
基于 Kubernetes 的云原生 AI 平台建设
作者:
黄河 极视角科技技术合伙人
霍秉杰 KubeSphere 资深架构师 / KubeSphere 可观测性及 Serverless 产品负责人 / OpenFunction 发起人
人工智能与 Kubernetes
在国外众多知名网站 2021 年对 Kubernetes 的预测中,人工智能技术与 Kubernetes 的更好结合通常都名列其中。Kubernetes 以其良好的扩展和分布式特性,以及强大的调度能力成为运行 DL/ML 工作负载的理想平台。

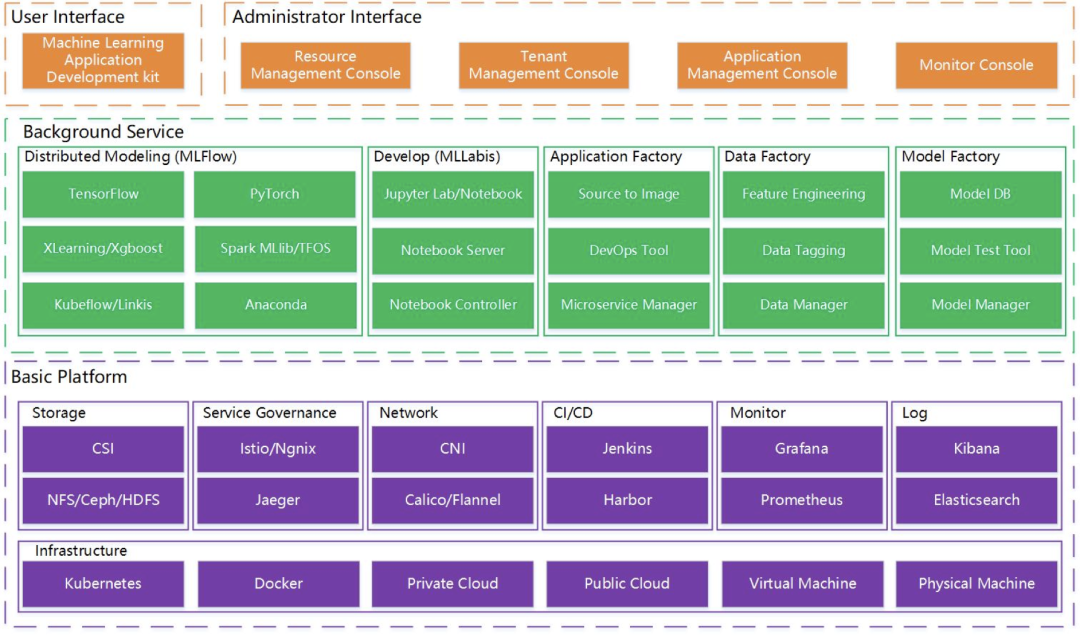
上面是微众银行开源的机器学习平台 Prophecis 的架构图,我们可以看到绿色的部分是机器学习平台通常都会有的功能包括训练、开发、模型、数据和应用的管理等功能。而通常这些机器学习平台都是运行在 Kubernetes 之上的,如紫色的部分所示:最底层是 Kubernetes,再往上是容器管理平台 (微众银行的开发者曾在 KubeSphere 2020 Meetup 北京站上提到这里采用的是 KubeSphere),容器管理平台在 Kubernetes 之上提供了存储、网络、服务治理、CI/CD、以及可观测性方面的能力。
Kubernetes 很强大,但通常在 Kubernetes 上运行 AI 的工作负载还需要更多非 K8s 原生能力的支持比如:
用户管理: 涉及多租户权限管理等 多集群管理 图形化 GPU 工作负载调度 GPU 监控 训练、推理日志管理 Kubernetes 事件与审计 告警与通知
具体来说 Kubernetes 并没有提供完善的用户管理能力,而这是一个企业级机器学习平台的刚需;同样原生的 Kubernetes 也并没有提供多集群管理的能力,而用户有众多 K8s 集群需要统一管理;运行 AI 工作负载需要用到 GPU,昂贵的 GPU 需要有更好的监控及调度才能提高 GPU 利用率并节省成本;AI 的训练需要很长时间才能完成,从几个小时到几天不等,通过容器平台提供的日志系统可以更容易地看到训练进度;容器平台事件管理可以帮助开发者更好地定位问题;容器平台审计管理可以更容易地获知谁对哪些资源做了什么操作,让用户对整个容器平台有深入的掌控。
总的来说,K8s 就像 Linux/Unix, 但用户仍然需要 Ubuntu 或 Mac 。KubeSphere 是企业级分布式多租户容器平台,本质上是一个现代的分布式操作系统。KubeSphere 在 Kubernetes 之上提供了丰富的平台能力如用户管理、多集群管理、可观测性、应用管理、微服务治理、CI/CD等。
