
基于mmdetection框架算法可视化分析随笔(上)
AI编辑:深度眸
0 摘要
mmdetection是一个非常优秀的目标检测框架,不仅仅有出色的框架可扩展性,而且默认集成了几乎目前最常用的各种sota目标检测算法,提供了超级多开箱即用的特性,实在是良心框架。
其对于不同的算法都提供了一套基于coco数据集上的默认配置,比较好用,但是对于不同的实际数据集,这些参数就不一定适用了,故大部分时候都需要明白修改这些默认参数带来的影响,一个最快的途径就是各种可视化分析。故结合一些我觉得非常重要的参数配合可视化分析,通常可以快速对该参数有个感性上的理解。本文就是基于mmdetection框架代码,加入一些可视化分析代码,希望对大家理解框架流程和参数重要性有点帮助。
由于本人水平有限,如果写的不好,望见谅。如果大家有好的想法我没有涉及的可视化部分,欢迎留言。
这一篇以最新的mmdetection v2,版本号是2.2.0+741b638,faster rcnn部分代码为例进行可视化分析。包括anchor可视化,正样本数统计、正样本anchor质量可视化。
1 anchor 可视化
在基于anchor-base的算法中,anchor的重要性不言而喻,故第一个可视化就是对anchor进行深入分析。其典型配置如下:
Anchor_generator=dict(type='AnchorGenerator',scales=[8],ratios=[0.5, 1.0, 2.0],strides=[4, 8, 16, 32, 64]),
可以看出,其类是AnchorGenerator,缩放系数是8,宽高比例有三种,基于原图的下采样strides是5个尺度,也就是5个输出层,每个位置有3个anchor。以最大输出特征图即stride=4的层为例,可以发现其anchor的base
size=4*8=32像素。
V2版本的AnchorGenerator的生成anchor过程非常好理解,比v1版本好理解很多。代码在mmdet/core/anchor/anchor_generator.py,其核心流程是:
(1) 先对单个位置(0,0)生成base anchors
假设stride=4,ratios=[0.5, 1.0,
2.0],则首先利用ratio生成3种宽高比例的ratios,然后对base_size即stride乘以宽高比例和scale,然后转换为x1y1x2y2坐标格式输出,此时(0,0)特征图位置就可以得到3个x1y1x2y2的anchors。
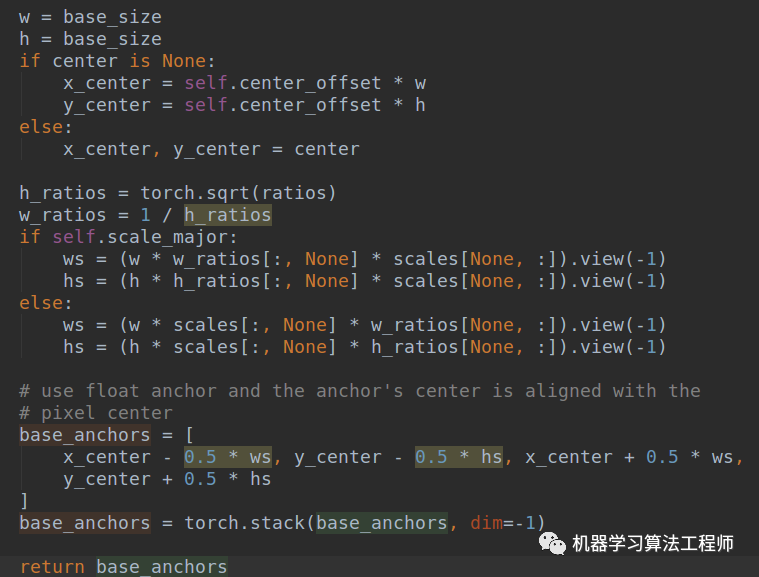
在V2版本中,center默认是none,没有刻意偏移0.5。即上述得到的anchor坐标是基于左上角定义的。
