
懂你,更懂Rust系列之集合、泛型、trait(接口)、生命周期和错误处理
总在刹那间有一些了解
说过的话不可能会实现
就在一转眼 发现你的脸
已经陌生 不会再像从前
请注意,本篇文章有介绍的有一些Rust非初级理论(比如trait、生命周期和引用有效性)的东西了,应该算中级一点了吧,所以篇幅较长,请花点耐心咯。最重要一点:代码需要多手动敲!敲得越多理解越快。
后续因为会有几个Rust的常见API介绍,所以,这里建个rust_api包。
一、泛型
首先思考一个场景,假设需要从一个i8数据类型的数组中,找到最大的那个数字
很简单,先定义一个函数,get_max_number,然后方法传入参数为数组引用,循环比较,找到其最大值,然后调用运行:
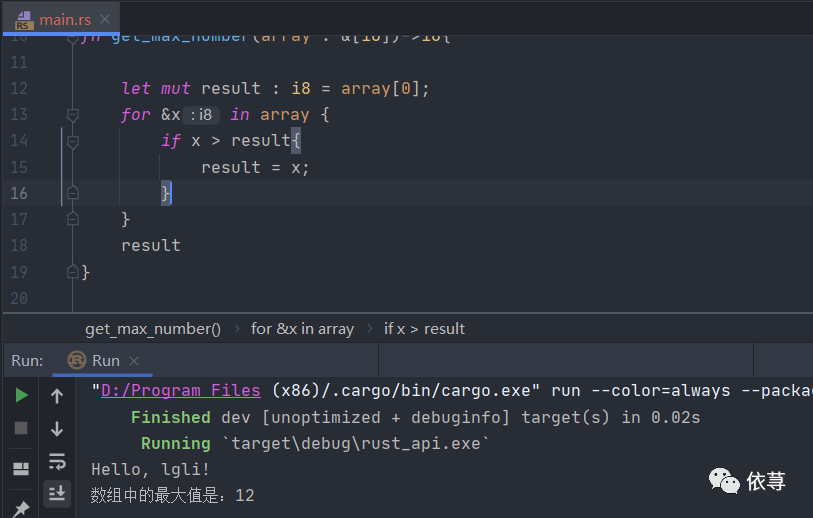
fn main() {println!("Hello, lgli!");let array:[i8;6] = [12,3,5,2,7,9];let result: i8 = get_max_number(&array);println!("数组中的最大值是:{}",result);}//找到最大值fn get_max_number(array : &[i8])->i8{let mut result : i8 = array[0];for &x in array {if x > result{result = x;}}result}
上述函数函数体的代码,这里就不在详述了,简单的基础语法,比如引用、可变变量就不在多说了,前面已经说了很多了。
那么接下来的是,如果,数组包含的是i16的数字呢?
很明显,需要再写一个和上述get_max_number相同的方法,除了参数类型不一样之外。这样子的大量代码重复量,肯定是不优雅的,所以这里Rust提供了一种优雅的解决方案,那就是泛型<Generic>
比如上述函数可以修改为:
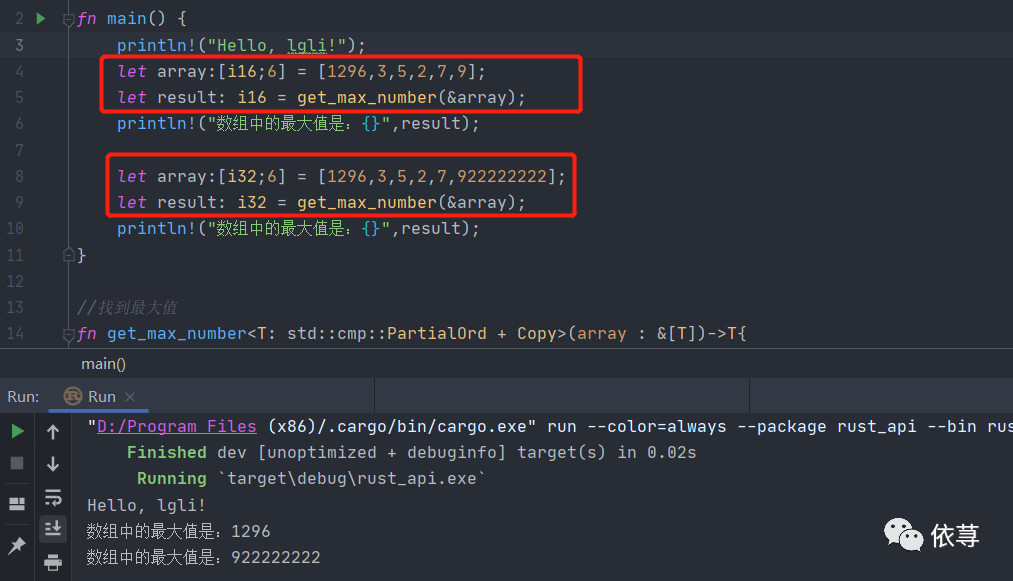
fn main() {println!("Hello, lgli!");let array:[i16;6] = [1296,3,5,2,7,9];let result: i16 = get_max_number(&array);println!("数组中的最大值是:{}",result);}//找到最大值fn get_max_number<T: PartialOrd + Copy>(array : &[T])->T{let mut result : T = array[0];for &x in array {if x > result{result = x;}}result}
注意上述代码,函数get_max_number返回值变成了T
同时在函数前面加上了<T: PartialOrd + Copy>
然后参数:array : &[T]
这里的T表示泛型,即方法可以传入任意类型的数组,可以是i8的,也可以是i16的,甚至还可以是char
这里是定义了一个带返回值的泛型函数,返回值和参数传入的类型一致,同时函数名后面需要跟上泛型类型,也就是这里的<T>,本函数因为涉及一些其他Rust的理论,比如添加std::cmp::PartialOrd是为了使函数体的比较大小x>result可以实现比较,添加std::cmp::Copy是为了保证result的初始化,意思是,只对在栈中变量初始化,因为这里泛型会考虑到是否有堆中数据,堆中数据,则需要加引用&,但是又不能保证都是堆中数据,所以这里这么做。先做个简单的了解,后续会详细说到!
所以这个时候,函数get_max_number就可以是各种类型的了,不需要copy各种大量重复代码了:
同样的,可以在结构体中定义泛型:
//定义了课程,课程名字是字符串,课程内容是个泛型struct Course<T>{name:String,content:T}
还有在方法体中定义泛型:
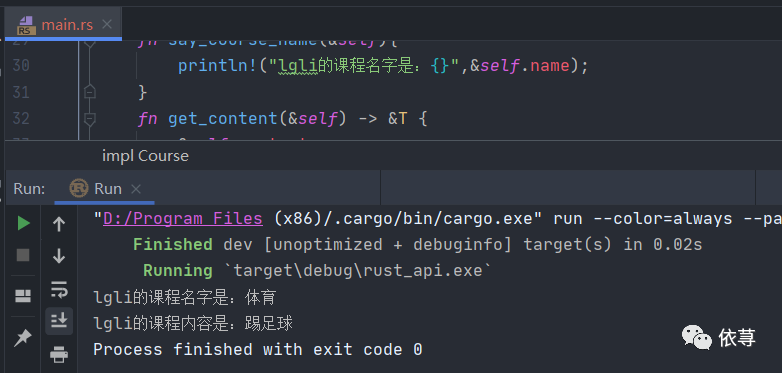
//方法定义中的泛型impl <T> Course <T> {fn say_course_name(&self){println!("lgli的课程名字是:{}",&self.name);}//方法中函数泛型fn get_content(&self) -> &T {&self.content}}
这里提一点前面的基础,在Rust中不要把方法和函数混为一谈了。
然后测试下上述代码:
fn main() {let my_course = Course{name:String::from("体育"),content : "踢足球"};my_course.say_course_name();let my_course_content = my_course.get_content();print!("lgli的课程内容是:{:#}",my_course_content);}//定义了课程,课程名字是字符串,课程内容是个泛型struct Course<T>{name:String,content:T}//方法定义中的泛型impl <T> Course <T> {fn say_course_name(&self){println!("lgli的课程名字是:{}",&self.name);}//方法中函数泛型fn get_content(&self) -> &T {&self.content}}
编译运行
看下面这个泛型例子:
fn main() {let point_one : Point<i8,char> = Point{x:8,y:'c'};let point_two : Point<i16,String> = Point{x:8,y:String :: from("lgli")};let point_three : Point<i8,String> = point_one.update_y_value(point_two);print!("交换Y值的结构为:{:?}",point_three);}//定义泛型结构体#[derive(Debug)]struct Point<U,V>{x : U,y : V}//结构体方法impl <U,V> Point<U,V>{//方法函数fn update_y_value<W,Z>(self,other_point : Point<W,Z>) ->Point<U,Z>{Point{x : self.x,y : other_point.y}}}
编译运行:
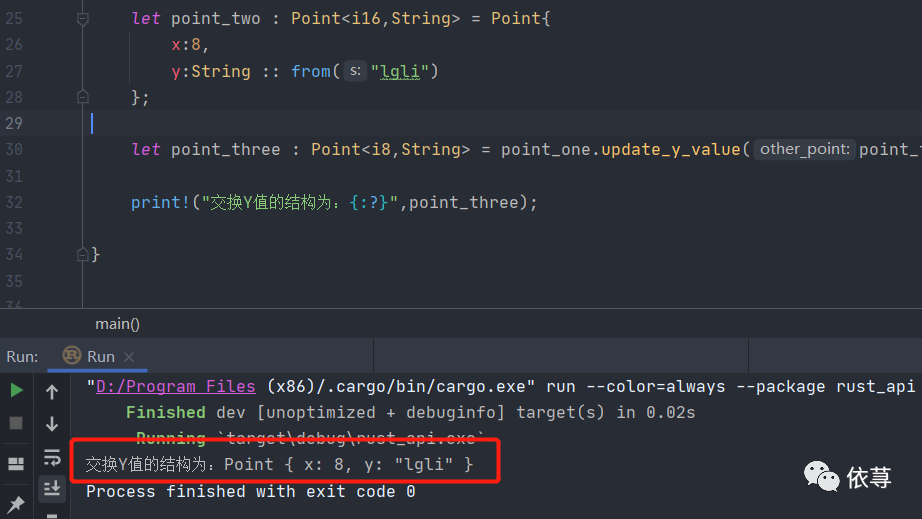
前面已经有介绍过Rust标准库中的一些泛型实例,比如Option<T>,这也都是结构体泛型,
在Rust中,泛型编译通过泛型编码的单态化(monomorphization)来保证效率,单态化是一个通过填充编译时使用的具体类型,将通用代码转换为特定代码的过程
比如:
let integer = Some(5);let float = Some(5.0);
当 Rust 编译这些代码的时候,它会进行 单态化。编译器会读取传递给
Option<T>
的值并发现有两种 Option<T>:
一个对应 i32 另一个对应 f64。
为此,它会将泛型定义 Option<T>
展开为 Option_i32 和 Option_f64,接着将泛型定义替换为这两个具体的定义。
即:
enum Option_i32 {Some(i32),None,}enum Option_f64 {Some(f64),None,}fn main() {let integer = Option_i32::Some(5);let float = Option_f64::Some(5.0);}
二、集合
在rust_api中新建一个二进制的crate-->vec
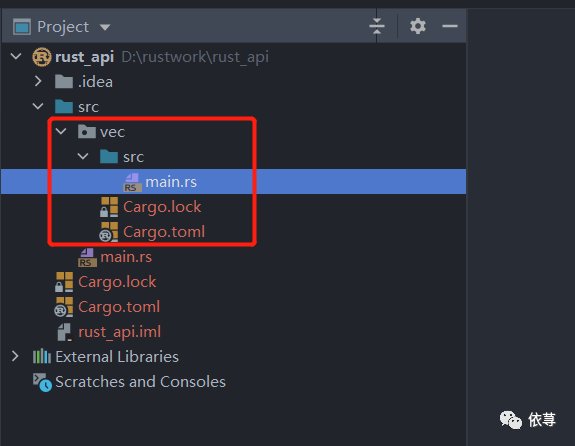
首先要介绍的第一个集合是 Vec<T>
let v: Vec<i32> = Vec::new();上述代码,初始化一个i32数据类型的集合
可以使用push添加集合数据,但是必须都是i32的:
fn main() {println!("Hello, lgli!");let mut v: Vec<i32> = Vec::new();v.push(32);v.push(64);v.push(128);print!("集合的长度为:{}",v.len());}
当存在集合元素被引用时候,尝试改变集合数据是不行的:
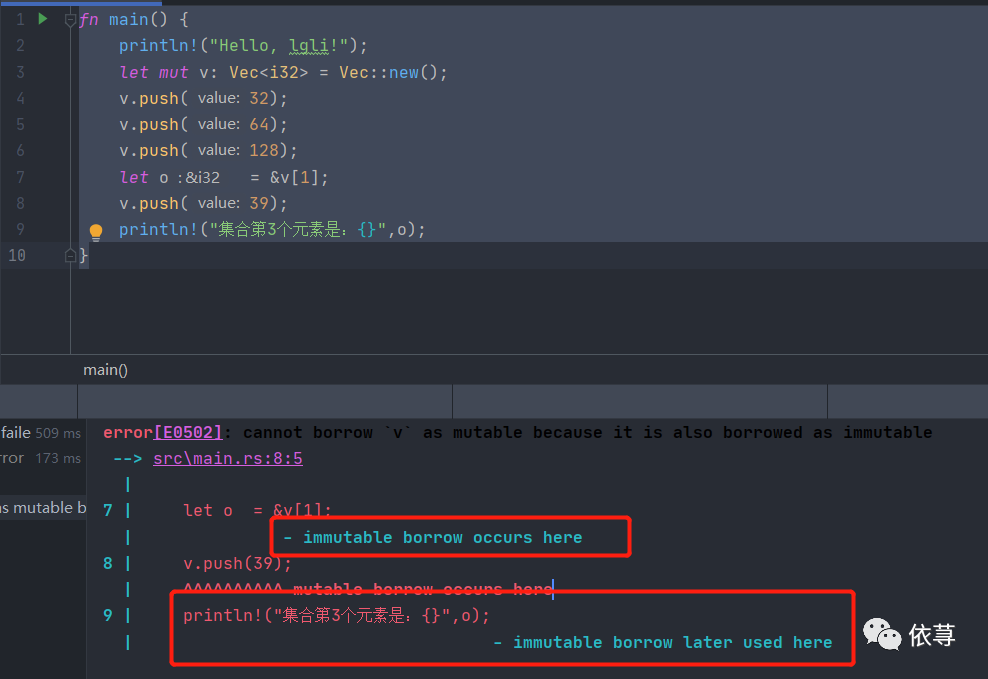
fn main() {println!("Hello, lgli!");let mut v: Vec<i32> = Vec::new();v.push(32);v.push(64);v.push(128);let o = &v[1];v.push(39);println!("集合第3个元素是:{}",o);}
上述代码,变量o获取了集合元素引用,同时borrow到了println!
这时候,尝试push元素是会报错的
所以编译报错:
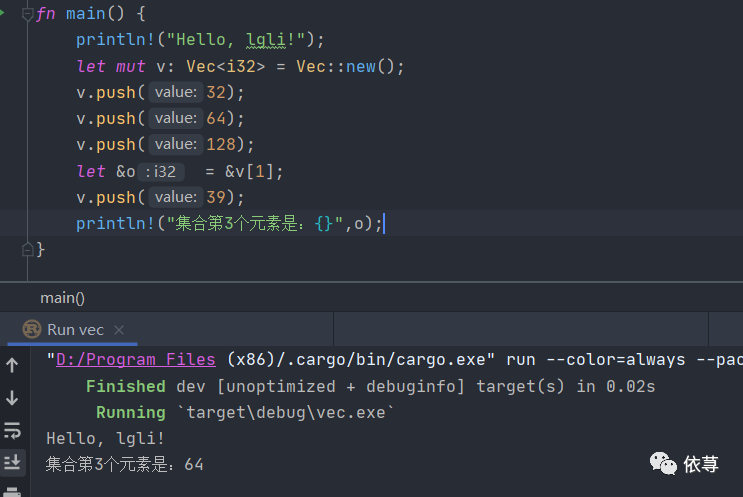
修改上述代码:
fn main() {println!("Hello, lgli!");let mut v: Vec<i32> = Vec::new();v.push(32);v.push(64);v.push(128);let &o = &v[1];v.push(39);println!("集合第3个元素是:{}",o);}
编译运行:
遍历集合元素可以使用for循环:
let v: Vec<i32> = vec![13,25,159,1336];for &i in &v{println!("{}",i);}
编译运行:
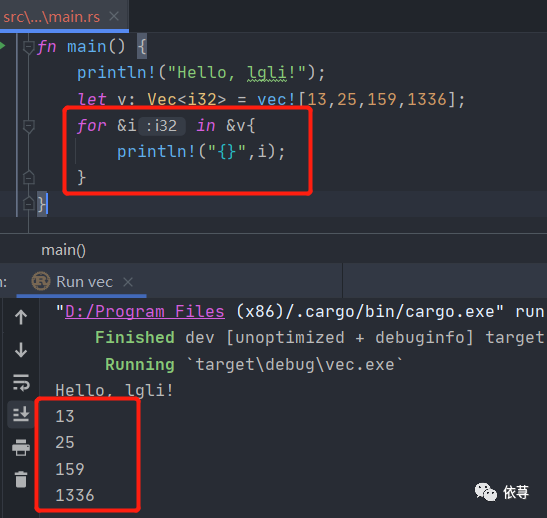
也可以尝试对集合的元素做运算:
let mut v: Vec<i32> = vec![13,25,159,1336];for i in &mut v{*i += 22;}for &i in &v{println!("{}",i);}
编译运行:
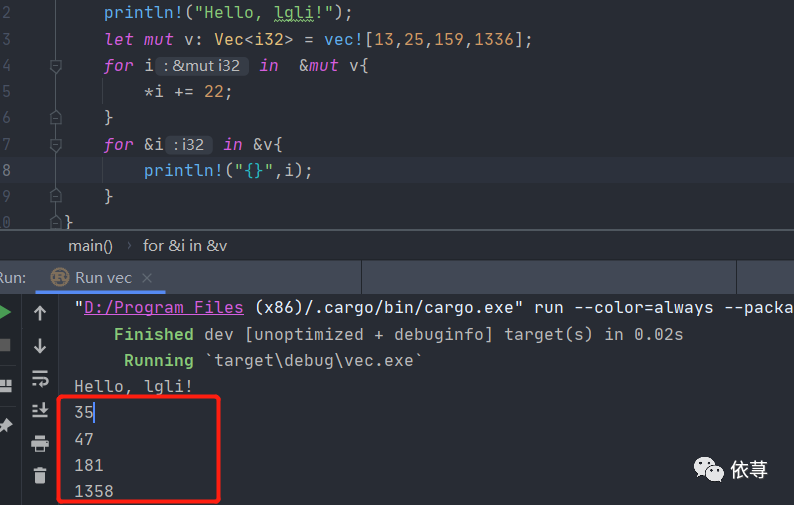
这里通过对元素都加了22,从而改变了元素的值
这里需要先记住一个点:在使用 += 运算符之前必须使用解引用运算符(*)获取 i 中的值。
这个解引用运算符追踪指针的值中会介绍到
集合vec!只能存放相同类型的数据,这很不方便,在某些特殊情况下,需要保存不同类型的数据,这就不适用了
这时候,可以这么做,定义枚举,成员变量是不同类型,这时候,集合元素为枚举,这就可以满足上述需求了,比如:
#[derive(Debug)]enum Course {Text(String),Int(i128),Float(f64)}let some_vec = vec![Course ::Int(160),Course :: Float(0.265),Course :: Text(String :: from("lgli"))];for x in &some_vec {println!("{:?}",x);}
编译运行:
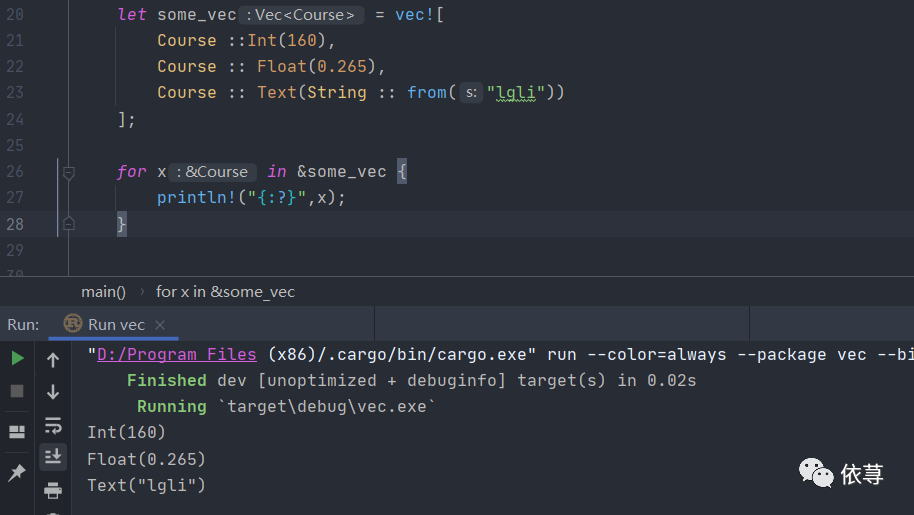
