
Hbase与MySQL对比,区别是什么?

阅读本文大概需要 2.8 分钟。
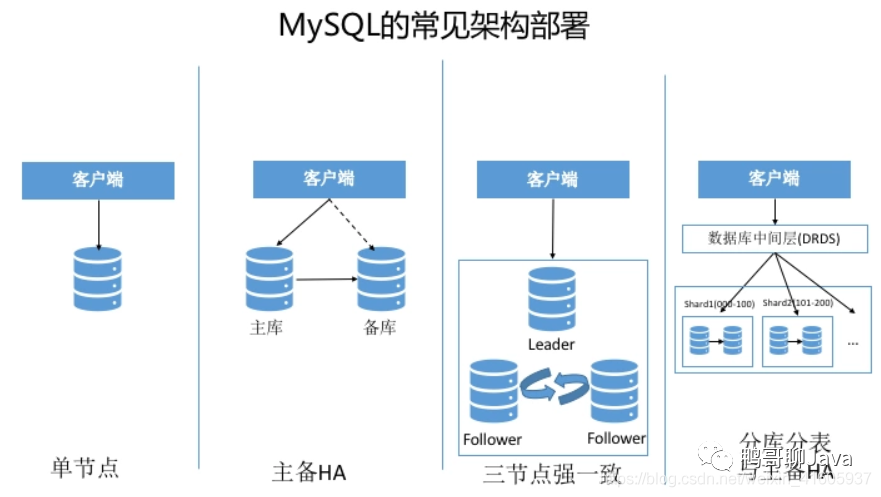
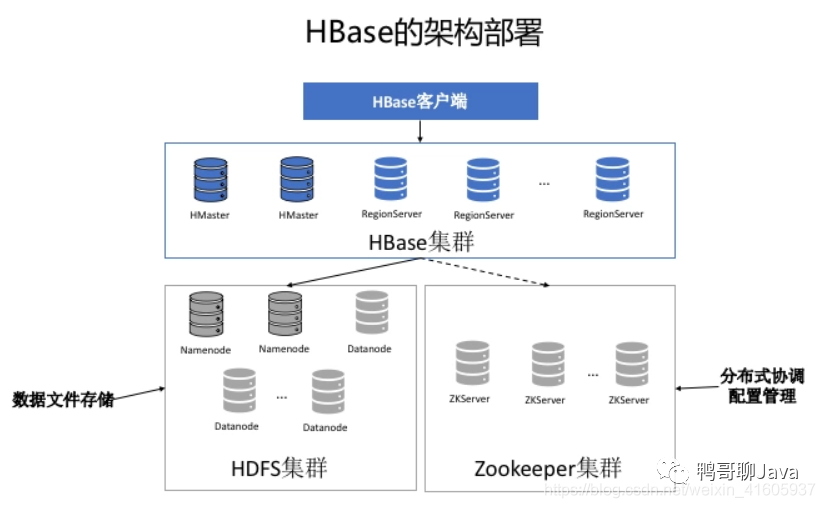
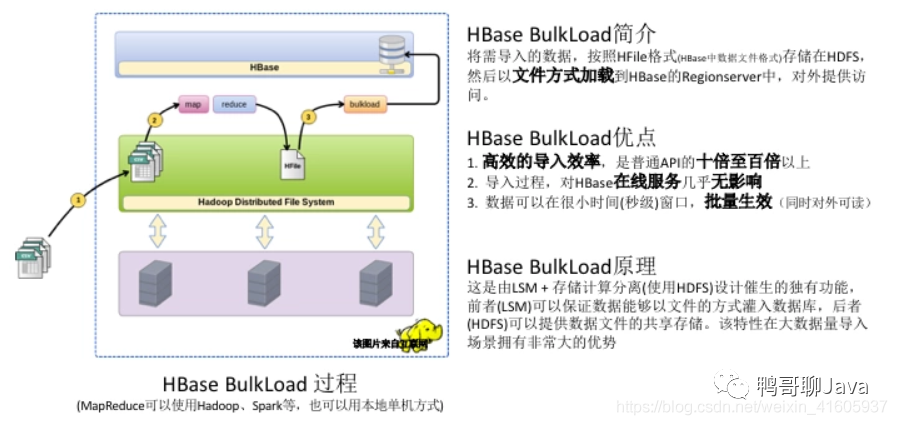
 相比MySQL,HBase的内部引擎特点:
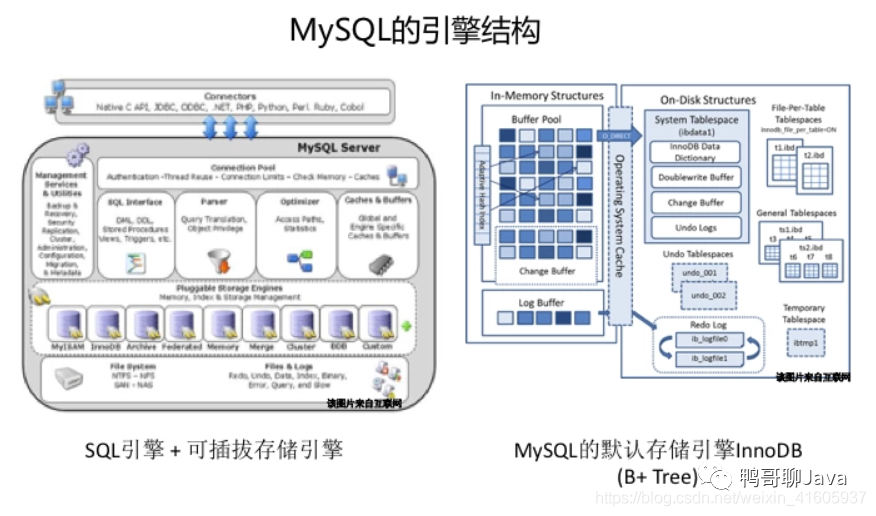
相比MySQL,HBase的内部引擎特点: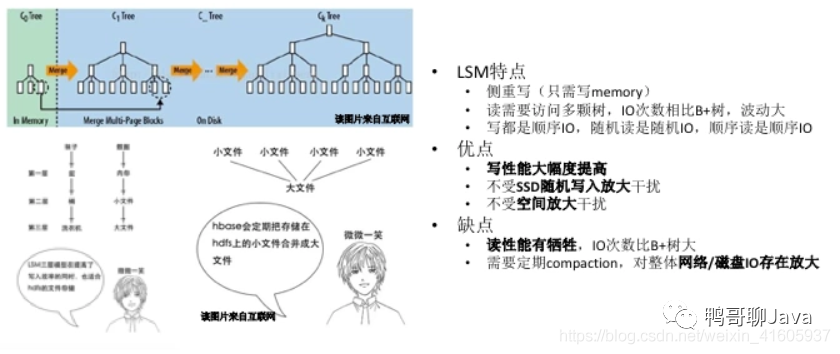
从磁盘读数据是以页为单位,根据这个特点使用平衡多路查找树
B+树的非叶子节点存放索引,叶子节点存放数据
非叶子节点能够存放更多的索引,树的高度更低
叶子节点通过指针相连,有利于区间查询
叶子节点和根节点的距离基本相同,查找的效率稳定