如何利用 Kubernetes 和 KubeSphere 构建机器学习平台
极栈平台是一个面向企业或机构的机器学习服务平台,提供从数据处理、模型训练、模型测试到模型推理的 AI 全生命周期管理服务,致力于帮助企业或机构迅速构建 AI 算法开发与应用能力。平台提供低代码开发与自动化测试功能,支持任务智能调度与资源智能监控,帮助企业全面提升 AI 算法开发效率,降低 AI 算法应用与管理成本,快速实现智能化升级。
极栈 AI 平台迭代演变的挑战
在使用 Kubernetes 之前,平台使用 Docker 挂载指定 GPU 来分配算力,容器内置 Jupyter 在线 IDE 实现和开发者交互,开发者在分配的容器内完成训练测试代码编写、模型训练,当时存在四个问题需要解决:
算力利用率低:开发者在编码时,GPU 仅仅用于代码调试;同时开发者需手动开启或者关闭环境,如果开发者训练结束未关闭环境,将继续占用算力资源。以算法大赛的场景为例,算力利用率平均在 50%,算力资源浪费严重。 存储运维成本高:平台使用 Ceph 来存储数据集、代码,比如容器挂载了 Ceph 的块存储来持久化存储开发环境,方便再次使用时能在其他node还原。在大量开发者使用时,出现挂载卷释放不了、容器无法停止等问题,影响开发者使用。 数据集安全无法保障:商用算法数据集往往涉密,需要实现数据所有权和使用权分离,比如许多大型政企开发算法往往外包给专业的 AI 公司。怎么让外部 AI 公司的算法工程师在既能完成算法开发,又能不接触到数据集,是政企算法平台客户的迫切需求。 算法测试人力成本高:对于算法开发者提交的算法,要对精度和性能等指标进行评测,达到算法需求方要求的精度和性能指标后方可上线。还是以算法大赛的场景举例,一般的 AI 平台会提供训练数据集、测试数据集给到用户,用户完成算法开发后,用算法跑测试集,将结果写入到 CSV 文件里面和算法一起提交。对于获奖的开发者,我们要还原开发者测试环境,重新用开发者的算法来跑测试集,并和开发者提交的 CSV 结果对比,确定 CSV 文件没有被修改,保证比赛公平,这些都需要大量的测试人员参与,作为定位全栈 AI 开发的极栈平台来说,要在平台上开发万千算法,急需降低测试的人工成本。
