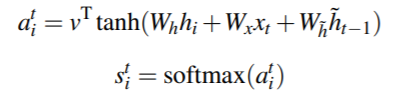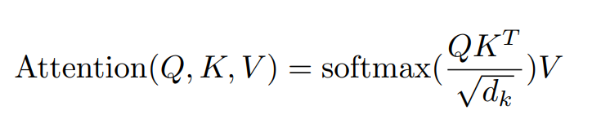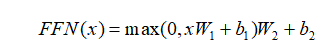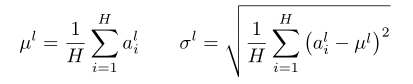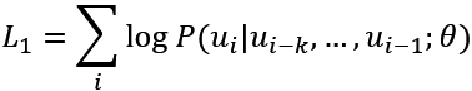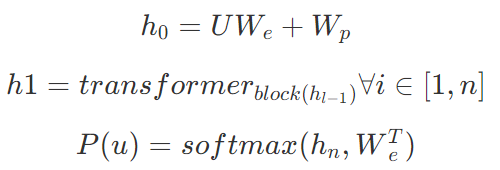作者丨马钘 马增来 谢明辉 邓雯敏 张煜蕊 周寅张皓 张哲宇本文详细介绍了Transformer结构(Encoder/Decoder)、Efficient Transformers、Language models以及Transformer预训练技术等。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
写在前面:自 2017 年 Transformer 技术出现以来,便在 NLP、CV、语音、生物、化学等领域引起了诸多进展。知源月旦团队期望通过“Transformer+X” 梳理清 Transformer 技术的发展脉络,以及其在各领域中的应用进展,以期推动 Transformer 技术在更多领域中的应用。限于篇幅,在这篇推文中,我们先介绍 Transformer 的基本知识,以及其在 NLP 领域的研究进展;后续我们将介绍 Transformer + CV / 语音/生物/化学等的研究。
Github:floatingCatty/BAAI-Monthly-Transformer模型由Google在2017年在 Attention Is All You Need[1] 中提出。该文使用 Attention 替换了原先Seq2Seq模型中的循环结构,给自然语言处理(NLP)领域带来极大震动。随着研究的推进,Transformer 等相关技术也逐渐由 NLP 流向其他领域,例如计算机视觉(CV)、语音、生物、化学等。因此,我们希望能通过此文盘点 Transformer 的基本架构,分析其优劣,并对近年来其在诸多领域的应用趋势进行梳理,希望这些工作能够给其他学科提供有益的借鉴。1.1 Transformer 结构
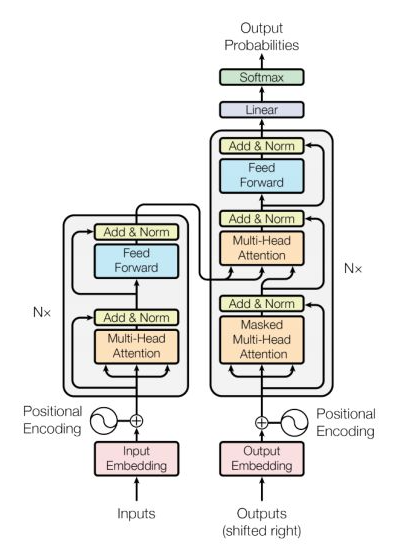
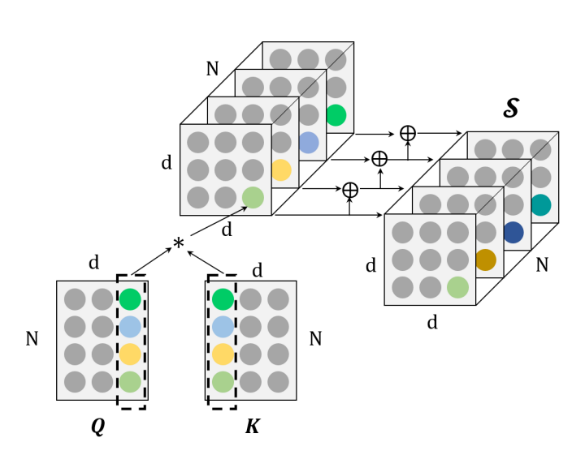
Transformer 模型结构如图1所示,模型由6个编码器(Encoder)和6个解码器(Decoder) 组成,输入(Inputs)和输出(Outputs)通过同一个训练好的词嵌入层(Word Embedding)将输入字符转换为维度为d的向量。Transformer对编码器(Encoder)与解码器(Decoder)两端的序列分别添加位置编码(Positional Encoding)。之后,编码经过含有多头自注意力机制(Multi-head Self-Attention)、位置前向传播网络(Position-wise Feed-Forward Network)、残差连接(Residual Connection)和层归一化(Layer Normalization)的计算单元。由于Transformer的计算抛弃了循环结构的递归和卷积,无法模拟文本中的词语位置信息,因而需要人为添加。该过程称为位置编码(Positional Encoding),使用词的位置向量,表示单词在句中的位置与词间的相对位置,在Transformer中与句子的嵌入表示相加,获得模型输入。Vaswani et.al[1]提出 Positonal Encoding的两种方式:一种是学习得到,随机初始化后加入模型作为参数进行训练。一种是使用不同频率的正弦和余弦函数,在每个词语的词向量的偶数位置添加sin变量,奇数位置添加cos变量,以此填满Positional Encoding矩阵,该方式保证了每个位置向量不重复而且不同之间的位置之间存在线性关系,在计算注意力权重的时候(两个向量做点积),相对位置的变化会对注意力产生影响,而绝对位置变化不会对注意力产生影响,这更符合常理。上述方式都是将单词嵌入向量与位置嵌入向量分开训练,且只能接受整型数值作为词索引或位置索引,不能捕捉有序的关系,例如邻接关系或优先级,会导致每个位置上的位置向量是彼此独立的,称之为 Position Independence Problem[2]。针对这个问题,Benyou et.al 提出了一种改进方法——将以前定义为独立向量的词嵌入扩展为以位置 pos 为自变量的连续函数。这样词的表示可以随着位置的变化而平滑地移动,不同位置上的词表示就可以互相关联起来。实验结果表示,Complex Embedding 在性能上有较大的优化和提高。注意力机制(Attention Mechanism)作为对Seq2Seq模型的改进而被提出。在机器翻译任务中,目标语言与输入语言的词汇之间,存在一些对应关系,Bahdanau[3] 鲜明地指出了固定大小的中间层维度对翻译任务的限制,并直接计算 BiRNN 对输入的编码h与候选输出的编码的s之间的相似度量作为替代,根据相似得分输出预测的目标语言词汇。这突破了 Seq2Seq 模型学习的中间表征h的维度对输入信息的限制。日后发展出的大多 Attention 机制仍可以表述在这一框架下,即计算输入的表示与输出表示间的得分 score,作为判断输出单词的依据,但不同的是,对于输入词的编码采用了不同的处理模型,例如RNN,CNN[4]等。