
长沙旅游攻略!用Python告诉你31块的臭豆腐它香吗?
回复“书籍”即可获赠Python从入门到进阶共10本电子书
五一去长沙吃喝玩乐
前几天发表过一篇文章厦门不止鼓浪屿,得到了一些朋友的肯定,让我再写下其他城市。这两天又获取到了两份关于长沙的数据:长沙景点和长沙美食,之后进行了分析,如果有朋友想去长沙或者周边城市玩,要仔细看看喔。

导入库
import pandas as pd
import re
import csv
import json
import requests
import random
# 显示所有列
# pd.set_option('display.max_columns', None)
# 显示所有行
# pd.set_option('display.max_rows', None)
# 设置value的显示长度为100,默认为50
# pd.set_option('max_colwidth',100)
# 绘图相关
import jieba
import matplotlib.pyplot as plt
from pyecharts.globals import CurrentConfig, OnlineHostType
from pyecharts import options as opts # 配置项
from pyecharts.charts import Bar, Pie, Line, HeatMap, Funnel, WordCloud, Grid, Page # 各个图形的类
from pyecharts.commons.utils import JsCode
from pyecharts.globals import ThemeType,SymbolType
import plotly.express as px
import plotly.graph_objects as go
长沙景点
数据获取
长沙景点的数据获取方法和之前那篇关于厦门的文章是一样的,只是重新跑了一遍代码,具体过程不再阐述,感兴趣的朋友可以看之前的文章,爬取的字段:
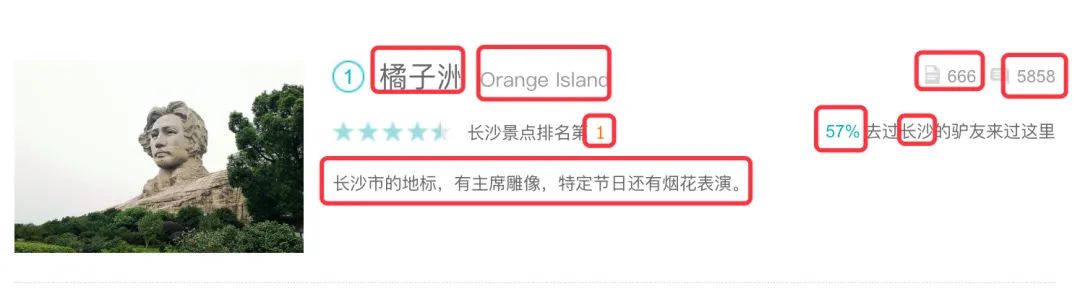
中文名 英文名 攻略数 评价数 位置 排名 驴友占比 简介
具体的源代码如下:
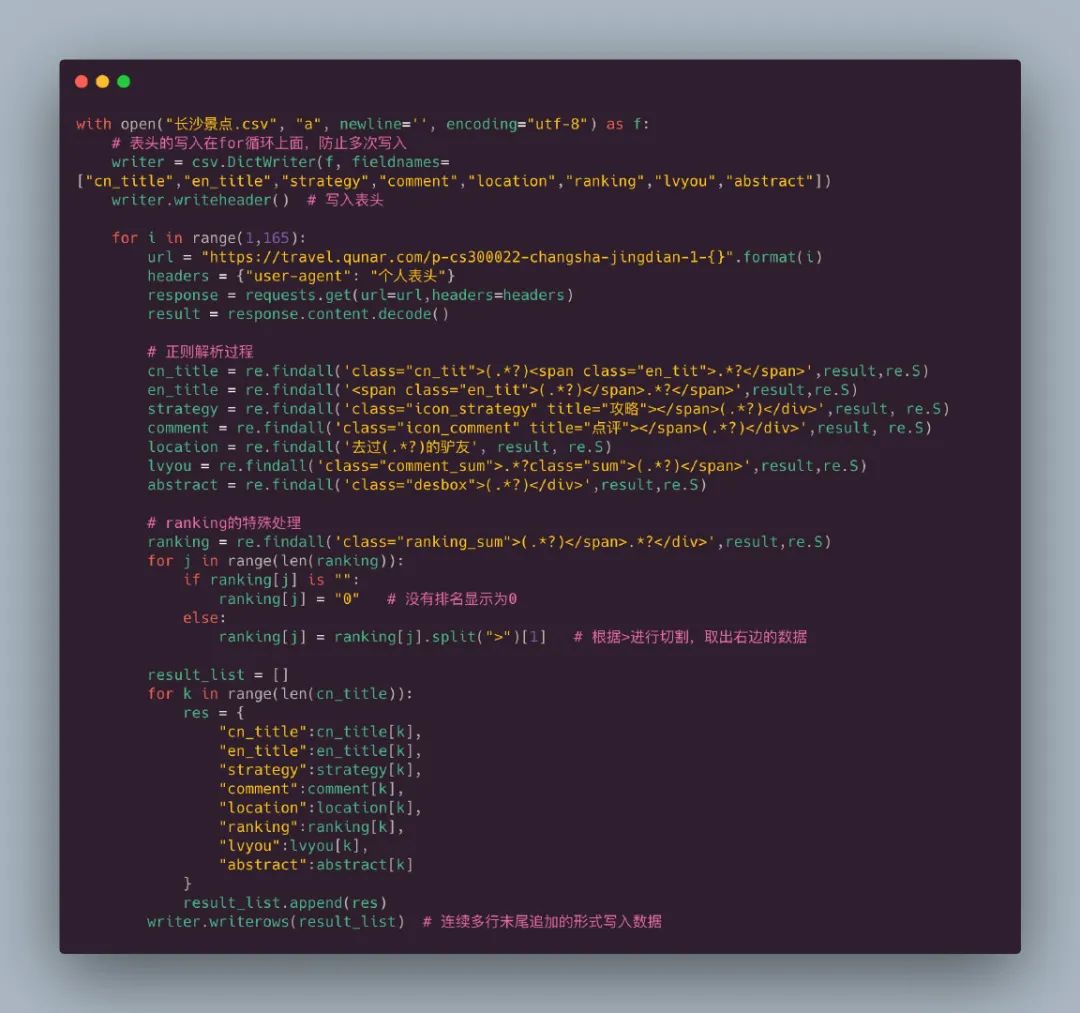
最终数据有1152条,数据中绝大部分是长沙的景点数据,也有少量少量周边城市,比如:宁乡、浏阳等的数据,整体的数据前5行如下:

