
字节跳动自研万亿级图数据库ByteGraph及其应用与挑战

本文约3000字,建议阅读6分钟
本文将介绍字节跳动自研的图数据库ByteGraph及其在字节内部的应用和挑战。
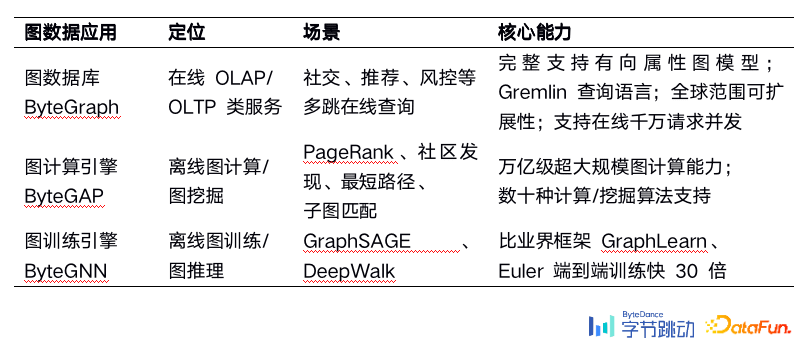
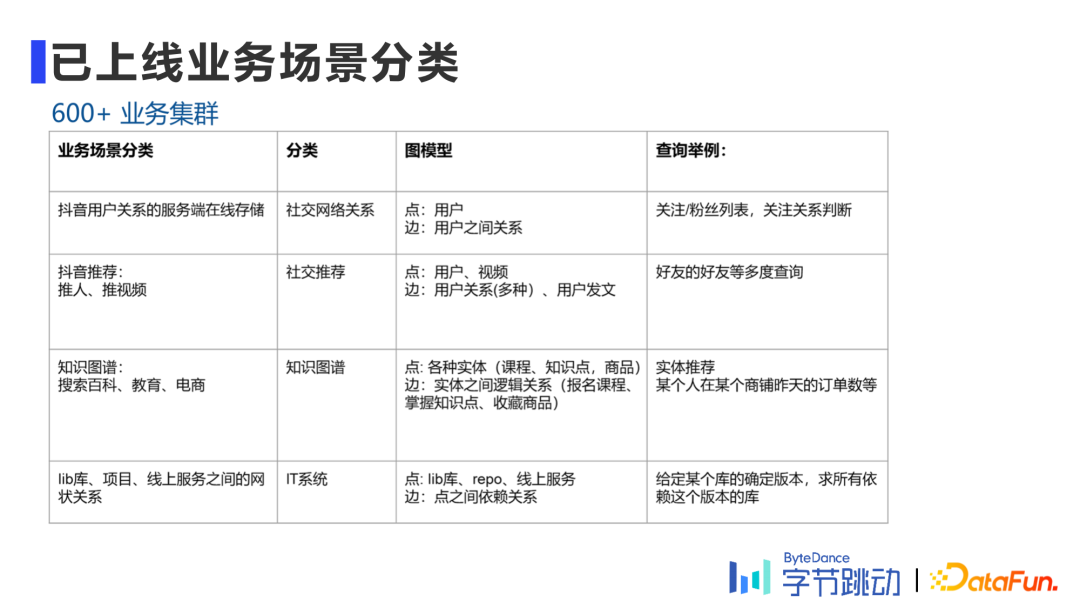
[ 导读 ] 作为一种基础的数据结构,图数据的应用场景无处不在,如社交、风控、搜广推、生物信息学中的蛋白质分析等。