在 Transformer 以及后续的主流模型中,多采用多头自注意力机制(Scale-dot Product Self-Attention)。自注意力在 Cheng et. al.[5] 的机器阅读工作中提出,该模型采用加和式的 Attention 得分,计算输入新词与前文各词的联系,使用加和式注意力计算:Transformer 中采用的是多头自注意力机制[1]。在 Encoder 中,Q、K、V均为输入的序列编码,而多头的线性层可以方便地扩展模型参数。该方法经常被表示为词与词之间的全连接结构[6],同一序列中词的关系直接由 score 值计算得到,不会因为时序、传播的限制而造成信息损失,有利于模拟长程依赖,但也有工作通过实验表明[7],多头注意力机制解决长程依赖是由于参数量的增加,若在同规模下对比,相对CNN,RNN并未有明显提升。自注意力长程依赖、可扩展、多连接等特点让其在语言任务上表现出色。许多工作针对计算开销问题提出了改进。Kitaev et. al[8] 的 Reformer,并在计算时,使用相同的线性层参数计算Q、K矩阵,并对每个 Query 单独计算 Attention 得分,这样虽然增加了循环次数,但却能将存储开销变为原来的平方根级。此外,考虑到 Softmax 函数更多关注序列中较大的值,因此筛选了部分相似的 Token 计算相关性值,这与 Rewon Child[9] 提出了 Sparse Attention 优化计算的方法相似。Zhang et. al.[10] 在 TensorCoder 中提出了维度的 Scale-dot Product Attention,将计算开销从O(N^2d),降低到O(Nd^2),对于序列长度大于词向量维度时,能有效降低开销。3)Position-Wise Feed-Forward Network
Position-Wise Feed-Forward Network 是一个简单的全连接前馈网络:其中 x 是 MultiHead(Q,K,V) 中的一个token。Position-Wise 即以单个位置为单位进行前馈,也就是说 FFN(x) 中的 x 的维度为 [1,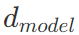 ],同一个 Encoder 或者 Decoder 中的不同x共享
],同一个 Encoder 或者 Decoder 中的不同x共享  ,
,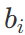 ,不同 Encoder 和 Decoder 之间不共享参数。在模型学习过程中,当我们采用梯度下降法对最优参数进行搜索时,很大程度上会受到输入特征分布的影响。当输入的不同特征的特征空间的范围差异较大,会导致在空间上寻找最优点时,产生较大偏差。为了解决这种情况,将不同的特征分布通过归一化使其成为均值为0,标准差为1的概率分布,可以帮助模型以更快的速度收敛。1.4.2 Batch Normalization出现在深度神经网络反向传播的特性在更新神经元参数的同时,也存在着内部协变量偏移效应(Internal Covariate Shift),经过多层的偏移效应放大后,很多变量会趋向于分布到激活函数(以 Sigmoid 为例)的两端,发生梯度急剧下降甚至产生梯度消失现象。有学者提出通过采用将每层输入归一化的方式防止这种现象的发生。同时还增加了可训练变量β与γ。使得归一化后的输入α,通过线性变换
,不同 Encoder 和 Decoder 之间不共享参数。在模型学习过程中,当我们采用梯度下降法对最优参数进行搜索时,很大程度上会受到输入特征分布的影响。当输入的不同特征的特征空间的范围差异较大,会导致在空间上寻找最优点时,产生较大偏差。为了解决这种情况,将不同的特征分布通过归一化使其成为均值为0,标准差为1的概率分布,可以帮助模型以更快的速度收敛。1.4.2 Batch Normalization出现在深度神经网络反向传播的特性在更新神经元参数的同时,也存在着内部协变量偏移效应(Internal Covariate Shift),经过多层的偏移效应放大后,很多变量会趋向于分布到激活函数(以 Sigmoid 为例)的两端,发生梯度急剧下降甚至产生梯度消失现象。有学者提出通过采用将每层输入归一化的方式防止这种现象的发生。同时还增加了可训练变量β与γ。使得归一化后的输入α,通过线性变换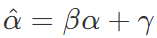 ,转换成
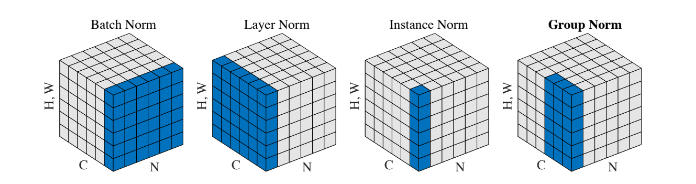
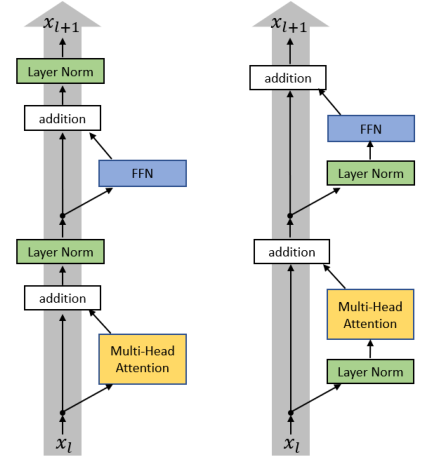