下面重点介绍数据分析的过程
整体情况
首先看看整体的数据情况:
fig = px.scatter(changsha[:10], # 前10个
x="strategy", # 攻略数
y="comment", # 评论数
color="comment", # 颜色选取
size="comment", # 散点大小
hover_name="cn_title",
text="cn_title" # 显示文字
)
fig.update_traces(textposition='top center') # 文本顶部居中显示
fig.show()
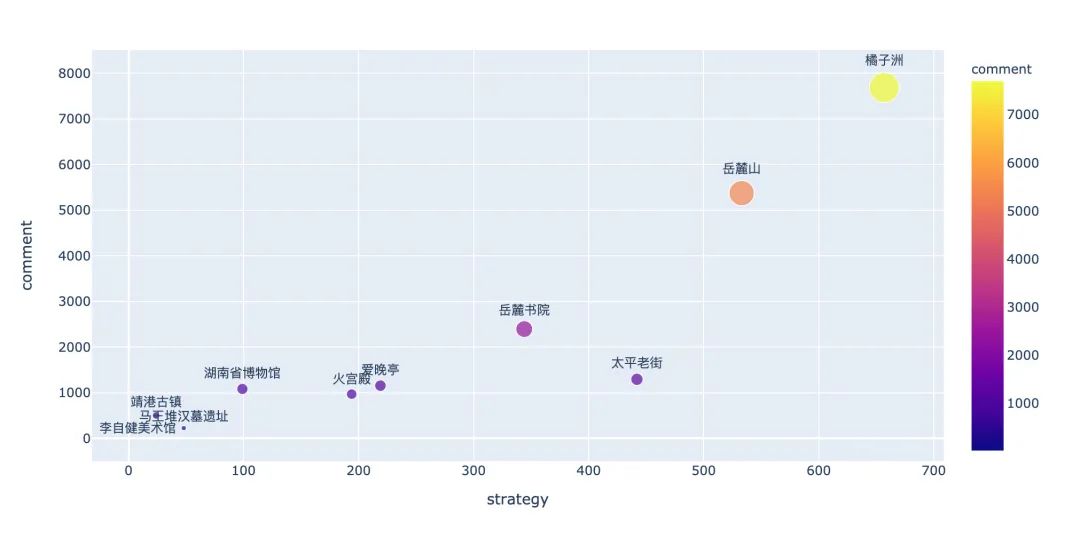
很显然:橘子洲、岳麓山、岳麓书院、太平老街排名靠前
排名靠前景点
看看排名靠前的景点是哪些?
# 根据ranking排序取出前20名数据,排除ranking=0的数据,再取出前10数据
changsha1 = changsha[changsha["ranking"] != 0].sort_values(by=["ranking"])[:20].reset_index(drop=True)
changsha1.head(10)
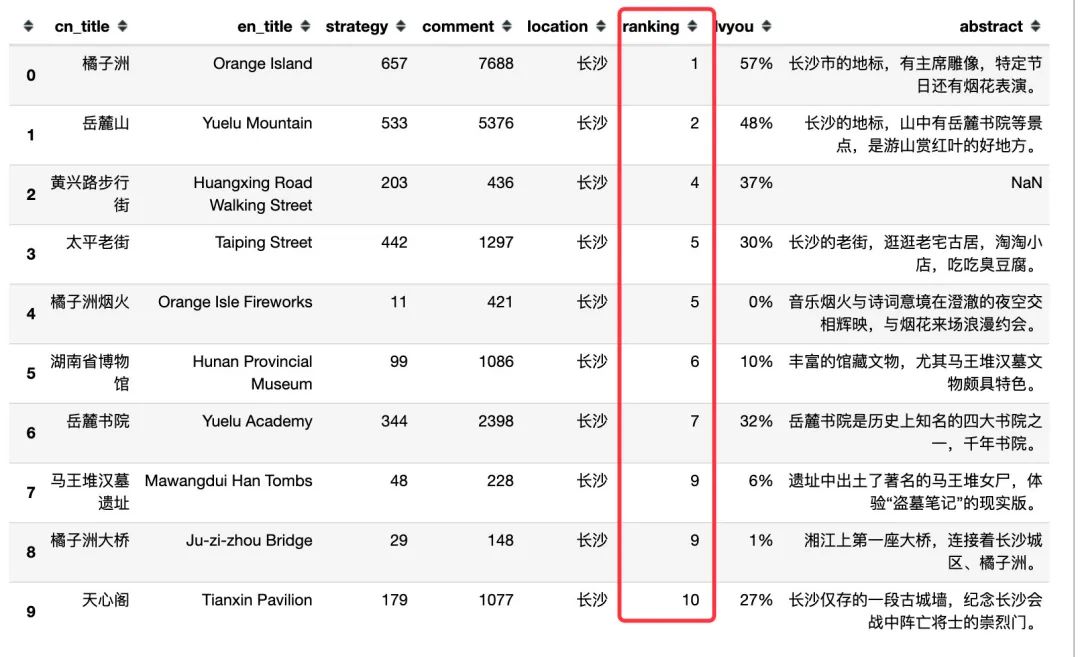
通过排名我们发现:橘子洲(烟火、大桥、天心阁)、岳麓山(书院)、黄兴路步行街、马王堆汉墓遗址、湖南省博物馆,整体排名很靠前,深受游客们欢迎,具体看看排名前20的景点:
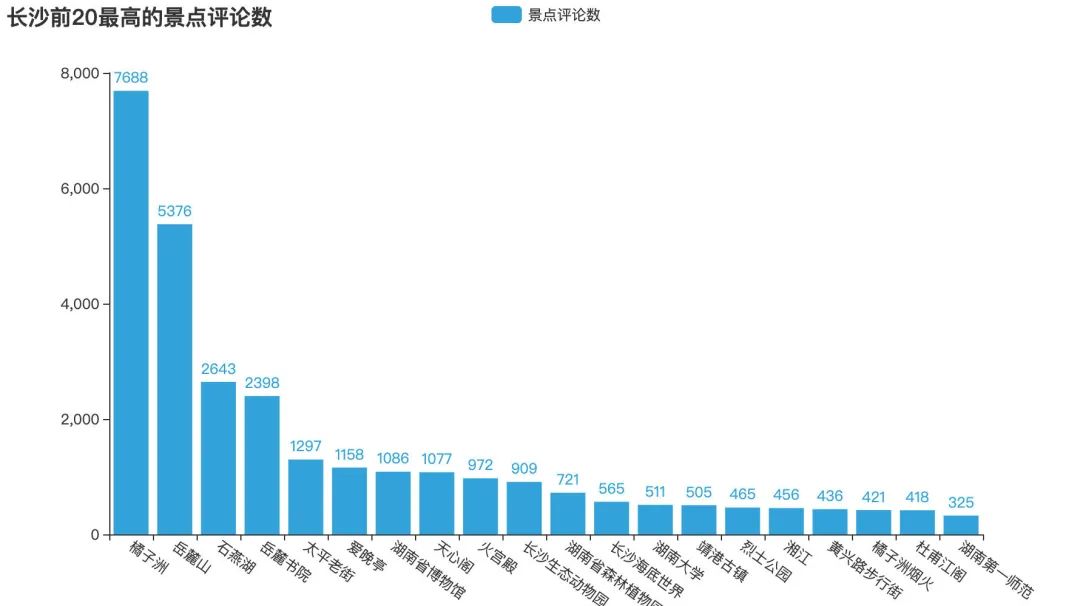
评论火爆景点
很多游客到了一个景点喜欢写评论,看下哪些景点获得大量的评论:
changsha2 = changsha[changsha["comment"] != 0].sort_values(by=["comment"],ascending=False)[:10]
# 绘图
fig = px.scatter(
changsha2,
x="cn_title",
y="comment",
size="comment",
color="comment",
text="cn_title"
)
fig.update_traces(textposition="top center")
fig.show()
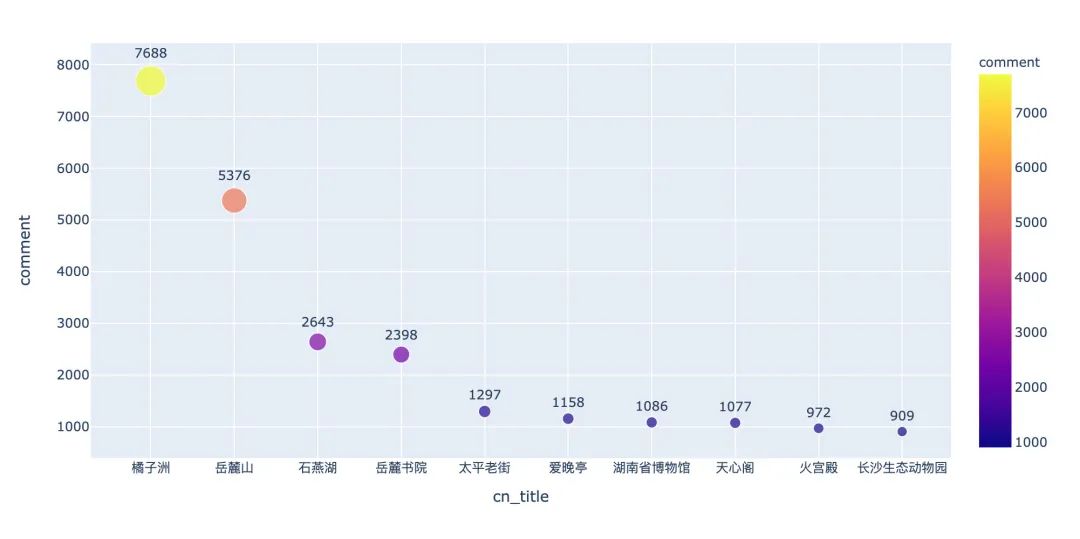
攻略在手,旅游不愁
出门旅游之前最好还是做一份旅游攻略,看看提供攻略最多的前10景点是哪些:
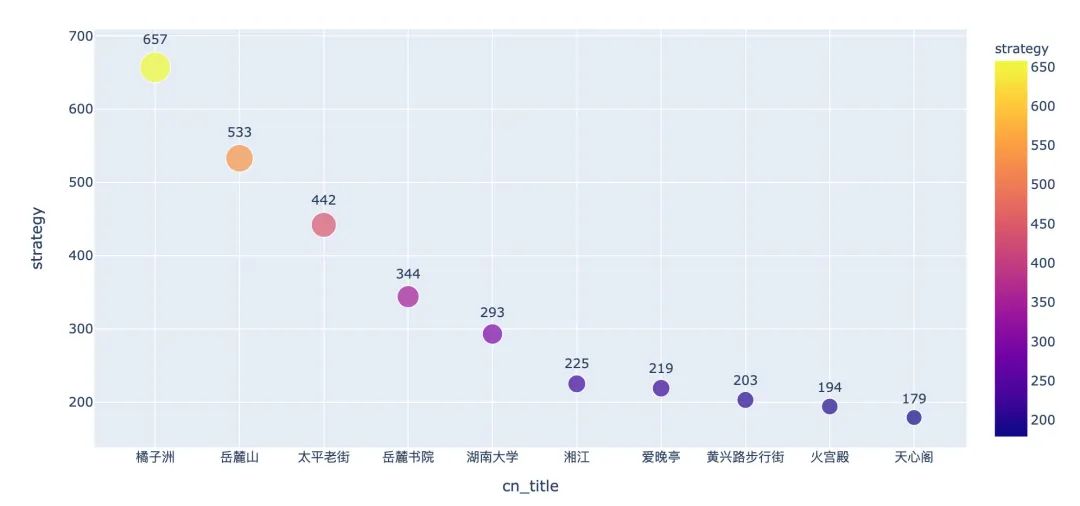
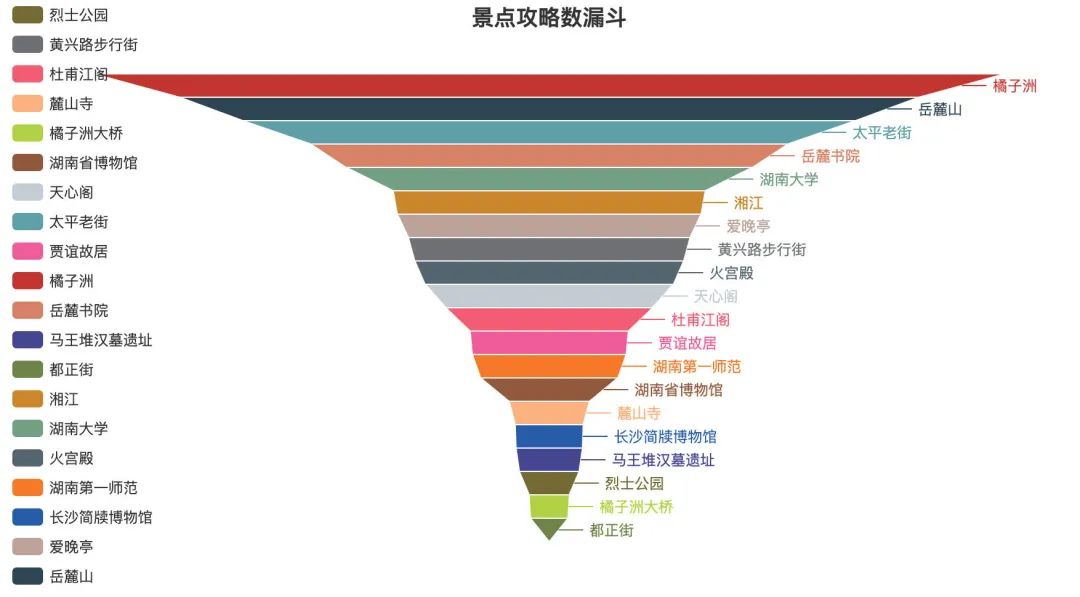
如果我们考虑前20个景点的攻略数:
驴友占比
我们爬取到的驴友数据是百分比,类型是字符串类型,我们现在去掉%符号,取出左边的数值,如果没有则用0代替,方便最终画图,具体操作如下:
# 去掉%取出左边数据
changsha["lvyou_number"] = changsha["lvyou"].apply(lambda x:x.split("%")[0])
changsha["lvyou_number"] = changsha["lvyou_number"].astype(int)
changsha.head()
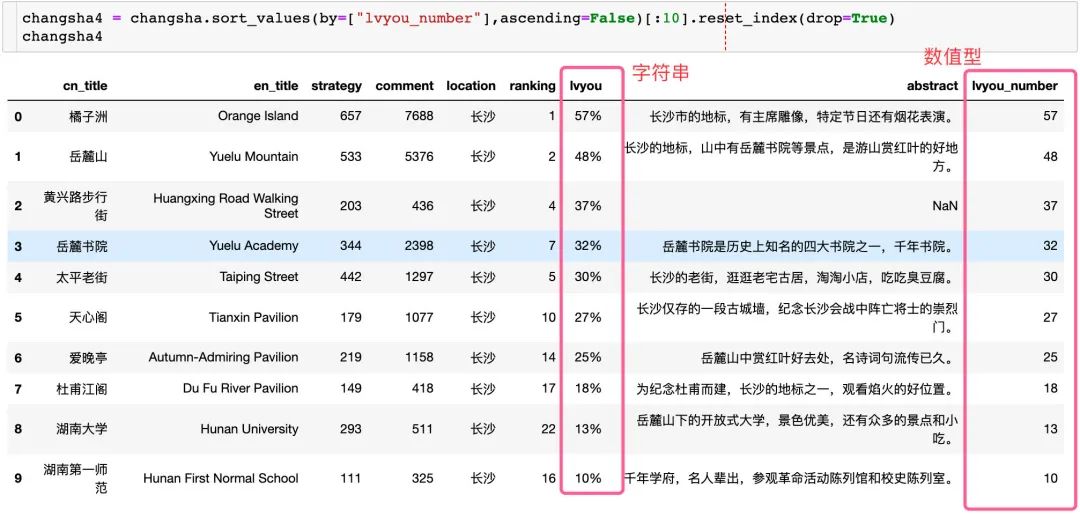
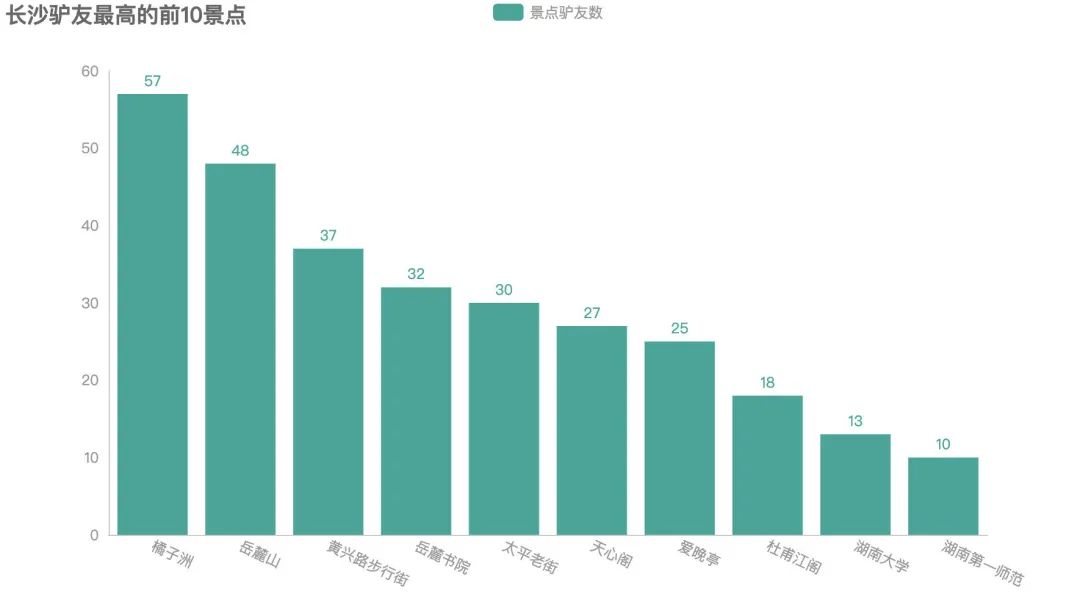
取出排名前10的驴友占比景点:
景点介绍
获取到的abstract字段是用来描述景点的基本信息,可以用来制作词云图,具体处理过程如下:
abstract_list = changsha["abstract"].tolist()
# 1、分词
jieba_name = []
for i in range(len(abstract_list)):
# seg_list只是一个generator生成器:<class 'generator'>
seg_list = jieba.cut(str(abstract_list[i]).strip(), cut_all=False)
# 对list(seg_list)中的每个元素进行追加
for each in list(seg_list):
jieba_name.append(each)
# 2、去停用词
# 创建停用词list
def stopwordslist(filepath):
stopwords = [line.strip() for line in open(filepath, 'r', encoding='utf-8').readlines()]
return stopwords
# 传入路径,加载去停用词
stopwords = stopwordslist('/Users/peter/Desktop//nlp_stopwords.txt')
stopword_list = []
for word in jieba_name: # jieba_name中的word不在停用词表中,且不是\t制表符
if word not in stopwords:
if word != "\t" and word != " " and word != "nan":
stopword_list.append(word)
# 3、统计单词出现个数
dic = {}
number = 0
for each in stopword_list:
if each in dic.keys():
number += 1
dic[each] = number
else:
dic[each] = 1 # 不存在则结果为1
# 4、字典转成json数据,绘制词云图需要
tuple_list = []
for k,v in dic.items():
tuple_list.append(tuple([k,v]))
tuple_list[:20]

