
别去送死了!爬虫使用 Selenium 与 Puppeteer 能被网站探测的几十个特征

很多人喜欢使用 Selenium 或 Puppeteer(Pyppeteer) 通过模拟浏览器来编写爬虫,自以为这样可以不被网站检测到,想爬什么数据就爬什么数据
但实际上,Selenium 启动的浏览器,有几十个特征可以被网站通过 JavaScript 探测到;Puppeteer 启动的浏览器,也有很多特征能够被网站探测
如果你不相信,那么我们来做一个实验。首先你使用正常的浏览器打开如下网址:https://bot.sannysoft.com/
可以看到,页面的内容如下:
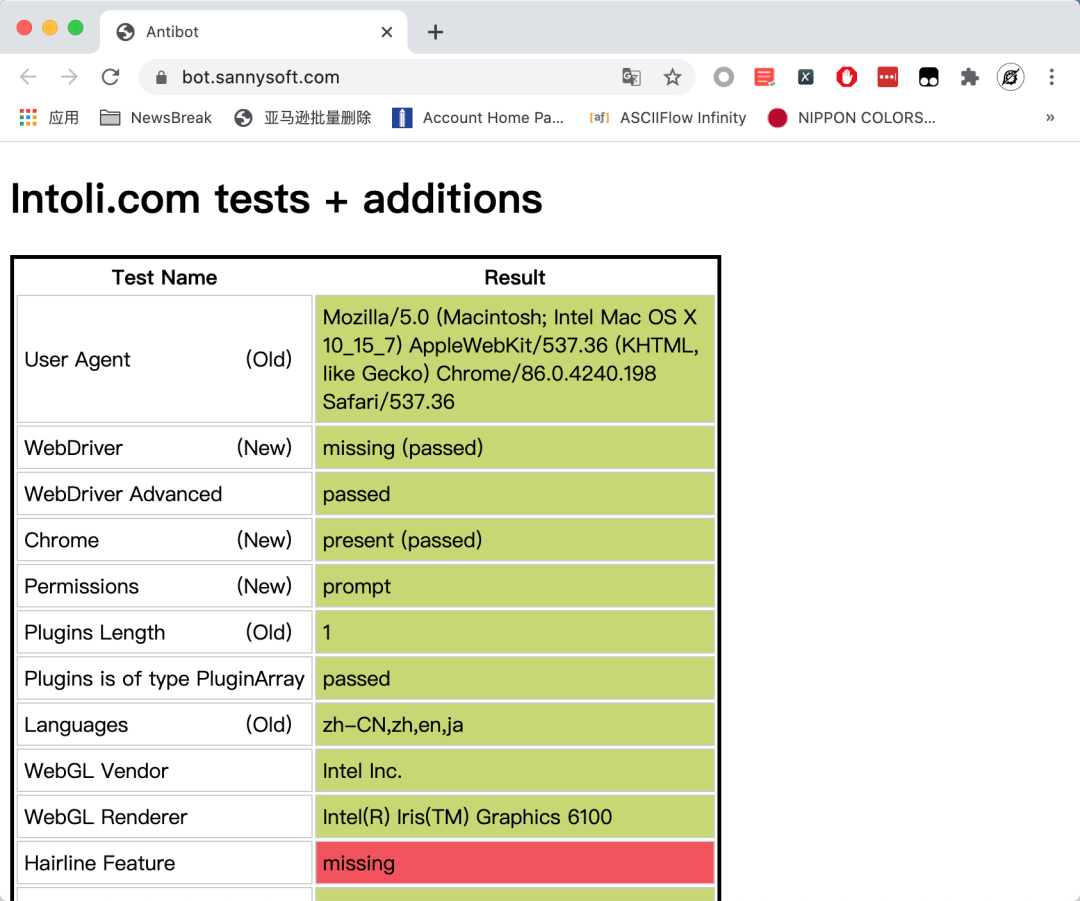
这个页面很长,你得滚动鼠标往下看,大部分都是绿色的