(2) 利用输入的特征图大小加上base anchors,得到每个特征图位置的对于原图的anchors
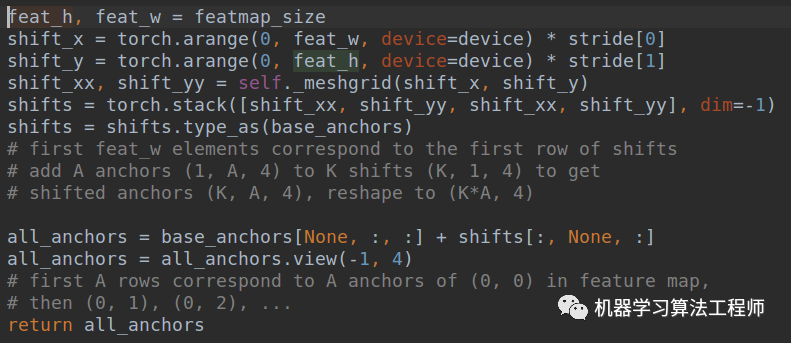
可以看出就是简单的base_anchors[None, :, :] + shifts[:, None, :]而已。
下面进行可视化分析。首先举一个非常简单的例子说明:
input_shape_hw = (10, 10, 3)stride = 5feature_map = [input_shape_hw[0] // stride, input_shape_hw[1] // stride]anchor_generator_cfg = dict(type='AnchorGenerator',scales=[1], # 缩放系数ratios=[1.0], # 宽高比例strides=[stride]) # 特征图相对原图下降比例
假设输入原图是10x10,stride=5,也就是下采样5倍,得到特征图大小是2x2,假设scales=1,比例只有1种,则首先可以知道会生成:2x2x1=4个anchor。
[[-2.5 -2.5 2.5 2.5][ 2.5 -2.5 7.5 2.5][-2.5 2.5 2.5 7.5][ 2.5 2.5 7.5 7.5]]
首先生成base anchor,base size=5,乘上宽高比例、scale,得到5,然后计算x1y1x2y2=[0-5/2,0-5/2,5/2,5/2]。然后得到4个offset,即[0,0,0,0]、[5,0,5,0]、[0,5,0,5]和[5,5,5,5],最后加起来即可得到上述。
为了稍微好看一点,我写了下可视化代码,如下所示:
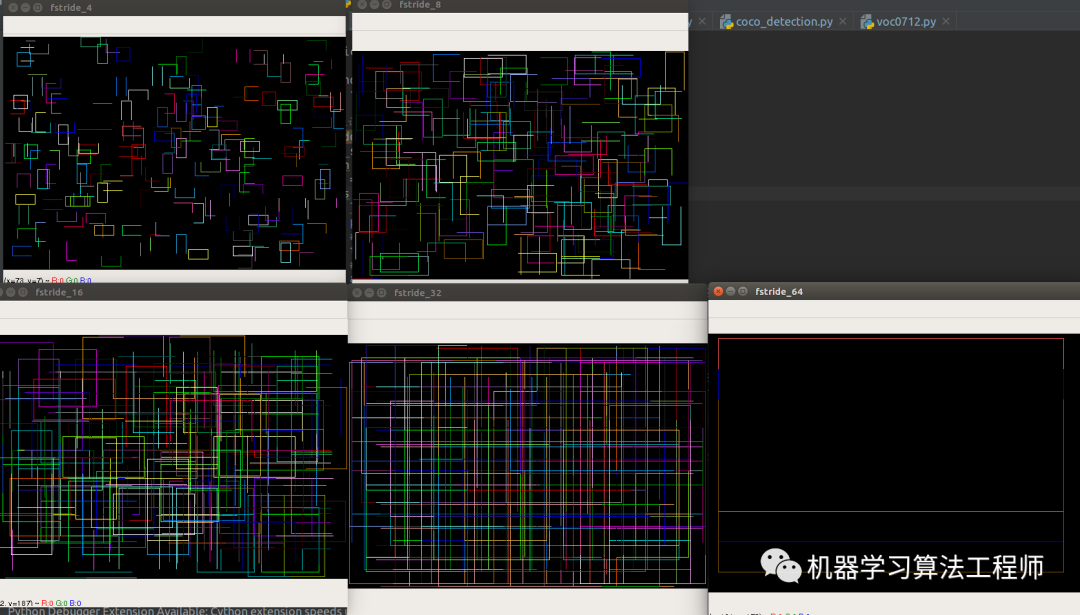
前随机选择200个可视化如下所示:

当scale=8时候,随机选择50个anchor:

联系具体faster rcnn算法,也可以把按照上述方式可视化出来。为了简单,我就直接在faster rcnn算法里面显示出来,具体为:在mmdet/models/dense_heads/anchor_head.py的loss函数的大概475行,也就是:
anchor_list, valid_flag_list = self.get_anchors(featmap_sizes, img_metas, device=device)
代码下面插入:
代码写的比较随意,请见谅。可以得到如下显示:
2 RPN正样本anchor相关分析
前段时间,有位知乎友问我一个问题:请问一下降低RPN、RCNN的IOU阈值会有什么影响吗?这是一个非常好的问题,我们一直习惯了用默认值,所以我想通过可视化分析看下有没有办法基于不同项目确定该阈值?