长沙美食
第二部分介绍的是长沙(附近部分长沙)的美食,接下来从3个方面介绍:
字段获取 数据保存及处理 美食数据分析
发送请求
url = "https://travel.qunar.com/p-cs300022-changsha-meishi?page=1"
headers = {"user-agent": "个人请求头"}
response = requests.get(url=url,headers=headers)
result = response.content.decode()
字段获取
名称cn_title 评分socre 均价person_avg 地址address 推荐菜recommand 评价comment
1、源码结构
网页显示每页有10个景点(最后页未必是10个),总共200页的数据,每个景点的信息包括在一个<li></li>标签对中,我们只需要从标签中获取到相应的信息即可
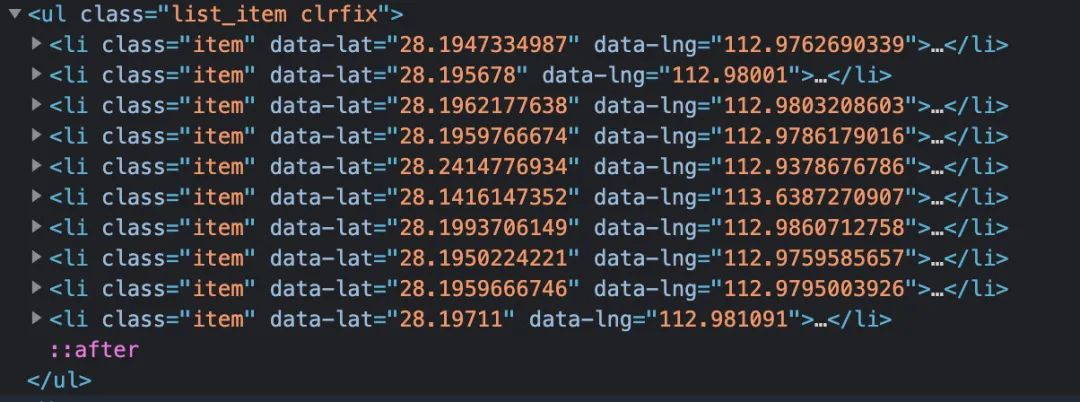
2、名称和评分两个字段的获取相对简单,直接通过正则表达式来获取,关键字定位需要准确(以后会详细详解正则表达式的使用)
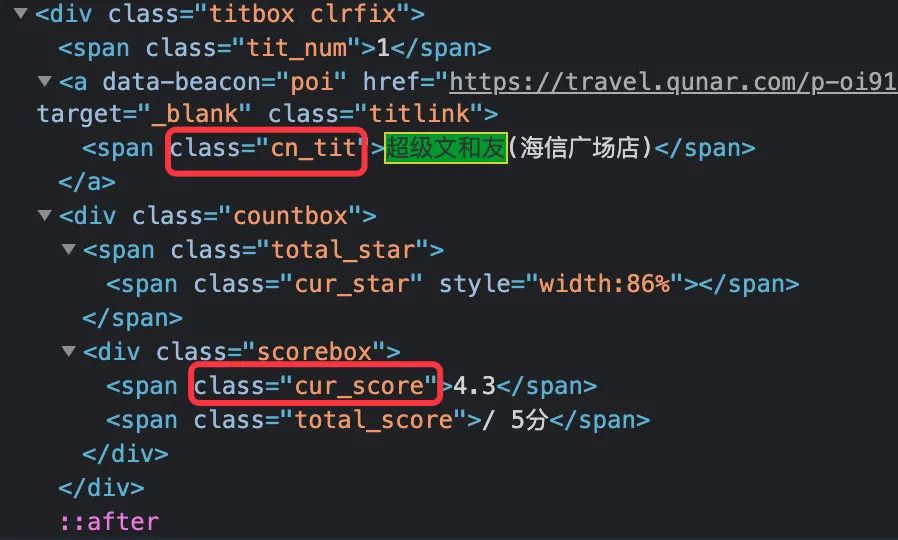
# 中文名
cn_title = re.findall('cn_tit">(.*?)</span>.*?countbox',result,re.S)