接下来,使用 Selenium启动一个 Chrome 的有头模式,再打开这个页面看看效果:
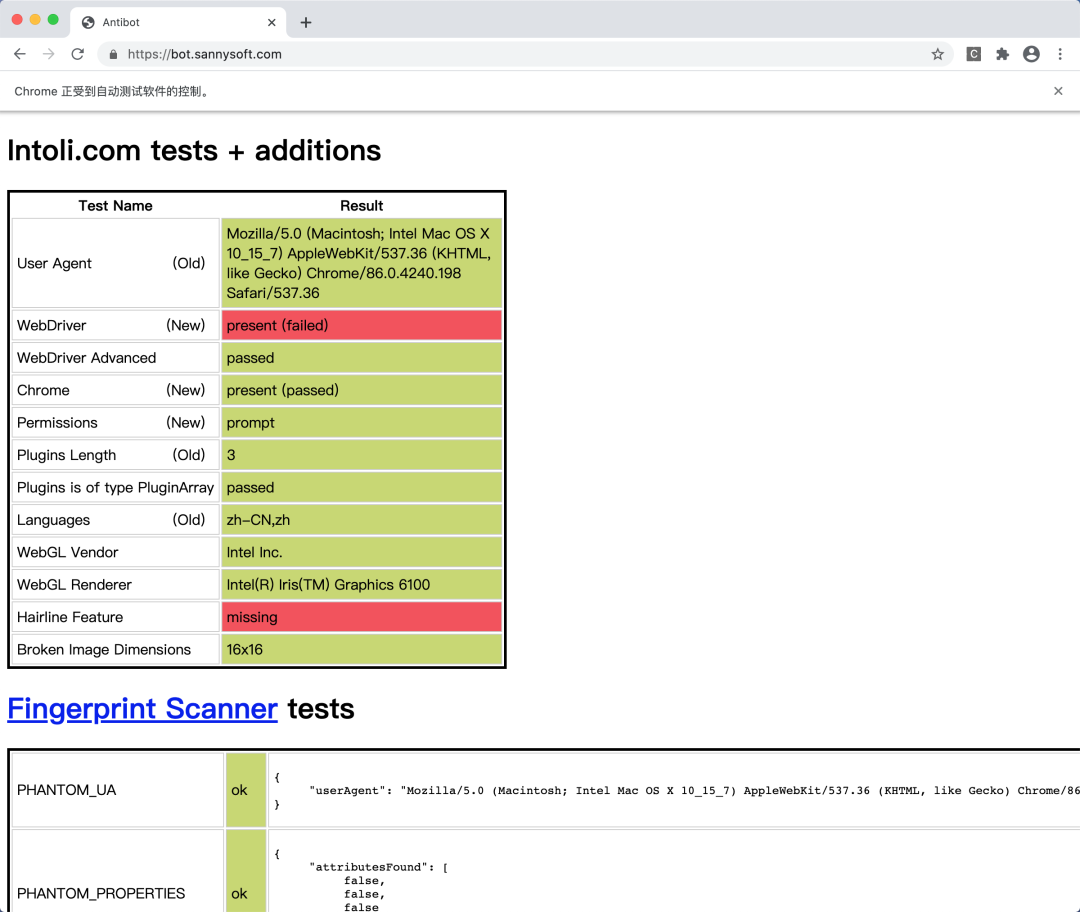
一开始 WebDriver这一项就标红了,说明网站成功检测到你使用模拟浏览器了
你再往下翻,标红的都是可以被检测出的特征

左边是普通浏览器,右边是模拟浏览器
如果你一项一项对比,就会发现很多地方都不一样
这还是有头模式的效果。我们来看看无头模式:
from selenium.webdriver import Chrome
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument("--headless")
driver = Chrome('./chromedriver', options=chrome_options)
