
selenium新总结与数据抓取新技巧

作者:龙威
来源:玩大数据的规划师
"娄底终于放晴了,病树前头万木春,希望早点结束这场浩劫,恢复生机。本期更新两个知识点:一是selenium结合浏览器驱动器的数据爬取可以实现不让浏览器在前端打开显示;二是有些网站的一些数据本身是用网页存成的json数据,无需耗费大量心神去用selenium去抓取。"
01
—
selenium新技能
在抓取数据的过程中,界面的显示对于用户来说意义不大。除了在小白面前展示一下这种像见了鬼一样的自动化操作,对于完成一件事来说反而是累赘,因为网络的传播与渲染是需要耗时的,目前对于无界面的操作,抱歉我还不知道在后台有没有加载渲染,不过不是重点,重点把两种操作都给大家展示一下。
有界面
能清除的看到整个操作过程,举例百度一下疫情。代码如下:
from selenium import webdriverimport timedriver = webdriver.Chrome()driver.get("https://www.baidu.com/")driver.maximize_window()time.sleep(1)driver.find_element_by_xpath('//*[@id="kw"]').send_keys("疫情")driver.find_element_by_xpath('//*[@id="su"]').click()time.sleep(3)driver.close()
整个操作流程展示动图:
无界面
无界面的好处,当某些操作要做成应用程序,去打开浏览器,那这个软件有点怪。
代码如下:
from selenium import webdriverimport time# 创建chrome参数对象opt = webdriver.ChromeOptions()# 把chrome设置成无界面模式,不论windows还是linux都可以,自动适配对应参数opt.add_argument('--headless')# 创建chrome无界面对象driver = webdriver.Chrome(options=opt) #DeprecationWarning: use options instead of chrome_optionsdriver.get("https://www.baidu.com/")time.sleep(1)driver.find_element_by_xpath('//*[@id="kw"]').send_keys("疫情")driver.find_element_by_xpath('//*[@id="su"]').click()time.sleep(3)text = driver.page_sourceprint(text)driver.close()