# 得分:没有得分用--表示
score = re.findall('cur_score">(.*?)</span>.*?total_score',result,re.S)
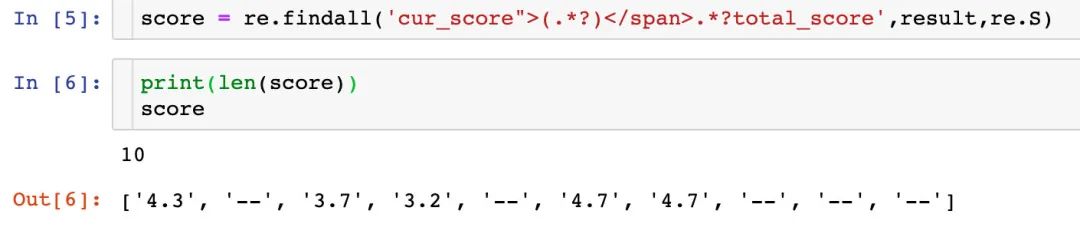
3、关于剩下4个字段的获取,相对复杂。因为他们并不是在每个店的信息中存在,有的,但是他们有一个共同点:全部是隐藏一个<div></div>标签对中,而且每个字段都有自己的关键词
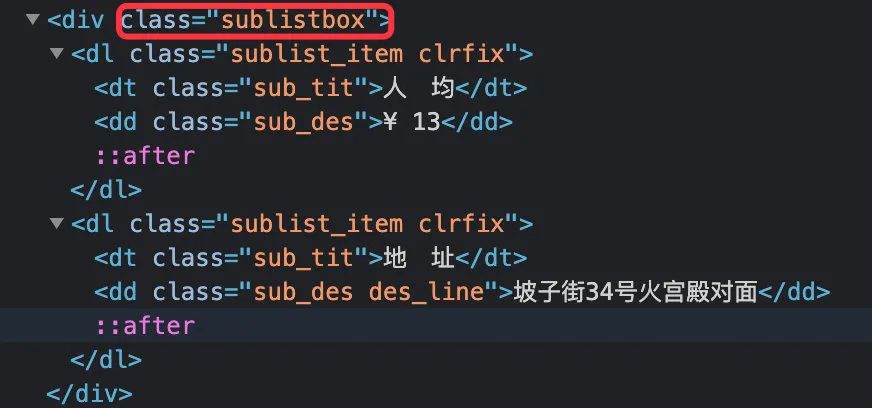