三、字符串
新建一个str二进制库:
字符串其实是一个非常复杂的玩意儿了
在前面的例子中多次都是用到过,但是真正细细分析,还没有弄过,今天就来分析这个复杂的字符串
首先,Rust 的核心语言中只有一种字符串类型:str,它通常以被借用的形式出现,&str,前面说到的字符串 slice:它们是一些储存在别处的 UTF-8 编码字符串数据的引用。比如字符串字面值被储存在程序的二进制输出中,字符串 slice 也是如此。
称作 String 的类型是由标准库提供的,而没有写进核心语言部分,它是可增长的、可变的、有所有权的、UTF-8 编码的字符串类型。
Rust 标准库中还包含一系列其他字符串类型,比如 OsString、OsStr、CString 和 CStr
这些字符串类型能够以不同的编码,或者内存表现形式上以不同的形式,来存储文本内容
很多 Vec 可用的操作在 String 中同样可用,从以 new 函数创建字符串开始
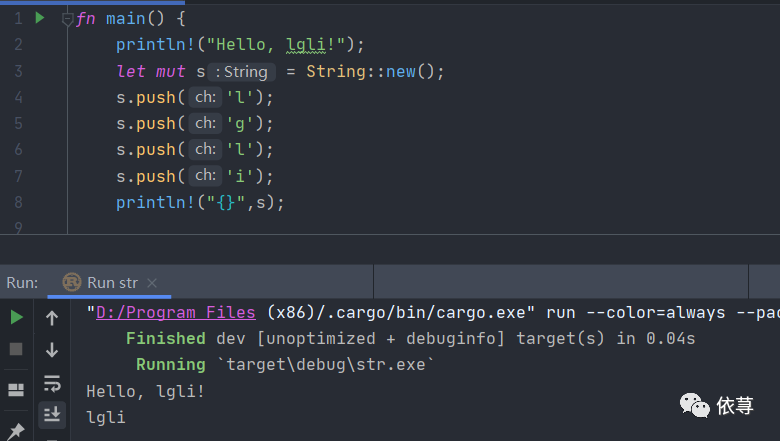
let mut s = String::new();也可以通过push添加数据
let mut s = String::new();s.push('l');s.push('g');s.push('l');s.push('i');println!("{}",s);
编译运行
也可以直接,将str转化为String
let mut s = "你好".to_string();s.push('l');println!("{}",s);
或者
let mut s = String :: from("你好");s.push('l');println!("{}",s);
这里添加的str,是逐个char添加,可以使用push_str添加slice片
let mut s = String :: from("你好");s.push_str("lgli");println!("{}",s);
也可以这样
let mut s = String :: from("你好");let sts = "lgli";s.push_str(sts);println!("{}",s);
这里需要记住一点,push_str是不糊获取参数的所有权的,所有在执行上述代码之后,sts依然有效
下面代码可以说明这一点:
let mut s = String :: from("你好");let sts = String :: from("lgli");s.push_str(&sts);println!("{}",s);
不能直接传入sts,因为直接传入,则说明方法要获取所有权,但是这里只能传入其引用
看下面代码
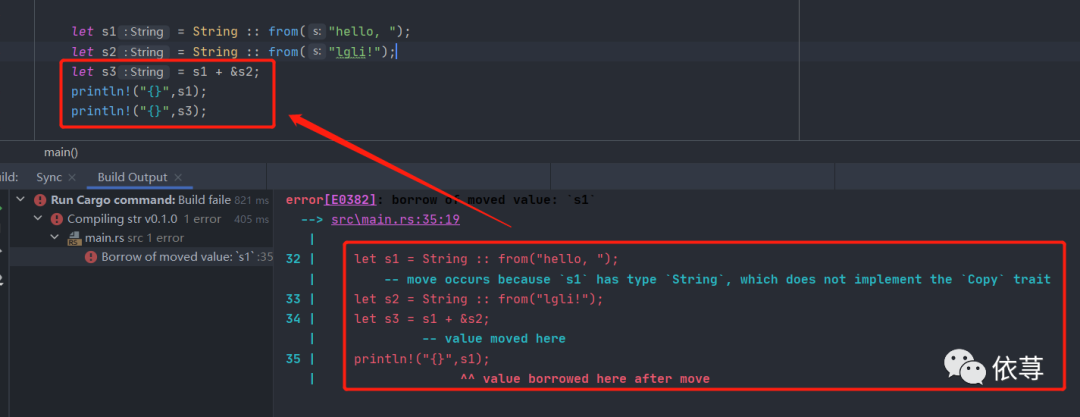
let s1 = String :: from("hello, ");let s2 = String :: from("lgli!");let s3 = s1 + s2;println!("{}",s3);
如果从其他语言的角度,比如Java,这个代码是没有什么问题的,但是在Rust中,这里是有问题的
首先Rust中的字符串的+号,会调用string的add方法
#[stable(feature = "rust1", since = "1.0.0")]impl Add<&str> for String {type Output = String;#[inline]fn add(mut self, other: &str) -> String {self.push_str(other);self}}
上述是Rust的add源码,这里可以看到,参数传入的是一个&str,即str引用,所以上述代码应该改成:
let s1 = String :: from("hello, ");let s2 = String :: from("lgli!");let s3 = s1 + &s2;println!("{}",s3);
那么这里应该又有问题了,这个地方的&s2是一个&String也不是&str呀?
Rust 使用了一个被称为 解引用强制多态(deref coercion)的技术,可以理解为,它把 &s2 变成了 &s2[..],这里不做过多的扩展。
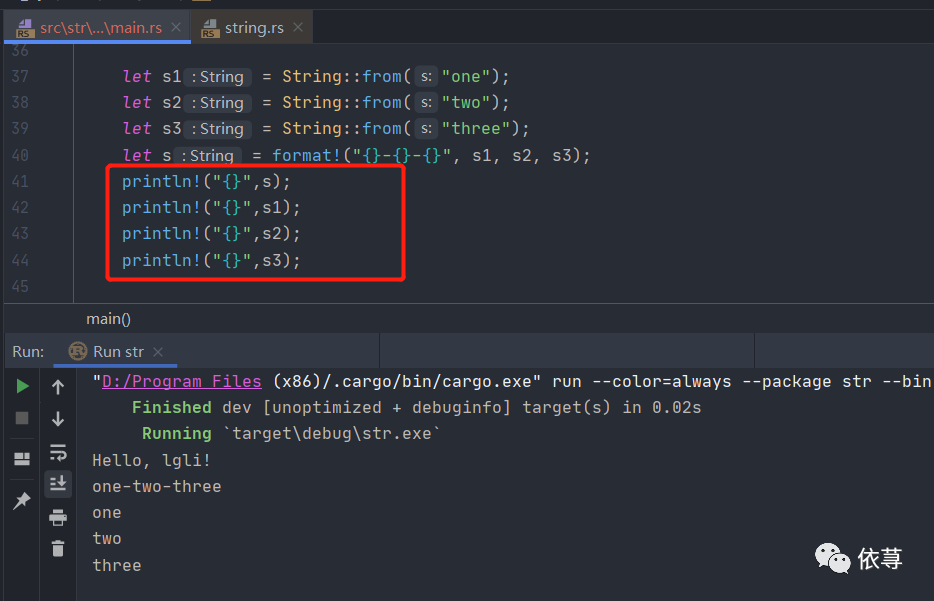
在需要使用多个+拼接字符串的时候,这个就显得很尴尬了,Rust提供了一种
format!
let s1 = String::from("one");let s2 = String::from("two");let s3 = String::from("three");let s = format!("{}-{}-{}", s1, s2, s3);
format!不会发生移动,即在上述代码运行之后,s1、s2、s3都是有效的
但是使用+,则首个字符串是会发生移动的
但是后者不会
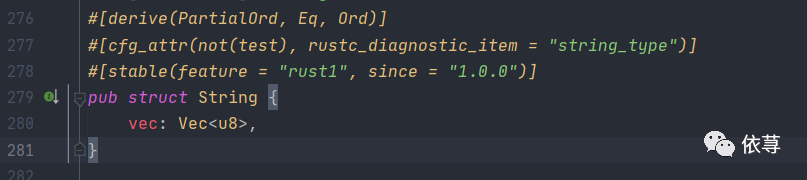
String其内部也是一个集合vec
下面尝试下标的方式获取字符串
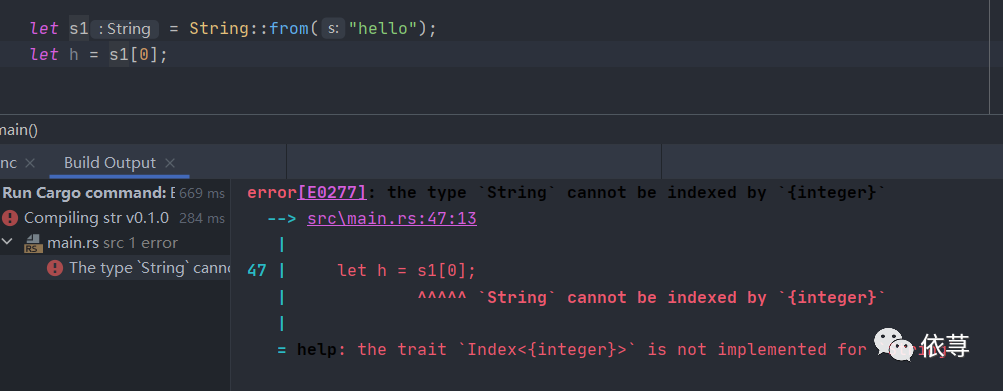
很遗憾,报错了
为什么?
前面我们看到了,String,内部其实是一个u8类型的集合,即所有的字符串都是通过UTF-8 编码成u8保存在集合中,索引访问是一个确切的位置,但是一个字符串字节值的索引并不总是对应一个有效的 Unicode 标量值。
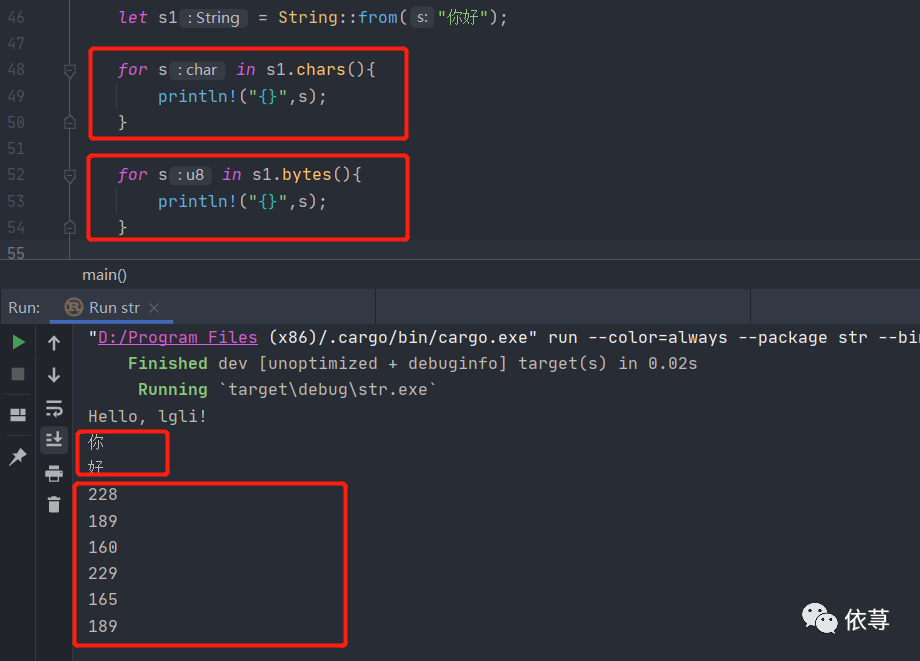
即此时s1[0]是需要返回228?还是'你'?
