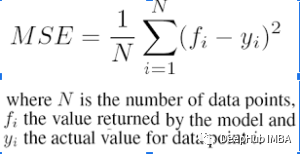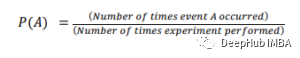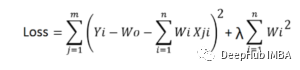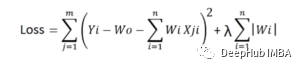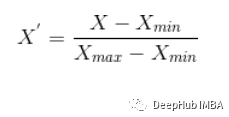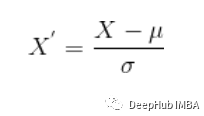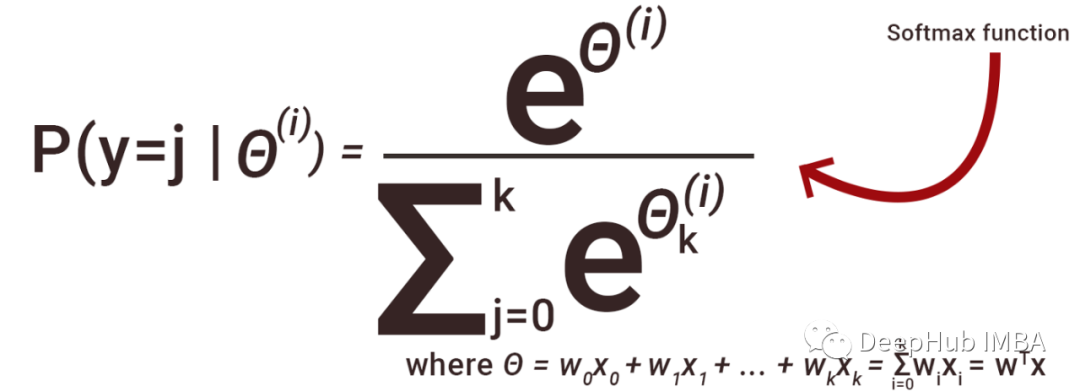本文为你介绍数据科学的基础知识和数据分析的相关问题。
来自Amazon,google,Meta, Microsoft等的面试问题,问题很多,所以对问题进行了分类整理,本文包含基础知识和数据分析相关问题。基础知识
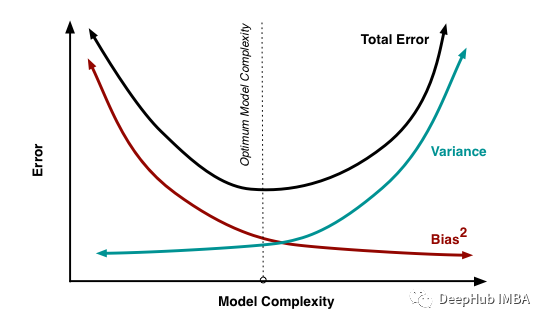
1. 什么是数据科学?列出监督学习和非监督学习的区别。数据科学是各种工具、算法和机器学习方法的混合,其目标是从原始数据中发现隐藏的模式。这与统计学家多年来一直在做的事情相似但是有什么不同?下图解释了数据分析和数据科学的区别:有监督学习:输入数据是有标记的,主要用于预测。例如分类和回归等;无监督学习:输入数据是没有标记的,多用于分析。密度估计和降维等。选择性偏差溯源英文为Selection Bias,指的是在研究过程中因样本选择的非随机性而导致得到的结论存在偏差,也称选择性偏差为选择性效应(Selection Effect)。它是由于采集样本的方法造成的统计分析的失真。如果没有考虑到选择偏差,那么研究的一些结论可能不准确。选择性偏差是指这样一种认知倾向:人们喜欢把事物分为典型的几个类别,然后在对事件进行概率估计时,过分强调这种典型类别的重要性,而不顾有关其他潜在可能性的证据。选择性偏差的后果势必使人们倾向于在实际上是随机的数据序列中“洞察”到某种模式,从而造成系统性的预测偏差。偏差:偏差是由于机器学习算法过于简化而在模型中引入的错误。它会导致不适应。当你在那个时候训练你的模型时,模型会简化假设,使目标函数更容易理解。低偏差机器学习算法有:决策树,k-NN和SVM,高偏差机器学习算法有:线性回归,逻辑回归。方差:方差是由于复杂的机器学习算法在模型中引入的误差,模型会从训练数据集学习噪声,在测试数据集上表现很差。它会导致高灵敏度和过拟合。通常,当增加模型的复杂性时,会看到由于模型中较低的偏差而导致的误差的减少。然而,这种情况只会在特定的点发生。当模型变得更复杂时,最终会过度拟合型,因此你的模型将开始变为i高方差。任何监督机器学习算法的目标都是具有低偏差和低方差,才能达到良好的预测性能。在机器学习中,偏见和方差之间的关系不可避免。增加偏差会减少方差。增加方差会减少偏差。for i in range(1,51):print(i)
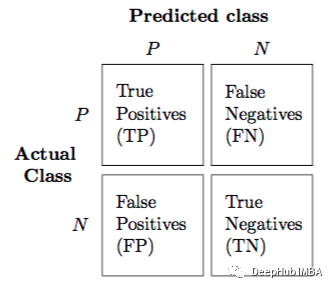
混淆矩阵是一个2X2表,包含由二分类器提供的4个输出。错误率、准确率、精确度、查全(召回)率等指标都由它来衡量。混淆矩阵:用于性能评估的数据集称为测试数据集。它应该包含正确的标签和预测的标签。但实际上模型预测的标签通常与现实场景中部分观察到的标签相匹配。分类器预测测试数据集的所有数据实例为正或负。这产生了四种结果:- 敏感度(Sensitivity真阳性率)= TP/P;