以RPN为例,RCNN也是一样道理,其正样本阈值的选择会决定正样本数量以及质量,进而会影响最终结果,在级联rcnn里面分析的已经蛮透彻了。
RPN层的配置如下:
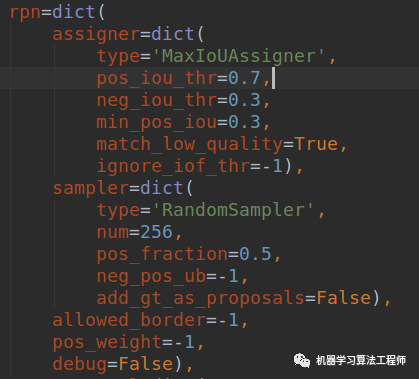
其采用最大iou分配原则,其实现细节和原理具体参见微信公众号或者知乎文章:目标检测正负样本区分策略和平衡策略总结(一)。
负样本预测neg_iou_thr一般不用调整,主要是pos_iou_thr,默认是0.7,比较高。注意这个默认值是基于coco数据集确定的,换一个数据集不一定适合。我们来统计下正样本个数,由于mmdetection计算正样本anchor都是基于单张图片的,故我们分析也是对单张图片分析。要统计正样本数非常简单,仅仅在mmdet/models/dense_heads/anchor_head.py的_get_targets_single函数里面,大概231行即:
assign_result = self.assigner.assign(anchors, gt_bboxes, gt_bboxes_ignore,None if self.sampling else gt_labels)
下面加入如下代码:
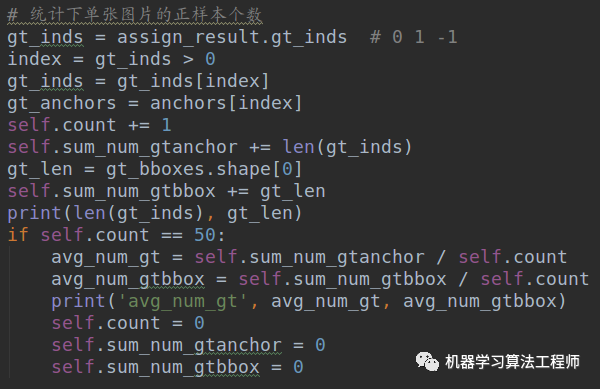
就可以在训练过程中实时打印每张图片的正样本个数。self.count、self.sum_num_gtanchor和self.sum_num_gtbbox是初始化时候定义的两个变量,初始化都是0,目的是每隔50张图片计算一下平均正样本个数和gt
bbox数目。
在coco数据集上,当pos_iou_thr=0.7时候,每张图片的大概数目是:
21 5 47 7 10 5 114 42 60 68 7 13 6 50 41 96 59 127 358 70 5 13 7 13 7 27 57 19 16 71 10 3 11 66 3 17 4242 9 44 39 37 8 50 13 27 15 46 4
平均数是:
32.6 29.76 41.42 36.14 33.5 35.18 29.8当pos_iou_thr=0.5时候,每张图片的大概数目是:
68 56 83 40 53 57 530 124 267 348 50 80 44 211 48353 336 264 27 91 118 51 13 78 52 48 193 134 41 83100 36 42 60 93 30 149 185 205 48 217 193 135 77 26631 115 48 308 44
平均数是:
126.46 120.68 160.3 155.48 136.78 137.18 114.42而gt bbox的平均数是:
6.48 7.16 8.44 7.98 7.32 7.44 5.88 5.82当阈值设置为0.7时候,gt bbox占据gt anchor比例大概是21.1% ,而阈值为0.5时候,比例为5.3%,通过这个比例大概可以估计每个gt bbox平均分配了几个anchor,如果想更加精细,则需要分别统计大小gt bbox的分配情况。可以明显看出:当阈值设置为0.5时候,正样本数目急剧增加,几乎是0.7的4倍了。
在voc数据集上,当pos_iou_thr=0.7时候,每张图片的大概数目是:
7 6 4 3 3 4 5 26 3 11 3 13 8 6 13 8 12 13 17 6 1813 6 14 5 19 5 2 10 8 10 10 16 41 5 27 5 2 8 9 834 10 53 14 6 6 2 7 4
平均数是:
10.96 8.1 9.08 8.88 8.02 9.08 8.38 9.38当pos_iou_thr=0.5时候是:
58 6 18 30 30 31 46 113 15 80 32 69 31 9 60 73 103 3854 6 30 77 71 130 32 112 43 26 84 62 64 89 24 124 27 28441 6 71 36 73 153 47 232 53 30 23 28 52 34
平均数是:
61.2 46.32 51.74 48.92 45.34 53.72 51.2 52.36而对应的gt bbox的平均数是:
2.66 2.06 2.22 2.06 1.84 2.36 2.2当阈值设置为0.7时候,gt bbox占据gt anchor比例大概是21.7% ,而阈值为0.5时候,比例为3.8%。
由于coco数据单张图片中bbox数目比voc多很多,所以在阈值相同情况下,单张图片coco的正样本anchor个数会比voc多。这样看起来好像voc阈值设置为0.7也是合适的。其实不一定,因为后面还有一个采样参数256。
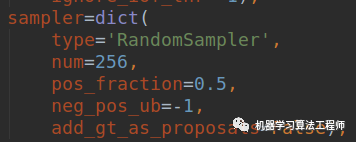
每张图片采样256个样本,并且正负比例是1:1,如果正样本很多,则会随机选择128个,由于正样本增加了很多,导致随机选择的很可能是大量低质量的anchor,故对学习是不利的,所以在coco上面阈值设置为0.5不太合适,但是我觉得voc上面设置0.7也不太合适,正样本稍微有点少,可以适当降低下。
个人经验,实际上该阈值的选择和很多参数都有联系,例如图片中gt
bbox个数、anchor设置是否合理、后续采样策略和match_low_quality。在大部分场景下,0.7应该是该参数的最大值了,已经非常高了,不同项目应该是维持不变或者稍微下降,太高会导致明显漏报,太低会导致回归质量比较差。
如果数据量不多,最好还是在0.5~0.7之间设置几个参数跑几次对比实验,比较靠谱,或者从大数据里面挑选一些数据组成小数据集,进行对比实验。在可视化方面,可以可视化所有正样本的anchor,可以初步看下anchor质量,其代码非常简单,在上面的统计代码后面增加:
需要注意的是,我们希望得到输入到网络前的图片,则需要在datasets配置文件里面,把img的key添加到meta_keys,如下所示:

就是在原始的meta_keys后面新增'img'就可以了。
选几张典型图片可视化如下。白色bbox是gtbbox 正样本阈值为0.7时候,voc数据:




正样本阈值为0.5时候,voc数据:

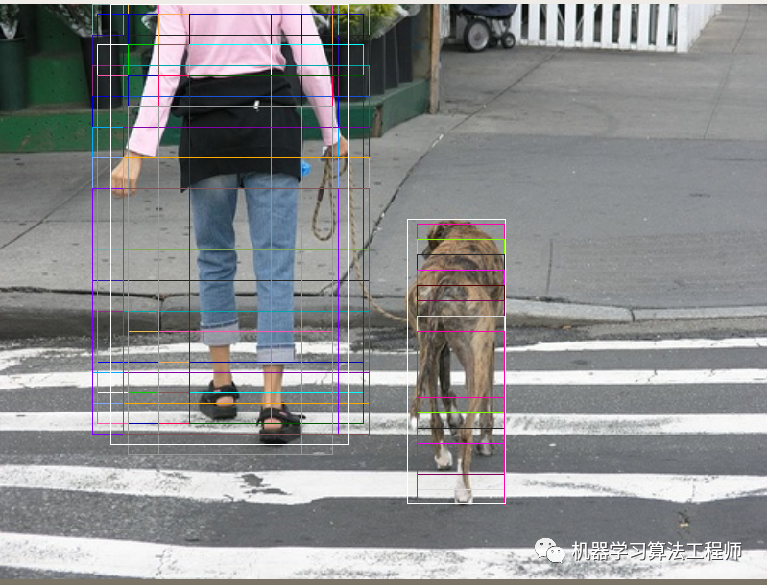


