你准备把这些文件存储在硬盘上,并在需要的时候读取出来。要设计怎样的软件,才能更方便地在硬盘中读写这些文件呢?1
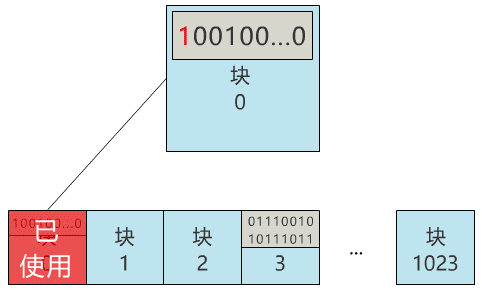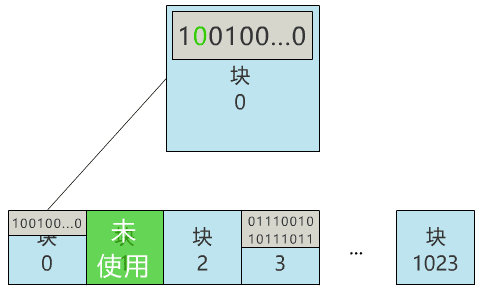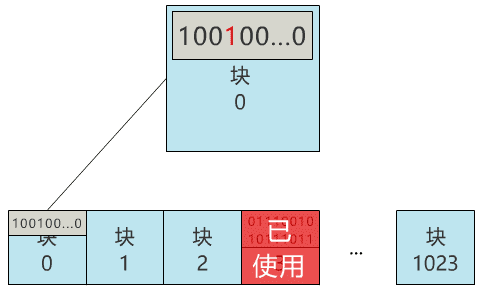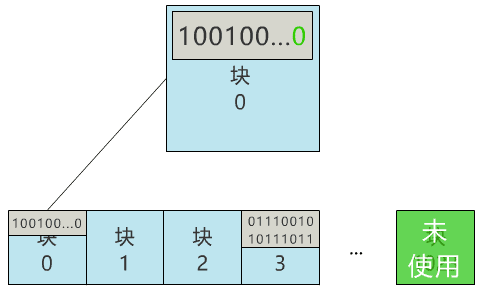
首先我不想和复杂的扇区,设备驱动等细节打交道,因此我先实现了一个简单的功能,将硬盘按逻辑分成一个个的块,并可以以块为单位进行读写。每个块就定义为两个物理扇区的大小,即 1024 字节,就是 1KB 啦。硬盘太大不好分析,我们就假设你的硬盘只有 1MB,那么这块硬盘则有 1024 个块。诶?发现问题了,万一这个文件也存到了 3 号块,不是把原来的文件覆盖了么?不行,得有一个地方记录,现在可使用的块有哪些,像这样。块 0:未使用
块 1:未使用
块 2:未使用
块 3:已使用
块 4:未使用
...
块 1023:未使用
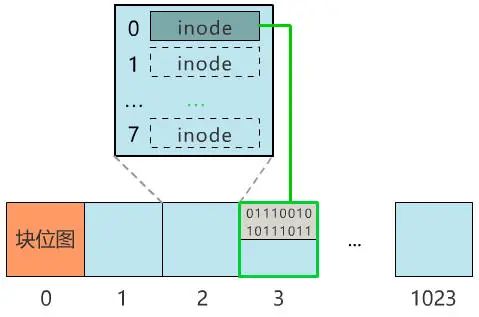
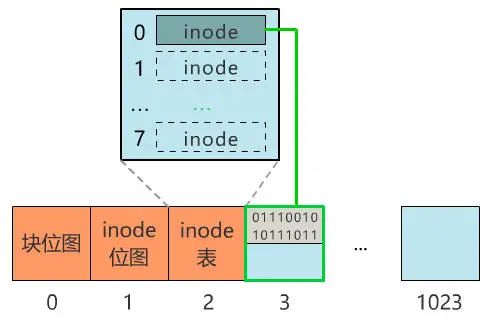
那我们就用 0 号块,来记录所有块的使用情况吧!怎么记录呢?那我们给块 0 起个名字,叫块位图,之后这个块 0 就专门用来记录所有块的使用情况,不再用来存具体文件了。当我们再存入一个新文件时,只需要在块位图中找到第一个为 0 的位,就可以找到第一个还未被使用的块,将文件存入。同时,别忘了把块位图中的相应位置 1。咦?又遇到问题了,我怎么找到刚刚的文件呢?根据块号么?这也太蠢了,就像你去书店找书,店员让你提供书的编号,而不是书名,显然不合理。因此我们给每个文件起一个名字,叫文件名,通过它来寻找这个文件。那必然就要有一个地方,记录文件名与块号的对应关系,像这样。葵花宝典.txt:3 号块
数学期末复习资料.mp4:5 号块
低并发编程的秘密.pdf:10 号块
...