如何高效地对海量的图数据进行存储、查询、计算及分析,是当前业界热门的方向。本文将介绍字节跳动自研的图数据库ByteGraph及其在字节内部的应用和挑战。
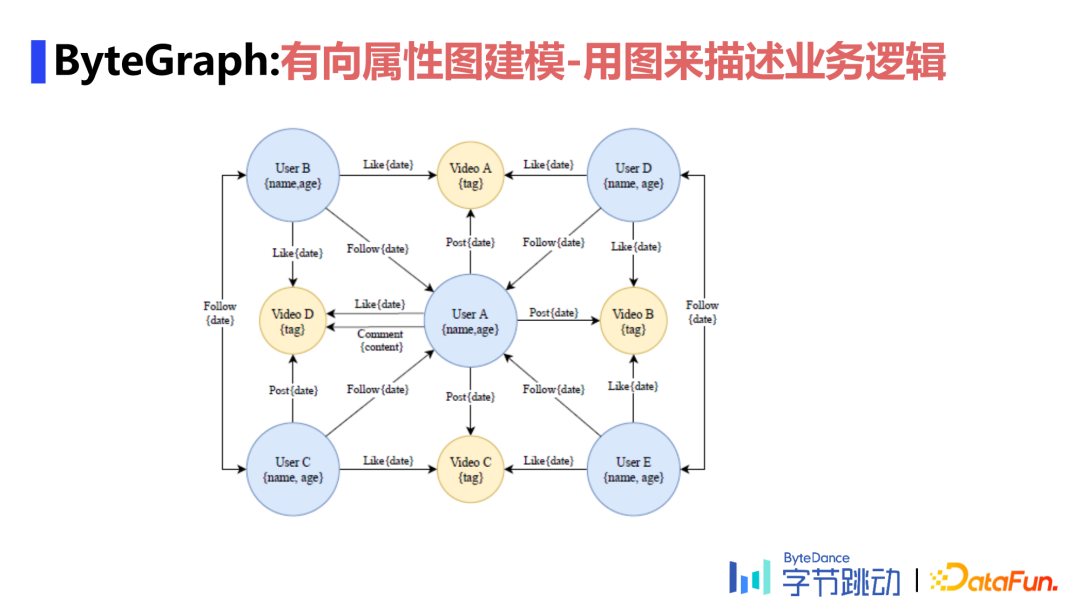
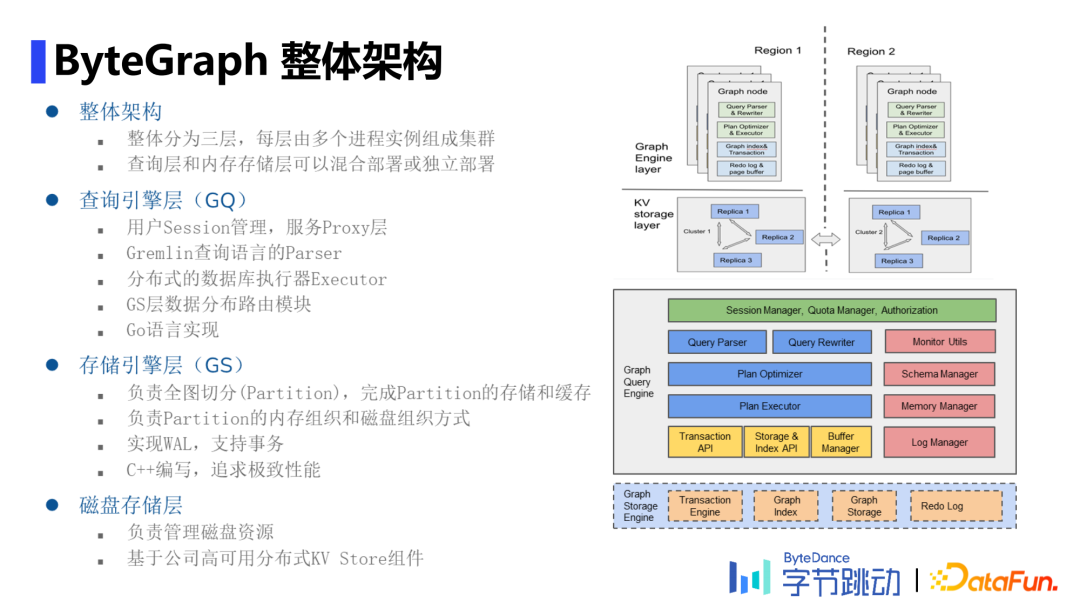
了解图数据库 适用场景介绍举例 数据模型和查询语言 ByteGraph架构与实现 关键问题分析