具体处理方法:先大后小
1、先整体:提取sublistbox下面的全部信息

2、从步骤1的信息进行判断,获取4个单独字段
# 均价
person_avg = []
for i in range(len(sublistbox)):
try:
if "均" in sublistbox[i]: # 如果均价存在
person_avg.append(re.findall('¥ (.*?)</dd></dl>',sublistbox[i],re.S) [0]) # 将解析出来的第一个字段放入列表中
else: # 否则,不存在的话,添加0
person_avg.append(0)
continue # 遇到报错继续往下执行
except:
person_avg.append(0)
剩下3个字段处理类似:
address = []
for i in range(len(sublistbox)):
try:
if "址" in sublistbox[i]: # 关键词
address.append(re.findall('址.*?des_line">(.*?)</dd></dl>',sublistbox[i],re.S)[0])
else:
address.append("无")
continue
except:
address.append("无")
recommand = []
for i in range(len(sublistbox)):
try:
if "推荐菜" in sublistbox[i]:
recommand.append(re.findall('推荐菜.*?des_line">(.*?)</dd></dl>',sublistbox[i],re.S)[0])
else:
recommand.append("无")
continue
except:
recommand.append("无")
comment = []
for i in range(len(sublistbox)):
try:
if "desbox" in sublistbox[i]: # 关键词
comment.append(re.findall('.*?txt">(.*?)<span class="img_doublequote img_r">',sublistbox[i],re.S)[0])
else:
comment.append("无")
continue
except:
comment.append("无")
4、上面是获取单页数据的解析过程,下面讲解如何获取200页的字段数据:
# 中文名:得分字段类似
cn_title_list = []
for i in range(1,201):
url = "https://travel.qunar.com/p-cs300022-changsha-meishi?page={}".format(i)
headers = {"user-agent": "请求头"}
response = requests.get(url=url,headers=headers)
result = response.content.decode()
cn_title = re.findall('cn_tit">(.*?)</span>.*?countbox',result,re.S)
for each in cn_title:
cn_title_list.append(each)
cn_title_list
# 均价字段:地址、推荐菜、评价类似
# 某个字段不存在,用0或者无代替
person_avg_list = []
for i in range(1,201):
url = "https://travel.qunar.com/p-cs300022-changsha-meishi?page={}".format(i)
headers = {"user-agent": ""}
response = requests.get(url=url,headers=headers)
result = response.content.decode()
# 1、先整体提取
sublistbox = re.findall('sublistbox">(.*?)</div>', result, re.S)
# 2、再局部提取
person_avg = []
for i in range(len(sublistbox)):
try:
if "均" in sublistbox[i]:
person_avg.append(re.findall('¥ (.*?)</dd></dl>',sublistbox[i],re.S)[0])
else:
person_avg.append(0)
continue
except:
person_avg.append(0)
for each in person_avg:
person_avg_list.append(each)
# 地址
address_list = []
for i in range(1,201):
url = "https://travel.qunar.com/p-cs300022-changsha-meishi?page={}".format(i)
headers = {"user-agent": "请求头"}
response = requests.get(url=url,headers=headers)
result = response.content.decode()
# 1、先整体提取
sublistbox = re.findall('sublistbox">(.*?)</div>', result, re.S)
# 2、再局部提取
address = []
for i in range(len(sublistbox)):
try:
if "址" in sublistbox[i]:
address.append(re.findall('址.*?des_line">(.*?)</dd></dl>',sublistbox[i],re.S)[0])
else:
address.append("无")
continue
except:
address.append("无")
for each in address:
address_list.append(each)
address_list[:20]
获取全网数据
5、提取到每个字段后生成整体数据,并保存:
# 1、生成数据
df = pd.DataFrame({
"中文名": cn_title_list,
"得分": score_list,
"均价": person_avg_list,
"地址": address_list,
"推荐菜": recommand_list,
"评价": comment_list
})
# 2、保存数据
# df.to_csv("长沙美食.csv",index=False,encoding='utf_8_sig') # 防止乱码
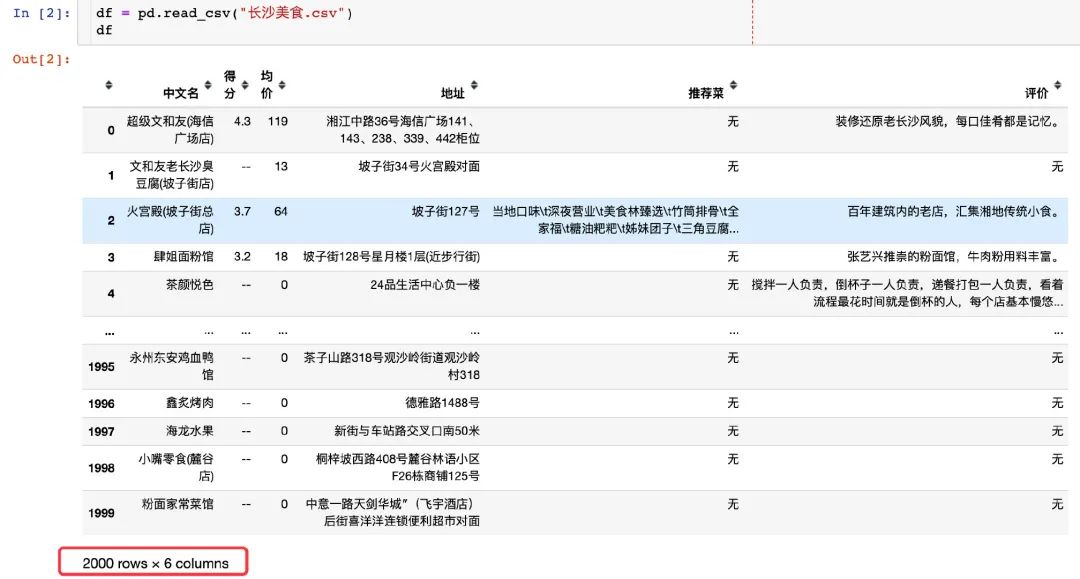
美食数据分析
前期处理
在进行数据分析之前,需要进行前期的处理:
df["得分"] = df["得分"].apply(lambda x: x.replace("--","0")) # 将得分中的--替换成0
改变两字字段的数据类型:

长沙到底有几家文和友?
1、文和友是长沙的知名老店,那获取到的数据中有几家和文和友相关的店?
数据显示:20家

看看前5家:

2、哪家文和友得分最高?
我们看看前5名:
fig = px.scatter(
wenheyou_score[:5],
x="中文名",
y="得分",
color="得分",
size="得分",
text="地址"
)
fig.update_traces(textposition="top center")
fig.show()
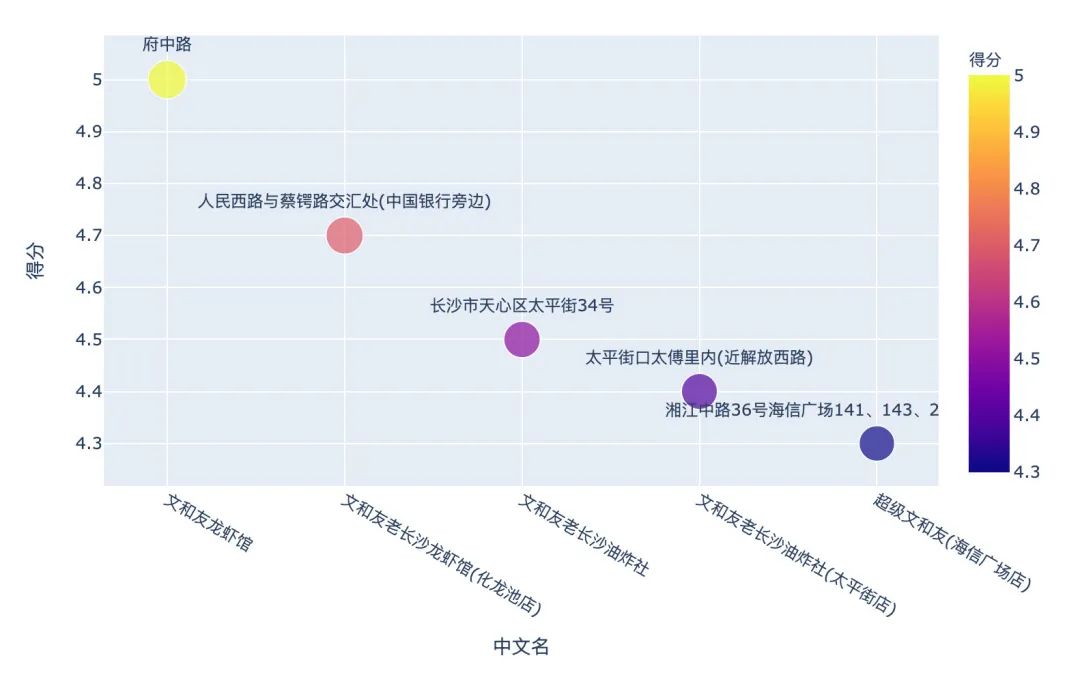
可以看到:府中路的这家店是评分最高的,网友给的评价是:
虾肉很新鲜,口感嫩滑,入味极佳,个人觉得不是很辣,但是如果对于吃辣程度一般的人来说,绝对足够了。
臭豆腐香不香?
1、看看数据中有臭豆腐店
数据显示有19家,我们看看前5家店