为解决这些问题,2018 年中决定引入 Kubernetes 对平台进行重构,但当时团队没有精通 Kubernetes 的人员,Kubernetes 的学习成本也不低,重构进展受到一定影响;后来我们发现了由青云科技开源的容器管理平台 KubeSphere,它把很多 Kubernetes 底层细节都屏蔽了,用户只需要像用公有云一样,用可视化的方式使用,可以降低使用 Kubernetes 的成本。同时社区的维护团队也非常认真负责,最开始把 KubeSphere 部署到我们测试环境,集群运行一段时间会崩溃,开源社区的同学手把手帮助我们解决了问题,后来又陆续引入了 QingStor NeonSAN 来替代 Ceph,极大地提升了平台稳定性。

KubeSphere v3.0.0 支持了多集群管理、自定义监控,提供了完善的事件、审计查询及告警能力;KubeSphere v3.1.x 新增对 KubeEdge 边缘节点管理的功能、新增多维度计量计费的能力、重构了告警系统,提供了兼容 Prometheus 格式的告警设置、新增了包括企业微信/钉钉/邮件/Slack/Webhook 等众多通知渠道、同时对应用商店和 DevOps 也进行了重构;还在开发当中的 KubeSphere v3.2 将对运行 AI 工作负载提供更好的支持包括 GPU 工作负载调度、GPU 监控等;未来 KubeSphere v4.0.0 将升级为可插拔架构,前后端将都会获得可插拔的能力,基于此可以构建可插拔到 KubeSphere 的机器学习平台。

云原生 AI 平台实践
提高算力资源利用
GPU 虚拟化
首先针对开发者编码算力利用率低的情况,我们将编码和训练算力集群分开,同时使用 GPU 虚拟化技术来更好利用 GPU 算力,这方面市场上已经有成熟的解决方案。在技术调研之后,选择了腾讯云开源的 GPUManager 作为虚拟化解决方案。
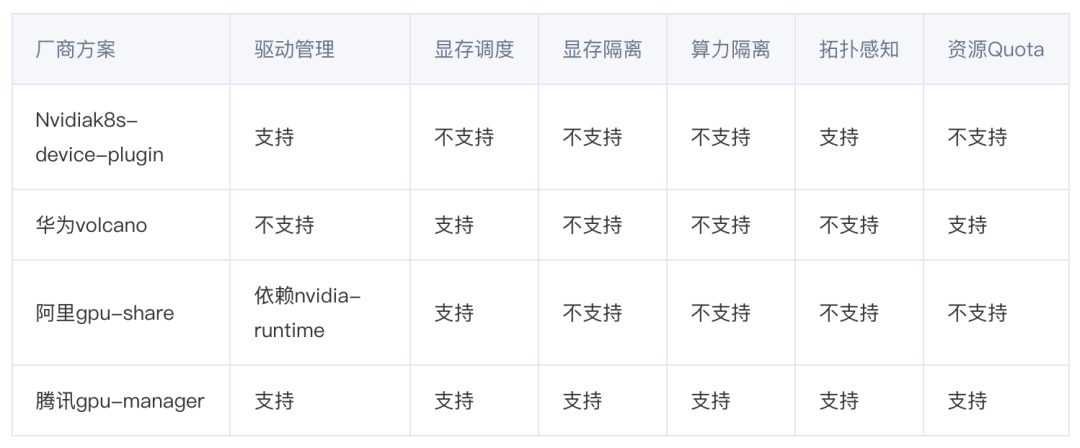
GPUManager 基于 GPU 驱动封装实现,用户需要对驱动的某些关键接口(如显存分配、cuda thread 创建等)进行封装劫持,在劫持过程中限制用户进程对计算资源的使用,整体方案较为轻量化、性能损耗小,自身只有 5% 的性能损耗,支持同一张卡上容器间 GPU 和显存使用隔离,保证了编码这种算力利用率不高的场景开发者可以共享 GPU,同时在同一块调试时资源不会被抢占。
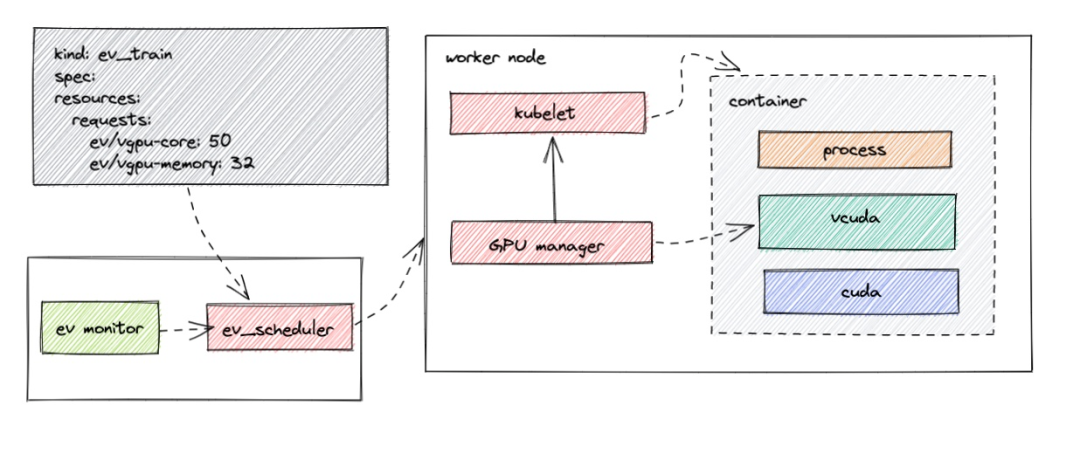
训练集群算力调度
在 Kubernetes 里面使用 Job 来创建训练任务,只需要指定需要使用的GPU资源,结合消息队列,训练集群算力资源利用率可以达到满载。
resources:
requests:
nvidia.com/gpu: 2
cpu: 8
memory: 16Gi
limits:
nvidia.com/gpu: 2
cpu: 8
