
让我们来看看池化技术有多牛?
生活案例 1
早些年间,某宝双“11”突然爆火,然后无数个男男女女疯狂“剁手”,然而最痛苦的并不是“剁手”之后吃“灰”的日子,而是漫长而又揪心的等待快递小哥的日子。

为了缓解彼此的“痛苦”(快递公司的电话被打爆,用户等得不耐烦),快递公司后面就变“聪明”了,每当购物节将要来临之前,快递公司会预先准备好充足的人和车,以迎接扑面而来的订单。
至此,当我们再遇到各种购物节,就再也不用每天盯着手机煎熬的等待快递小哥了。
生活案例 2
小美是一家公司的 HR,每年年初是小美最头疼的日子了。因为年初有大量的员工离职,因此小美需要一边办理离职员工的手续,一边疯狂的招人,除了这些工作之外,小美还要忍受来自各部门和大 BOSS 的间歇性催促,这些都让小美痛苦不已。
于是为了应对每年年初的这种囧境,小美也变聪明了,她每年年末的时候都会预先招聘一些员工,以备来年的不时之需。
自从用了这招之后(提前招人),小美从此过上了幸福的生活。

池化技术指的是提前准备一些资源,在需要时可以重复使用这些预先准备的资源。
也就是说池化技术有两个优点:
提前创建; 重复利用。
池化技术优点分析
以 Java 中的对象创建来说,在对象创建时要经历以下步骤:
根据 new 标识符后面的参数,在常量池查找类的符号引用; 如果没找到符号应用(类并未加载),进行类的加载、解析、初始化等; 虚拟机为对象在堆中分配内存,并将分配的内存初始化为 0,针对对象头,建立相应的描述结构(耗时操作:需要查找堆中的空闲区域,修改内存分配状态等); 调用对象的初始化方法(耗时操作:用户的复杂的逻辑验证等操作,如IO、数值计算是否符合规定等)。
从上述的流程中可以看出,创建一个类需要经历复杂且耗时的操作,因此我们应该尽量复用已有的类,以确保程序的高效运行,当然如果能够提前创建这些类就再好不过了,而这些功能都可以用池化技术来实现。
池化技术常见应用
常见的池化技术的使用有:线程池、内存池、数据库连接池、HttpClient 连接池等,下面分别来看。
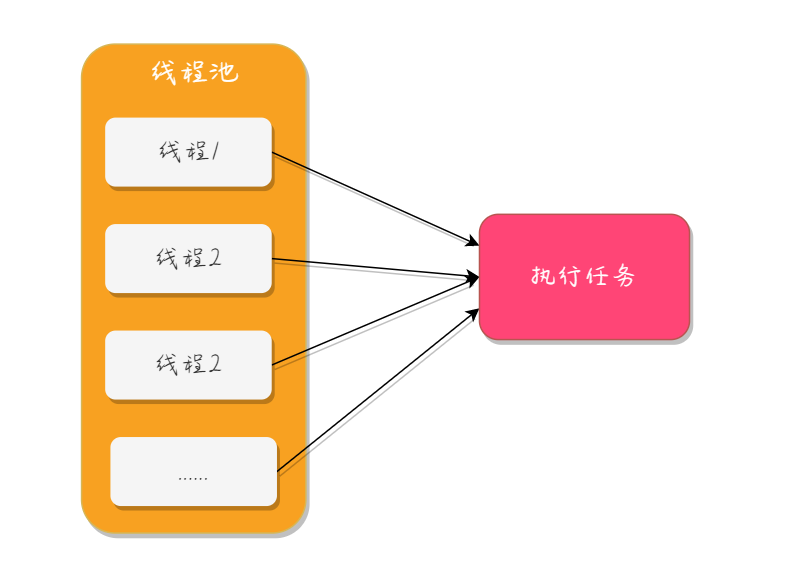
1.线程池
线程池的原理很简单,类似于操作系统中的缓冲区的概念。线程池中会先启动若干数量的线程,这些线程都处于睡眠状态。当客户端有一个新的请求时,就会唤醒线程池中的某一个睡眠的线程,让它来处理客户端的这个请求,当处理完这个请求之后,线程又处于睡眠的状态。
线程池能很高地提升程序的性能。比如有一个省级数据大集中的银行网络中心,高峰期每秒的客户端请求并发数超过100,如果为每个客户端请求创建一个新的线程的话,那耗费的 CPU 时间和内存都是十分惊人的,如果采用一个拥有 200 个线程的线程池,那将会节约大量的系统资源,使得更多的 CPU 时间和内存用来处理实际的商业应用,而不是频繁的线程创建和销毁。
