
Python如何计算编辑距离?
算法原理
大家好,欢迎来到 Crossin的编程教室 !
在计算文本的相似性时,经常会用到编辑距离。编辑距离,又称Levenshtein距离,是指两个字串之间,由一个转成另一个所需的最少编辑操作次数。通常来说,编辑距离越小,两个文本的相似性越大。这里的编辑操作主要包括三种:
插入:将一个字符插入某个字符串;
删除:将字符串中的某个字符删除;
替换:将字符串中的某个字符替换为另外一个字符。
下面通过示例来看一下。
将字符串batyu变为beauty,编辑距离是多少呢?这需要经过如下步骤:
1、batyu变为beatyu(插入字符e)
2、beatyu变为beaty(删除字符u)
3、beaty变为beauty(插入字符u)
所以编辑距离为3。
那么,如何用Python计算编辑距离呢?我们可以从较为简单的情况进行分析。
当两个字符串都为空串,那么编辑距离为0;
当其中一个字符串为空串时,那么编辑距离为另一个非空字符串的长度;
当两个字符串均为非空时(长度分别为 i 和 j ),取以下三种情况最小值即可:
1、长度分别为 i-1 和 j 的字符串的编辑距离已知,那么加1即可;
2、长度分别为 i 和 j-1 的字符串的编辑距离已知,那么加1即可;
3、长度分别为 i-1 和 j-1 的字符串的编辑距离已知,此时考虑两种情况,若第i个字符和第j个字符不同,那么加1即可;如果不同,那么不需要加1。
很明显,上述算法的思想即为动态规划。
求长度为m和n的字符串的编辑距离,首先定义函数——edit(i, j),它表示第一个长度为i的字符串与第二个长度为j的字符串之间的编辑距离。动态规划表达式可以写为:
if i == 0 且 j == 0,edit(i, j) = 0
if (i == 0 且 j > 0 )或者 (i > 0 且j == 0),edit(i, j) = i + j
if i ≥ 1 且 j ≥ 1 ,edit(i, j) == min{ edit(i-1, j) + 1, edit(i, j-1) + 1, edit(i-1, j-1) + d(i, j) },当第一个字符串的第i个字符不等于第二个字符串的第j个字符时,d(i, j) = 1;否则,d(i, j) = 0。
最终的编辑距离即为edit(m,n)。上述示例的edit矩阵可以表示如下:
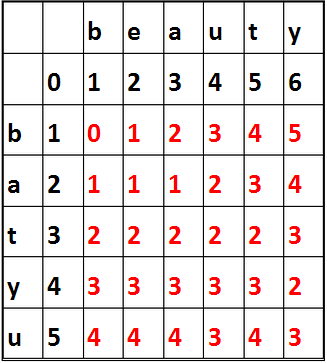
Python代码实现
Talk is cheap. Show me the code. Python代码也是极其简洁的,这也是动态规划的魅力:
def editdistance(str1, str2):
'''
计算字符串str1和str2的编辑距离
:param str1:
:param str2:
:return:
'''
edit = [[i + j for j in range(len(str2) + 1)] for i in range(len(str1) + 1)]
for i in xrange(1, len(str1) + 1):
for j in xrange(1, len(str2) + 1):
if str1[i - 1] == str2[j - 1]:
d = 0
else:
d = 1
edit[i][j] = min(edit[i - 1][j] + 1, edit[i][j - 1] + 1, edit[i - 1][j - 1] + d)
return edit[len(str1)][len(str2)]扩展
那么,Python功能这么强大,有没有计算编辑距离的包呢?
答案是肯定的,Python中的Levenshtein包可以用来计算编辑距离,安装方法很简单,直接安装即可:
pip install python-Levenshtein这样我们就可以引入包直接计算编辑距离了:
import Levenshtein
str1 = 'batyu'
str2 = 'beauty'
print Levenshtein.distance(str1, str2)有同学可能想计算汉字之间的编辑距离,如下:
import Levenshtein
str1 = 'Python那些事'
str2 = 'Python那些事!'
print Levenshtein.distance(str1, str2)得到的结果是3而不是1。这是因为在字符串编码为utf-8时,一个汉字占用3个字节。改为unicode编码即可得到1,即:
import Levenshtein
str1 = u'Python那些事'
str2 = u'Python那些事!'
print Levenshtein.distance(str1, str2)那么,Levenshtein包中还有没有其它计算距离的方法呢?
这个包有很多计算距离的方法,包括如下:
hamming(str1, str2),计算长度相等的字符串str1和str2的汉明距离,即为两个等长字串之间对应位置上不同字符的个数。
ratio(str1, str2),计算莱文斯坦比。计算公式 r = (sum – ldist) / sum, 其中sum是指str1 和 str2 字串的长度总和,ldist是类编辑距离。注意这里是类编辑距离,在类编辑距离中删除、插入依然+1,但是替换+2。
jaro(str1, str2),jaro_winkler(str1, str2)等等。
总结
可以用动态规划算法求解字符串的编辑距离。
PyPi包Levenshtein可以用来计算字符串的编辑距离,也可以计算其它类型的距离。
_往期文章推荐_