memory: 16Gi
资源监控
资源监控对集群编码、训练优化有关键指导作用,KubeSphere 不仅能对 CPU 等传统资源监控,通过自定义监控面板,简单几个步骤配置,便可顺利完成可观察性监控,同时极栈平台也在 Kubernetes 基础上,按照项目等维度,可以限制每个项目 GPU 总的使用量和每个用户 GPU 资源分配。
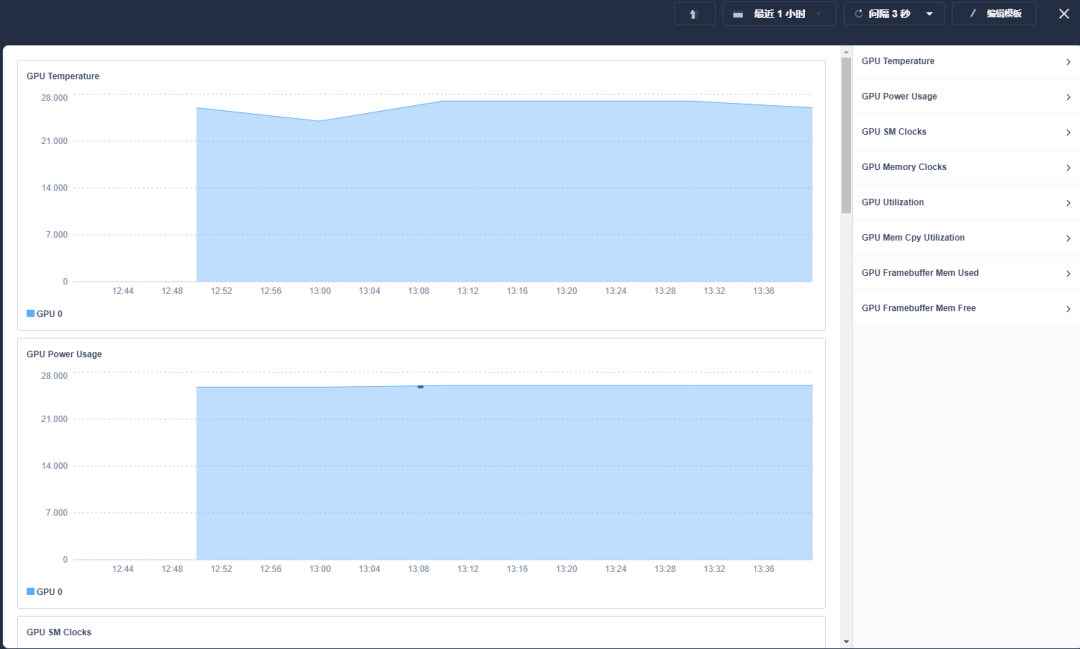
现在,比如算法大赛的场景,我们监控到的 GPU 平均使用率在编码集群达到了 70%,训练集群达到了 95%。
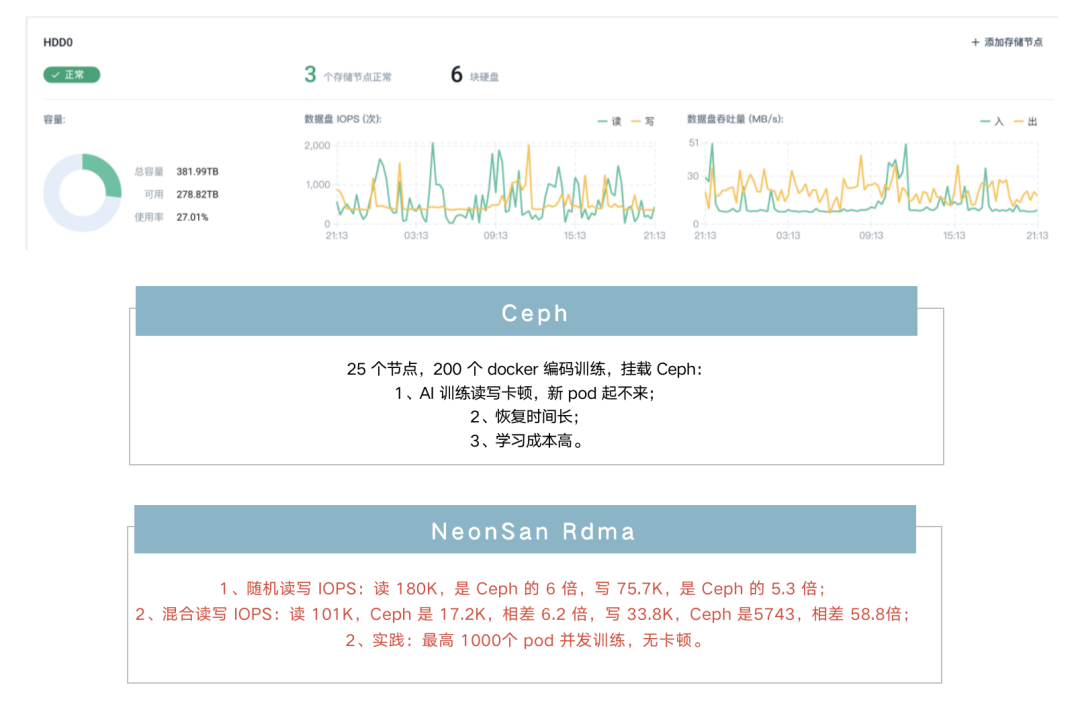
存储:QingStor NeonSan Rdma
我们采用 NVMe SSD+25GbE(RDMA)的 NeonSAN 来替换开源的 Ceph,NeonSAN 的表现很惊艳:比如随机读写的 IOPS,读达到了 180K,是 Ceph 的 6 倍,写也可以达到 75.7K,是Ceph 的 5.3倍,之后 AI 平台最高 1000 个 Pod 并发训练,没有再出现存储挂载卷释放不了引起的卡顿问题。
数据集安全
我们做了数据安全沙箱来解决数据集安全的问题,数据安全沙箱实现了在不泄漏数据的同时,又能让算法开发者基于客户数据训练模型和评估算法质量。
数据安全沙箱要解决两个问题:
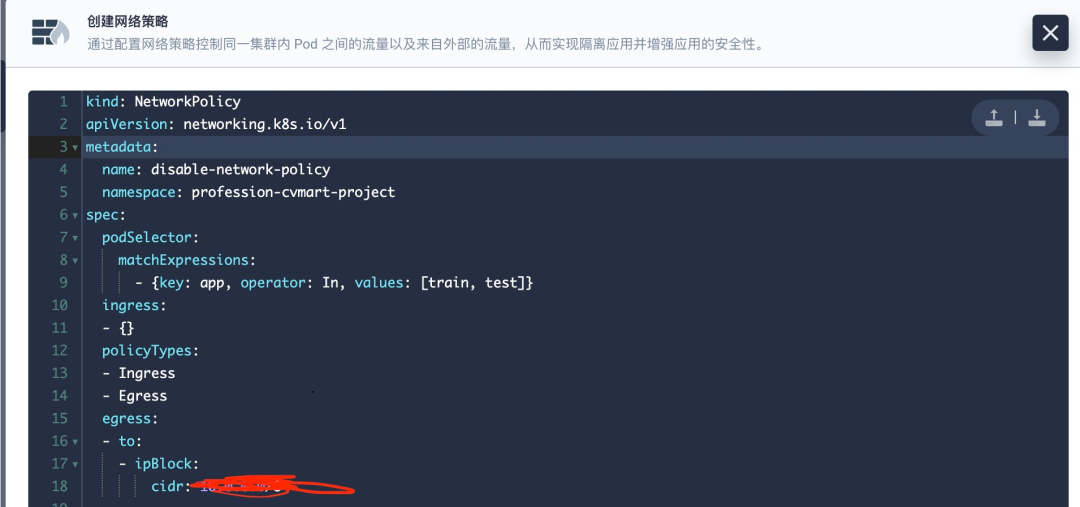
安全隔离问题:对外集群不能连通外网,把数据传出去;在平台内部,可以通过程序把数据传输到开发者能够访问的环境。比如在开发者可以控制的编码环境里面起个 http 服务接收训练集群传输过来的训练数据。KubeSphere 提供了基于租户的可视化网络安全策略管理,极大地降低了容器平台在网络层面的运维工作压力。通过网络策略,可以在同一集群内实现网络隔离,这意味着可以在 Pod 之间设置防火墙,如果多个策略选择了一个 Pod, 则该 Pod 受限于这些策略的入站(Ingress)/出站(Egress)规则的并集,它们不会冲突,所以这里只要设置一个限制访问外网的策略和禁止访问编码 Pod 的策略即可。
训练体验问题:隔离之后,开发者要能够实时知道训练和测试状态,训练和测试不能是一个黑箱,否则会极大影响模型训练和算法测试效率,如下图。