从这里来看,voc设置为0.7有点高,但是设置为0.5也是太低了,或许中间值可以。
coco数据集上面也是一样,如下所示:
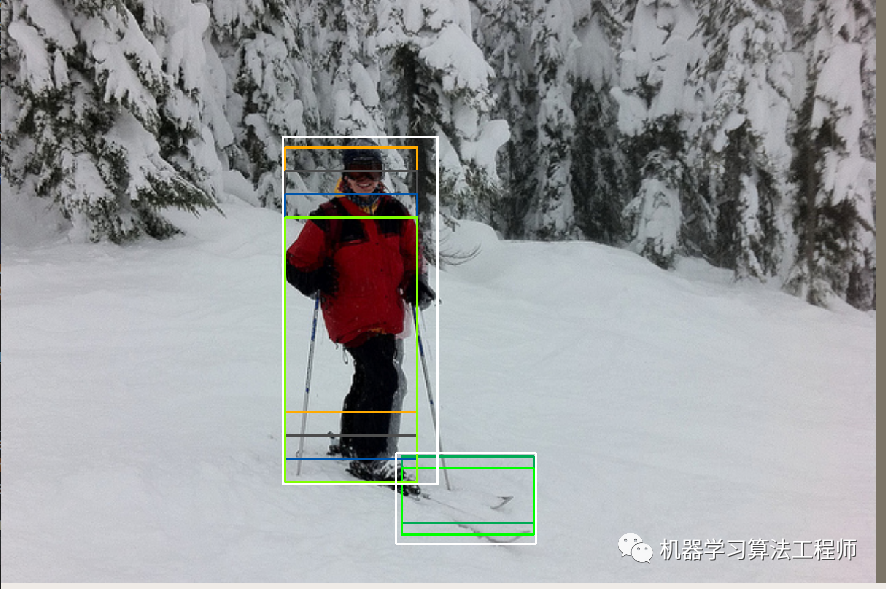
如果还想看每个anchor和gt bbox的匹配iou,还可以把这个数值绘制在上方,更加好看一些。
3 RPN预测输出可视化
通常我都会看下RPN预测的bbox都是张啥样,故可以通过实时保存图片或者采用tensorboard进行存储。我这里就简单看下RPN的预测输出,方法非常多种,我的写法是:
在mmdet/models/detectors/two_stage.py的forward_train方法里面,在
proposal_list = self.rpn_head.forward_train(x,img_metas,gt_bboxes,gt_labels=None,gt_bboxes_ignore=gt_bboxes_ignore,proposal_cfg=proposal_cfg)
代码后面插入如下代码即可:
和前面代码几乎差不多,只不过这里多了一个预测概率显示。如果从头训练coco数据,那么刚开始时候会显示如下:


可以看出,刚开始训练时候RPN预测输出其实就是相当于随机输出。
如果我采用mmdetection训练好的模型faster_rcnn_r50_fpn_2x_coco_bbox_mAP-0.384_20200504_210434-a5d8aa15.pth进行可视化,如下所示(如果可视化前1000个,会太密集不好看,故我修改参数为300):


这个是mAP等于0.384的模型,实际上看RPN的预测结果也不是很好,正如GA论文里面提到的,很多预测框都是在没有语义的地方,有些特别奇怪的超大预测框出现,但是幸好gt bbox还是有蛮多roi框住了。
4 RCNN正样本anchor可视化
其配置如下:
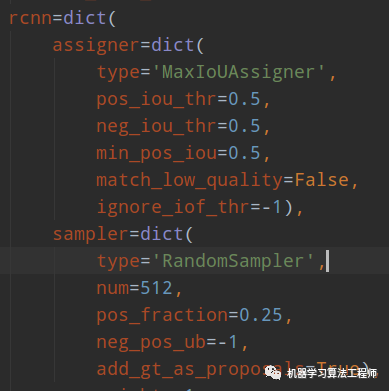
