ByteBuf,避免了各个 ByteBuf 之间的拷贝。
wrappedBuffer 方法将 byte[] 数组包装成 ByteBuf 对象
slice 方法将一个 ByteBuf 对象切分成多个 ByteBuf 对象
实例
PS:API操作便捷性,动态扩容,多种ByteBuf实现,高效的零拷贝机制(逻辑上边的设计)上边的所有就是nettyByteBuf所做的工作,性能提升,操作性增强。