,转换成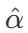 ,这样进入激活函数的输入将不受内部协变量影响,加快了模型训练的收敛速度[11]。1.4.3 Layer Normalization出现一些学者发现 Batch Normalization 在RNN上所起到的作用是很有限的。当他们对 RNN 应用 Batch Normalization 时,需要计算序列中每个时间步的统计信息[12]。这存在很多问题。当时间步超出训练序列长度后,没有归一化层可以与多出的测试序列对应了。而且 Batch Normalization 对 Batch Size 依赖很大,当Batch Size 过小时,BN 层的均值和标准差计算与整个数据集的实际统计数据相差过大,就使得其丧失了归一化效果。所以,可以采取另一种改进的归一化方法即 Layer Normalization,即通过对在相同时间步的神经元的输入求其均值与标准差,在这个方向上对输入进行归一化,可以理解为 BN 的转置。LN 在实现归一化过程中与 Batch 是无关联的,这就克服了 BN 在小 Batch Size 的情况下,效果较差的缺点[12]。H代表同一序列的隐藏神经元数,归一化过程无关于 Batch Size。对于 Transformer 而言,模型深度更大,搜索范围更广,因而采用 Layer Normaliazation层对模型起到的帮助是基础性的。这使得 Transformer 在训练过程中收到内部协变量的影响降到很低,也是 Transformer 的高性能的重要原因之一。对于 Transformer 的 LN 层还存在一些讨论。有学者说明原始模型输出层参数期望较大,在这些梯度上采用较大的学习率,会使训练不稳定,将 LN 层前置到子层前[13],见下图右,发现通过这样的方式,也可以提升 Transformer 模型本身的训练性能。Transformer 解码器(Decoder)与编码器(Encoder)具有相同的计算单元,不同的是,模型仍是 Seq2Seq 结构,因此,为了令解码器不提前得知未来信息,使用 Masked Multi-head Attention 隐藏下文。Transformer 在获得性能提升的同时,也大大增加了计算开销,因此,许多工作关注获得更高效的 Transformer 模型,列举介绍如下。
,这样进入激活函数的输入将不受内部协变量影响,加快了模型训练的收敛速度[11]。1.4.3 Layer Normalization出现一些学者发现 Batch Normalization 在RNN上所起到的作用是很有限的。当他们对 RNN 应用 Batch Normalization 时,需要计算序列中每个时间步的统计信息[12]。这存在很多问题。当时间步超出训练序列长度后,没有归一化层可以与多出的测试序列对应了。而且 Batch Normalization 对 Batch Size 依赖很大,当Batch Size 过小时,BN 层的均值和标准差计算与整个数据集的实际统计数据相差过大,就使得其丧失了归一化效果。所以,可以采取另一种改进的归一化方法即 Layer Normalization,即通过对在相同时间步的神经元的输入求其均值与标准差,在这个方向上对输入进行归一化,可以理解为 BN 的转置。LN 在实现归一化过程中与 Batch 是无关联的,这就克服了 BN 在小 Batch Size 的情况下,效果较差的缺点[12]。H代表同一序列的隐藏神经元数,归一化过程无关于 Batch Size。对于 Transformer 而言,模型深度更大,搜索范围更广,因而采用 Layer Normaliazation层对模型起到的帮助是基础性的。这使得 Transformer 在训练过程中收到内部协变量的影响降到很低,也是 Transformer 的高性能的重要原因之一。对于 Transformer 的 LN 层还存在一些讨论。有学者说明原始模型输出层参数期望较大,在这些梯度上采用较大的学习率,会使训练不稳定,将 LN 层前置到子层前[13],见下图右,发现通过这样的方式,也可以提升 Transformer 模型本身的训练性能。Transformer 解码器(Decoder)与编码器(Encoder)具有相同的计算单元,不同的是,模型仍是 Seq2Seq 结构,因此,为了令解码器不提前得知未来信息,使用 Masked Multi-head Attention 隐藏下文。Transformer 在获得性能提升的同时,也大大增加了计算开销,因此,许多工作关注获得更高效的 Transformer 模型,列举介绍如下。1.2 Efficient Transformers
Taxonomy of Efficient Transformer Architectures.Transformer 发布后即在 NLP 多个领域取得显著成绩,也激发了领域研究者们极大的兴趣。后续研究者们在 Transformer 的基础上又提出了一系列 X-former模型,如 Set-Transformer[14]、Transformer-XL[15] 等。这些模型针对Transformer 的计算效率和存储效率进行优化,或是提升了模型处理长序列的效率。谷歌2020年9月份在arXiv发表的综述论文《Efficient Transformers: A Survey》[16]即针对这一类进行了总结。1.3 Language models
Transformer 的出现催生出一批基于 Transformer 的语言模型,这些模型被证实在一系列NLP任务上取得极大性能提升。如2018年 OpenAI 提出的 GPT(Generative Pre-Training)[17] 模型和 Google Brain 提出的 BERT(Bidirectional Encoder Representation from Transformer) 模型[18],一经提出即引起极大反响,二者分别基于单向、双向Transformer 模型,运用了 Pre-training + Fine-tuning 的训练模式,在分类、标注等 NLP 经典下游任务取得很好的效果。值得注意的是,GPT 和 BERT 两个模型都是在 Fine-tuning 阶段在编码层后面加上 Task-layer 以适应不同下游任务的训练需求,而另一个基于双向 Transformer 的模型 MT-DNN[19] 是将所有任务的 Fine-tuning 步骤都放了一起。MT-DNN 的优势表现在使用多任务学习+预训练,使得在单一任务数据有限的有监督训练中,可以利用其他相似任务的标注数据,以达到数据增强的作用。2.1 预训练技术