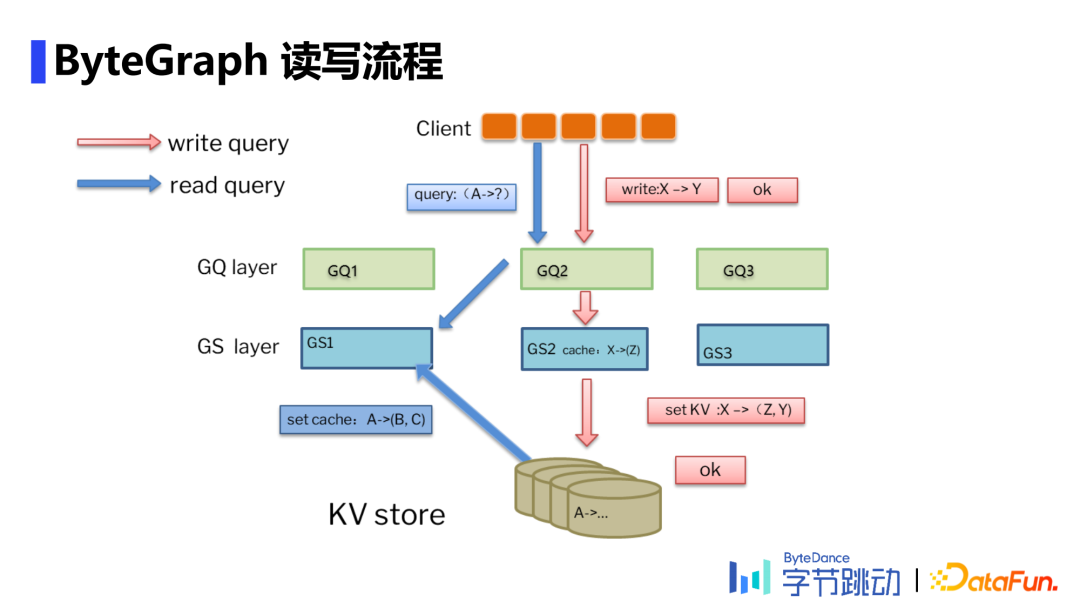
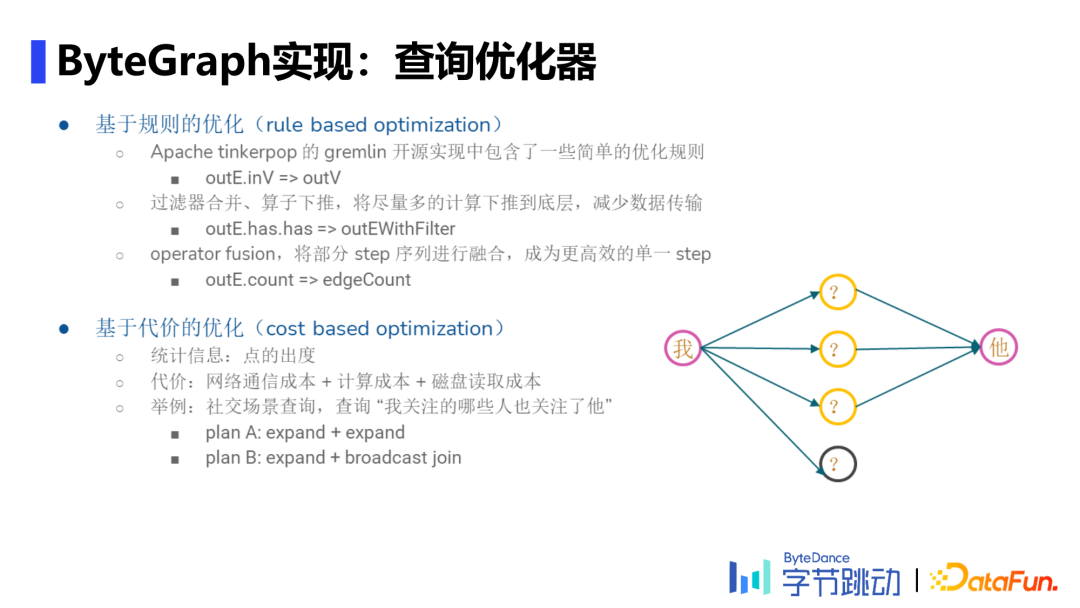
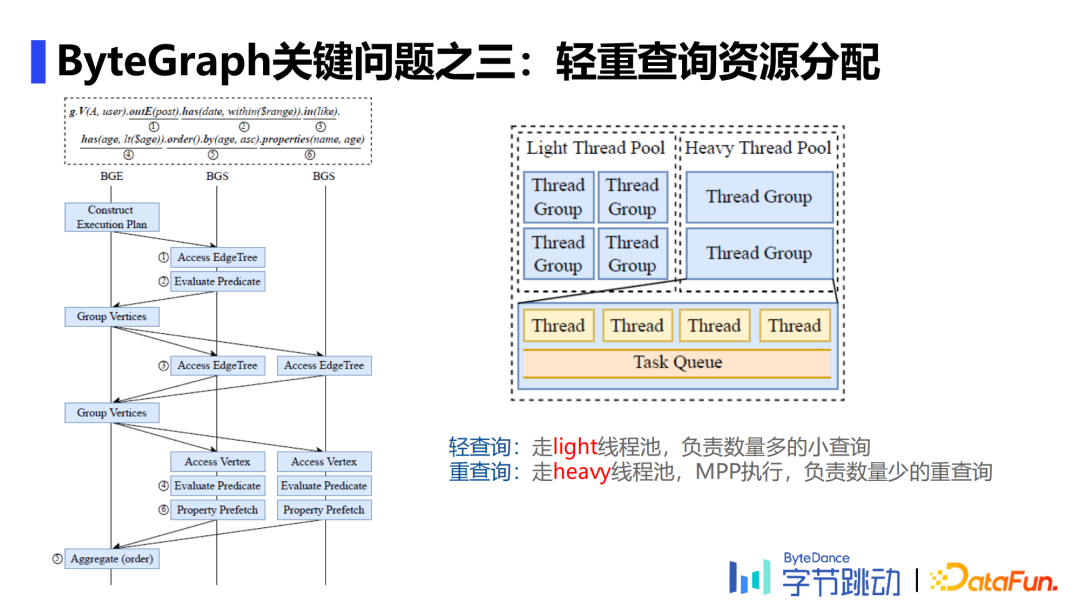
Parser阶段:利用递归下降解析器将查询语言解析为一个查询语法树。 生成查询计划:将Parser阶段得到的查询语法树按照查询优化策略(RBO&CBO)转换为执行计划。 