这是其中一个无法通过索引访问string的原因
还有一个Rust 不允许使用索引获取 String 字符的原因是,索引操作预期总是需要常数时间 (O(1))。但是对于 String 不可能保证这样的性能,因为 Rust 必须从开头到索引位置遍历来确定有多少有效的字符。
四、哈希map
新建一个map二进制包
哈希map是通过键值对<key,value>来保存任意数据类型的数据集合,查找数据也是直接通过key来寻找对应的value,而不需要像集合那样通过遍历索引
下面尝试新建一个哈希map,并插入值
let mut map : HashMap<String,i8> = HashMap::new();map.insert(String::from("one"), 1);map.insert(String::from("two"), 2);
这里新建了一个map,其中键值对类型分别为String和i8
使用insert可以给map中添加对应的key及其对应的value
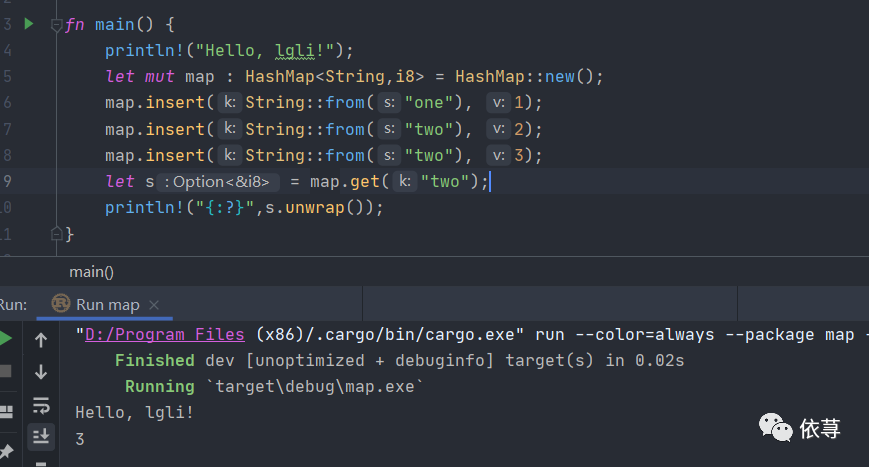
let mut map : HashMap<String,i8> = HashMap::new();map.insert(String::from("one"), 1);map.insert(String::from("two"), 2);map.insert(String::from("two"), 3);let s = map.get("two");println!("{:?}",s.unwrap());
重复insert的key会覆盖掉之前的value值,获取key对应的value,使用get
返回值是Option枚举
上述代码运行结果:
插入堆上数据类型,将会获取数据所有权
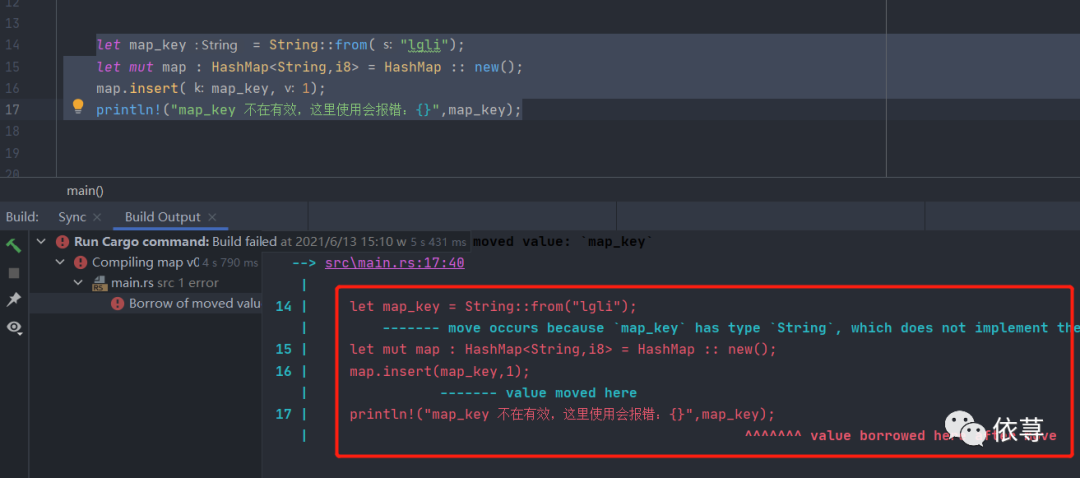
let map_key = String::from("lgli");let mut map : HashMap<String,i8> = HashMap :: new();map.insert(map_key,1);println!("map_key 不在有效,这里使用会报错:{}",map_key);
上述代码编译报错:
有的时候,可能未知或者忘了,map中是否有某个key的value值,这时候,有一个想法就是,想要检验,如果map中存在某个key的value值,就不变,否则就插入,而不是直接覆盖掉。Rust提供了这种API
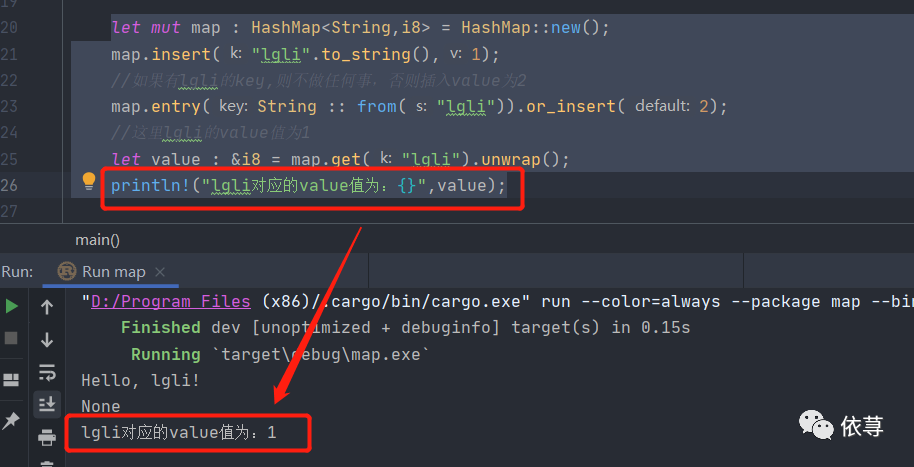
let mut map : HashMap<String,i8> = HashMap::new();map.insert("lgli".to_string(),1);//如果有lgli的key,则不做任何事,否则插入value为2map.entry(String :: from("lgli")).or_insert(2);//这里lgli的value值为1let value : &i8 = map.get("lgli").unwrap();println!("lgli对应的value值为:{}",value);
上述代码运行结果:
map.entry(&str).or_insert(value)
or_insert 方法会返回这个键的值的一个可变引用
根据此特性,可以进行一个计数操作
比如计算字符串内相同的slice的次数:
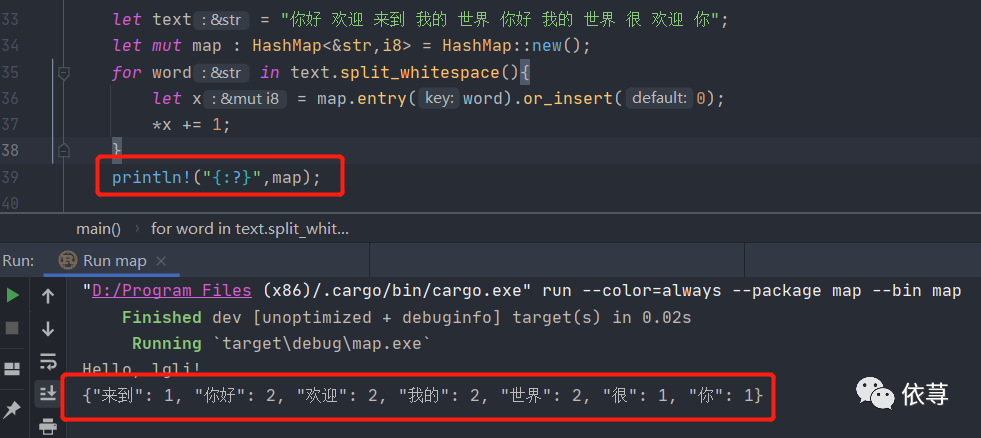
let text = "你好 欢迎 来到 我的 世界 你好 我的 世界 很 欢迎 你";let mut map : HashMap<&str,i8> = HashMap::new();for word in text.split_whitespace(){let x = map.entry(word).or_insert(0);*x += 1;}println!("{:?}",map);
运行上述代码,得到text的相同字符串的次数组成的map
有点累了,再来首音乐:
五、trait:定义共享的行为
还记得上面泛型开篇的那个找最大数字的方法么?get_max_number
就是这个:
fn get_max_number<T: std::cmp::PartialOrd + Copy>(array : &[T])->T{let mut result : T = array[0];for &x in array {if x > result{result = x;}}result}
前面就直接说了为啥,但是没有这个过程的来源。这里就来看看这个,先去掉这个std::cmp::Copy运行看看
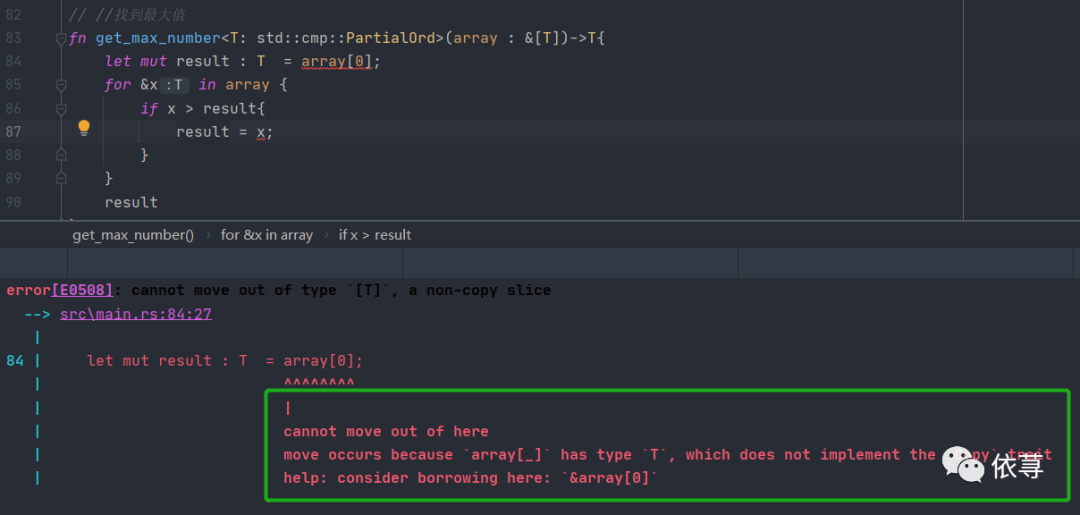
首先这里IDE都已经把报错了,也就谈不上编译了。
看看这个错误信息
move occurs because `array[_]` has type `T`, which does not implement the `Copy` trait
Rust说,这个T是没有实现这个'Copy' trait
然后加上这个std::cmp::Copy这就好了,看下这个std::cmp::Copy源码
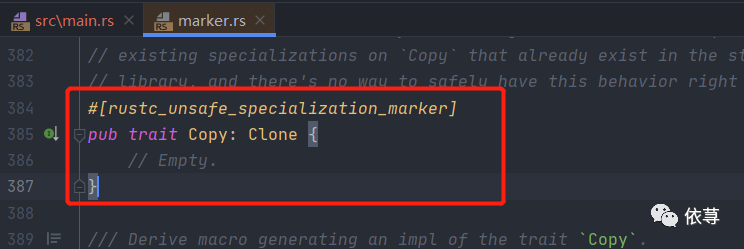
这里的是一个trait关键字定义的,非前面说到的结构体、枚举、方法、函数等任意一种定义形式
然后这个std::cmp::Copy还实现了std::cmp::Clone
同样的std::cmp::Clone也是一个trait
那么,下面先了解下这个trait
一个类型的行为由其可供调用的方法构成。如果可以对不同类型调用相同的方法的话,这些类型就可以共享相同的行为了。trait 定义是一种将方法签名组合起来的方法,目的是定义一个实现某些目的所必需的行为的集合。
从上面这段话可以看出,trait定义了相同行为的方法签名。
新建包my_trait
文件lib.rs
例如下面的定义trait:
//定义traitpub trait Summary{fn summary(&self)->String;}
这里使用 trait 关键字来声明一个 trait,后面是 trait 的名字,在上面例子中是 Summary。在大括号中声明描述实现这个 trait 的类型所需要的行为的方法签名,在这个例子中是 fn summarize(&self) -> String。
trait 体中可以有多个方法:一行一个方法签名且都以分号结尾。
这点和Java的接口类似。
但是,Rust的trait的方法可以有默认实现,比如<lib.rs>:
//定义traitpub trait Summary{//只定义方法签名fn summary(&self)->String;//有默认实现的trait方法fn summary_other()->String{String :: from("hello lgli")}//只定义方法签名fn summary_other_for(&self)->String;}
上面有一个方法有默认的实现
下面定义结构体,同时定义实现这个trait的方法函数