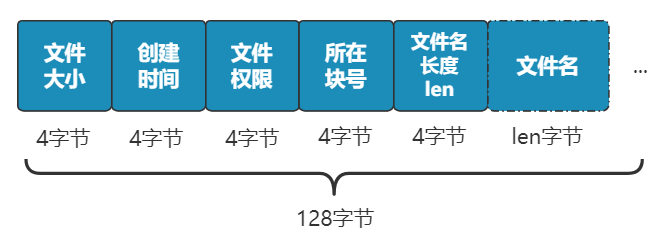
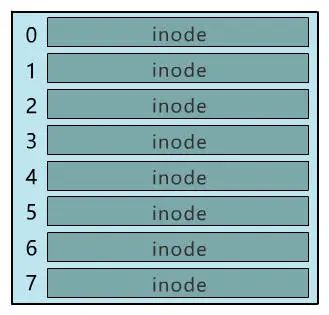
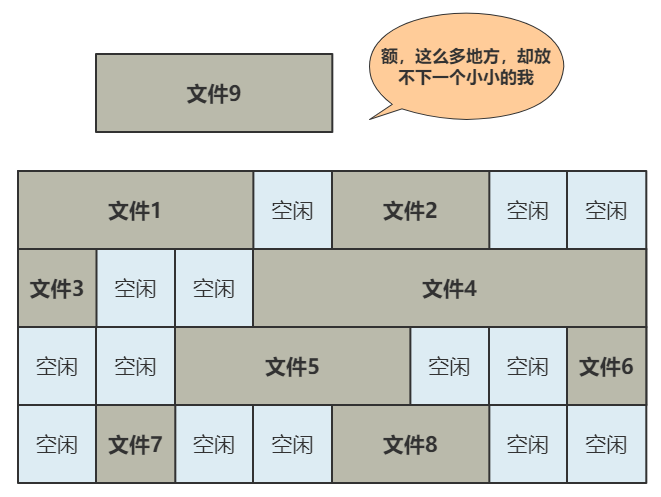
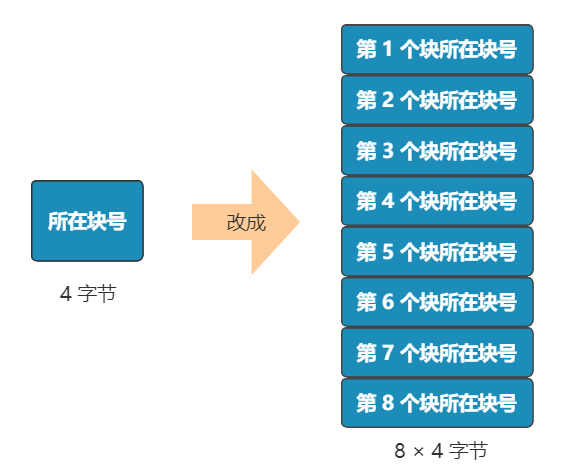
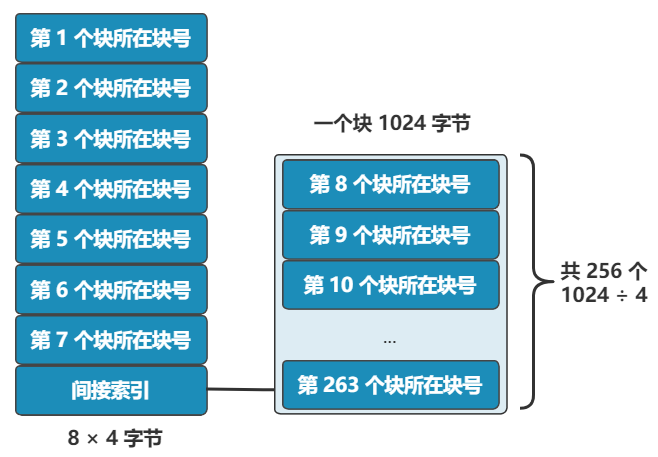
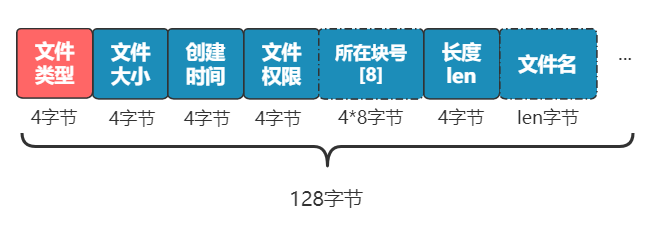
别急,既然都要选一个地方记录文件名称了,不妨多记录一点我们关心的信息吧,比如文件大小、文件创建时间、文件权限等。这些东西自然也要保存在硬盘上,我们选择用一个固定大小的空间,来表示这些信息,多大空间呢?128 字节吧。我们将这 128 字节的结构体,叫做一个 inode。之后,我们每存入一个新的文件,不但要占用一个块来存放这个文件本身,还要占用一个 inode 来存放文件的这些元信息,并且这个 inode 的所在块号这个字段,就指向这个文件所在的块号。如果一个 inode 为 128 字节,那么一个块就可以容纳 8 个 inode,我们可以将这些 inode 编上号。如果你觉得 inode 数不够,也可以用两个或者多个块来存放 inode 信息,但这样用于存放数据的块就少了,这就看你自己的平衡了。同样,和块位图管理块的使用情况一样,我们也需要一个 inode 位图,来管理 inode 的使用情况。我们就把 inode 位图,放在 1 号块吧!同时,我们把 inode 信息,放在 2 号块,一共存 8 条 inode,这样我们的 2 号块就叫做 inode 表。