driver.get('https://bot.sannysoft.com/')
driver.save_screenshot('screenshot.png')
截图打开以后是下面这样的。不要吓到:
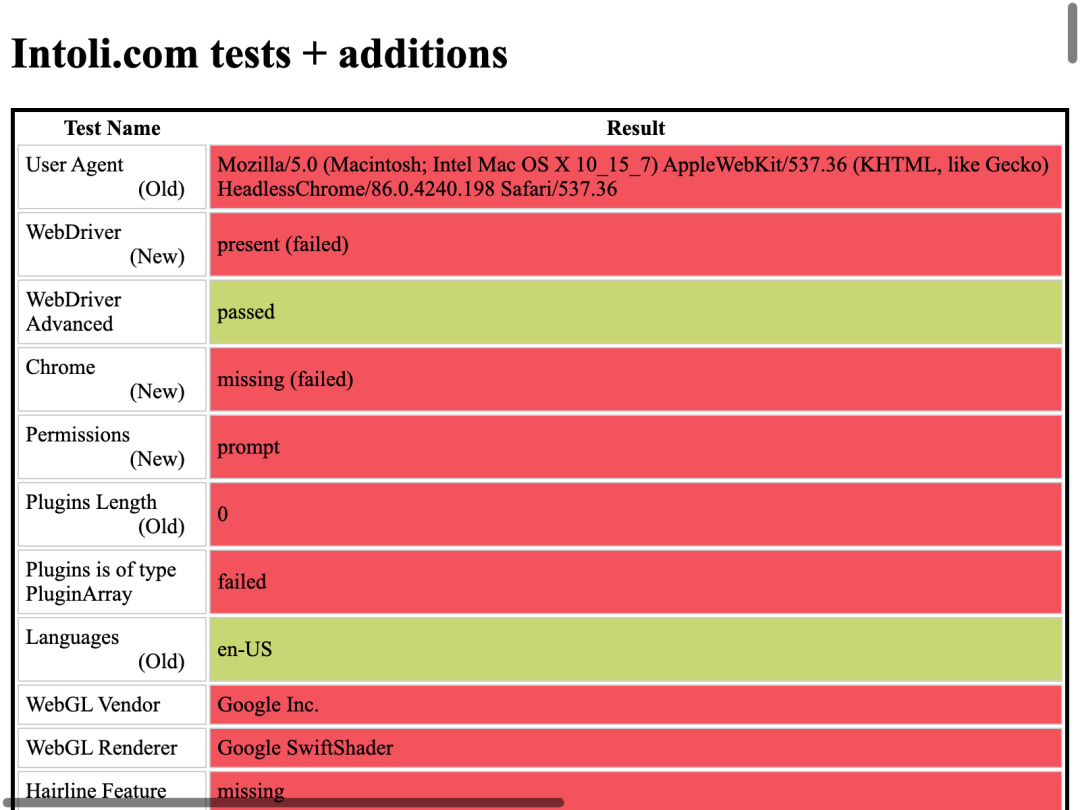
这么多特征都直接暴露了,你还隐藏个屁。网站只要想发现你,非常容易。
既然 Selenium 不行,那 Puppeteer 或者 Pyppeteer怎么样呢?
我们使用 Pyppeteer 来做个实验,直接启动无头模式并截图
运行效果是下面这样的:
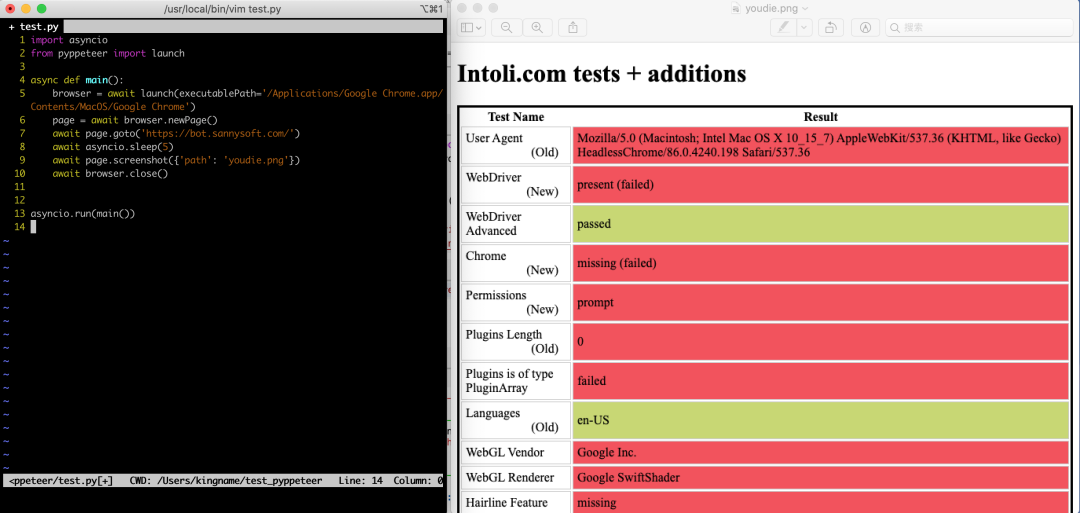
跟 Selenium 没什么区别
所以,你还好意思继续用这两个东西来写爬虫?
爬点没有安全意识的小网站可以,爬那些有强大安全团队和法务团队的公司,你就是在找死!
评论