执行查询计划:理解GS数据分Partition的逻辑,找到相应数据并下推部分算子,保证网络开销不会太大,最后合并查询结果,完成查询计划。
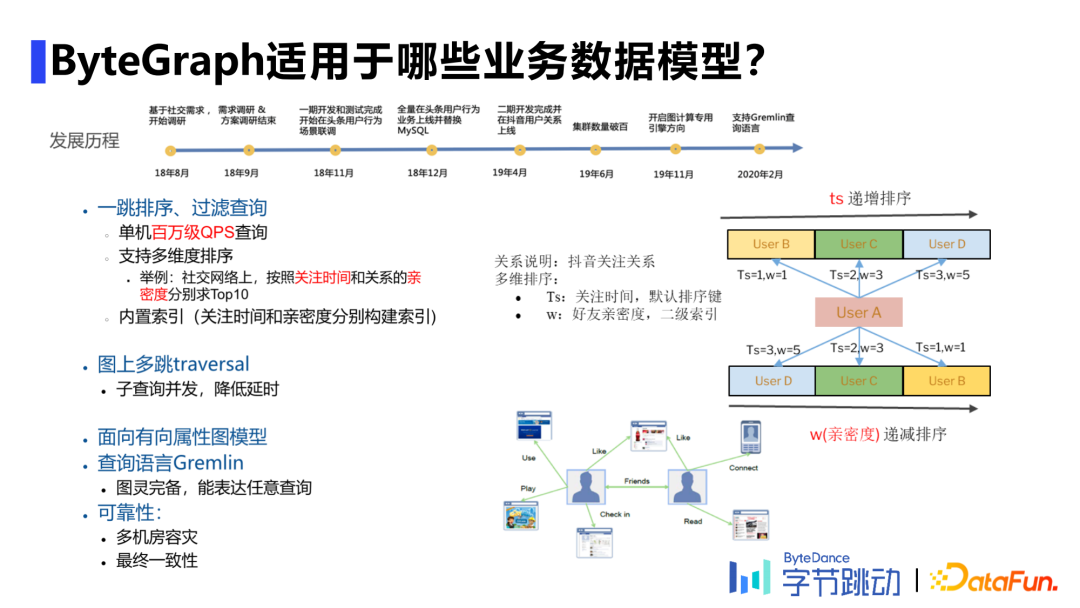
Brute force哈希分区:即根据起点和边的类型进行一致性哈希分区,可以大部分查询场景需求,尤其是一度查询场景。 知识图谱场景:点、边类型极多,但每种类型边数量相对较少,此时根据边类型进行哈希分区,将同种边类型数据分布在一个分区内。 