开发者发起训练或者测试,任务在算力集群里面跑了起来,EFK 收集和存储容器日志,针对不同数据集,可以设置不同等级的黑白名单过滤策略,防止图片数据转码成日志泄露出来,比如高安全性数据集直接设置白名单日志展示。 我们开发了 EV_toolkit 可视化工具包,来查看训练的指标如精度、损失函数(比如交叉熵)等,原理是训练指标通过 toolkit 的 API 接口写入到指定位置,再展示到界面上。 训练监控:支持无人值守训练,错误消息通知,训练进展定制化提醒,训练结束通知。 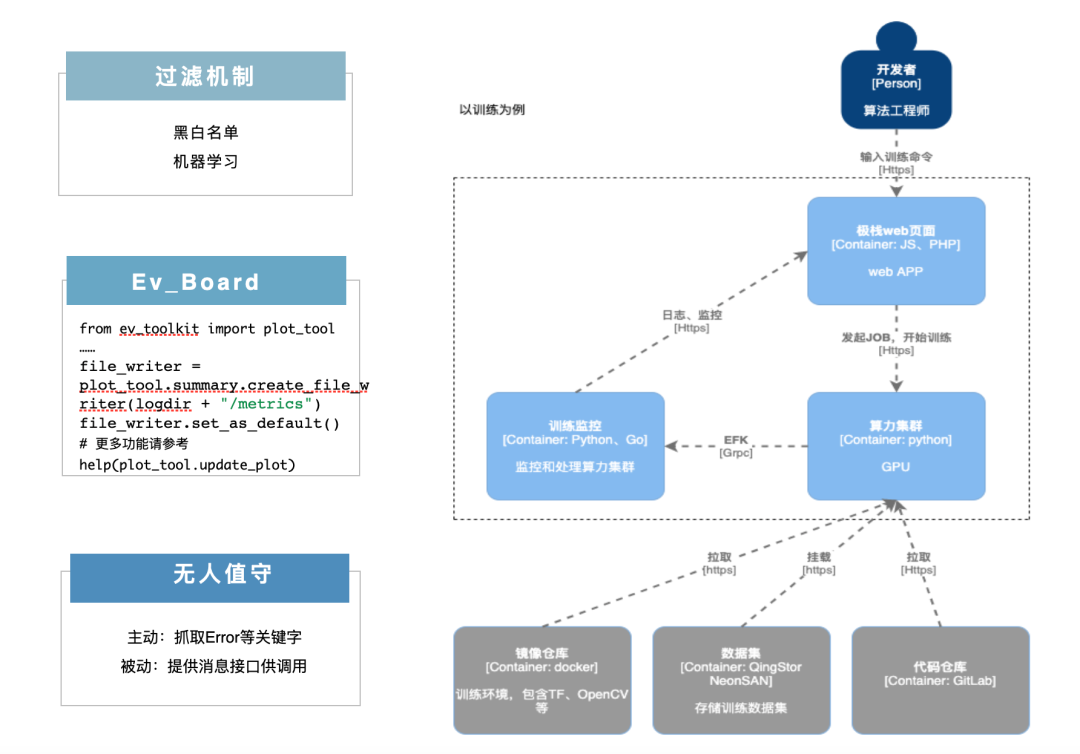
自动测试
要完成算法的自动测试需要解决 3 个问题:
各个算法框架开发出来的模型格式不统一,怎么规范化统一调用。 所有算法输入要统一、标准化。 客户对算法要求越来越高,算法输出的数据结构也越来越复杂,算法输出怎么跟数据标注的正确结果比对。
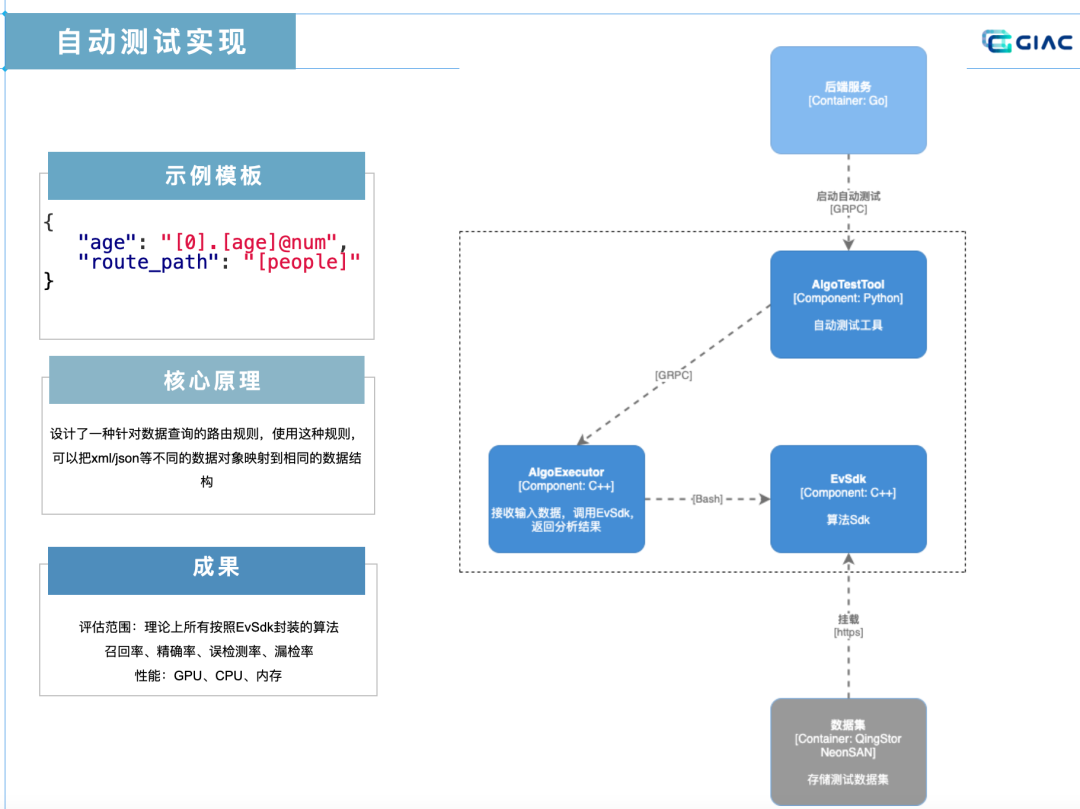
先来看看我们自研的推理框架 EvSdk,它解决了前两个问题,一是制定了算法统一封装标准,不同于其他 AI 平台针对单模型进行评估,极栈自动测试系统针对封装好的算法进行评估,因为随着算法越来越复杂,一个算法有多个模型的情况也越来越常见,只是对单模型进行评估并不能评估交付给客户的成品质量,另外对模型评估还要考虑各种开发框架模型格式兼容问题;二是 EVSdk 抽象出了算法输入接口,比如针对视频分析,第一个参数是创建的检测器实例,第二个参数是输入的源帧,第三个参数是可配置的 json,比如 roi、置信度等,通过 EVSdk 制定规范实现了算法输入的标准化。除了解决自动测试的两个问题,EVSdk 还提供工具包,比如算法授权,另外有了统一的推理框架,外面一层的算法工程化工作也可以标准化,由平台统一提供,以安装包形式安装进去,不用开发者来做了,比如处理视频流、算法对外提供 GRPC 服务等。
还要解决算法输出的问题,算法输出就是要找到输出 JSON 或者 XML 的节点里面的算法预测数据,找到之后和标注的正确数据做对比。自动测试系统引入了两个概念:
模版:定义了算法输出的数据结构,这个数据结构中包含若干个变量和如何从原始数据中获取到具体值的路由路径,根据模版解析原始数据之后,模版中的所有变量将被填充具体的值。 路由路径:一种针对数据查询的路由规则,使用这种规则可以把 xml / json 等不同的数据对象映射到相同的数据结构。对于不同来源或者不同结构的测试数据,就可以通过改变配置文件,得到相同数据结构的数据,从而可以对同一类型的任务使用同一个解析器来计算算法指标。