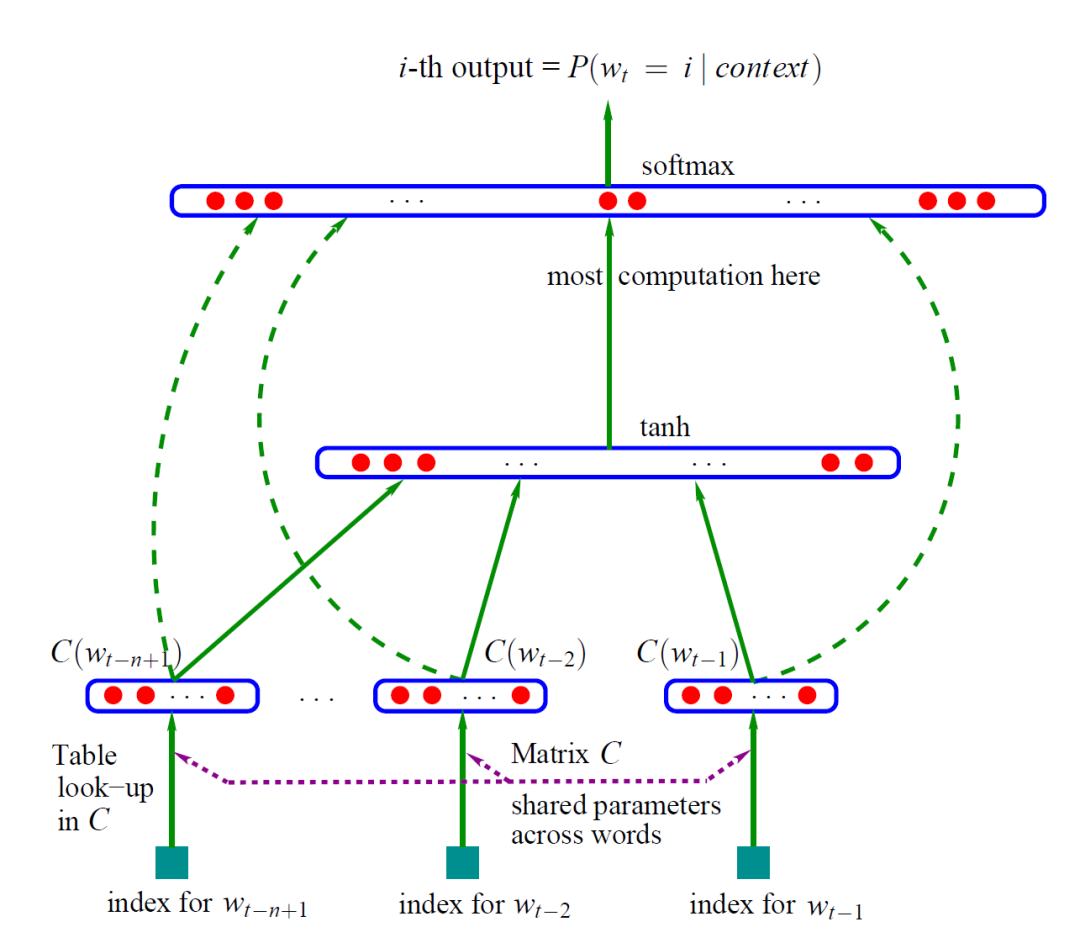
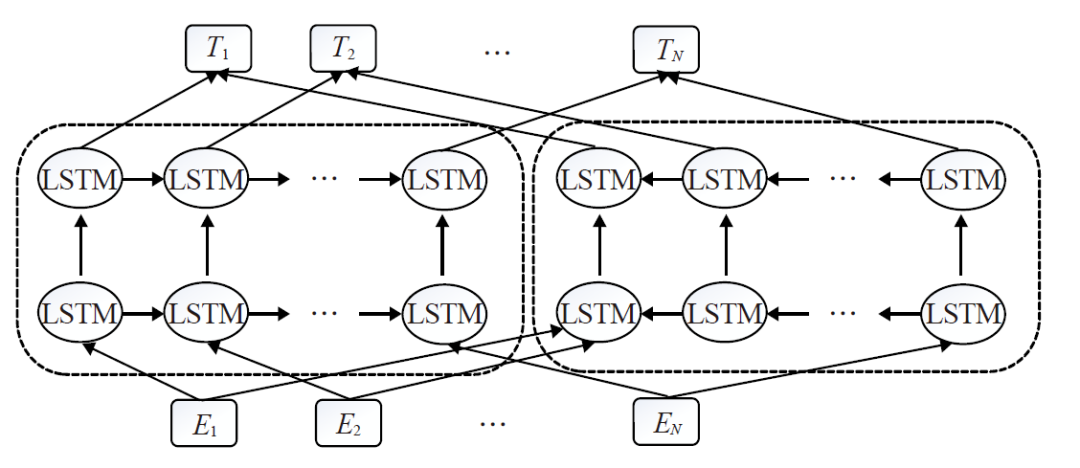
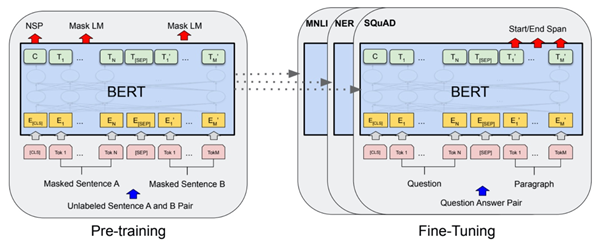
预训练技术是指预先设计多层网络结构,将编码后的数据输入到网络结构中进行训练,增加模型的泛化能力。预先设计的网络结构通常被称为预训练模型,它的作用是初始化下游任务。将预训练好的模型参数应用到后续的其他特定任务上,这些特定任务通常被称为“下游任务”[20]。随着深度学习的发展,模型参数迅速增加。另外,模型在小数据集上容易过拟合,需要更大的数据集。而 NLP 中构建带标签的大数据集成本高昂。相较而言,无标签大数据集构造简单。为了利用无标签数据,可以预训练得到其他任务的通用表示。然后将这些通用表示应用到下游任务的构建过程中。大量实验表明,使用预训练方式可以较大改善某些任务的性能[21]。早在2006年,深度学习的突破就出现在贪婪的分层无监督预训练,然后是有监督的微调。在 CV 领域, 主要是在如 ImageNet 等较大规模数据集上预训练模型,接着在不同任务的数据上进行微调,方法取得了明显的效果改善。而在 NLP 中早期的预训练模型围绕预训练词向量进行,现代词向量最早是由 Yoshua Bengio et. al.[22] 在2003年的 NNLM 模型中提出。C是词向量矩阵,负责将词映射为特征向量。模型通过训练之后可以得到词向量矩阵C。NNLM 的主要贡献是创见性地将模型的第一层特征映射矩阵当作词的文本表征,从而开创了将词语表示为向量形式的模式,这直接启发了后来的 Word2Vec 的工作。在2011年,Collobert et. al.[23] 发现在无标签数据预训练的词向量能够显著改善很多NLP任务。2013年,Mikolov et. al.[24] 借鉴NNLM的思想提出了 Predictive-based Word2Vec 模型,分为两种训练方式,包含根据上下文预测中间词的Continuous Bag-of-Words(CBOW) 和根据中间词预测上下文的 Skip-Gram (SG) 。2014年,Jeffrey Pennington et. al.[25] 提出了 Count-based Glove。Word2vec 和 Glove 都是之前广泛用来预训练词向量的模型。Word2Vec 和GloVe 都是使用无监督数据训练得到词向量,而 FastText [26] 则是利用带有监督标记的文本分类数据完成训练。FastText 的网络结构与CBOW基本一致,其最大优势在于预测速度。在一些分类数据集上,FastText 通常可以把要耗时几小时甚至几天的模型训练大幅压缩到几秒钟。由于传统词向量的缺点,大家尝试使用深层模型提取出上下文相关的词向量。McCann et. al.[27]在 MT 数据集上使用 Attention-Seq2Seq 模型预训练深层 LSTM 的 Encoder,该 Encoder 输出的 Context Vectors (CoVe) 对改善了很多NLP任务的效果。后面提出了BiLM [28] 等模型。这些模型都属于 ELMo (Embeddings from Language Models)。但是这些模型仍然一般只作为特征提取器提取出上下文相关的词向量。除了这部分工作可以继承外,下游任务的其他参数仍需要从头训练。BiLSTM 包括前向 LSTM 模型和后向 LSTM 模型。两个方向的 LSTM 共享部分权重。模型的目标是最大化前向和后向的似然概率和。利用 Fine-tune 将 PTM 应用到下游任务,只需在新的小数据集上进行参数微调即可,无需重新训练。2017年,Ramachandran et. al.[29]发现无监督预训练可以大幅提高 Seq2Seq的效果。Seq2Seq 的 encoder 和 decoder 分别使用两个语言模型的参数进行初始化,然后使用标记数据进行微调。2018年,Jeremy Howard et. al.[30] 提出ULMFiT (Universal Language Model Finetuning),并且探索了一些有效的 Fine-tune 技巧,如 Slanted Triangular Learning Rates。自从 ULMFiT 之后,Fine-tuning 成为将PTM应用到下游任务的主流。2017年,谷歌提出Transformer模型,它在处理长期依赖性方面比LSTM有更好的表现,一些业内人士开始认为它是LSTM的替代品。在此背景下,GPT预训练模型应运而生。GPT采用了Transformer中的解码器结构,并没有使用一个完整的Transformer来构建网络。GPT模型堆叠了12个Transformer子层,并用语言建模的目标函数来进行优化和训练。GPT模型虽然达到了很好的效果,但本质上仍是一种单向语言模型,对语义信息的建模能力有限。BERT 模型堆叠 Transformer 的编码器结构,并且通过 Masked-LM 的预训练方式达到了真双向语言模型的效果。上面的介绍包含了两种常见的迁移学习方式:特征提取和微调,两者的区别是 ELMo 等为代表的模型使用的特征提取方法冻结了预训练参数,而以 BERT 等为代表的模型采用的微调则是动态地改变参数,根据下游任务进行参数上的微调。特征提取需要更复杂的任务架构,并且就综合性能来看,微调的方法更适合下游任务。2.2 方法介绍