- 特异度(Specificity真阴性率)= TN/N;
- F-Score(精度和查全率的调和平均值)= (1+b)(PREC.REC)/(b²PREC+REC),其中b通常为0.5,1,2。
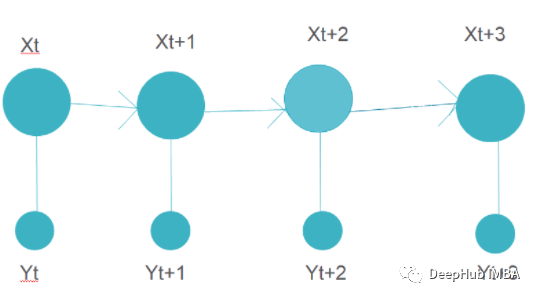
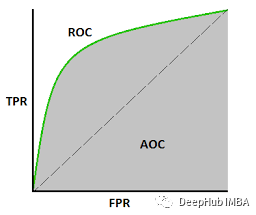
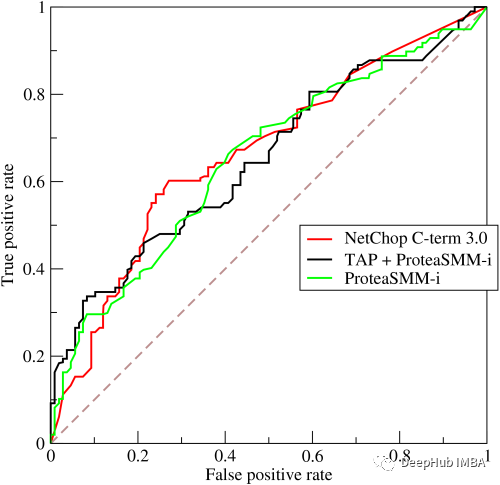
真阳性率(TPR)是真阳性与真阳性和假阴性的比率。它是实际阳性结果被测试为阳性的概率。假阳性率(FPR)是假阳性与所有阳性(真阳性和假阳性)的比率。它是虚惊一场的概率,也就是说,当它实际上是负的时候,会给出一个正的结果。马尔可夫链是一种随机过程。在马尔可夫链中,任何状态的未来概率只取决于当前状态。上图表示了一个马尔可夫链模型,其中每个步骤都有一个输出,只依赖于当前状态。例如文字推荐。当我们输入一个段落时,这个模型会提示下一个单词,它只依赖于前一个单词,而不依赖于它之前的任何单词。马尔科夫链模型之前在一个类似的段落上进行训练,其中给定单词的下一个单词存储在训练数据中的所有单词上。根据这个训练数据输出,建议接下来的单词。ROC曲线是假阳性率(x轴)和真阳性率(y轴)之间的曲线。真阳性率是指真阳性率与阳性样本总数之比。假阳性率是假阳性与阴性样本总数之比。在几个阈值上绘制FPR和TPR,构建ROC曲线。ROC曲线下的面积范围为0 ~ 1。完全随机模型的ROC为0.5,用直线表示。ROC曲线偏离这条直线越多,模型越好。ROC曲线用于二元分类。下图展示了ROC曲线的一个例子。减少给定数据集的特征数量被称为降维。有许多技术用于降低维度,如:降维的主要原因之一是“降维魔咒”。当特征的数量增加时,模型变得更加复杂。但如果数据点较少,模型将开始学习过拟合数据。模型不会泛化。这就是众所周知的“维度诅咒”。10. 如何在线性回归模型中找到RMSE和MSE ?采用均方根误差(RMSE)来检验线性回归模型的性能。它评估在最佳拟合线上分布了多少数据。MSE的公式是:均方误差(MSE)表示直线与实际数据的接近程度。取直线与数据点的差值并平方。对于一个好的模型,MSE值应该很低。这意味着实际输出值和预测输出值之间的误差应该很低。在进行二分类时,如果数据集不平衡,仅使用R2评分无法正确预测模型的精度。例如,如果属于其中一个类的数据在数量上比属于另一个类的数据少得多,那么传统的精度将在较小的类中占很小的百分比。如果只有5%的示例属于较小的类,而模型将属于其他类的所有输出分类,精度仍然在95%左右。但这是错误的。为了解决这个问题,我们可以这样做:- 使用其他方法来计算模型性能,如精度/召回率,F1评分等;
- 使用以下技术对数据重新采样(减少较大类的样本大小)、过采样(使用重复、SMOTE和其他此类技术增加较小类的样本大小);
- 使用集成学习,使每棵决策树考虑小类的整个样本,而只考虑大类的一个子集。
直方图和箱线图都用于直观地表示某一特征值的频率。下图显示了一个直方图。直方图用于了解数据的潜在概率分布。箱线图更多地用于比较多个数据集。箱线图比直方图有更少的细节和占用更少的空间。NLP代表自然语言处理。它是对计算机编程来学习大量文本数据的研究。NLP的例子包括标记化、停止词去除、词根提取、情感分析等。在所有可能的结果中,某一事件发生的可能性被称为其概率。事件发生的概率总是在(包括)0和1之间。- 加法规则:P(A或B)= P(A) + P(B) - P(A和B);