下图示例里面截取了一个模板里面最小单元,但足以说明自动测试原理。自动测试程序要在算法输出里找到年龄这个值,来和图片或视频标注的标签里面的年龄做对比。route_path 字段告诉系统有个根节点的 key 是 people,age 这个字段的 value 就是我们要找的路由路径了,[0] 代表了这是一个数组,这也很好理解,因为可以有多个人出现在一帧视频里面,. 代表了下一级,[] 里如果不是 0,比如 age 代表这是个对象,key 名叫做 age,@num 就是他的数据类型,至此程序就找到了 age 在算法输出的位置,找到后拿去和标注的正确数据作对比。当然有更复杂的评判标准,例如年龄误差在 3 岁以内系统认为算法分析结果是正确的。
极栈平台现状
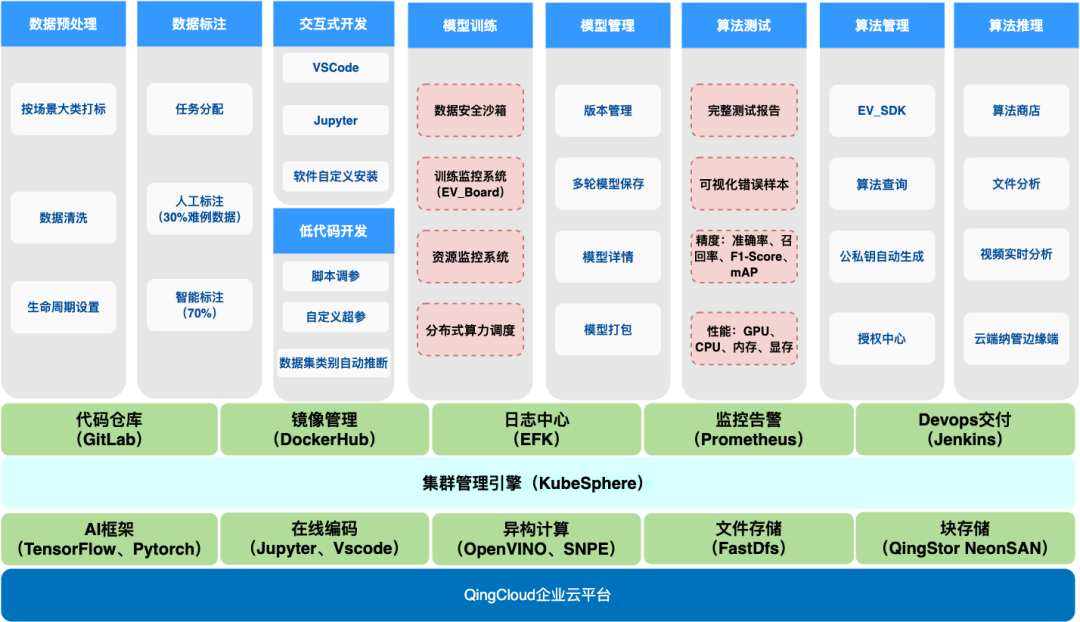
PaaS 层用 KubeSphere 作为底座打造了三个平台:数据平台,开发平台,推理平台。采集到原始数据之后对数据大类进行打标,再用算法对数据进行去重,以及把低质量数据去除掉等初筛工作,人工再进行筛选。因为 AI 训练数据量非常大,我们还支持对数据生命周期进行设置,比如根据数据重要性进行保存,然后到数据标注,标注是非常占用时间的工作,需要做任务的分配和对标注人员做绩效管理,通过再训练的模型进行自动标注和人工调整标注。数据标注好之后流转到开发平台,开发平台支持两种开发模式,一是交互式开发,二是低代码的开发。最后算法生产出来之后上架到推理平台的算法商店,推理平台的客户端可以部署到用户侧,用户只需要输入激活码就可以安装算法,然后分析本地实时视频流或图片。
极栈平台未来展望
计算机视觉算法和其他软件不同在哪里呢,比如说 KubeSphere,给我们用的产品和给另外公司用的是一致的。但是对于算法来说,在 A 客户那里效果很好,到 B 客户摄像头距离远一些、角度不同,或者是检测物体多了个颜色,效果就不达标了,要重新采集数据来训练模型。算法可复制性不强,难以标准化、产品化。对于解决通用场景的问题,每提高一个百分点识别率需要的算力和数据成本要翻倍,所以目前业界总共花了百亿成本才让人脸识别达到产品化,针对万千算法,如何大规模可复用,这是我们要攻克的难题。
既然适配通用场景非常难,回到现实场景中来,我们真的需要不断去优化一个算法适配所有用户的场景吗?对于每个用户来说,他真正关心的是算法在他自己场景下的算法效果。而在实践中,对于新场景,我们会将新场景数据集加入到训练集里面,对算法进行再训练来解决。如果系统能够实现不让算法工程师介入再训练过程,而是由客户通过简单的操作来完成,就解决了这个问题。
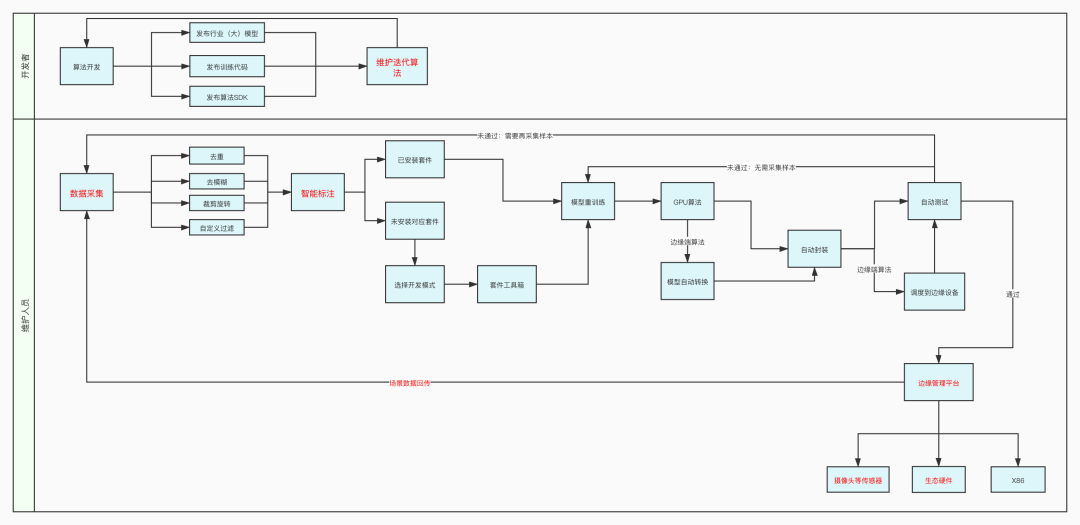