注意:块位图是管理可用的块,每一位代表一个块的使用与否。inode 位图管理的是一条一条的 inode,并不是 inode 所占用的块,比如上图中有 8 条 inode,则 inode 位图中就有 8 位是管理他们的使用与否。很简单,我们只需要采用连续存储法,而 inode 则只记录文件的第一个块,以及后面还需要多少块,即可。这种办法的缺点就是:容易留下大大小小的空洞,新的文件到来以后,难以找到合适的空白块,空间会被浪费。既然在 inode 中记录了文件所在的块号,为什么不扩展一下,多记录几块呢?原来在 inode 中只记录了一个块号,现在扩展一下,记录 8 个块号!而且这些块不需要连续。但是这也仅仅能表示 8 个块,能记录的最大文件是 8K(记住,一个块是 1K), 现在的文件轻松就超过这个限制了,这怎么办?这样瞬间就有 263 个块(多了 256 -1 个块)可用了,这种索引叫一级间接索引。如果还嫌不够,就再弄一个块做一级间接索引,或者做二级间接索引(二级间接索引则可以多出 256 * 256 - 1 个块)。我们的文件系统,暂且先只弄一个一级间接索引。硬盘一共才 1024 个块,一个文件 263 个块够大了。再大了不允许,就这么任性,爱用不用。好了,现在我们已经可以保存很大的文件了,并且可以通过文件名和文件大小,将它们准确读取出来啦!但我们得精益求精,我们再想想看这个文件系统有什么毛病。比如,inode 数量不够时,我们是怎么得知的呢?是不是需要在 inode 位图中找,找不到了才知道不够用了?要是有个全局的地方,来记录这一切,就好了,也方便随时调整,比如这样inode 数量