- 条件概率:它是事件B发生的概率,假设事件A已经发生;
- P(A and B) = P(A|B)P(B) = P(B|A)P(A);
- 中心极限定理:当我们从一个大总体中抽取随机样本,然后取这些样本的均值,它们形成一个正态分布。
L2正则化-(Ridge回归)-在L2正则化中,我们将所有权重的平方和,乘以一个值lambda,加到损失函数。Ridge回归公式为:可以看到,如果某一特定数据点和特征的权值乘以数据值变得非常大,那么原始的损失就会变得很小。但是增加值乘以权重平方和也会变大。同样如果原来的损失价值变得很大,那么增加的价值就会变小。因此它将控制最终值不变得太大或太小。L1正则化-(Lasso回归)-在L1正则化中,我们将所有权重的绝对值加和,乘以一个值lambda,到损失函数。Lasso回归公式为:损失函数和优化算法使参数趋近于零而不是实际为零,而lasso则消除了不太重要的特征,并将各自的权重值设置为零。Dropout用于神经网络的正则化。全连接层更容易过拟合。Dropout丢掉了神经网络中一些概率为1-p的神经元。Dropout减少了过拟合,提高了训练速度,使模型更健壮。在一个模型被部署之后,它输入的数据可能会随时间而改变。例如,在预测房价的模型中,房价可能会随着时间的推移而上涨,也可能会因为其他一些因素而波动。所以模型在新数据上的准确性可以被记录下来。一些确保准确性的常用方法包括:- 应经常通过输入阴性试验数据对模型进行检查。如果模型给出的精度较低且测试数据为负,则说明需要更新;
- 建立自动编码器,利用异常检测技术,AE模型计算重构误差值。如果重构错误值很高,这意味着新数据没有遵循模型学习到的旧模式;
- 如果模型对新数据显示出较好的预测精度,则说明新数据遵循模型对旧数据学习到的模式或泛化。因此,可以根据新数据对模型进行重新训练。如果新数据的准确性不是很好,那么可以使用对数据特征和旧数据进行特征工程的方法对新数据重新训练模型;
Precision = True Positives / (True Positives + False Positives)Recall = True Positives / (True Positives + False Negatives)
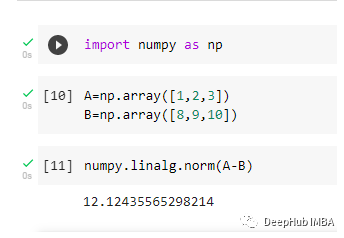
18. 如何在NumPy中测量两个数组之间的欧氏距离?2个阵列A[1,2,3,]和b[8,9,10]之间的欧氏距离可以通过分别取每个点的欧氏距离来计算。使用numpy. linalgy .norm():误差是指预测值与实际值之间的差值。数据科学中最常用的误差计算方法是平均绝对误差(MAE)、均方误差(MSE)和均方根误差(RMSE)。而剩余误差是一组观测值与其算术平均值之间的差。误差通常是不可观察的,而剩余误差可以在图上显示出来。误差表示观测数据与实际总体的差异。而剩余误差则表示观察数据与样本总体数据的差异。归一化,也称为最小-最大缩放,是一种将所有数据值转换为介于0和1之间的技术。标准化是指将我们的数据进行转换,使其具有均值为0,标准差为1的正态分布。因此,虽然标准化只将数据缩放到0到1的范围,但标准化确保数据遵循标准的正态分布。数据通常以不同的方式分布,有向左或向右的偏差,也可能全部混杂在一起。