我们下一步会开发行业低代码套件,算法开发者在平台内只需开发算法和维护算法在行业的领先性,用户拿自己场景数据来标注,训练模型,适配自己的场景,无需任何编码工作,就可以完成算法优化,优化效果不达标的场景,再由开发者介入。模型优化的工作如果无法避免,放到用户侧,算法就相当于用户喂养的宠物,这其实会重新定义用户和算法之间的关系,只有这样走,算法才能产品化,万千场景才能打开。
Serverless 在 AI 领域的应用
上面详细阐述了 Kubernetes 在 AI 的应用实践,其实 AI 也需要 Serverless 技术,具体来说 AI 的数据、训练、推理等都可以同 Serverless 技术相结合而获得更高的效率并降低成本:
AI 离不开数据,以 Serverless 的方式处理数据成本更低。 可以通过定时或者事件触发 Serverless 工作负载的方式进行 AI 训练以及时释放昂贵的 GPU。 训练好的模型可以用 Serverless 的方式提供服务。 AI 推理结果可以通过事件的方式触发 Serverless 函数进行后续的处理。
Serverless 是云原生领域不容错失的赛道,以此为出发点,青云科技开源了云原生 FaaS 平台 ——OpenFunction。
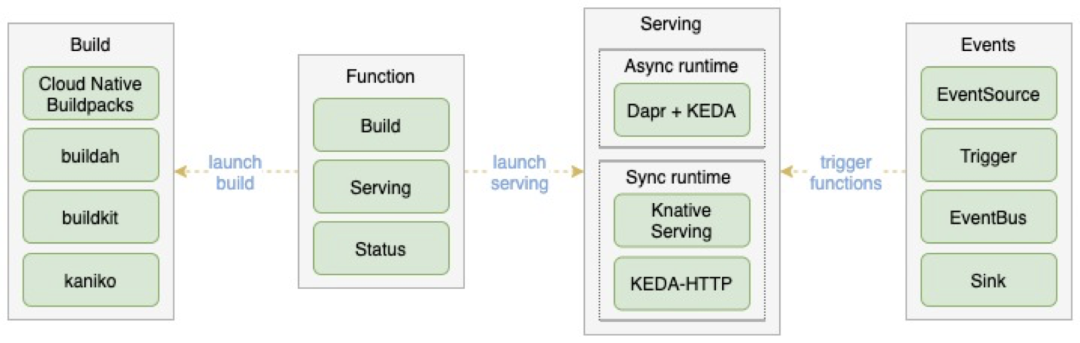
FaaS 平台主要包含 Build、Serving 及 Events 几个部分。其中 Build 负责将函数代码转换成函数镜像;Serving 部分负责基于生成的函数镜像提供可伸缩的函数服务;Events 部分负责对接外部事件源并驱动函数运行。
Kubernetes 已经启用 Docker 作为默认的 container runtime,从此不能在 K8s 集群里用 Docker in Docker 的方式 用 docker build 去 build 镜像,需要有别的选择。OpenFunction 现在默认支持 Cloud Native Buildpacks ,后面还将陆续支持 buildah、 buildkit、 kaniko 等。
Dapr 是微软开源的分布式应用程序运行时,提供了运行分布式应用程序需要的一些通用基础能力。OpenFunction 也把 Dapr 应用到了 OpenFunction 的 Serving 和 Events 里。
函数服务最重要的是 0 与 N 副本之间的自动伸缩,对于同步函数,OpenFunction 支持 Knative Serving 作为同步函数运行时,后面还计划支持 KEDA-HTTP ; 对于异步函数来说,OpenFunction 结合 Dapr 与 KEDA 开发了名为 OpenFunction Async 的异步函数运行时。