RCNN部分可视化代码和RPN代码是完全相同的,只是位置不一样而已,具体就是在mmdet/models/roi_heads/standard_roi_head.py的forward_train函数的:
assign_result = self.bbox_assigner.assign(proposal_list[i], gt_bboxes[i], gt_bboxes_ignore[i],gt_labels[i])
代码下面加入和RPN一样的正样本分析和可视化代码(我这里加的是简化版):
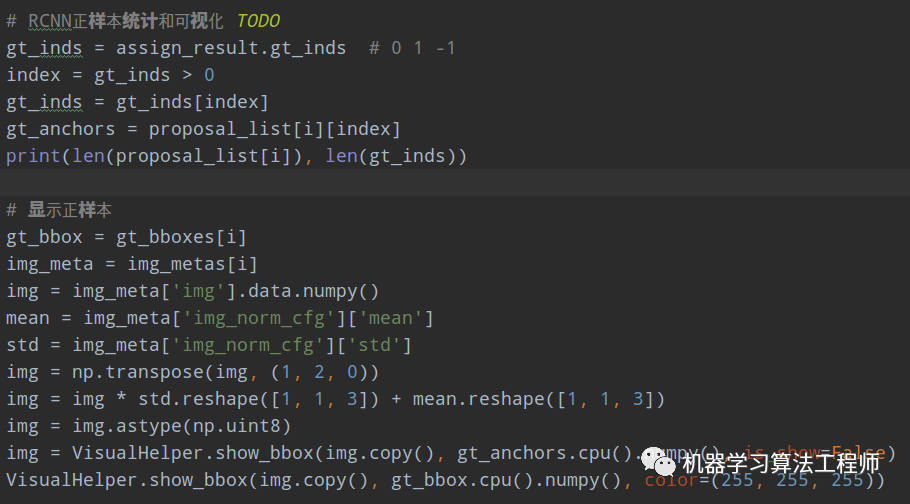
在mmdetection训练好的模型faster_rcnn_r50_fpn_2x_coco_bbox_mAP-0.384_20200504_210434-a5d8aa15.pth上可视化如下:

1000个roi,正样本有59个。看起来还不错。 如果从头训练,则开始时候显示如下:

正样本只有3个,而gt bbox有4个。可以明显看出,随着rpn训练过程的不断迭代,正样本数目会慢慢增加。但是需要注意的是在RCNN后面的RandomSampler采样类里面会开启参数add_gt_as_proposals=True,因为我们可以看到开始训练时候正样本太少了,会导致收敛很慢,故会增加gt bbox,然后再进行随机采样。
同时在这里,大家也可以统计输入的1000个roi和gt bbox的平均iou,并且结合极联rcnn来分析看是否现象和论文一致。
如果先看RCNN预测前后bbox变化,这个可视化的目的是可以最终每个正样本anchor回归情况,还是比较关键的。我这里暂时就是显示而已,并没有真正的追踪(要追踪比较容易,因为他的正样本anchor顺序并没有改变),其具体做法是:
(1) 可视化正样本anchor
在mmdet/models/roi_heads/standard_roi_head.py的forward_train函数里面,在如下代码:
sampling_result = self.bbox_sampler.sample(assign_result,proposal_list[i],gt_bboxes[i],gt_labels[i],feats=[lvl_feat[i][None] for lvl_feat in x])