2.内存池
如何更好地管理应用程序内存的使用,同时提高内存使用的频率,这时值得每一个开发人员深思的问题。内存池(Memory Pool)就提供了一个比较可行的解决方案。
内存池在创建的过程中,会预先分配足够大的内存,形成一个初步的内存池。然后每次用户请求内存的时候,就会返回内存池中的一块空闲的内存,并将这块内存的标志置为已使用。当内存使用完毕释放内存的时候,也不是真正地调用 free 或 delete 的过程,而是把内存放回内存池的过程,且放回的过程要把标志置为空闲。最后,应用程序结束就会将内存池销毁,将内存池中的每一块内存释放。
内存池的优点:
减少内存碎片的产生,这个优点可以从创建内存池的过程中看出,当我们在创建内存池的时候,分配的都是一块块比较规整的内存块,减少内存碎片的产生。 提高了内存的使用频率。这个可以从分配内存和释放内存的过程中看出。每次的分配和释放并不是去调用系统提供的函数或操作符去操作实际的内存,而是在复用内存池中的内存。
内存池的缺点:会造成内存的浪费,因为要使用内存池需要在一开始分配一大块闲置的内存,而这些内存不一定全部被用到。
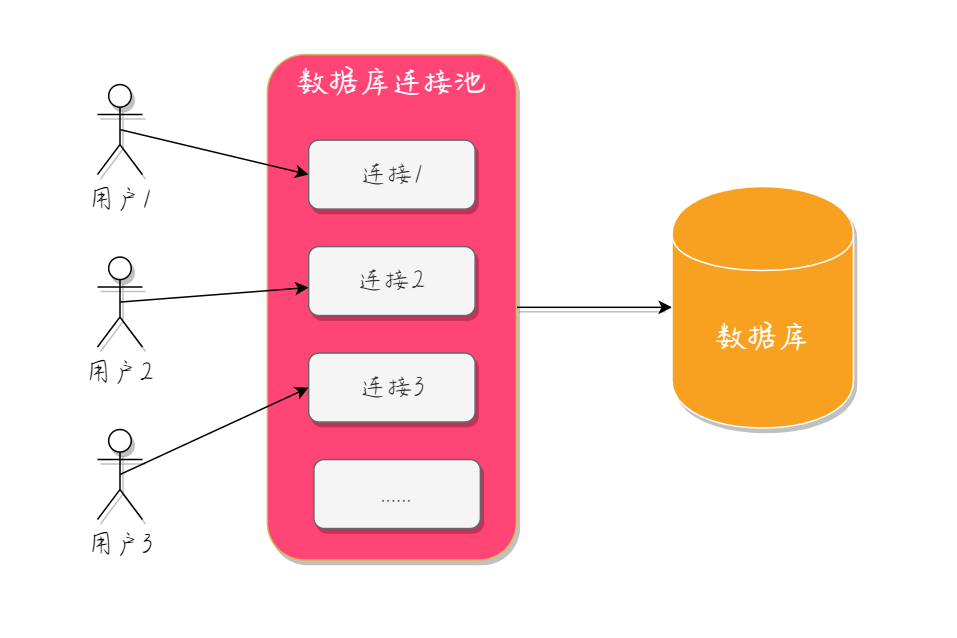
3.数据库连接池
数据库连接池的基本思想是在系统初始化的时候将数据库连接作为对象存储在内存中,当用户需要访问数据库的时候,并非建立一个新的连接,而是从连接池中取出一个已建立的空闲连接对象。在使用完毕后,用户也不是将连接关闭,而是将连接放回到连接池中,以供下一个请求访问使用,而这些连接的建立、断开都是由连接池自身来管理的。
同时,还可以设置连接池的参数来控制连接池中的初始连接数、连接的上下限数和每个连接的最大使用次数、最大空闲时间等。当然,也可以通过连接池自身的管理机制来监视连接的数量、使用情况等。
4.HttpClient 连接池
HttpClient 我们经常用来进行 HTTP 服务访问。我们的项目中会有一个获取任务执行状态的功能使用 HttpClient,一秒钟请求一次,经常会出现 Conection Reset 异常。经过分析发现,问题是出在 HttpClient 的每次请求都会新建一个连接,当创建连接的频率比关闭连接的频率大的时候,就会导致系统中产生大量处于 TIME_CLOSED 状态的连接,这个时候使用连接池复用连接就能解决这个问题。
实战:线程 VS 线程池
本文我们使用之前文章介绍的统计方法《6种快速统计代码执行时间的方法,真香!(史上最全)》,来测试一下线程和线程池执行的时间差距有多大,测试代码如下:
import java.util.concurrent.LinkedBlockingDeque;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
/**
* 线程池 vs 线程 性能对比
*/
public class ThreadPoolPerformance {
// 最大执行次数
public static final int maxCount = 1000;
public static void main(String[] args) throws InterruptedException {
// 线程测试代码
ThreadPerformanceTest();
// 线程池测试代码
ThreadPoolPerformanceTest();
}
/**
* 线程池性能测试
*/
private static void ThreadPoolPerformanceTest() throws InterruptedException {
// 开始时间
long stime = System.currentTimeMillis();
// 业务代码
ThreadPoolExecutor tp = new ThreadPoolExecutor(10, 10, 0,
TimeUnit.SECONDS, new LinkedBlockingDeque<>());
for (int i = 0; i < maxCount; i++) {
tp.execute(new PerformanceRunnable());
}
tp.shutdown();
tp.awaitTermination(1, TimeUnit.SECONDS); // 等待线程池执行完成
// 结束时间
long etime = System.currentTimeMillis();
// 计算执行时间
System.out.printf("线程池执行时长:%d 毫秒.", (etime - stime));
System.out.println();
}
/**
* 线程性能测试
*/
private static void ThreadPerformanceTest() {
// 开始时间
long stime = System.currentTimeMillis();
// 执行业务代码
for (int i = 0; i < maxCount; i++) {
Thread td = new Thread(new PerformanceRunnable());
td.start();
try {
td.join(); // 确保线程执行完成
} catch (InterruptedException e) {