然而,也有可能数据分布在中心值周围,没有任何向左或向右的偏差,并以钟形曲线的形式达到正态分布。单峰,左右镜像对称,钟形-最大高度(模式)在平均值,均值、众数和中位数都位于中心。协方差和相关是两个数学概念;这两种方法在统计学中被广泛使用。相关和协方差都建立了关系,也衡量两个随机变量之间的依赖性。虽然从数学的角度来说,这两者的工作是相似的,但他们彼此不同。相关性:相关被认为或描述为测量和估计两个变量之间的定量关系的最佳技术。相关性衡量的是两个变量的相关性有多强。协方差:在协方差中,两个项目一起变化,它是一个衡量两个随机变量在周期变化的程度。这是一个统计术语;它解释了一对随机变量之间的系统关系,其中一个变量的变化与另一个变量的相应变化互为倒数。点估计给我们一个特定的值作为总体参数的估计。采用矩量法和极大似然估计法导出了总体参数的点估计。置信区间为我们提供了一个可能包含总体参数的值范围。通常首选置信区间,因为它告诉我们这个区间包含总体参数的可能性有多大。这种可能性或概率称为置信水平或置信系数,用1 - alpha表示,其中alpha是显著性水平。A/B测试的目标是识别变化,以最大限度地找到改变实验动作后对结果产生的影响。当在统计学中进行假设检验时,p值可以帮助您确定结果的强度。p值是0到1之间的一个数字。它将根据值表示结果的强度。这个正在试验的主张被称为零假设。较低的p值(≤0.05)意味着我们可以拒绝原假设。高p值(≥0.05)这意味着可以接受零假设,p值为0.05表明假设可以双向。26. 概率计算:在任何15分钟的间隔内,有20%的概率你会看到至少一颗流星。你在一小时内看到至少一颗流星的概率是多少?= 1 - P(看到一颗流星)= 1-0.2 = 0.8= 1 - P(看不到任何流星)= 1-0.4096 = 0.5904任何骰子有从1到6有6个面。一次掷骰子不可能得到7个相同的结果。如果我们掷骰子两次,考虑两次的事件,我们现在有36种不同的结果。为了得到7个相等的结果我们要把36化简成能被7整除的数。因此可以只考虑35种结果,并排除其中的一种。一个简单的场景便是排除组合(6,6),即如果6出现两次便再次掷骰子。从(1,1)到(6,5)的所有剩余组合可以分为7个部分,每个部分5。这样七组结果都是等可能的。28. 一对夫妇告诉你他们有两个孩子,其中至少有一个是女孩。他们有两个女孩的概率是多少?其中B =男孩,G =女孩,第一个字母表示第一个孩子。从问题中,我们可以排除第一种BB。因此,从BG, GB, BB剩下的3种可能性中,我们必须找出两个女孩的情况的概率。29. 一个罐子有1000枚硬币,其中999枚是正常的,1枚的两面都是正面。随机选择一枚硬币,投掷10次。假设你看到10个正面,那枚硬币下一次扔出来也是正面的概率是多少?选择硬币有两种方法。一种是选出一枚正常的硬币,另一种是选出两个正面的硬币。选择正常硬币的概率= 999/1000 = 0.999选择非正常硬币的概率= 1/1000 = 0.001连续选择10个正面=选择正常硬币*得到10个正常+选择一枚非正常硬币:P (A) = 0.999 *(1/2)⁵= 0.999 * (1/1024)= 0.000976P (b) = 0.001 * 1 = 0.001P(a / a + b) = 0.000976 / (0.000976 + 0.001) = 0.4939P(b / a + b) = 0.001 / 0.001976 = 0.5061选择另一个正面的概率= P(A/A+B) * 0.5 + P(B/A+B) * 1 = 0.4939 * 0.5 + 0.5061 = 0.753130. 