空闲 inode 数量
块数量
空闲块数量
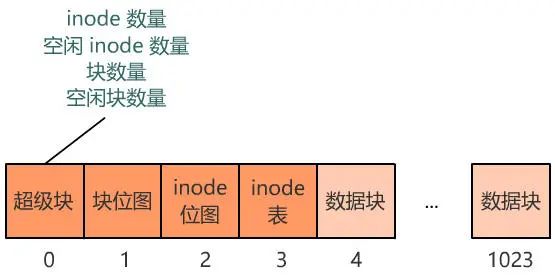
那我们就再占用一个块来存储这些数据吧!由于他们看起来像是站在上帝视角来描述这个文件系统的,所以我们把它放在最开始的块上,并把它叫做超级块,现在的布局如下。现在,块位图、inode 位图、inode 表,都是是固定地占据这块 1、块 2、块 3 这三个位置。假如之后 inode 的数量很多,使得 inode 表或者 inode 位图需要占据多个块,怎么办?或者,块的数量增多(硬盘本身大了,或者每个块变小了),块位图需要占据多个块,怎么办?程序是死的,你不告诉它哪个块表示什么,它可不会自己猜。很简单,与超级块记录信息一样,这些信息也选择一个块来记录,就不怕了。那我们就选择紧跟在超级块后面的 1 号块来记录这些信息吧,并把它称之为块描述符。当然,这些所在块号只是记录起始块号,块位图、inode 位图、inode 表分别都可以占用多个块。葵花宝典.txt
数学期末复习资料.mp4
赘婿1.mp4
赘婿2.mp4
赘婿3.mp4
赘婿4.mp4
低并发编程的秘密.pdf
诶?这看着好不爽,所有的文件都是平铺开的,能不能拥有层级关系呢?比如这样葵花宝典.txt
数学期末复习资料.mp4
赘婿
赘婿1.mp4
赘婿2.mp4
赘婿3.mp4
赘婿4.mp4
低并发编程的秘密.pdf
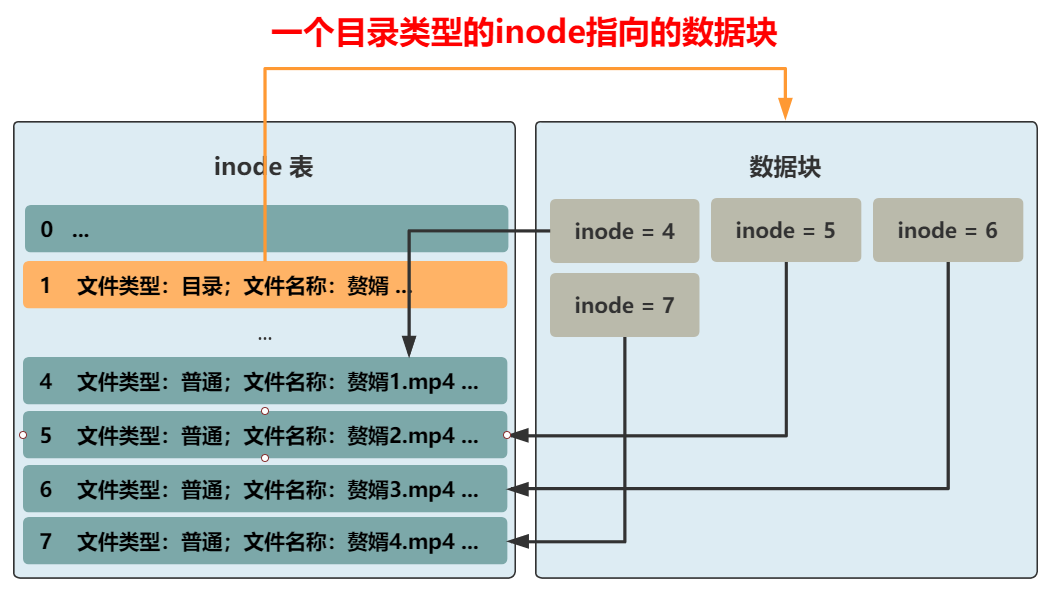
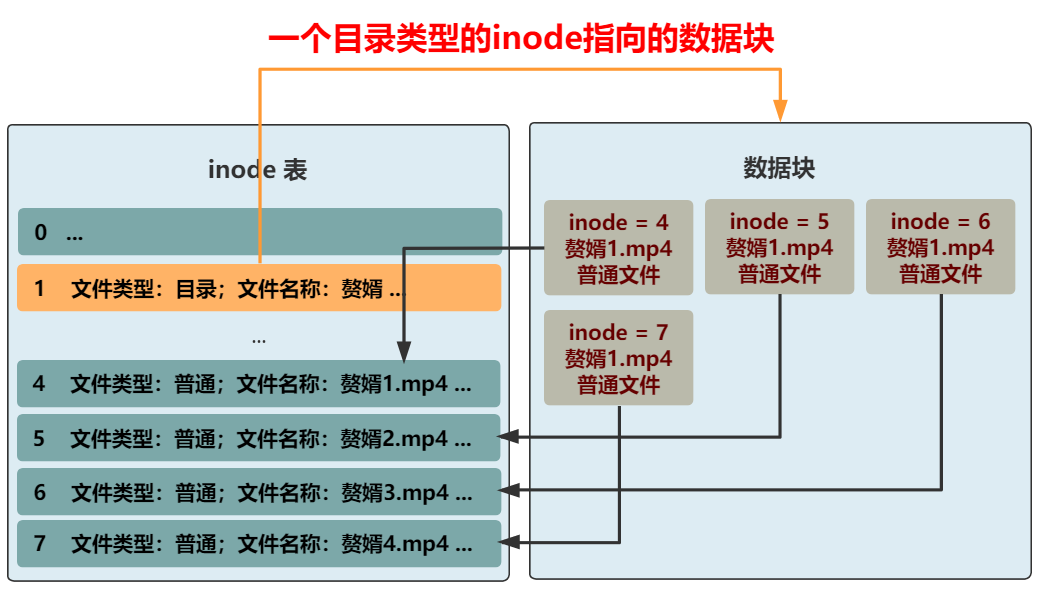