//定义traitpub trait Summary{//只定义方法签名fn summary(&self)->String;//有默认实现的trait方法fn summary_other()->String{String :: from("hello lgli")}//只定义方法签名fn summary_other_for(&self)->String;}#[derive(Debug)]pub struct Life{pub year : String,pub is_happiness : String}//没有实现默认trait方法impl Summary for Life{fn summary(&self) -> String {format!("Life has been more than {} years, your life is happy? {}",self.year, self.is_happiness)}fn summary_other_for(&self) -> String {format!("Having lived for more than {} years , \your life is seriously whether someone else is happy or not ? {}",self.year, self.is_happiness)}}#[derive(Debug)]pub struct Study{pub name : String,pub content : String}//实现所有trait方法impl Summary for Study{fn summary(&self) -> String {format!("I learned the course of {}, \the main content of which was the {}",self.name, self.content)}fn summary_other() -> String {String :: from("hello lgli, the best for you happiness")}fn summary_other_for(&self) -> String {format!("I learned the course of {}, and at the same time, \I also brought some content about {} to others",self.name, self.content)}}
在实现trait方法的时候,trait已经有默认实现的方法,就可以不用实现了<比如Life>,当然也可以实现<比如Study>
调用测试,main.rs:
use my_trait;use my_trait::Summary;fn main() {let life = my_trait :: Life{year: "18".to_string(),is_happiness: "yes".to_string()};let string = Summary::summary(&life);println!("trait原生调用没有实现方法的trait:");println!("{}",string);println!("trait原生调用有默认实现方法的trait:");let string = Summary::summary_other(&life);println!("{}",string);println!("trait原生调用没有实现方法的trait:");let string = Summary::summary_other_for(&life);println!("{}",string);println!("Life结构体调用trait方法:");let my_life = life.summary();println!("{}",my_life);let my_life_for = life.summary_other_for();println!("{}",my_life_for);let study = my_trait :: Study{name: "history".to_string(),content: "the modern and contemporary history of China".to_string()};println!("Study结构体调用trait方法:");let my_study = study.summary();println!("{}",my_study);let my_study_other = study.summary_other();println!("{}",my_study_other);let string = Summary::summary_other(&study);println!("{}",string);let my_study_for = study.summary_other_for();println!("{}",my_study_for);}
当直接通过trait调用trait方法签名时,需要传入有实现该方法的结构体
调用trait结构体有默认的实现方法时,如果结构体本身没有实现,则调用trait默认实现
上述测试,编译运行:
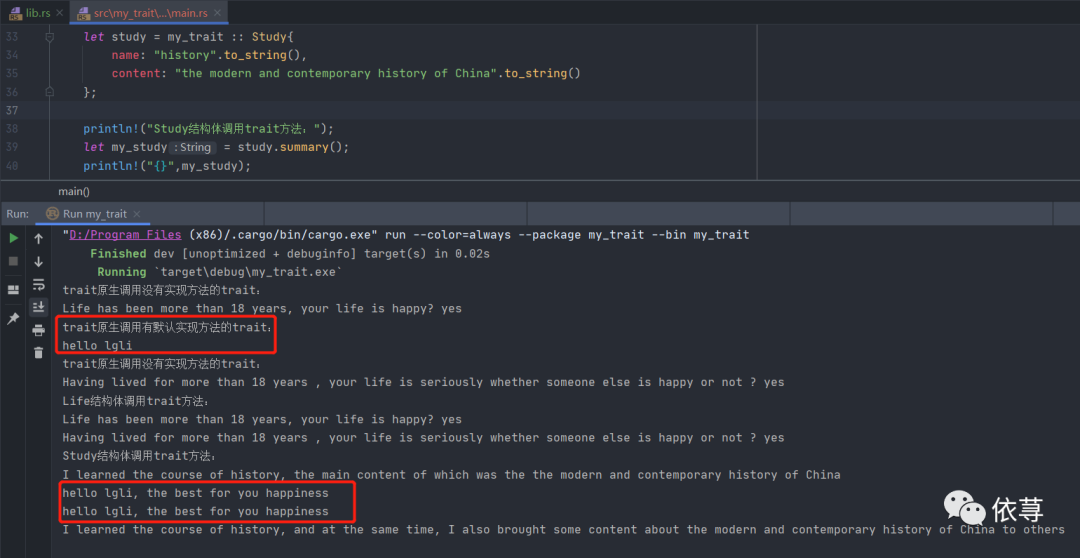
结构印证了前面描述的话
除此之外,trait方法,还可以作为参数传入函数体中,比如下列代码,lib.rs :
//trait作为参数传入函数pub fn trait_param(trait_obj : &impl Summary)->String{trait_obj.summary_other_for()}
测试下 main.rs
use my_trait;fn main() {let study = my_trait :: Study{name: "history".to_string(),content: "the modern and contemporary history of China".to_string()};let trait_param = my_trait::trait_param(&study);println!("{}",trait_param);}
编译运行:
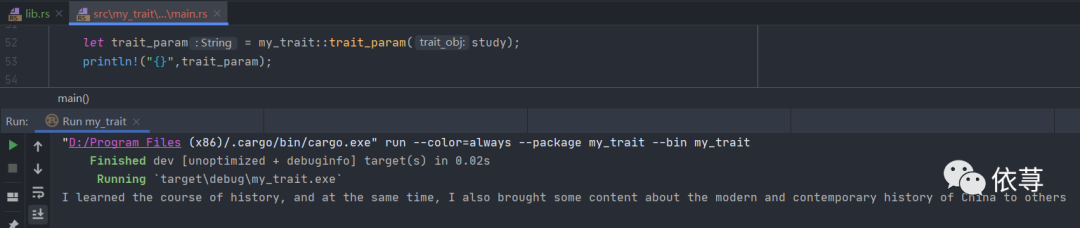
trait作为参数传入函数还有另外的写法,比如:
pub fn trait_param_other<T : Summary>(trait_obj : &T)->String{trait_obj.summary()}
上述写法,是不是特别的眼熟了,回头去想想找最大数字的函数
get_max_number
传入了一个泛型T 同时指定了泛型T必须实现Copy
为什么必须实现Copy?
还记得函数中有这么一句代码:
let mut result : i8 = array[0];
这里,如果array[0]是堆中数据或栈中数据,这里是不一样的概念,如果是堆中数据,这里就会发生移动,之后不在有效,但是后面是有效的,所以,如果是堆中数据,这里需要加引用&,而代码并没有加,所以必须指明T的类型了,必须实现了Copy的类型,才可以实现没有移动的赋值。类似的PartialOrd为了比较大小,前面也提到了,也是相同的道理,不是所有类型都可以通过>符号来比较大小的。
六、生命周期和引用有效性
之前的Rust介绍了引用,同时,今天的前面例子中也有用到引用,比如上面的trait作为参数传入的时候,其实也只是传入的引用,那么说明引用在Rust中占据了举足轻重的作用,所以有必要了解得更多一些。
新建二进制crate,reference
看下面代码:
fn main() {let y;{let x = 5;y = &x;}println!("{}",y);}
这里首先申明了一个y,接着在一个匿名的函数体内,对y赋值为x的引用,最后打印输出y
上述代码编译是会报错的。
在匿名函数体内,x是有效的,但是离开了这个匿名函数体,x不在有效,那么x的引用也同样不在有效,所以编译不通过:
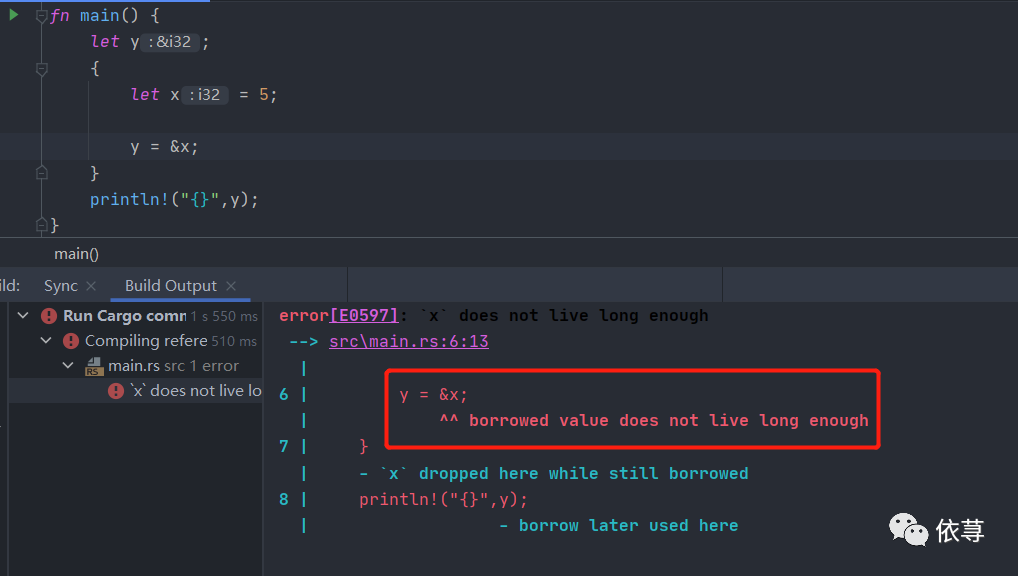
编译器说,租借的值,没能活得足够长
用下面这个图来表示:
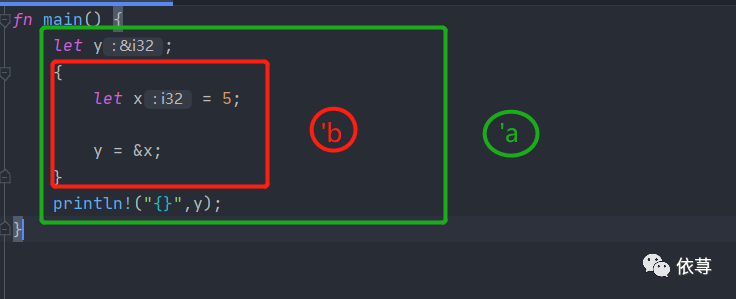
'b:表示x的生命周期时间
'a:表示y的生命周期时间
很明显,y的生命周期大于x的,所以这种情况下,y引用x的值是不会被Rust认同的,因为引用已经超出了被引用对象的作用域。
在看下面这个例子:
fn main() {let s1 = String::from("lgli");let s2 = "hello";let max_length_str = get_long_str(s1.as_str(),s2);println!("{}",max_length_str);}fn get_long_str(s1 : &str,s2 : &str)->&str{if s1.len() > s2.len() {s1}else if s1.len() < s2.len() {s2}else{"the same length"}}
上述代码,主要目的是想找到2个字符串中比较长的一个,并输出。
但是很遗憾,也是会报错的。为什么?