你对敏感度(Sensitivity)的统计能力有什么理解?你如何计算它?敏感度通常被用来验证分类器的准确性(Logistic, SVM, Random Forest等)。敏感度是“预测的真实事件/总事件”。真实事件是指真实的事件模型也预测了它们是真实的。计算非常简单。敏感度(Sensitivity真阳性率)= TP/P
- 通过使用可访问数据的子集或从一组数据点中随机抽取替换数据来估计样本统计数据的准确性;
- 通过使用随机子集(bootstrapping, cross-validation)来验证模型。
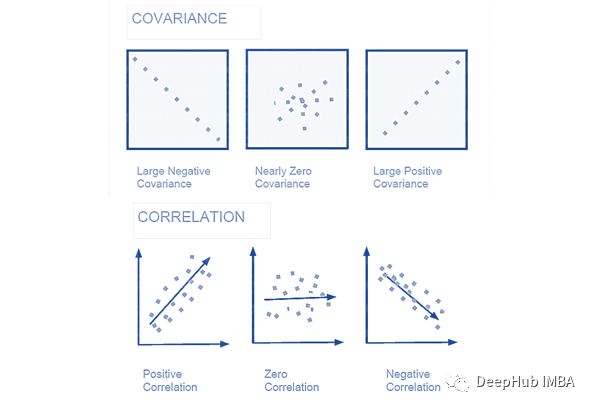
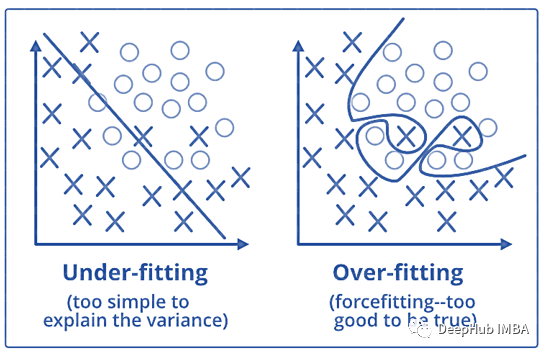
在统计学和机器学习中,最常见的任务之一就是将模型拟合到一组训练数据中,从而能够对一般的未经训练的数据做出可靠的预测。在过拟合中,统计模型描述的是随机误差或噪声,而不是潜在的关系。过拟合发生在一个模型过于复杂的时候,比如相对于观测数据有太多的参数。过拟合的模型预测性能较差,因为它对训练数据的微小波动反应过度。当统计模型或机器学习算法无法捕捉数据的潜在趋势时,就会发生欠拟合。例如,当用线性模型拟合非线性数据时,就会出现欠拟合。这种模型的预测性能也很差。为了避免过拟合和欠拟合,可以重采样数据来估计模型的准确性(k倍交叉验证),并通过验证数据集来评估模型。正则化可以防止过拟合。一般情况下是通过在现有的权重向量上加上一个常数倍数来实现的。这个常数通常是L1(Lasso)或L2(ridge)。然后模型预测应该最小化在正则化训练集上计算的损失函数。这个定理,描述了进行大量相同实验的结果。这个定理构成了频率式思维的基础:样本均值,样本方差和样本标准差收敛于他们试图估计的值。在统计数据中,混淆因素是一个影响因变量和独立变量的变量。混淆变量(Confounding Variable)是指与自变量和因变量均相关的变量,该变量使自变量和因变量间产生虚假的关系(Meinert, 1986)。这里的混淆变量将是影响这两个变量的任何变量例如受试者的年龄。38. 什么是生存偏差(Survivorship bias)?这是一个逻辑上的错误,即专注于支持幸存某些过程的方面,而忽略那些因为它们不突出而不起作用的方面。这可能会以各种不同的方式得出错误的结论。39. 什么是选择偏差(Selection bias)?当获得的样本不能代表要分析的总体时,就会出现选择偏差。ROC曲线是各种阈值下真实阳性率和假阳性率对比的图形表示。它经常被用作敏感性(真阳性率)和假阳性率之间权衡的标准。TF-IDF是 term frequency-inverse document frequency,的缩写,是反映一个词对集合或语料库中的文档的重要性的统计数字。在信息检索和文本挖掘中,它经常被用作加权因子。TF-IDF值与单词在文档中出现的次数成比例增加,但会被单词在语料库中的出现频率所抵消,这有助于调整某些单词在一般情况下出现的频率更高的事实。42. 为什么我们一般使用Softmax非线性函数作为网络最后一个操作?这是因为它采用了实数的向量并返回概率分布。它的定义如下。令X为实数的向量(正,负,无论如何,没有约束)。输出是概率分布:每个元素都是非负分布,所有分量的总和为1。