社交场景:更容易出现大V,利用facebook于2016年提出的social hash算法,通过离线计算尽量将有关联的数据放置在同一分片内,降低延迟。
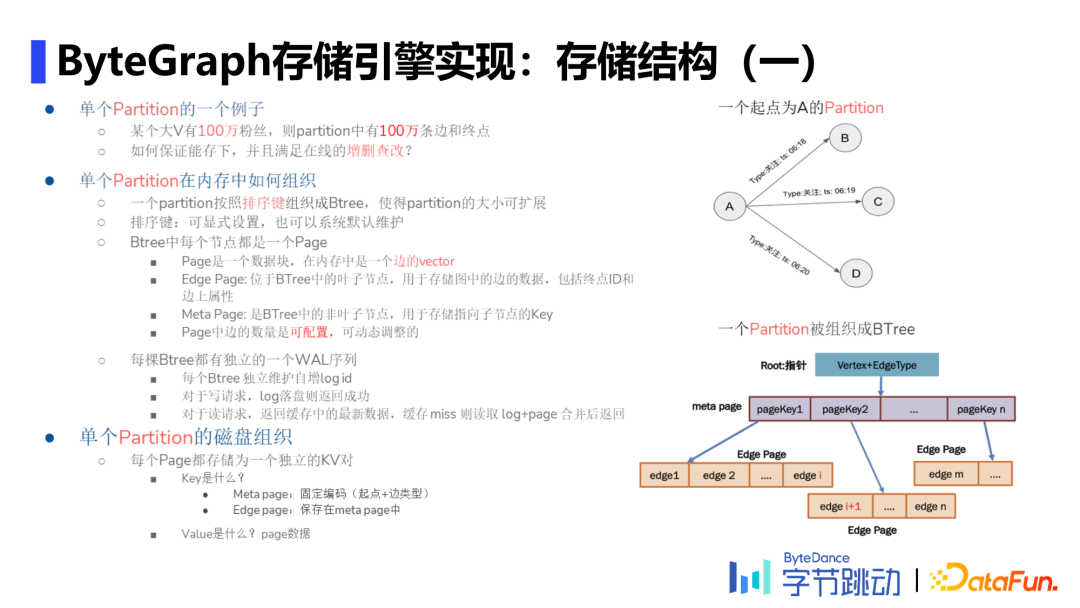
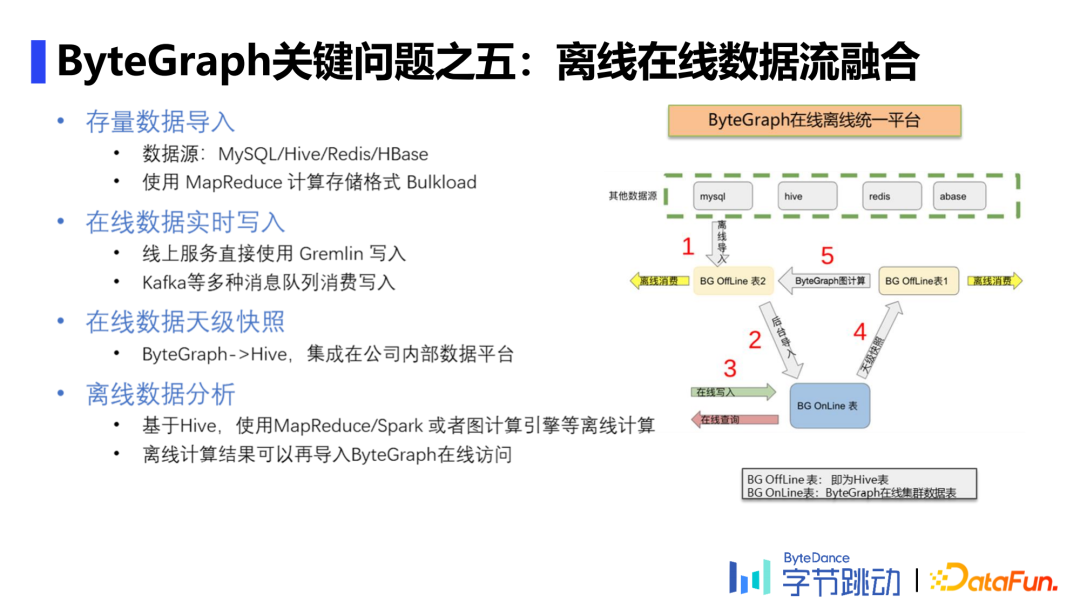
存储结构
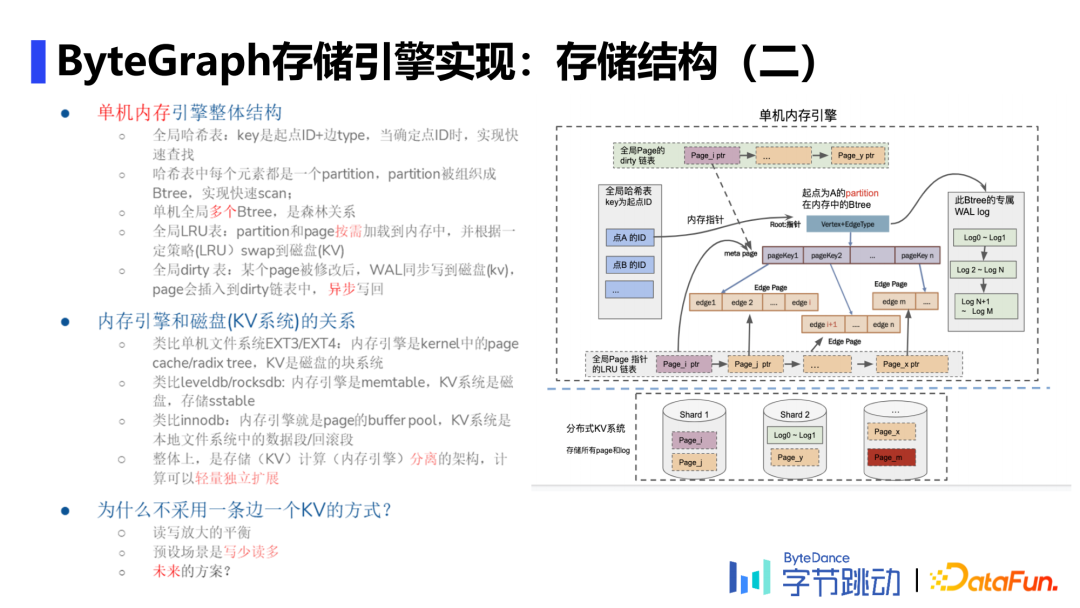