无界面模式下,开发者可以先通过有界面把代码写好。后续的操作过程把有界面改成无界面即可,视频展示如下:
02
—
新技巧
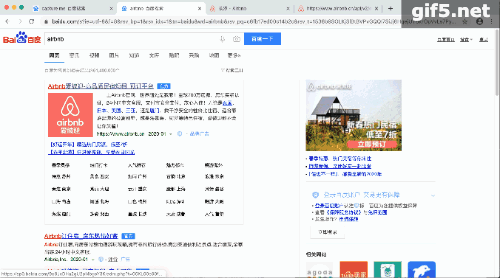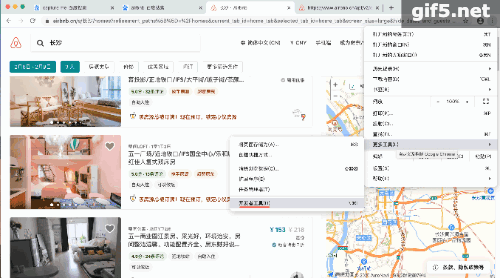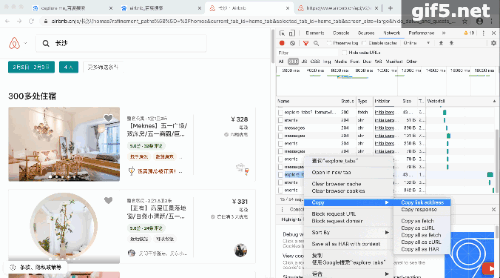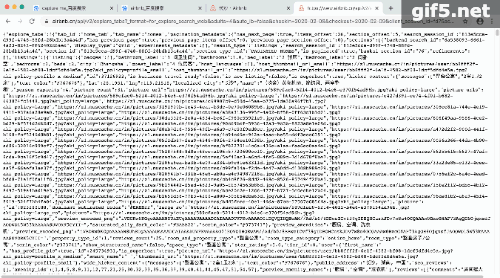
其实这个数据抓取也不是什么新技能,只是之前我在抓取Airbnb的时候,我以为是网站提供了api,其实是无意中从网页解析中获得的,这里举例在重温一下步骤。
Airbnb:
那些活动的网页,每次跳转的过程中都会加载一个新的页面。那个新的页面,只要找到那个含json数据的页面,加上python的基础技能,字典,列表,字符串等等,就能提取想要的数据。动态图如下:
彩票开奖网:
结构化的数据是最好提取的,网站要呈现结构的数据,我们只需要解析一个,后续的全部依葫芦画瓢解析,构建一个循环即可:
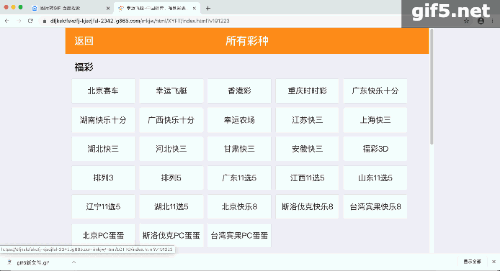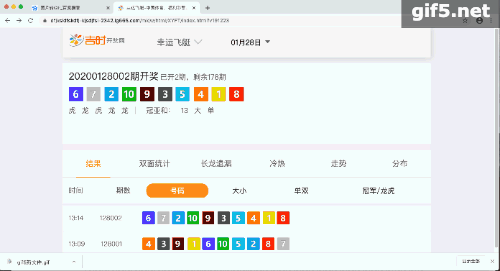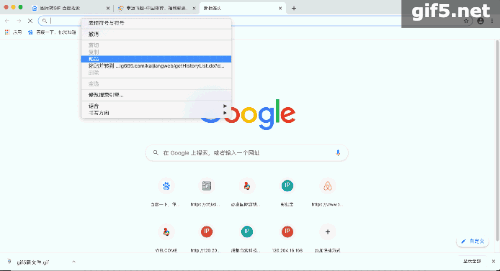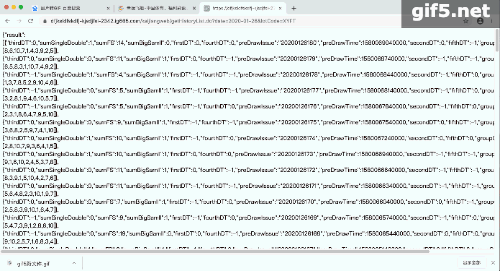
最终的每天的结果,修改日期即可:
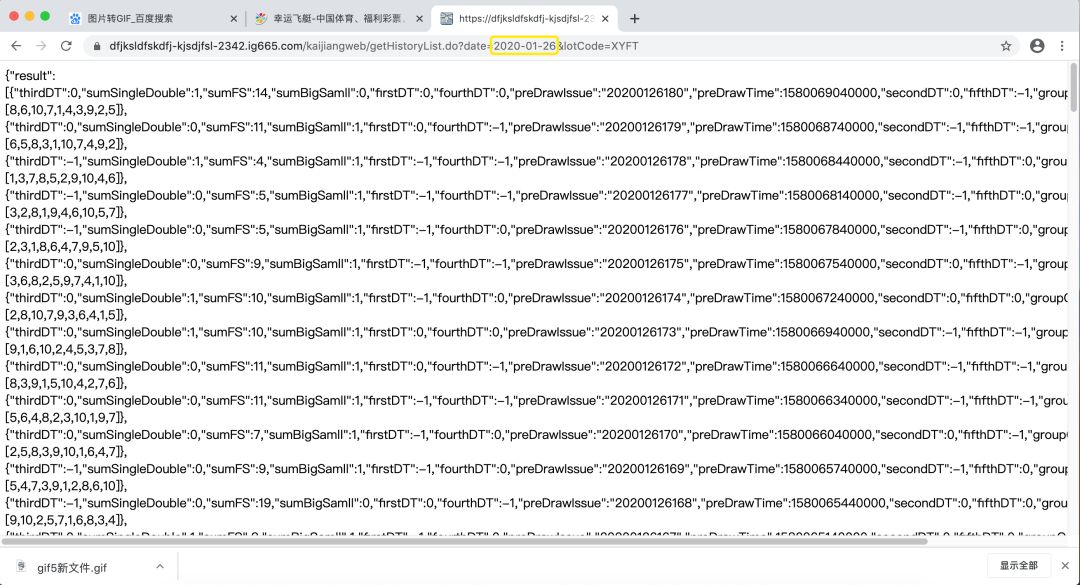
总结:静态页面获取速度快,如果去获取一个动态加载的网页,需要等网页全部加载完再获取,费事费力,更难的可能还需要验证码之类,所有途径,获取json格式网页是我所见最简单的。
◆ ◆ ◆ ◆ ◆
长按二维码关注我们
数据森麟公众号的交流群已经建立,许多小伙伴已经加入其中,感谢大家的支持。大家可以在群里交流关于数据分析&数据挖掘的相关内容,还没有加入的小伙伴可以扫描下方管理员二维码,进群前一定要关注公众号奥,关注后让管理员帮忙拉进群,期待大家的加入。
管理员二维码:
● 华农兄弟、徐大Sao&李子柒?谁才是B站美食区的最强王者?
● 你相信逛B站也能学编程吗