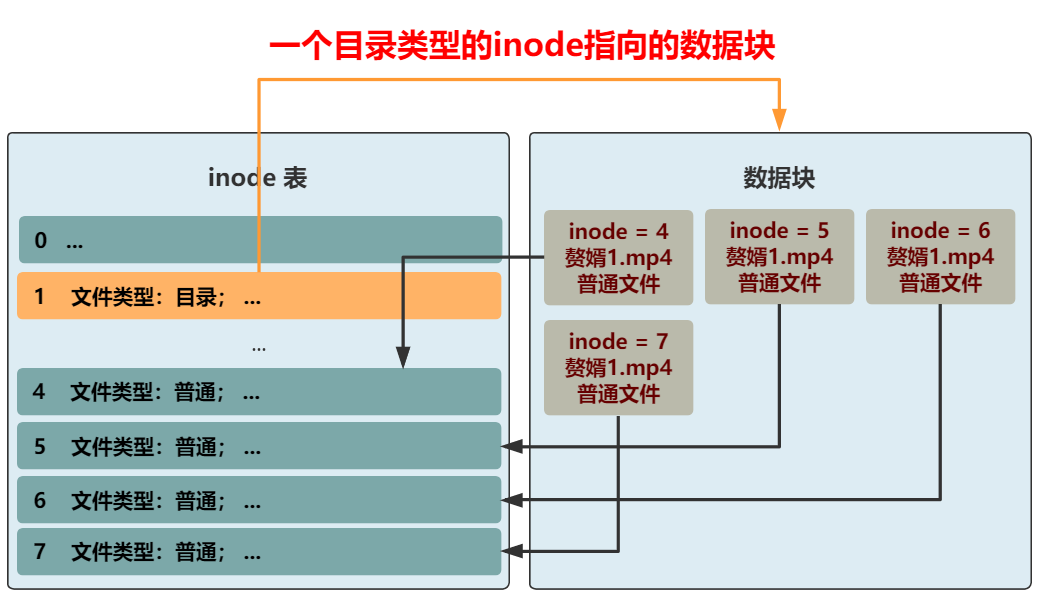
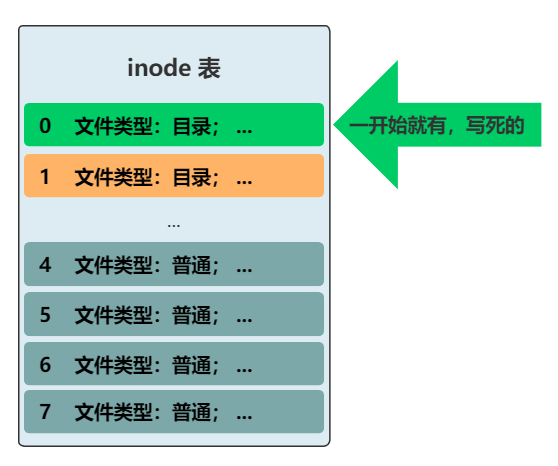
我们将葵花宝典.txt 这种称为普通文件,将赘婿这种称为目录文件,如果要访问赘婿1.mp4,那全文件名要写成如何做到这一点呢?那我们又得把 inode 结构拿出来说事了。此时需要一个属性来区分这个文件是普通文件,还是目录文件。缺什么就补什么嘛,我们已经很熟悉了,专门加一个 4 字节,来表示文件类型。如果是普通文件,则这个 inode 所指向的数据块仍然和之前一样,就是文件本身原封不动的内容。但如果是目录文件,则这个 inode 所指向的数据块,就需要重新规划了。这个数据块里应该是什么样子呢?可以是一个一个指向不同 inode 的紧挨着的结构体,比如这样。这样先通过 赘婿 这个目录文件,找到所在的数据块。再根据这个数据块里的一个个带有 inode 信息的结构体,找到这个目录下的所有文件。不过这样的话,你想想看,如果想要查看一下赘婿这个目录下的所有文件(比如 ll 命令),将文件名和文件类型都展示出来,怎么办呢?就需要把一个个结构体指向的 inode 从 inode 表中取出,再把文件名和文件类型取出,这很是浪费时间。而让用户看到一个目录下的所有文件,又是一个极其常见的操作。所以,不如把文件名和文件类型这种常见的信息,放在数据块中的结构体里吧。同时,inode 结构中的文件名,好像就没啥用了,这种变长的东西放在这种定长的结构中本身就很讨厌,早就想给它去掉了。而且还能给其他信息省下空间,比如文件所在块的数组,就能再多几个了。OK,大功告成,现在我们就可以给文件分门别类放进不同目录下了,还可以在目录下创建目录,无限套娃!