首先看这个get_long_str方法,方法传入了2个引用,然后返回值也是一个引用,这里就存在一个引用值作用域的问题,编译器无法得知返回值的引用是来自s1或者s2,又或者两者都不是<比如两者相等长度的时候,返回的是slice>,这些情况编译器无法得知的,这就造成的一个结果是,当返回这个引用对象之后,其作用域应该是多大的问题?
为了避免可能出现的作用域溢出,即租借的值,可能会超出其作用域范围,所以上述代码会在编译期直接编译不通过。
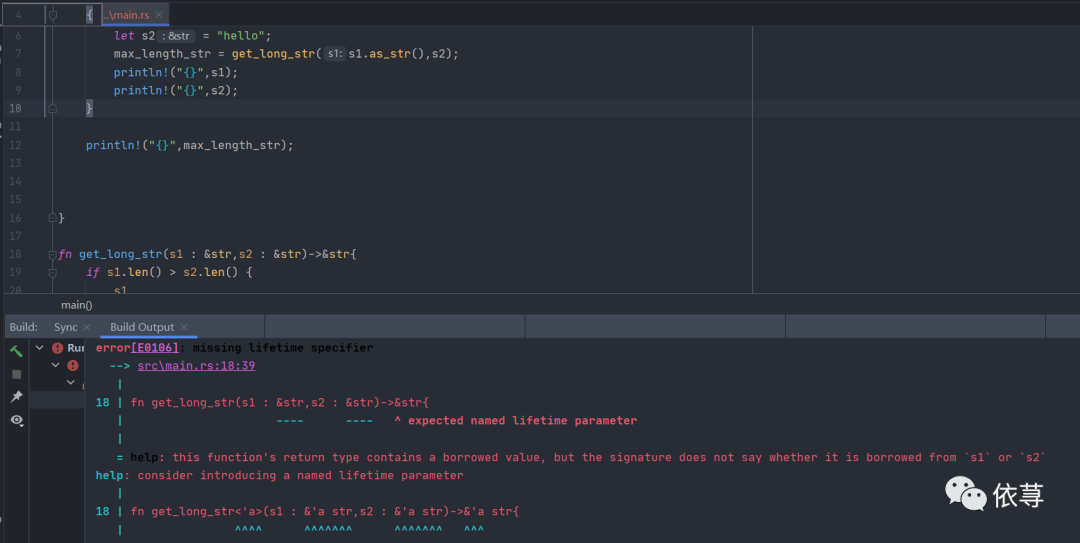
然后看这里编译器提出了一个解决方法
编译器说,将函数签名和返回值写成这样:
fn get_long_str<'a>(s1 : &'a str,s2 : &'a str)->&'a str
这个地方,就先来看看这个'a是个什么玩意儿?
'a其实就是一个生命周期注解语法,通过这个生命周期注解语法,告诉编译器,函数返回值的生命周期和函数参数s1和s2中最小生命周期是一样的,即返回值生命周期与参数中生命周期最小的那个参数的生命周期等同。
在Rust中,生命周期参数名称必须以撇号(')开头,其名称通常全是小写,类似于泛型其名称非常短。'a 是大多数人默认使用的名称。生命周期参数注解位于引用的 & 之后,并有一个空格来将引用类型与生命周期注解分隔开。生命周期注解,只是申明变量生命周期,并不会改变变量的生命周期。
这里有一些例子:我们有一个没有生命周期参数的 i32 的引用,一个有叫做 'a 的生命周期参数的 i32 的引用,和一个生命周期也是 'a 的 i32 的可变引用:
&i32 // 引用&'a i32 // 带有显式生命周期的引用&'a mut i32 // 带有显式生命周期的可变引用
这时候,根据提示,改造上述代码:
fn get_long_str<'a>(s1 : &'a str,s2 : &'a str)->&'a str{if s1.len() > s2.len() {s1}else if s1.len() < s2.len() {s2}else{"the same length"}}
编译运行:
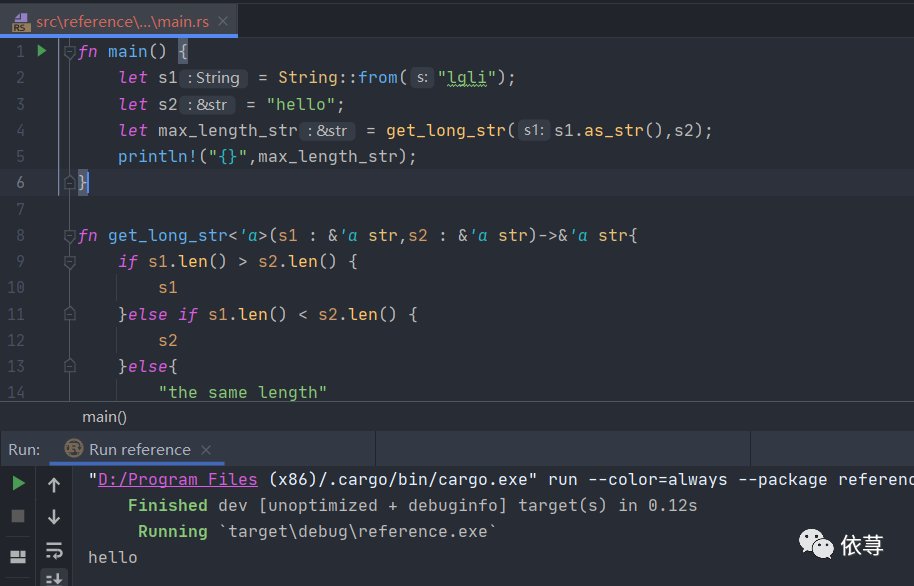
仔细看上述函数
fn get_long_str<'a>(s1 : &'a str,s2 : &'a str)->&'a str
这个函数体内因为可能返回到s1或者s2,所以必须给参数都加上生命周期注解,那么有没有一种情况,指定返回s1,从而达到不需要给s2加生命周期注解呢?
比如:
fn get_long_str<'a>(s1 : &'a str,s2 : &str)->&'a str{println!("{}",s2);s1}
这里是肯定可以的,因为返回值确定了是s1,所以可以编译通过并运行
那么同等的道理,这样子也是可以的:
fn get_long_str<'a>(s1 : &str,s2 : &str)->&'a str{println!("{}",s2);println!("{}",s1);"你好"}
那么这里就有一个疑问了,指定生命周期注解是为了保证作用域的一致性,在上述这种情况下,结果值没有和s1或者s2任何一个相关联,那么是否可以不需要指定生命周期注解呢?
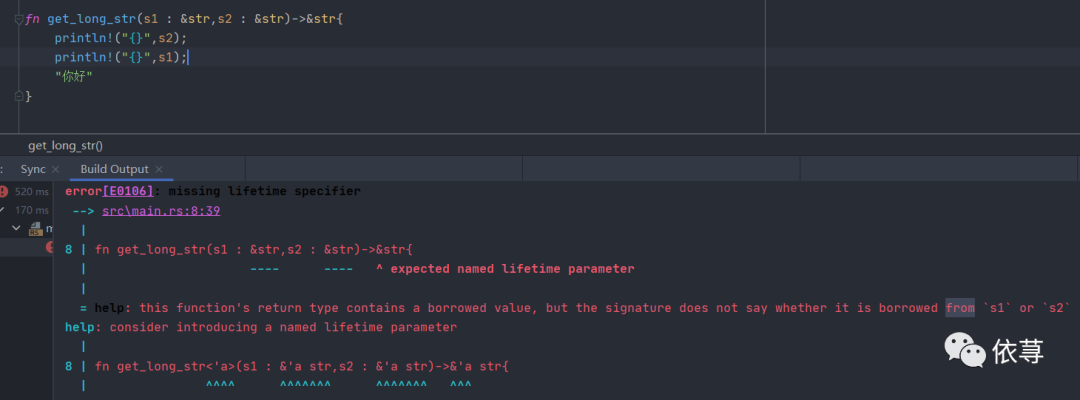
这里是也是编译不通过的,但是至于为什么,其实我确实是有点懵。
那么下面这样子呢:
fn get_long_str<'a>(s1 : &str,s2 : &str)->&'a str{println!("{}",s2);println!("{}",s1);let result = String::from("你好");result.as_str()}
上述代码无法编译通过,因为引用对象本身离开这个方法之后就失效了,即Rust会产生一个空的引用<悬垂引用>,这肯定也是不行的。这个时候,解决的办法就是返回一个拥有所有权的数据类型,比如:
fn get_long_str<'a >(s1 : &str,s2 : &str)->&'a str{println!("{}",s2);println!("{}",s1);"你好"}
这里的返回值是一个拥有所有权的str,所以离开函数作用域时不会被清除掉的,知道其引用对象离开作用域,会被清除掉,因为引用对象会获取"你好"的所有权。
下面看下生命周期注解在结构体中的应用,
之前定义的结构体,属性对象都是拥有其所有权的,比如:
#[derive(Debug)]struct School{name : String,}
这里定义了一个学校结构体,拥有了一个名字name属性,name属性的值是一个String类型,name属性同时还拥有了String的所有权。
学校可能还有分校,所以这里定义一个分校属性,这时候需要思考一个问题了,这个分校属性是否也需要分校数据类型的所有权?可以只是一个引用么?