数据分析
- 清理来自多个源的数据有助于将其转换为数据分析师或数据科学家可以使用的格式;
- 这是一个繁琐的过程,因为随着数据源数量的增加,由于数据源的数量和这些数据源生成的数据量,清理数据所需的时间呈指数增长;
- 清理数据可能要花费多达80%的时间,这使得它成为分析任务的关键部分。
单变量分析是一种描述性统计分析技术,可以根据在给定的时间点所涉及的变量的数量进行区分。例如,基于地域的销售饼图只涉及一个变量,分析可以称为单变量分析。双变量分析试图在散点图中理解两个变量在同一时间的差异。例如,分析销售和支出的数量可以被认为是双变量分析的一个例子。多变量分析涉及两个以上变量的研究,以了解变量对反应的影响。它是具有中心表的传统数据库模式。附属表将ID映射到物理名称或描述,可以使用ID字段连接到中心事实表;这些表被称为查找表,主要用于实时应用程序,因为它们可以节省大量内存。有时星型模式涉及多个汇总层以更快地获取相应的信息。46. 什么是整群抽样(Cluster sampling)?整群抽样是指整群地抽选样本单位,对被抽选的各群进行全面调查的一种抽样组织方式。例如,检验某种零件的质量时,不是逐个抽取零件,而是随机抽若干盒 (每盒装有若干个零件),对所抽各盒零件进行全面检验。如果全及总体划分为单位数目相等的R个群,用不重复抽样方法,从R群中抽取r群进行调查。47. 什么是系统抽样(Systematic Sampling)?先将总体的全部单元按照一定顺序排列,采用简单随机抽样抽取第一个样本单元(或称为随机起点),再顺序抽取其余的样本单元,这类抽样方法被称为等距抽样(Systematic Sampling)。等距抽样又称为机械抽样、系统抽样。等距抽样往往不能给出估计量的估计方差。48. 什么是特征向量(Eigenvectors)和特征值(Eigenvalues)?特征向量用于理解线性变换。在数据分析中,通常计算相关或协方差矩阵的特征向量。特征向量是特定线性变换通过翻转、压缩或拉伸作用的方向。特征值可以被认为是在特征向量方向上的变换强度或压缩发生的因子。假阳性是指错误地将非事件分类为事件,也就是第一类错误。假阴性是指错误地将事件归类为非事件的情况,也就是第二类错误。在医疗领域,例如癌症检查他的癌症检测呈阳性,但他实际上没有癌症。这是一个假阳性的案例。在这个病人没有癌症的情况下对他进行化疗是非常危险的。在没有癌细胞的情况下,化疗会对他正常健康的细胞造成一定的损害,可能导致严重的疾病,甚至癌症。假设有一个机场安检如果一个真正有威胁的客户被机场模型标记为无威胁,陪审团或法官决定释放犯罪的罪犯都是这种情况。51. 你能举出一些假阳性和假阴性同样重要的例子吗?在银行业,贷款是赚钱的主要来源,如果你的还款率不好,银行向你贷款面临巨大的损失风险。银行不想失去好客户,也不想获得差客户。在这种情况下假阳性和假阴性都变得非常重要。验证集可以被认为是训练集的一部分,因为它用于参数选择和避免模型的过拟合。测试集用于测试或评估训练好的机器学习模型的性能。简单地说,区别可以概括为;训练集是拟合参数,验证集是测试训练集的效果;测试集是评估模型的性能。交叉验证是一种模型验证技术,用于评估统计分析结果如何推广到独立数据集。主要用于预测目标和估计模型在实践中实现的准确性的背景。交叉验证的目标是定义一个数据集来在训练阶段测试模型(即验证数据集),以限制过拟合等问题,并深入了解模型将如何推广到一个独立的数据集。