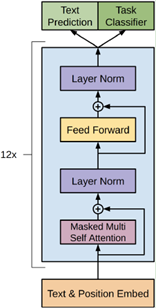
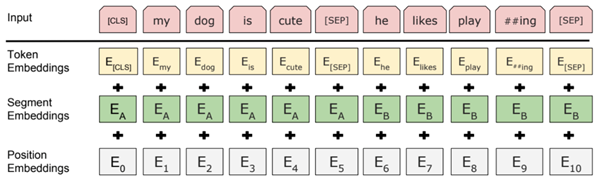
继17年谷歌大脑提出一个包含编码器和解码器的 Transformer 结构后,Transformer 在近三年间又有了许多不同的改进演化版本,对 Vanilla Transformer 的各种变体的技术线梳理可以按照时间来划分:早期达到多个 SOTA 的结构优化模型是 GPT、BERT,这两种模型都沿用了原始Transformer 的结构:GPT 把原始 Transformer 结构中的解码器结构用作编码器进行特征抽取,由于解码器中的 Mask 设计,使得 GPT 只使用了单向信息,即该语言模型只使用了上文预测当前词,而不使用下文,这也使得其更适用于文本生成类任务;而 BERT 只使用了原始 Transformer 结构中的编码器结构,因此其使用了双向的信息,并在一些任务中达到了更好的效果。基于 Transformer 的预训练+微调技术为 NLP 领域注入了新的活力,而这一工作的开创者,便是 OpenAI 的研究人员于2018年提出的 GPT[17]。论文中提出,我们可将训练过程分为两个阶段:第一阶段以标准语言模型作为目标任务,在大规模语料库上做无监督的预训练;第二阶段在特定的下游任务上对模型参数做有监督的微调,使其能够更好的适应特定目标任务。基于上述过程,GPT 使用多层 Transformer Decoder 作为语言模型,其基本结构如下:在第一阶段,使用标准 LM 作为预训练任务,即最大化如下似然函数:其中,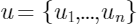 为语料中 Tokens 的集合,k 为上下文窗口的大小。该模型的训练过程其实就是将输入文本中每个词的 Embedding 作为输入,输出预测的下一个词,具体步骤如下:其中
为语料中 Tokens 的集合,k 为上下文窗口的大小。该模型的训练过程其实就是将输入文本中每个词的 Embedding 作为输入,输出预测的下一个词,具体步骤如下:其中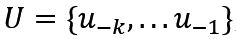 是文本中每个词的词向量,n为层数,
是文本中每个词的词向量,n为层数,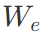 表示词嵌入矩阵,
表示词嵌入矩阵,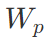 表示位置嵌入矩阵。第二阶段,即在特定任务上使用少量带标签的数据对模型参数进行有监督的微调,具体步骤如下:
表示位置嵌入矩阵。第二阶段,即在特定任务上使用少量带标签的数据对模型参数进行有监督的微调,具体步骤如下: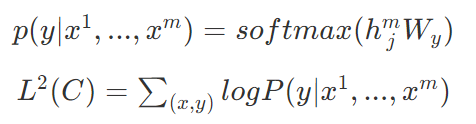
其中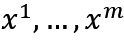 为特定下游任务的输入,y为标签,
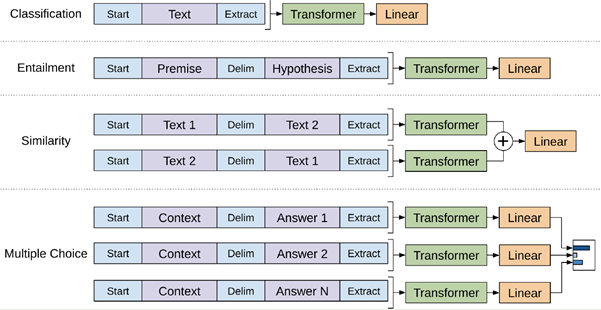
为特定下游任务的输入,y为标签,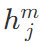 为预训练阶段最后一个词的输出 。原文中还提到了用辅助训练目标的方法来帮助模型在微调时拥有更好的泛化能力并加速收敛,具体做法是:在使用最后一个词的预测结果进行监督学习的同时,前面的词继续上一步的无监督训练。综上,要优化的目标函数如下:简单总结为:对于分类问题,不需要做修改;对于推理类的问题,可在前提和假设中间插入一个分隔符作为分隔;对于相似度问题,可将两个句子顺序颠倒,然后将两次输入相加来做推测;对于问答类问题,可将上下文和问题放在一起,用分隔符隔开与答案。为了解决 GPT 采用单向语言模型所带来的问题,Google Brain 在2018年提出了基于双向 Transformer 的大规模预训练语言模型 BERT[18],刷新了11项 NLP 任务的 SOTA,具有里程碑意义。在预训练阶段,BERT 提出了 Masked Language Model(MLM)与 Next Sentence Prediction(NSP) 的预训练方法,MLM 任务令模型预测文本中随机覆盖的缺失词,类似完形填空。同时,为避免覆盖所用高频标签 [MASK] 带来的误差,将其中部分标签换为随机词。NSP 任务则是利用 [CLS] 与 [SEP] 标签分隔上下句关系,以满足基于句子级别的下游任务的需要(如 QA、NLI 等)。在微调阶段,BERT 和 GPT 并没有多少本质上的区别,论文中给出了几种不同任务的微调方案,如下图:BERT 虽然有着非常好的表现,但它依然存在以下问题:1.预训练和微调阶段的不一致性(Discrepancy):预训练 BERT 时,会随机 Mask 掉一些单词,但在微调阶段,却并没有诸如 [MASK] 之类的标签,从而导致两个过程的不一致;2.与标准的语言模型相比,BERT 并不具备很好的生成能力。XLNet[31] 是 BERT 之后比较引人注目的一个模型,提出了 Permutation Language Model 的新目标,即利用重排列的方式使得在单向的自回归 LM 中也能看到下文信息,这样结合了自回归 LM 擅长生成和自编码 LM 能够捕获双向信息的优点。