从内存来看,获取一个引用其实就够了,不需要在开辟一个内存地址来保存一个可能和其他地方一样的数据,所以考虑这个属性是一个引用:
//定义学校#[derive(Debug)]struct School{name : String,branch_school : &BranchSchool}//定义分校#[derive(Debug)]struct BranchSchool {name : String}
上述代码是会报错的,因为这里引用就会存在引用值生命周期的问题,即要保证branch_school指向正确的数据对象,必须要保证branch_school的引用具有和结构体School一样的生命周期,所以应该这么来定义:
//定义学校#[derive(Debug)]struct School<'a,'b>{name : String,branch_school : &'a BranchSchool,teachers : Vec<Teacher>,teaching_building: &'b TeachingBuilding}//定义分校#[derive(Debug)]struct BranchSchool {name : String}//定义老师#[derive(Debug)]struct Teacher{name : String,age : i8,address : String}//定义一个教学楼#[derive(Debug)]struct TeachingBuilding{name : String,address : String}
测试编译运行:
let teacher = Teacher{name: "lgli".to_string(),age: 18,address: String :: from("here is my home")};let mut teachers: Vec<Teacher> = Vec::new();teachers.push(teacher);let teaching_building = TeachingBuilding{name: "第一教学楼".to_string(),address: "在心中".to_string()};let branch_school = BranchSchool{name: "第一分校".to_string()};let school = School{name: String :: from("清华大学"),branch_school: &branch_school,teachers,teaching_building: &teaching_building};println!("{:#?}",school);
编译运行:
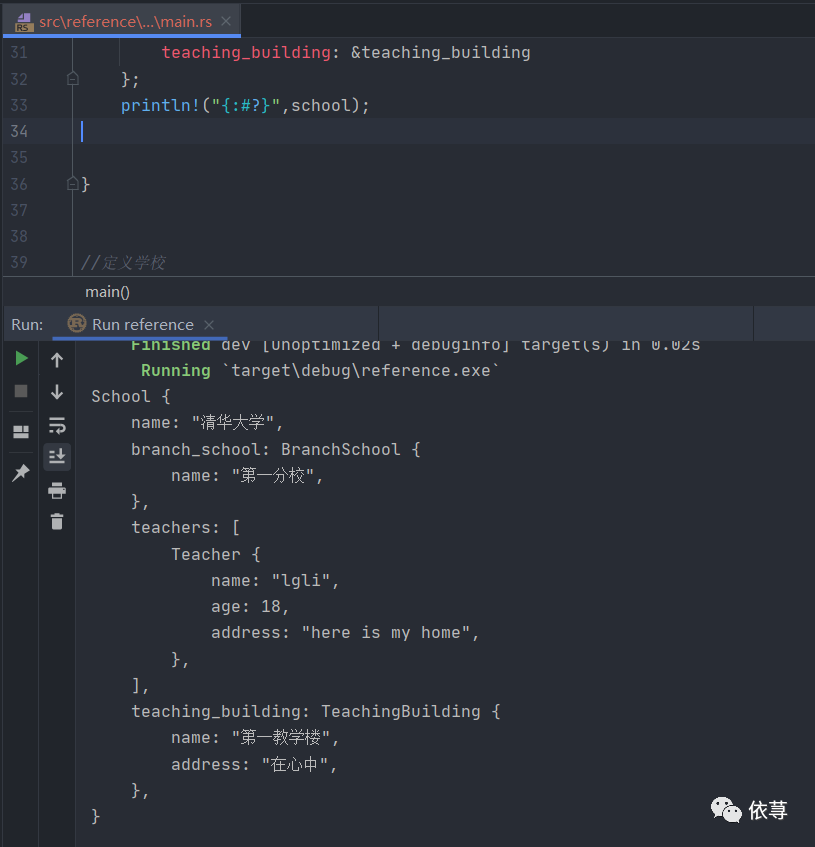
结果体参数表明,所有引用的对象,其存活时间都一定要比结构体大。
比如,如果下面这样就会编译错误:
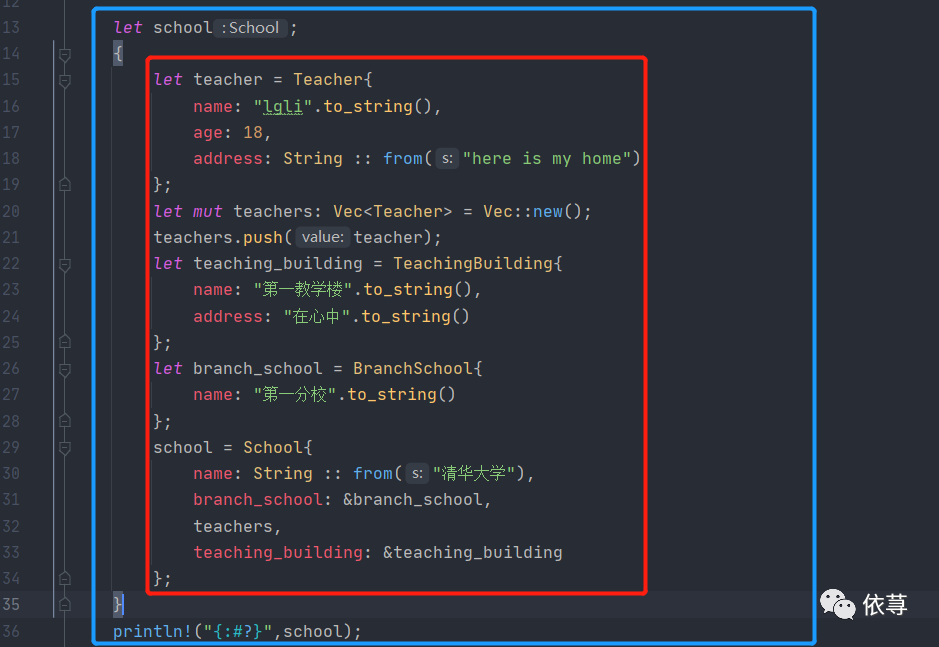
很明显,上述代码,结构体的作用域大于结构体属性引用的作用域了,所以编译报错!
在这里,了解了一个重要的信息,所有的引用都有生命周期。
但是有细心的朋友,会发现,在前面讲Rust的slice的时候,有写过一个函数,返回值和参数也都是引用,但是没有指定生命周期注解:
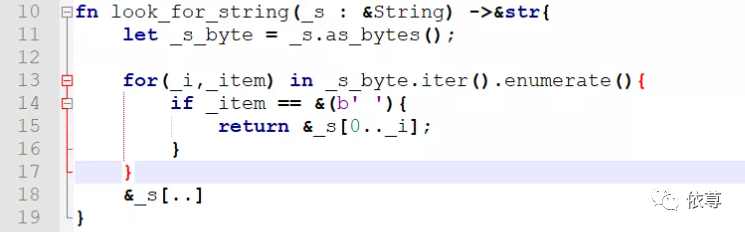
上述代码也是可以通过编译并运行的,这里没有指定生命周期。
这个函数没有生命周期注解却能编译是由于一些历史原因:在早期版本(pre-1.0)的 Rust 中,这的确是不能编译的。每一个引用都必须有明确的生命周期。那时的函数签名将会写成这样:
fn look_for_string<'a>(_s: &'a str) -> &'a str
在编写了很多 Rust 代码后,Rust 团队发现在特定情况下 Rust 程序员们总是重复地编写一模一样的生命周期注解。这些场景是可预测的并且遵循几个明确的模式。接着 Rust 团队就把这些模式编码进了 Rust 编译器中,如此借用检查器在这些情况下就能推断出生命周期而不再强制程序员显式的增加注解。这些模式被称为生命周期省略规则(lifetime elision rules)。这并不是需要我们遵守的规则;这些规则是一系列特定的场景,此时编译器会考虑,如果代码符合这些场景,就无需明确指定生命周期。
函数或方法的参数的生命周期被称为 输入生命周期(input lifetimes),而返回值的生命周期被称为 输出生命周期(output lifetimes)。
Rust编译器采用三条规则来判断引用何时不需要明确的注解:
1、每一个引用的参数都有它自己的生命周期参数。换句话说就是,有一个引用参数的函数有一个生命周期参数:fn foo<'a>(x: &'a i32),有两个引用参数的函数有两个不同的生命周期参数,fn foo<'a, 'b>(x: &'a i32, y: &'b i32),依此类推。
2、如果只有一个输入生命周期参数,那么它被赋予所有输出生命周期参数:fn foo<'a>(x: &'a i32) -> &'a i32。
3、如果方法有多个输入生命周期参数并且其中一个参数是 &self 或 &mut self,说明是个对象的方法(method), 那么所有输出生命周期参数被赋予 self 的生命周期。第三条规则使得方法更容易读写,因为只需更少的符号。
所以前面这个方法,刚好适用于第二条规则,所以是可以不用添加生命周期注解的。
关于第三条规则,主要体现在结构体方法上,比如:
impl<'a,'b> School<'a,'b>{fn get_school_name(&self,str : &str)->&str{println!("{}",str);self.name.as_ref()}}
这里结构体依然用到前面的学校结构体,然后有一个方法,get_school_name
方法,传入了两个引用,同时返回了引用,本来根据生命周期原则,需要指定生命周期注解,但是这里没有,依然可以编译通过运行
这里就是满足了前面的第三条规则,输出生命周期等于self生命周期
一种特殊的生命周期:静态生命周期,它可以在程序中一直存活。
静态生命周期,用'static表示:比如:
let s: &'static str = "I have a static lifetime";看下面这个函数:
fn get_max_length<'a , T:Display>(s1 : &'a str ,s2 : &'a str, an : T)->&'a str{println!("{}",an);if s1.len > s2.len(){s1}else{s2}}
这里是一个使用泛型参数和生命周期的例子,改方法是可以编译通过的,这里仅仅是想说明,泛型参数和生命周期,都是可以一起写在函数后的尖括号的!
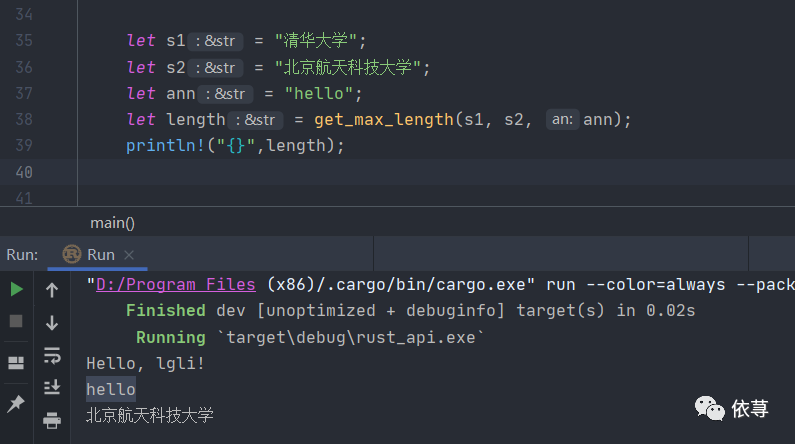
这里的函数签名还可以这么写:
fn get_max_length<'a , T>(s1 : &'a str ,s2 : &'a str, an : T)->&'a str where T : Display
即,使用关键字where,在函数返回值后面跟上泛型实现的trait
七、Rust错误处理
在Rust中,如果代码出现了异常或者错误怎么办?其他语言,类似Java、Python都有exception一说,同时可以使用try捕获异常信息。
在Rust中,没有捕获异常,只有panic!宏处理异常。当执行panic!宏之后,程序会打印出一个错误信息,展开并清理栈数据,然后接着退出
新建panic二进制包:
下面尝试下调用panic!