函数的事件管理我们调研了 Knative Eventing 之后觉得它虽然设计的比较好,但是有点过于复杂,不易学习和使用;Argo Events 架构虽然简单了许多,但并不是专为 Serverless 而设计,并且要求所有事件都必须发往它的事件总线 EventBus。基于以上调研,我们自己开发了函数事件管理框架 OpenFunction Events。
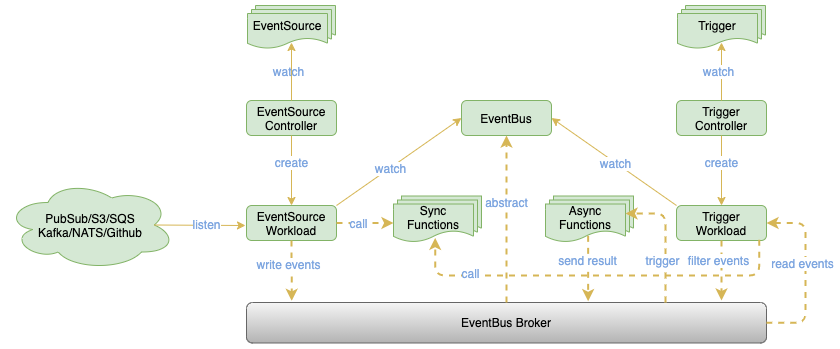
OpenFunction Events 充分利用了 Dapr 的能力去对接众多事件源、对接更多的 MQ 去作为 EventBus ,包含 EventSource、EventBus 和 Trigger 几个组件:
EventSource:用于对接众多外部事件源如 Kafka、NATS、 PubSub、S3、GitHub 等。在获取到事件之后,EventSource 可以直接调用同步函数进行处理,也可以将事件发往 EventBus 进行持久化,进而触发同步或者异步函数。 EventBus:利用 Dapr 能够以可插拔的方式对接众多消息队列如 Kafka、NATS 等。 Trigger:从 EventBus 中获取事件,进行过滤选出关心的事件后,可以直接触发同步函数,也可以将过滤出的事件发往 EventBus 触发异步函数。
Serverless 除了可以应用到上述 AI 领域之外,还可以应用到诸如 IoT 设备数据处理、流式数据处理、Web/移动终端后端 API backend (Backend for Frontend) 等领域。
OpenFunction 已经在 GitHub 开源,主要仓库包括:OpenFunction[1],functions-framework[2],builder[3],samples[4]
也欢迎大家到 KubeSphere 和 OpenFunction 社区的中文 Slack 频道[5]交流。
脚注
OpenFunction: https://github.com/OpenFunction/OpenFunction
[2]functions-framework: https://github.com/OpenFunction/functions-framework
[3]builder: https://github.com/OpenFunction/builder
[4]samples: https://github.com/OpenFunction/samples
[5]中文 Slack 频道: https://kubesphere.slack.com/archives/CBJ1A2UCB