HTTP keep-alive、TCP Keep-Alive、心跳检测,傻傻分不清?
1
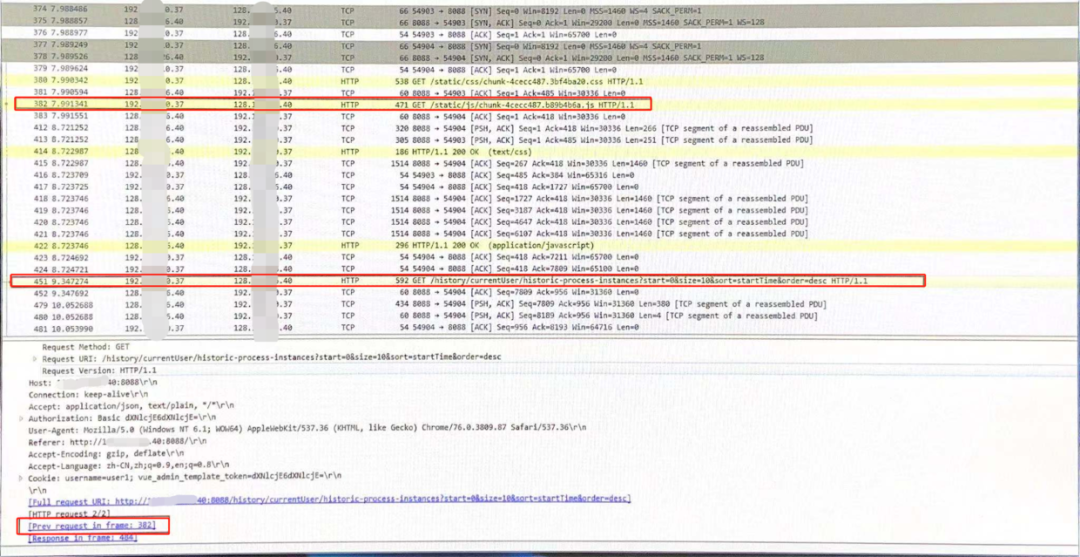
2
TCP Keep-Alive是什么?
3
浏览器和服务端之间的连接会一直保持吗?
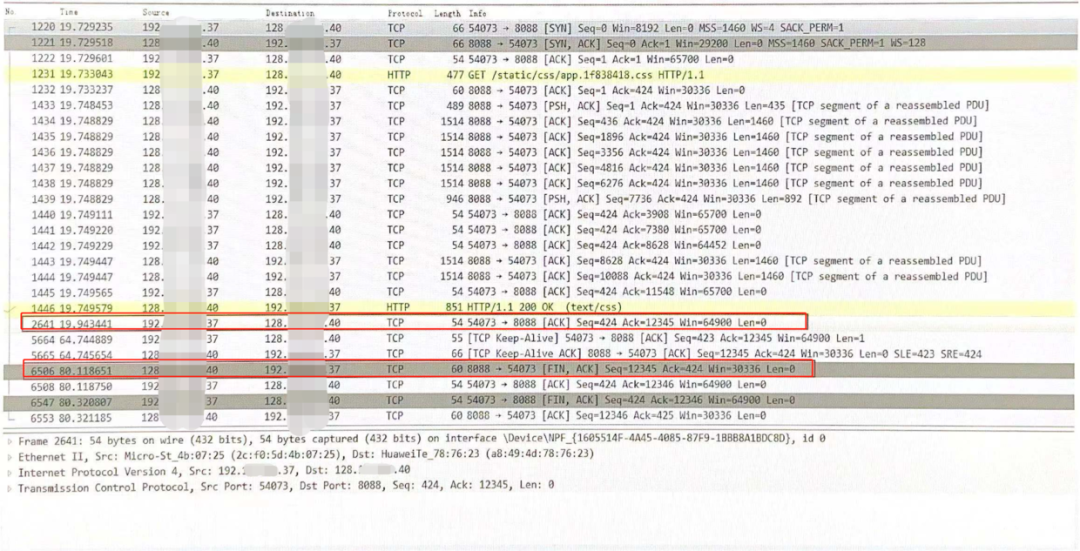
iptables -A INPUT -p tcp -s 192.x.x.37 -j DROPiptables -A OUTPUT -p tcp -d 192.x.x.37 -j DROP
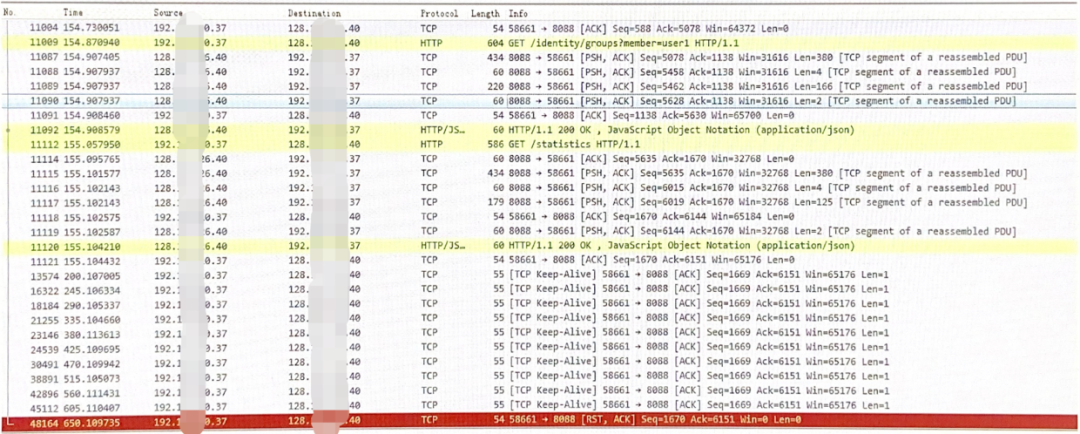
4
聊技术,不止于技术。
评论
 下载APP
下载APP1
2
TCP Keep-Alive是什么?
3
浏览器和服务端之间的连接会一直保持吗?
iptables -A INPUT -p tcp -s 192.x.x.37 -j DROPiptables -A OUTPUT -p tcp -d 192.x.x.37 -j DROP
4
聊技术,不止于技术。