但是,XLNet 的后续评价并没有高于 BERT,基于 XLNet 的后续研究也比较少,可能原因为 XLNet 使用的训练数据的质量要优于 BERT,这使得两者的对比并不公平。或者 BERT 根本没有得到充分的训练,因此没有发挥出其真正实力。基于这种观点,Facebook 的研究人员提出了 RoBERTa[32]。RoBERTa 的主要工作是通过改进训练任务和数据生成方式、使用更多数据、更大批次、训练更久等方式对 BERT 进行改进,换言之,RoBERTa 本质上算是一个调参调到最优的 BERT,其实际表现和 XLNet 不相上下。但无论是 XLNet 还是 RoBERTa 亦或是其它 BERT 变体,它们大多通过使用更多的数据、更复杂的模型等方式来提升训练效果,这极大加剧了内存开销。为了缓解这个问题,Google 提出了 ALBERT[33],希望用更少的参数、更低的内存开销来达到甚至提升 BERT 效果。论文中指出,增加参数量有时并不会提高模型性能,相反这可能会降低模型的效果,作者将该现象称为“模型退化”。基于此,ALBERT 提出了三种优化策略:1.分解词嵌入矩阵;2.跨层参数共享;3.将 NSP 任务换成更复杂的 SOP 任务,以补偿前两步性能上的损失。以上介绍了部分 Transformer 结构的主要应用模型与变体,概括了不同的模型优化方法,总的来说,按照模型提高效率的方法可以分为以下七类[16] :
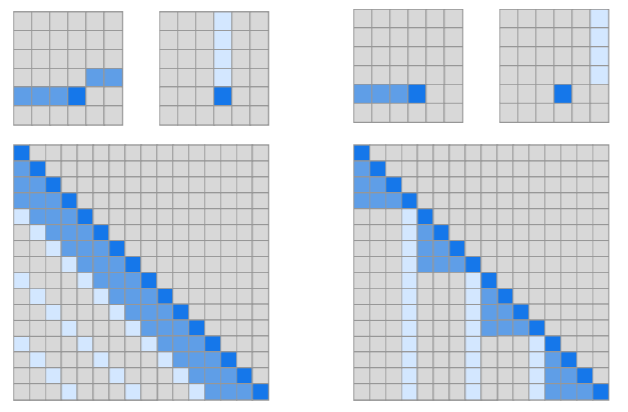
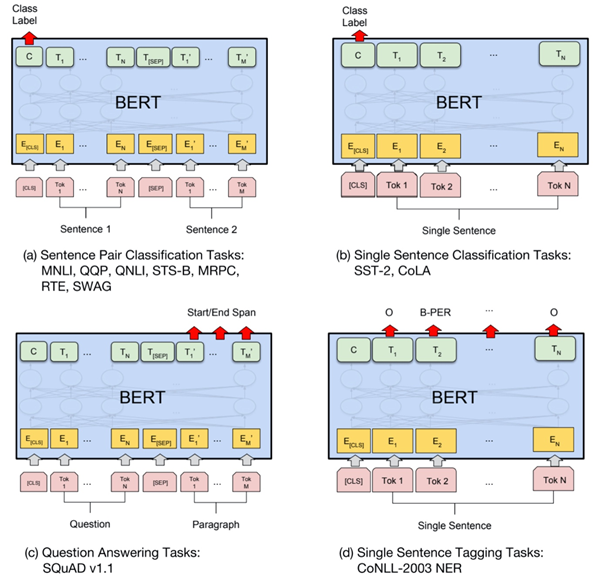
为预训练阶段最后一个词的输出 。原文中还提到了用辅助训练目标的方法来帮助模型在微调时拥有更好的泛化能力并加速收敛,具体做法是:在使用最后一个词的预测结果进行监督学习的同时,前面的词继续上一步的无监督训练。综上,要优化的目标函数如下:简单总结为:对于分类问题,不需要做修改;对于推理类的问题,可在前提和假设中间插入一个分隔符作为分隔;对于相似度问题,可将两个句子顺序颠倒,然后将两次输入相加来做推测;对于问答类问题,可将上下文和问题放在一起,用分隔符隔开与答案。为了解决 GPT 采用单向语言模型所带来的问题,Google Brain 在2018年提出了基于双向 Transformer 的大规模预训练语言模型 BERT[18],刷新了11项 NLP 任务的 SOTA,具有里程碑意义。在预训练阶段,BERT 提出了 Masked Language Model(MLM)与 Next Sentence Prediction(NSP) 的预训练方法,MLM 任务令模型预测文本中随机覆盖的缺失词,类似完形填空。同时,为避免覆盖所用高频标签 [MASK] 带来的误差,将其中部分标签换为随机词。NSP 任务则是利用 [CLS] 与 [SEP] 标签分隔上下句关系,以满足基于句子级别的下游任务的需要(如 QA、NLI 等)。在微调阶段,BERT 和 GPT 并没有多少本质上的区别,论文中给出了几种不同任务的微调方案,如下图:BERT 虽然有着非常好的表现,但它依然存在以下问题:1.预训练和微调阶段的不一致性(Discrepancy):预训练 BERT 时,会随机 Mask 掉一些单词,但在微调阶段,却并没有诸如 [MASK] 之类的标签,从而导致两个过程的不一致;2.与标准的语言模型相比,BERT 并不具备很好的生成能力。XLNet[31] 是 BERT 之后比较引人注目的一个模型,提出了 Permutation Language Model 的新目标,即利用重排列的方式使得在单向的自回归 LM 中也能看到下文信息,这样结合了自回归 LM 擅长生成和自编码 LM 能够捕获双向信息的优点。但是,XLNet 的后续评价并没有高于 BERT,基于 XLNet 的后续研究也比较少,可能原因为 XLNet 使用的训练数据的质量要优于 BERT,这使得两者的对比并不公平。或者 BERT 根本没有得到充分的训练,因此没有发挥出其真正实力。基于这种观点,Facebook 的研究人员提出了 RoBERTa[32]。RoBERTa 的主要工作是通过改进训练任务和数据生成方式、使用更多数据、更大批次、训练更久等方式对 BERT 进行改进,换言之,RoBERTa 本质上算是一个调参调到最优的 BERT,其实际表现和 XLNet 不相上下。但无论是 XLNet 还是 RoBERTa 亦或是其它 BERT 变体,它们大多通过使用更多的数据、更复杂的模型等方式来提升训练效果,这极大加剧了内存开销。为了缓解这个问题,Google 提出了 ALBERT[33],希望用更少的参数、更低的内存开销来达到甚至提升 BERT 效果。论文中指出,增加参数量有时并不会提高模型性能,相反这可能会降低模型的效果,作者将该现象称为“模型退化”。基于此,ALBERT 提出了三种优化策略:1.分解词嵌入矩阵;2.跨层参数共享;3.将 NSP 任务换成更复杂的 SOP 任务,以补偿前两步性能上的损失。以上介绍了部分 Transformer 结构的主要应用模型与变体,概括了不同的模型优化方法,总的来说,按照模型提高效率的方法可以分为以下七类[16] :Fixed Patterns(固定模式):将视野限定为固定的预定义模式,例如局部窗口、固定步幅块,用于简化注意力矩阵;
Combination of Patterns(组合模式):通过组合两个或多个不同的模式来提高效率;
