
vertex shader中怎么获取临近顶点的属性值?
在知乎上看到这么个问题,挺感兴趣的,正好有大佬的高赞回答,和大家分享一些。
作者:无材补天的梧桐 原文链接是:
https://www.zhihu.com/question/516695017/answer/2356701024
以下的回复原文:
先说问题的答案,没办法获取:
能提出这样的问题,想必你对渲染管线在硬件上具体的实现细节很感兴趣,那我就简单介绍一下每类shader在并行性上的一些特点吧。
老死不相往来的vertex shader
我们先知道一个前提,无论是顶点也好、几何着色器对应的图元也好、光栅化后的片元也好、还是自己开辟的线程也好,以NVIDIA GPU为例,它们都是以32个为单位,称为一个warp。
GPU在接收到drawcall指令的时候,所有的顶点会根据其索引被Primitive Distributor拆分为每组最多32个顶点的batch,然后再发往运算单元SM,执行顶点着色器的代码。
每个线程映射的对象是一个顶点,每32个线程虽然锁步执行顶点着色器里的指令,它们彼此无法通信。
四人一组的fragment shader
那为什么fragment shader就能和邻居打交道呢,这是为了硬件能通过算梯度以计算mipmap层级,这是一个很重要的刚需,因此迫不得已支持的。这样的支持是需要付出代价的:
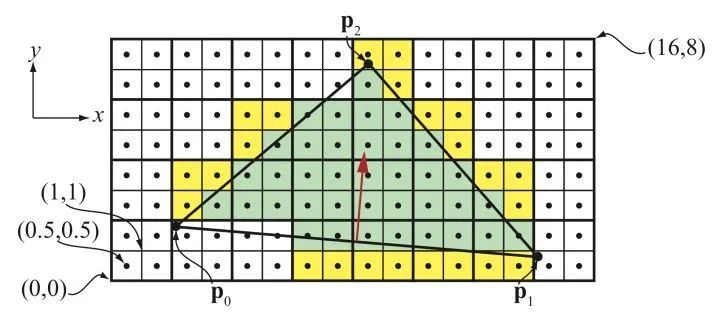
在三角形被光栅化成片元后,每四个相邻的片元组成一个小组,共八个这样的小组,总共32线程被捆绑成一个warp。是的,为了算ddx,ddy,就得确保有邻居,没有邻居也给你无中生有一个(图中黄色的片元),这就是代价。
很可能只有一个片元被三角形覆盖,为了支持这么一套机制,有三个不被三角形覆盖的片元被拖下了水(被迫占用三个线程,占着茅坑不拉屎)。而顶点着色器,目前没有这么刚需的需求值得显卡厂商去为此付出代价。
放飞自我的geometry shader
可是,如果我就想拿到同一个三角形的其他顶点怎么办?行吧,API制定者们搞出了一个几何着色器,一个线程对应一个图元(三角形),你可以拿到所有顶点,你还可以输出多个顶点。既实现了需求,也避免了为了这个并非刚需的需求,拖累了顶点着色器的大好前程。
本质上,图元与图元之间是并行的,但是几何着色器内部每个线程负责多个顶点的输出却是串行的,且数量不确定,这就埋下了效率低下的种子。实际上,显卡厂商们虽然不情不愿地支持了几何着色器,效率始终不尽人意。
未来可期的mesh shader
这样缝缝补补也没意思啊,而且这条饱经沧桑的管线也有一些其无法解决的硬伤。既然如此,英伟达大手一挥,给你们一个新玩具——mesh shader,直接让前面几何阶段的所有着色器(顶点、细分、几何)下岗。
怎么样才能又自由又高效呢?答案是,让你们程序员自己玩。mesh shader就是这么一个玩意儿,每个线程要映射什么玩意儿,程序员自己决定,线程组要怎么开也是程序员说了算。反正每一个线程组给我一堆顶点和索引就行(但这个数量是有限制的,不会有几何着色器那样的悲剧)。
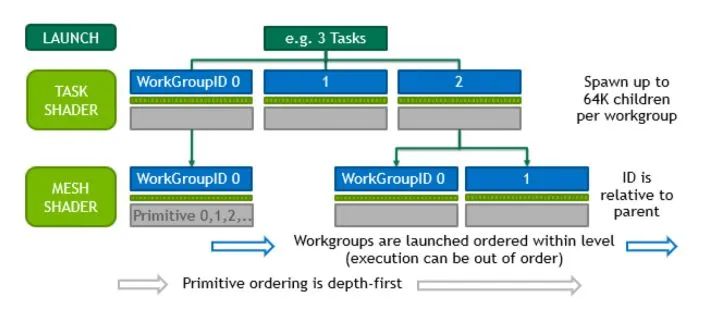
这种让程序员维护线程组的方式,同以往的以线程为单位强行映射到顶点或图元有明显不同,是协作式的,更像compute shader,未来整条光栅化图形管线可以预见的会更加“通用化”,越来越像通用管线。
无拘无束的compute shader
说完图形管线,最后再简单谈谈通用管线吧。计算着色器从一开始就十分自由,同一个线程组内的数据可以访问同一块数据(共享内存),不过可能需要同步(因为一个线程组可以包含多个warp);更新的硬件特性还支持shuffle操作,直接在线程间传递数据。
正因为计算着色器从一开始就对程序员充分授权,让使用者自负盈亏,所以并不像图形管线那样拧巴:又要让图形中的固定操作尽可能高效;又要支持越来越多的意料之外的“需求”。
限于篇幅,很多概念只是蜻蜓点水,可能会有“懂的都懂,不懂的不明觉厉”的感觉。如果真想深刻地理解这些shader的工作原理,下面的专栏可能会对你有所帮助:
https://www.zhihu.com/column/c_1351502583832354816
推荐阅读:
觉得不错,点个在看呗~