数据插入导致叶子节点分裂,最终导致逻辑连续的数据存放到不同物理磁盘块位置,导致区间查询效率下降
LSM(Log-Structured Merge),LevelDB,RocksDB,HBase,Cassandra等都是基于LSM结构
HDD,SSD顺序读写的速度都高于随机读写,写入日志就是顺序写
WAL,memtable,sstable
有利于写,不利于读,先从memtable查找,再到磁盘所有的sstable文件查找
Compaction的目的是减少sstable文件数量,缓解读放大的问题,加速查找可以对sstable文件使用布隆过滤器
Compaction策略
STCS(SIze-Tiered Compaction Strategy)空间放大和读放大问题
LCS(Leveled Compaction Strategy)写放大问题
Compaction会引入写放大问题,在Value较大时采用KV分离存储缓解写放大
写操作多于读操作时,LSM树有更好的性能,因为随着insert操作,为了维护B+树结构,节点分裂。读磁盘的随机读写概率会变大,性能会逐渐减弱。LSM树相比于B+树,多次单页随机写变成一次多页随机写,复用了磁盘寻道时间,极大提高写性能。不过付出代价就是放弃部分读性能。
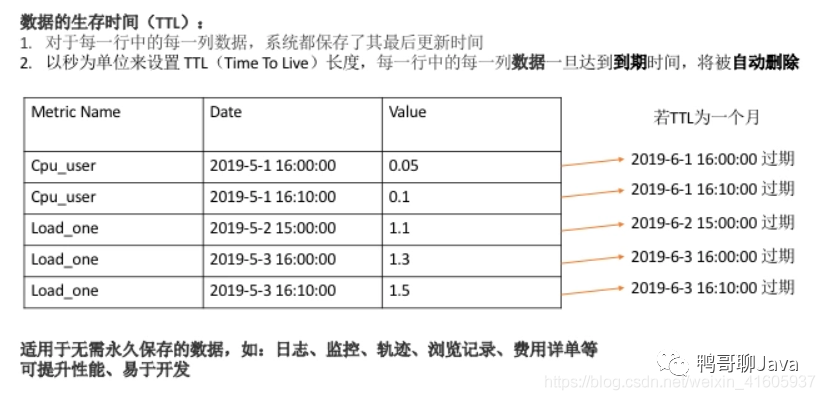

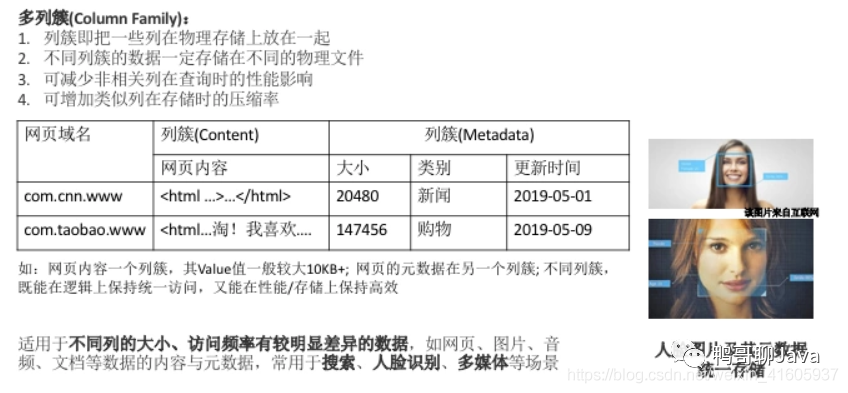
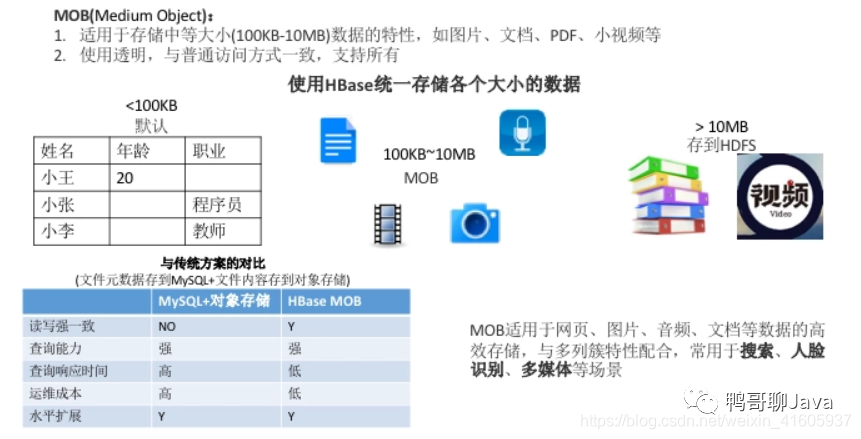




推荐阅读:
头条三面:toString()、String.valueOf、(String)强转,有啥区别?
最近面试BAT,整理一份面试资料《Java面试BATJ通关手册》,覆盖了Java核心技术、JVM、Java并发、SSM、微服务、数据库、数据结构等等。
朕已阅 