日志管理:单个起点+边类型组成一棵Btree,每个结点是一个KV对。
缓存实现:根据不同场景及当下cpu的开销有不同策略。
局部索引:给定一个起点和边类型,对边上的属性构建索引
全局索引:目前只支持点的属性全局索引,即指定一个属性值查询出对应的点。
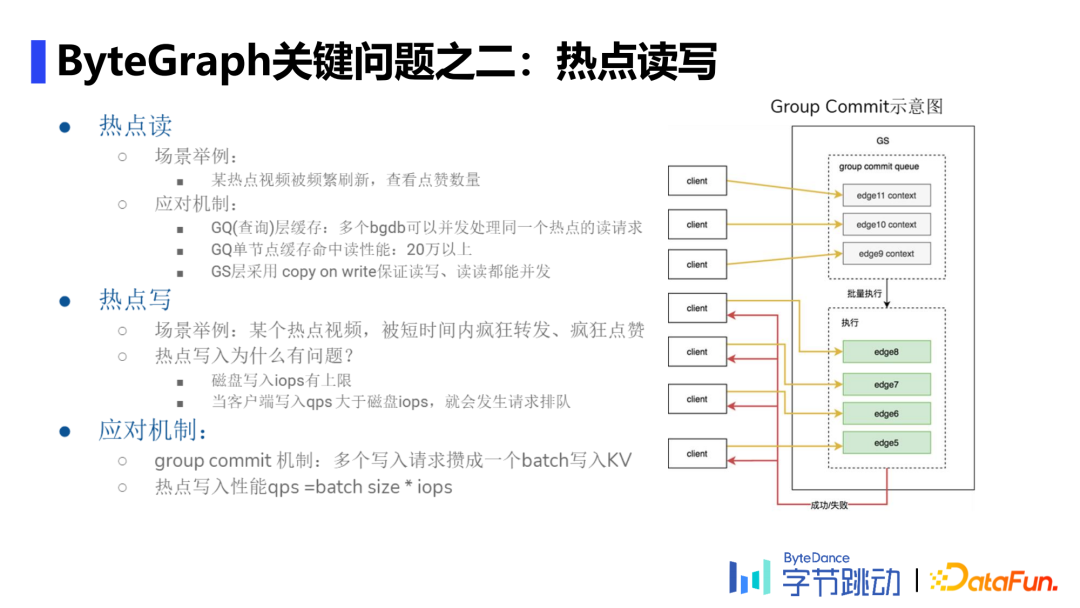
热点读
热点写
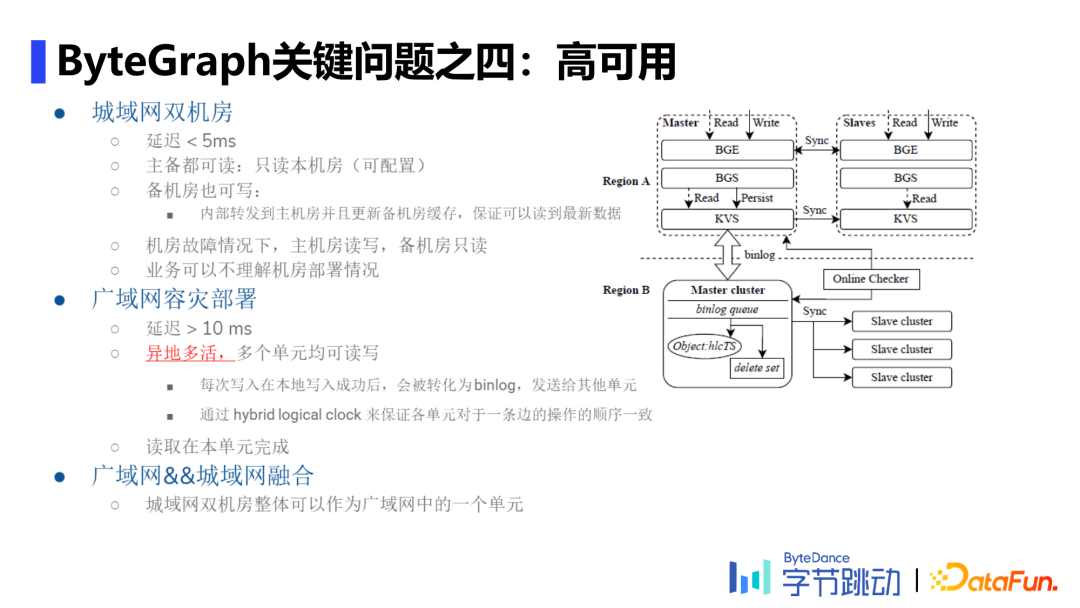
城域网双机房,如国内的两个机房,延迟较低。follow一写多读策略,备机房把写流量转入主机房,只有主机房会把WAL更新到KV存储上。 广域网容灾部署,如新加坡和美国的两台机器,延迟较高。follow了mysql的思想,每次写入在本地写入成功后,会被转化为binlog,再发送给其他单元;并通过hybrid logical clock保证各单元对于一条边的操作顺序一致性。
编辑:于腾凯
校对:林亦霖
评论