现在的文件系统,已经比较完善了,只是还有一点不太爽。我们访问到一个目录下,可以很舒服地看到目录里的文件,然后再根据名称访问这个目录下的文件或者目录,整个过程都是一个套路。但是,最上层的目录下的所有文件,即根目录,现在仍然需要通过遍历所有的 inode 来获得,能不能和上面的套路统一呢?答案非常简单,我们规定,inode 表中的 0 号 inode,就表示根目录,一切的访问,就从这个根目录开始!这个文件系统,和 linux 上的经典文件系统 ext2 基本相同。
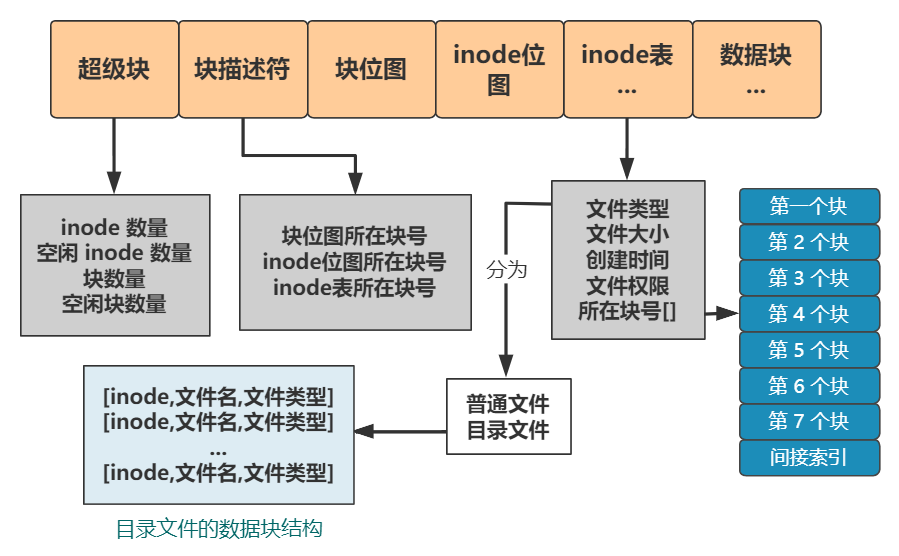
下面是我画的 ext2 文件系统的结构(字段部分只画了核心字段)
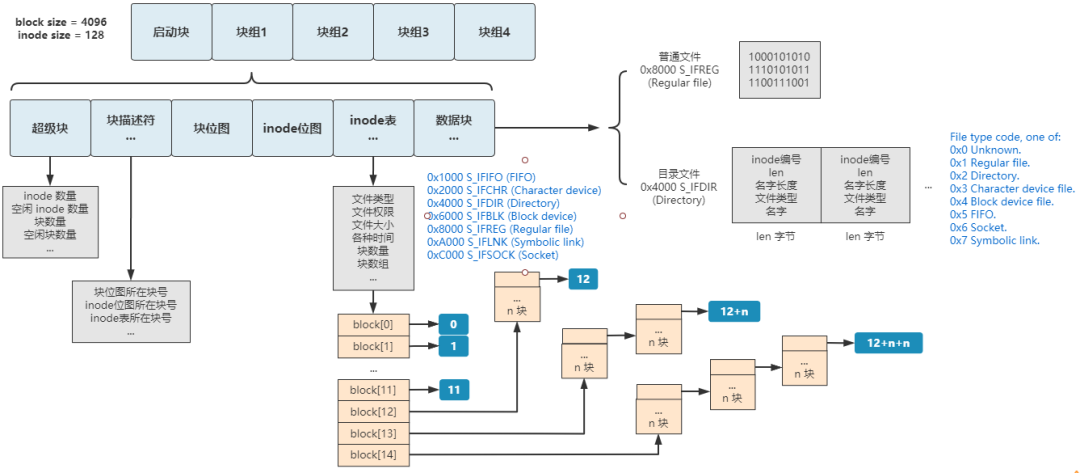
估计你是看不清了,我说下主要异同点:
1. 超级块前面是启动块,这个是 PC 联盟给硬盘规定的 1KB 专属空间,任何文件系统都不能用它。
2. ext2 文件系统首先将整个硬盘分为很多块组,但如果只有一个块组的话,和我们的文件系统整体结构就完全一样了,分别是超级块、块描述符、块位图、inode 位图、inode 表、数据块。
3. ext2 文件系统的 inode 表中用 15 个块来定位文件,其中第 13 个块为一级间接索引、14 个为二级间接索引、15 个为三级间接索引。
4. ext2 文件系统的文件类型分得更多,还有常见的如块设备文件、字符设备文件、管道文件、socket 文件等。