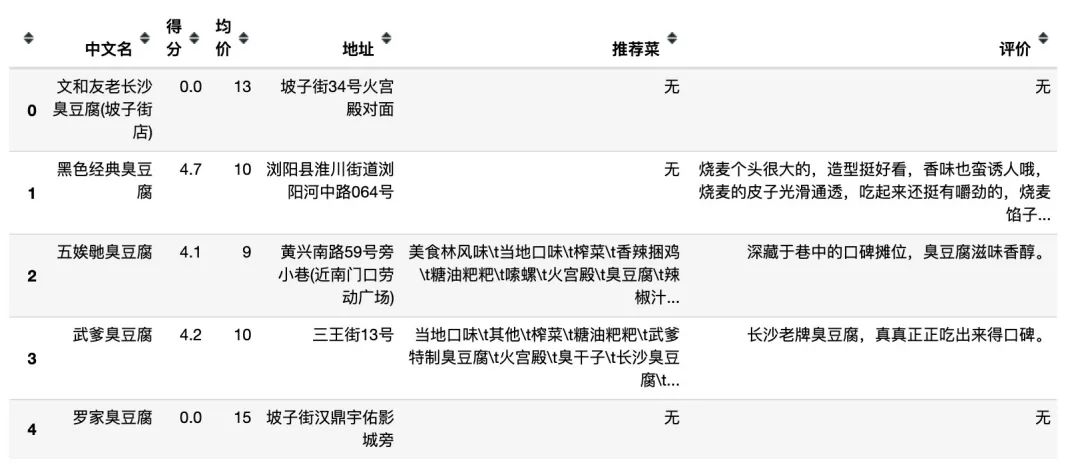
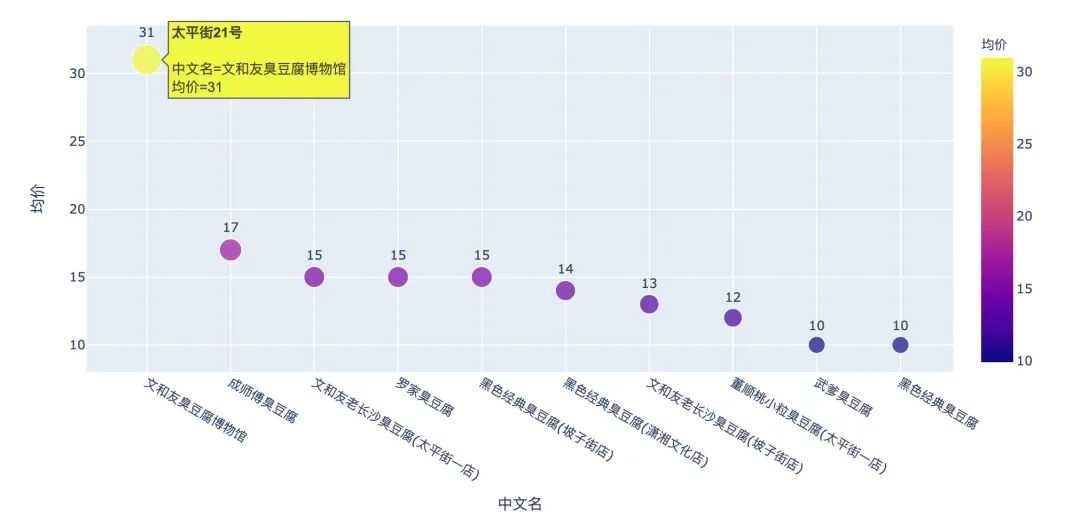
2、臭豆腐的价格如何?
太平街21号的一份臭豆腐31块?不知道香不香!!!
3、整体臭豆腐店的分布,基于得分和均价两个字段
px.scatter(choudoufou,x="得分",y="均价",color="中文名",size="均价") # 只筛选均价大于0

茶颜悦色好喝吗?
1、数据中几家茶颜悦色的店?
数据显示是10家,但是我想长沙肯定是不止10家!!!数据量还是太少了

2、茶颜悦色价格如何?
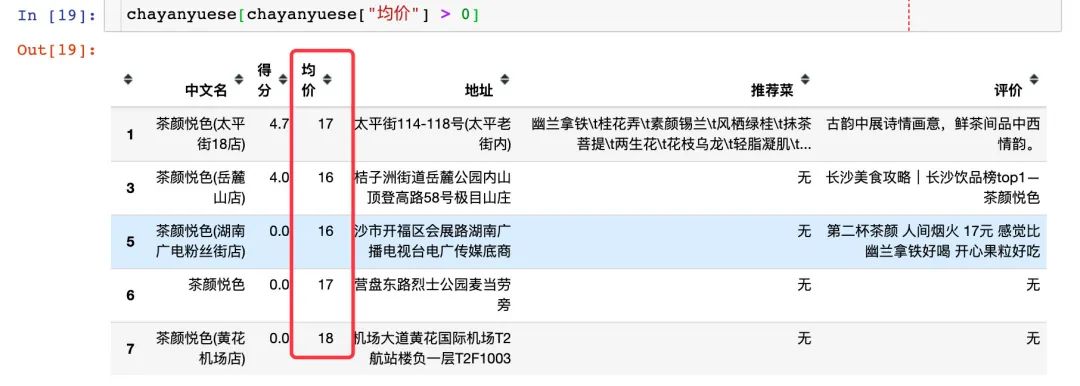
筛选出价格大于0的,我们:茶颜悦色的价格基本在17元左右
chayanyuese[chayanyuese["均价"] > 0]
湖南人爱嗦粉
湖南人非常喜欢吃粉,尤其是常德的米粉非常出名
1、看看数据中有几家粉店?
数据显示有103家!!!果然湖南人爱嗦粉