Learnable Patterns(可学习模式):以数据驱动的方式学习访问模式,关键在于确定 Token 相关性。
Memory(内存):利用可以一次访问多个 Token 的内存模块,例如全局存储器。
Low Rank(低秩):通过利用自注意力矩阵的低秩近似,来提高效率。
Kernels(内核):通过内核化的方式提高效率,其中核是注意力矩阵的近似,可视为低秩方法的一种。
Recurrence(递归):利用递归,连接矩阵分块法中的各个块,最终提高效率。
[1]Vaswani, Ashish, et al. "Attention is all you need." Advances in neural information processing systems 30 (2017): 5998-6008.[2]Wang, Benyou, et al. "Encoding word order in complex embeddings." arXiv preprint arXiv:1912.12333 (2019).[3]Bahdanau, Dzmitry, Kyunghyun Cho, and Yoshua Bengio. "Neural machine translation by jointly learning to align and translate." arXiv preprint arXiv:1409.0473 (2014).[4]Gehring, Jonas, et al. "Convolutional sequence to sequence learning." arXiv preprint arXiv:1705.03122 (2017).[5]Cheng, Jianpeng, Li Dong, and Mirella Lapata. "Long short-term memory-networks for machine reading." arXiv preprint arXiv:1601.06733 (2016).[6]Guo, Qipeng, et al. "Star-transformer." arXiv preprint arXiv:1902.09113 (2019).[7]Tang, Gongbo, et al. "Why self-attention? a targeted evaluation of neural machine translation architectures." arXiv preprint arXiv:1808.08946 (2018).[8]Kitaev, Nikita, Łukasz Kaiser, and Anselm Levskaya. "Reformer: The efficient transformer." arXiv preprint arXiv:2001.04451 (2020).[9]Child, Rewon, et al. "Generating long sequences with sparse transformers." arXiv preprint arXiv:1904.10509 (2019).[10]Zhang, Shuai, et al. "TensorCoder: Dimension-Wise Attention via Tensor Representation for Natural Language Modeling." arXiv preprint arXiv:2008.01547 (2020).[11]Ioffe, Sergey , and C. Szegedy . "Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift." (2015).[12]Ba, Jimmy Lei , J. R. Kiros , and G. E. Hinton . "Layer Normalization." (2016).[13]Xiong, Ruibin , et al. "On Layer Normalization in the Transformer Architecture." (2020).[14]Lee, Juho, et al. "Set transformer: A framework for attention-based permutation-invariant neural networks." International Conference on Machine Learning. PMLR, 2019.[15]Dai, Zihang, et al. "Transformer-xl: Attentive language models beyond a fixed-length context." arXiv preprint arXiv:1901.02860 (2019).[16]Tay, Yi, et al. "Efficient transformers: A survey." arXiv preprint arXiv:2009.06732 (2020).[17]Radford, Alec, et al. "Improving language understanding by generative pre-training." (2018): 12.