5. ext2 文件系统的超级块、块描述符、inode 表中记录的信息更多,但核心的和我们的文件系统一样,而且这些字段在后续的 ext3 和 ext4 中不断增加,保持向前兼容。
6. ext2 文件系统的 2 号 inode 为根目录,而我们的系统是 0 号 inode 为根目录,这个很随意,你设计一个文件系统定一个 187 号 inode 为根目录也没人拦着你。
如果你想了解 ext2 文件系统的全部细节,有三种方式。
1. 看源码,linux1.0 后的源码都有 ext2 文件系统的实现,源码是最准确的。2. 看官方文档,这里有个 pdf 连接。
https://www.nongnu.org/ext2-doc/ext2.pdf3. 看优质博客,这里我推荐一个。
http://docs.linuxtone.org/ebooks/C&CPP/c/ch29s02.html4. 用 linux 的 mke2fs 命令生成一个 ext2 文件系统的磁盘镜像,然后一个字节一个字节分析其格式,可以在公众号 低并发编程 回复 ext2 获得我的镜像分析文件。如果看源码和官方文档毫不吃力,我当然主推这两个,因为毕竟是一手资料。
但大多数人可能无法做到,有时也没大必要,因此也可以看一些优质的博客。
介绍思想的,我觉得我这一篇就算是很优质的一篇了,它会带你从设计者角度了解为什么这样来设计文件系统。
介绍细节的,那些连文件系统的格式和字段都写不对的,就别看了,所以我这里良心推荐一篇,就是上面的方式三,可以放心大胆,逐字逐句地食用。
最后你还可以用方式四,自己将文件系统镜像导出来,进行分析。
最近写这几篇文章,我感觉对如何学会一项新的技术,有了点小心得,不知道大家是否感兴趣,改天可以找一篇来专门和大家分享一下。