后面新增预测前anchor的情况:
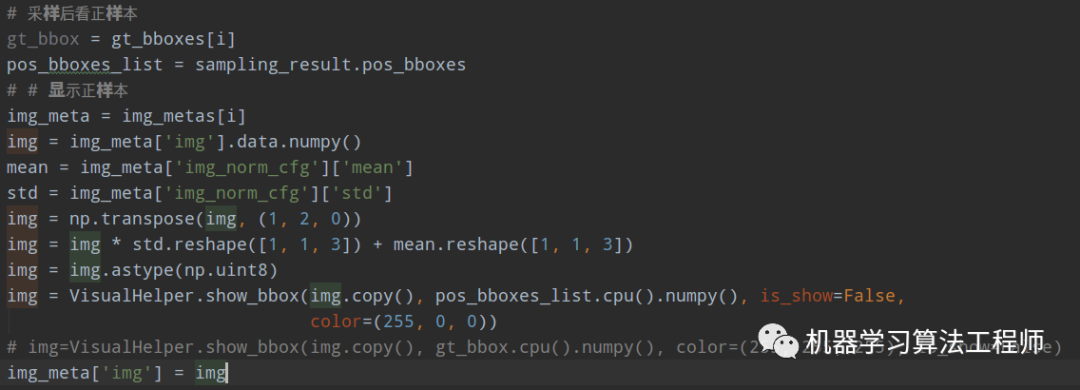
这里没有直接显示,而且把图片临时存储起来了,方便后面用。
(2) 解码预测bbox和类别,并且暂时保存内容
在mmdet/models/roi_heads/bbox_heads/bbox_head.py的loss函数的如下代码:
if pos_inds.any():后面追加:
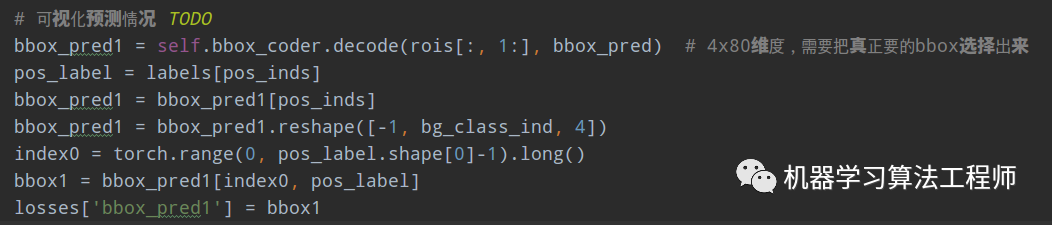
由于rcnn的bbox预测输出是80x4的,故还需要基于label或者预测类别切分出需要的bbox值。并且暂时保存起来,注意key不要和框架代码中已经存在的key重复,否则可能会出现一些莫名其妙的bug。
(3) 联合显示
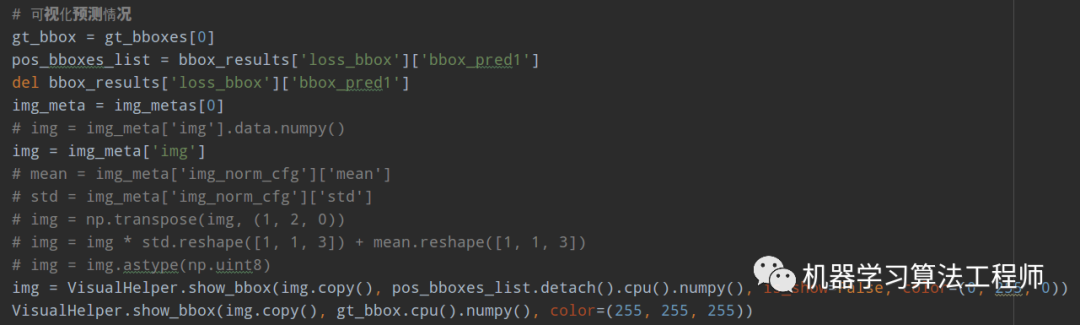
由于前面已经保存了可视化图,故这里就直接读取就行,具体操作是:
在mmdet/models/roi_heads/standard_roi_head.py的forward_train函数的如下代码:
bbox_results = self._bbox_forward_train(x, sampling_results,gt_bboxes, gt_labels,img_metas)
后面追加如下:
白色的gt bbox,蓝色的预测前anchor或者说roi的bbox,绿色是预测后的基于anchor解码后的bbox:
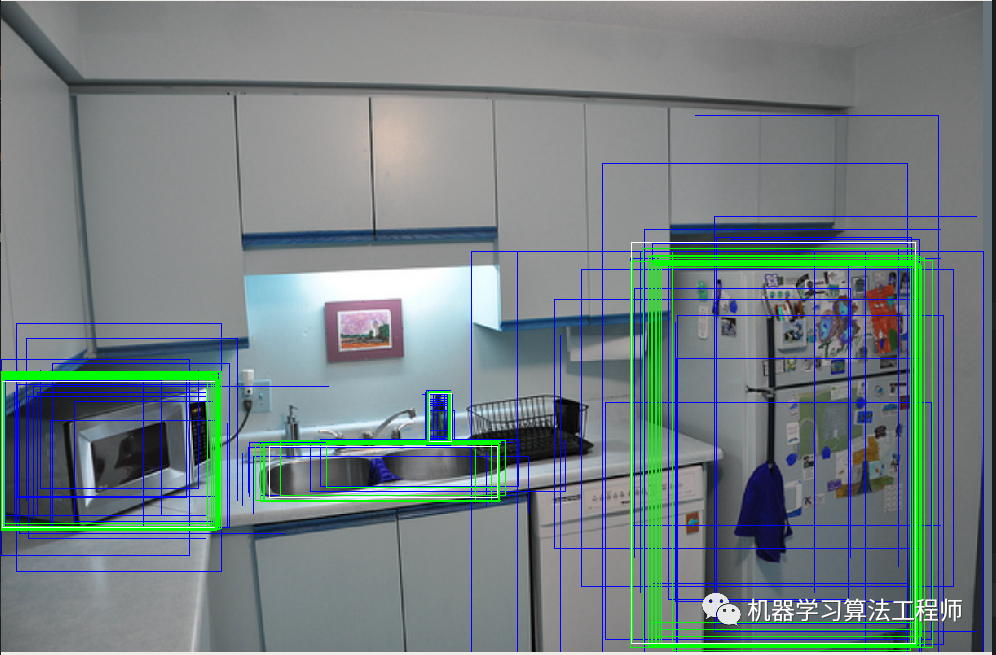
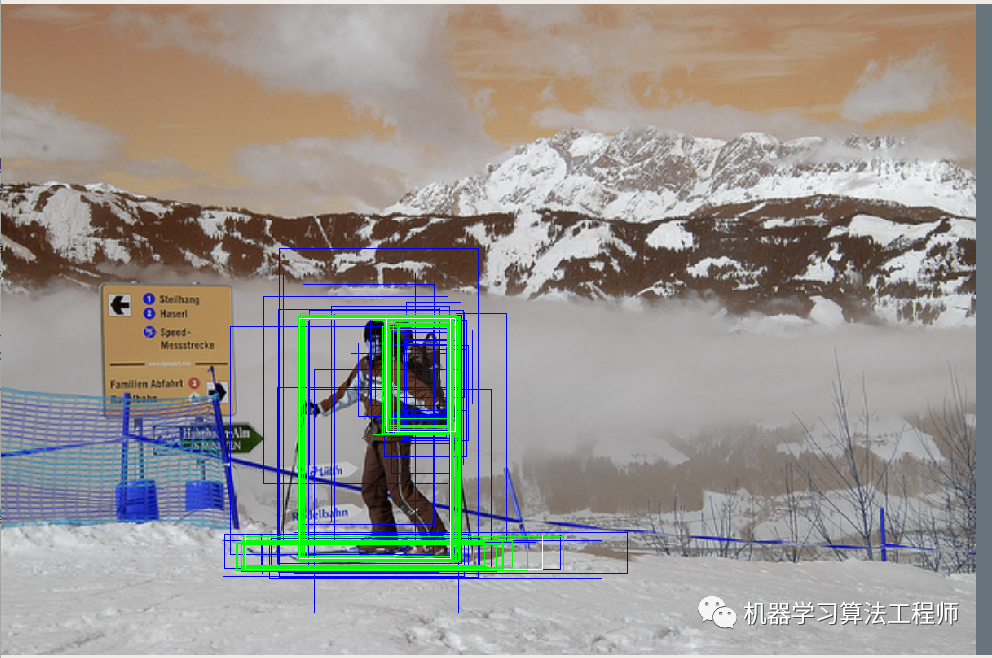
回归效果蛮不错的。
5 本文小结
通过可视化分析,主要目的是熟悉代码原理、框架实现过程和多超参的大概理解。这里我分析的还是比较浅陋,如果大家有更加深入的分析可视化,欢迎留言。
推荐阅读
机器学习算法工程师
一个用心的公众号