e.printStackTrace();
}
}
// 结束时间
long etime = System.currentTimeMillis();
// 计算执行时间
System.out.printf("线程执行时长:%d 毫秒.", (etime - stime));
System.out.println();
}
// 业务执行类
static class PerformanceRunnable implements Runnable {
@Override
public void run() {
for (int i = 0; i < maxCount; i++) {
long num = i * i + i;
}
}
}
}
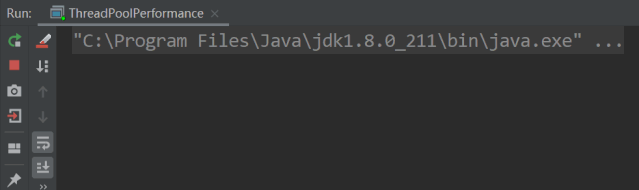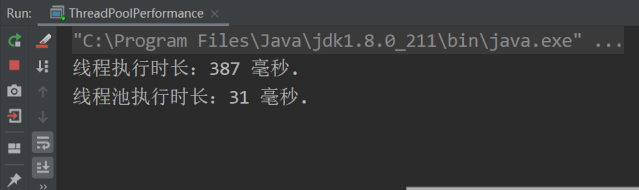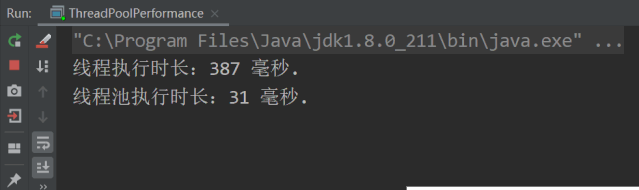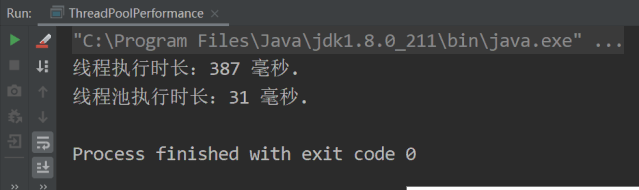
以上程序的执行结果如下图所示:
为了防止执行的先后顺序影响测试结果,下面我将线程池和线程调用方法打个颠倒,执行结果如下图所示:
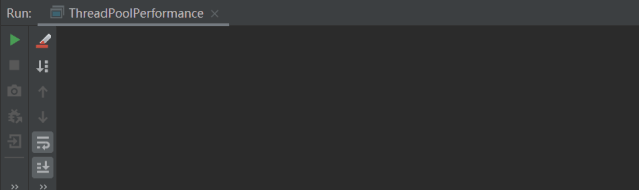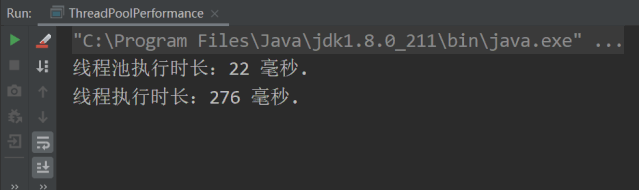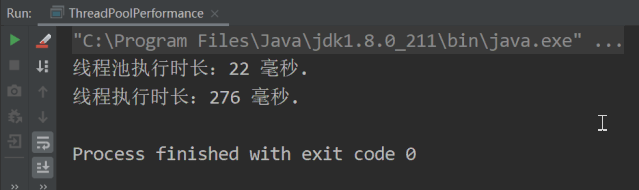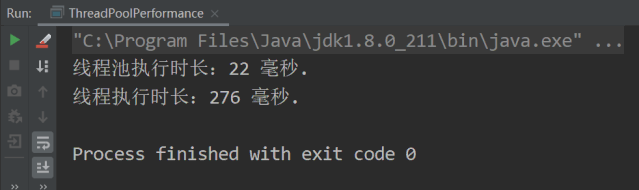
总结
从线程和线程池的测试结果来看,当我们使用池化技术时,程序的性能可以提升 10 倍。此测试结果并不代表池化技术的性能量化结果,因为测试结果受执行方法和循环次数的影响,但巨大的性能差异足以说明池化技术的优势所在。
无独有偶,阿里巴巴的《Java开发手册》中也强制规定「线程资源必须通过线程池提供,不允许在应用中自行显式创建线程」规定如下:

因此掌握并使用池化技术是一个合格程序员的标配,你还知道哪些常用的池化技术吗?欢迎评论区留言补充。
参考 & 引用
https://zhuanlan.zhihu.com/p/32204303
https://www.cnblogs.com/yanggb/p/10632317.html
最后的话
原创不易,都看到这了,点个「赞」再走呗,这是对我最大的支持与鼓励,谢谢你!
完

●从原型模式到浅拷贝和深拷贝 ●这 6 种统计代码执行时间的方法,你知道几个? ●为什么 Kafka 能这么快的 6 个原因 觉得不错,点个在看~