[18]Devlin, Jacob, et al. "Bert: Pre-training of deep bidirectional transformers for language understanding." arXiv preprint arXiv:1810.04805 (2018).[19]Liu, Xiaodong, et al. "Multi-task deep neural networks for natural language understanding." arXiv preprint arXiv:1901.11504 (2019).[20]余同瑞,金冉,韩晓臻,李家辉,郁婷.Tongrui Yu,ra自然语言处理预训练模型的研究综述,2020[21]Xipeng Qiu,Tianxiang Sun,Yige Xu,etc.Pre-trained Models for Natural Language Processing: A Survey,2020[22]Yoshua Bengio, et al. "A neural probabilistic language model." Journal of machine learning research, 3(Feb):1137–1155, 2003.[23]Ronan Collobert, JasonWeston, L´eon Bottou, Michael Karlen,Koray Kavukcuoglu, and Pavel P. Kuksa. Natural language processing (almost) from scratch. J. Mach. Learn. Res., 2011.[24]Tomas Mikolov, Ilya Sutskever, Kai Chen, Gregory S. Corrado, and Jeffrey Dean. Distributed representations of words and phrases and their compositionality. In NeurIPS, 2013.[25]Jeffrey Pennington, Richard Socher, and Christopher D. Manning. GloVe: Global vectors for word representation. In EMNLP, 2014.[26]Piotr Bojanowski, Edouard Grave, Armand Joulin, and Tomas Mikolov. Enriching word vectors with subword information.TACL, 5:135–146, 2017.[27]Bryan McCann, James Bradbury, Caiming Xiong, and Richard Socher. Learned in translation: Contextualized word vectors. In NeurIPS, 2017.[28]Oren Melamud, Jacob Goldberger, and Ido Dagan. Context2Vec: Learning generic context embedding with bidirectional LSTM. In CoNLL, pages 51–61, 2016.[29]Prajit Ramachandran, Peter J Liu, and Quoc Le. Unsupervised pretraining for sequence to sequence learning. In EMNLP,pages 383–391, 2017.[30]Jeremy Howard and Sebastian Ruder. Universal language model fine-tuning for text classification. In ACL, pages 328–339, 2018.[31]Yang, Zhilin, et al. "Xlnet: Generalized autoregressive pretraining for language understanding." Advances in neural information processing systems. 2019.[32]Liu, Yinhan, et al. "Roberta: A robustly optimized bert pretraining approach." arXiv preprint arXiv:1907.11692 (2019).[33]Lan, Zhenzhong, et al. "Albert: A lite bert for self-supervised learning of language representations." arXiv preprint arXiv:1909.11942 (2019).
推荐阅读
添加极市小助手微信(ID : cvmart2),备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳),即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群:每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
觉得有用麻烦给个在看啦~