2、查看得分排名前10的粉店
mifen.sort_values("得分",ascending=False).head(10)
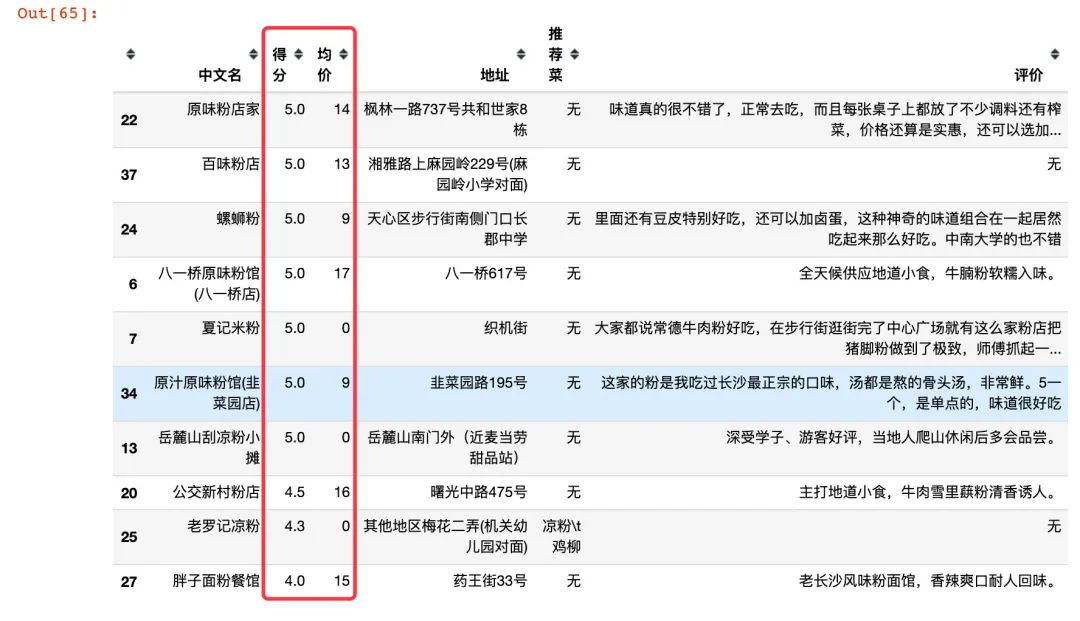
排名靠前的10位店价格基本上控制在14-15左右
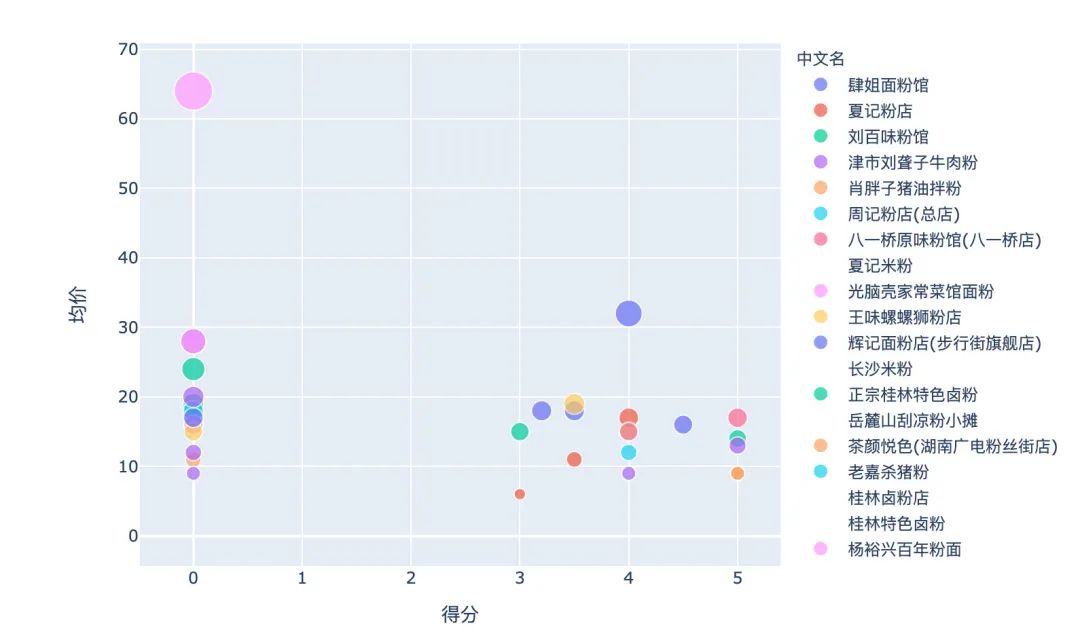
3、米粉店整体分布
px.scatter(mifen,x="得分",y="均价",color="中文名",size="均价")
4、店铺汇总
另外,查看数据发现,还有15家酒吧,28家火锅店,我们汇总下。数据量过少,仅供参考
doors = pd.DataFrame({
"数量":[19,18,9,103,15,28],
"名称":["文和友","臭豆腐","茶颜悦色","粉店","酒吧","火锅店"]
})
doors = doors.sort_values("数量",ascending=False)
c = (
Bar()
.add_xaxis(doors["名称"].tolist())
.add_yaxis("长沙店铺",doors["数量"].tolist())
.reversal_axis()
.set_series_opts(label_opts=opts.LabelOpts(is_show=True, position="right")) # 是否显示数据以及label的位置(显示在右方)
)
c.render_notebook()

网友推荐菜
对于网友的推荐菜,采用词云图展示:
# 1、选择推荐菜数据
rec = df[df["推荐菜"] != "无"].sort_values("得分",ascending=False).reset_index(drop=True)
rec_list = rec["推荐菜"].tolist()
# 2、jieba分词
rec_jieba_list = []
for i in range(len(rec_list)):
# jieba分词
seg_list = jieba.cut(str(rec_list[i]).strip(), cut_all=False)
for each in list(seg_list):
rec_jieba_list.append(each)
#3 3、通过pandas中的values来统计个数
rec_result = pd.value_counts(rec_jieba_list)[1::].to_frame().reset_index().rename(columns={"index":"词语",0:"次数"})
# 4、生成绘图数据
rec_words = [tuple(z) for z in zip(rec_result["词语"].tolist(), rec_result["次数"].tolist())]
rec_words[:3]
# 5、WordCloud模块绘图
c = (
WordCloud()
.add("", rec_words, word_size_range=[20, 100], shape=SymbolType.DIAMOND)
.set_global_opts(title_opts=opts.TitleOpts(title="长沙美食推荐菜词云"))
)
c.render_notebook()

总结
文章通过对两份数据获取和分析,数据量并不大,但还是想到长沙旅游的朋友几点建议:
1、橘子洲你应该去看看
从长沙景点数据分析中看出来,不管是整体排名、游客提供的攻略数、评论数,橘子洲都是排名第一的,可以在橘子洲大桥看烟火
2、五一广场真的很热门
五一广场整个片区很多吃喝玩乐的地方:太平老街、火宫殿、黄兴路步行街等,爱吃爱玩的你应该去
3、博物馆和遗址
如果喜欢历史,可以去湖南省博物馆、马王堆汉墓遗、长沙简牍博物馆址逛逛
4、不怕辣就吃龙虾
喜欢吃小龙虾的就去文和友吧,口味挺齐全的。推荐:海信广场店
5、一定要尝下湖南米粉
上面的数据已经显示了,大大小小的粉店在长沙太多了,到了长沙务必尝下,推荐:原味粉店家
一切看似逝去的,都不曾离开,你所给与的爱与温暖,让我执着地守护着这里。
------------------- End -------------------
往期精彩文章推荐:

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行
/今日留言主题/
随便说一两句吧~~