panic!("这儿有问题!");运行:
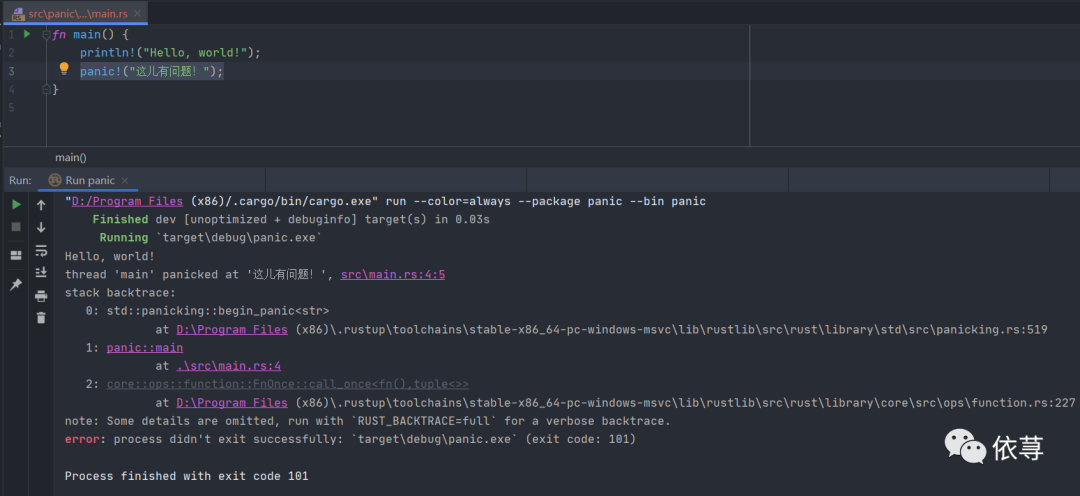
下面打印了堆栈信息,同时回溯找到异常来源。
panic!宏打印堆栈信息,有几个参数设置
RUST_BACKTRACE=0:可以理解为最简单的错误信息,即只会打印出程序具体哪一行的错误信息。
RUST_BACKTRACE=1:稍微多一些的堆栈信息,涵盖了具体panic!宏具体的错误信息
RUST_BACKTRACE=full:所有的堆栈信息,也是最为齐全的错误打印
这里就不挨个试了
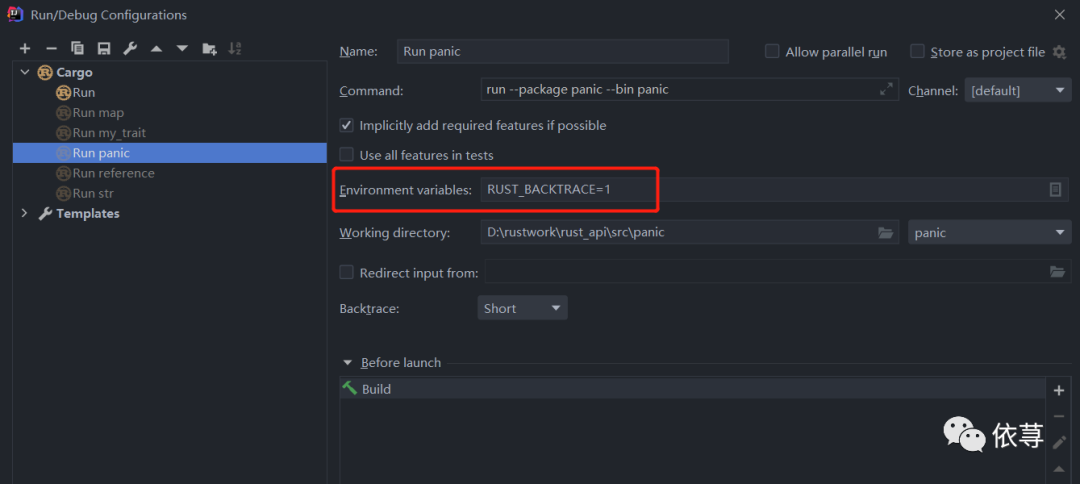
设置方式,可以通过命令行,直接在cargo run前面加上这个参数,即:
$ RUST_BACKTRACE=full cargo run
开发工具里,就根据不同开发工具设置了,我这里使用的是IEDA,直接在edit configurations
这里,使用到的panic!都是会使程序停止运行,称为不可恢复错误,但是有时候,并不是所有的错误都是不可恢复的,比如看下面代码:
let result = File::open("D:\\1.txt");这里尝试打开D盘下的一个1.txt文件,如果没有这个文件,应该算是异常了,这个时候,究竟是否需要panic!一般来说是需要根据实际情况来看的,比如如果没有这个文件或许只是要给个提示,程序依然需要进行下去。
所以File::open()函数提供了返回值为Result的枚举,可以根据实际的情况来判断是否需要panic!
Result枚举,是Rust提供的枚举类:
pub type Result<T> = result::Result<T, Error>;T 代表成功时返回的 Ok 成员中的数据的类型,而 E 代表失败时返回的 Err 成员中的错误的类型。因为 Result 有这些泛型类型参数,可以将 Result 类型和标准库中为其定义的函数用于很多不同的场景
比如:
let result = File::open("D:\\1.txt");let result = match result {Ok(file) => {file}Err(error) => {panic!("打开文件失败:{:?}",error)}};println!("{:?}",result);
这里通过match匹配模式分别来处理这两种情况
上述代码,在错误的时候还是panic!了,其实很多时候,是不需要panic!的,比如,根据不同的错误信息,做不同的操作:
let result = File::open("D:\\1.txt");let result = match result {Ok(file) => {file}Err(error) => match error.kind() {ErrorKind::NotFound => {}ErrorKind::PermissionDenied => {}ErrorKind::ConnectionRefused => {}ErrorKind::ConnectionReset => {}ErrorKind::ConnectionAborted => {}ErrorKind::NotConnected => {}ErrorKind::AddrInUse => {}ErrorKind::AddrNotAvailable => {}ErrorKind::BrokenPipe => {}ErrorKind::AlreadyExists => {}ErrorKind::WouldBlock => {}ErrorKind::InvalidInput => {}ErrorKind::InvalidData => {}ErrorKind::TimedOut => {}ErrorKind::WriteZero => {}ErrorKind::Interrupted => {}ErrorKind::Other => {}ErrorKind::UnexpectedEof => {}}};println!("{:?}",result);
上述代码,可以根据异常的各种原因,针对性的进行操作,这里就不举例了
失败时的错误简写:
File::open("D:\\1.txt").unwrap();或者
File::open("D:\\1.txt").expect("打开文件错误!");错误传播,当调用一个函数时,可能出现错误,这个时候,可以将这个错误抛出去,传播给调用者,比如:
fn fun_error_spread() -> Result<String,io::Error>{let f = File::open("D:\\1.txt");let mut f = match f {Ok(file) => file,Err(e) => return Err(e),};let mut s = String::new();match f.read_to_string(&mut s) {Ok(_) => Ok(s),Err(e) => Err(e),}}
上述代码,描述了一个打开并读取文件为String操作,如果打开读取正常,则返回值Result泛型包含正确的信息,即String,否则返回错误Error。
同时错误传播还可以简写为?
上述代码也可写为:
fn fun_error_spread() -> Result<String,io::Error>{let f = File::open("D:\\1.txt")?;let mut s = String::new();f.read_to_string(&mut s)?Ok(s)}
上述代码量就减小了许多了,但是功能依然等同于前面的方式,这里的?号等同于错误的时候返回的Err,即return Err()
而且在?后面还可以链式调用函数,上述代码还可以改进:
fn fun_error_spread() -> Result<String,io::Error>{let mut s = String::new();File::open("D:\\1.txt")?.read_to_string(&mut s)?;Ok(s)}
这里是在函数中调用,如果直接在主程序中调用呢?
fn main() -> Result<(), Box<dyn Error>>{File::open("D:\\1.txt")?;Ok(())}
在main函数中调用错误传播,需要在main函数中添加返回值Result。
这里的()表示返回正确的任意数据,
同时Box<dyn Error>被称为"trait对象"("trait object"),这个在后面会讲到,这里可以理解 Box<dyn Error> 为使用 ? 时 main 允许返回的 “任何类型的错误”。
这里是关于Rust的错误的常见处理方式,那么在实际的项目中,是否需要panic!或者不panic!,这个取决于自己的逻辑决定。
八、编写测试代码
前面写到的所有函数,方法,模块儿,结构体,泛型,trait等等,写测试类的时候,都是在二进制的crate中进行的,这样子其实很不方便,很多时候,希望可以灵活的测试我们正在写的任何一段代码,而不想多余的新建代码文件这个时候,测试代码就来了。
Rust提供了代码测试方法。
在项目中新建crate库(非二进制)my_test
这时候,可以看见Rust在lib.rs中已经帮我们写好了一段代码:
#[cfg(test)]mod tests {#[test]fn it_works() {+ 2, 4);}}
这里的#[cfg(test)]表明crate库是一个测试库,同时在函数it_works中前面有一个#[test],表示这是一个测试函数。
assert_eq!宏来断言2+2是否等于4
同时测试函数是可以运行的:
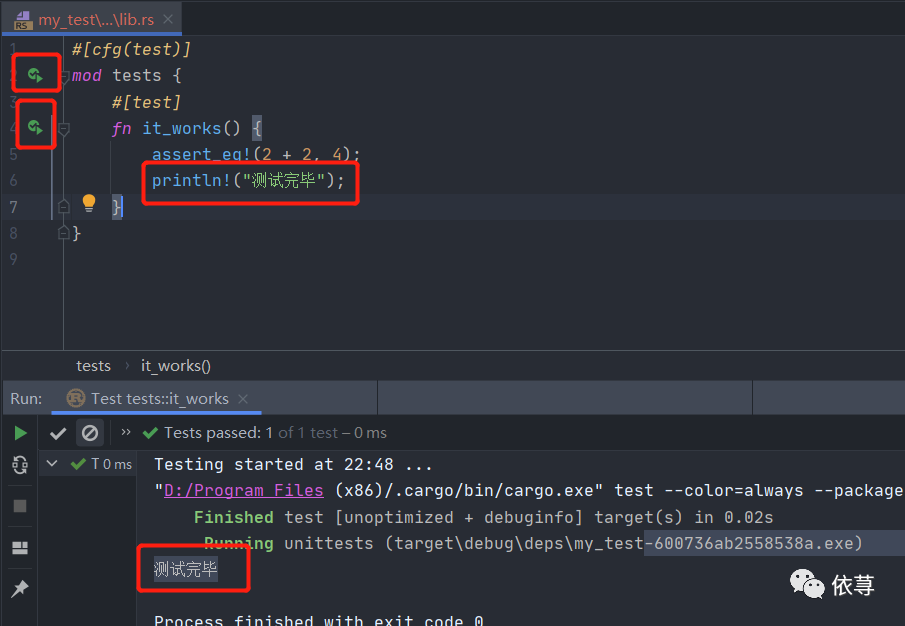
如上图所示,mod前的运行按钮,可以保证模块儿下的所有测试函数都会执行一次,函数上的运行按钮,则保证当前函数执行一次,如果执行有问题,则运行按钮会出现红色颜色区分,控制台会异常。
比如:
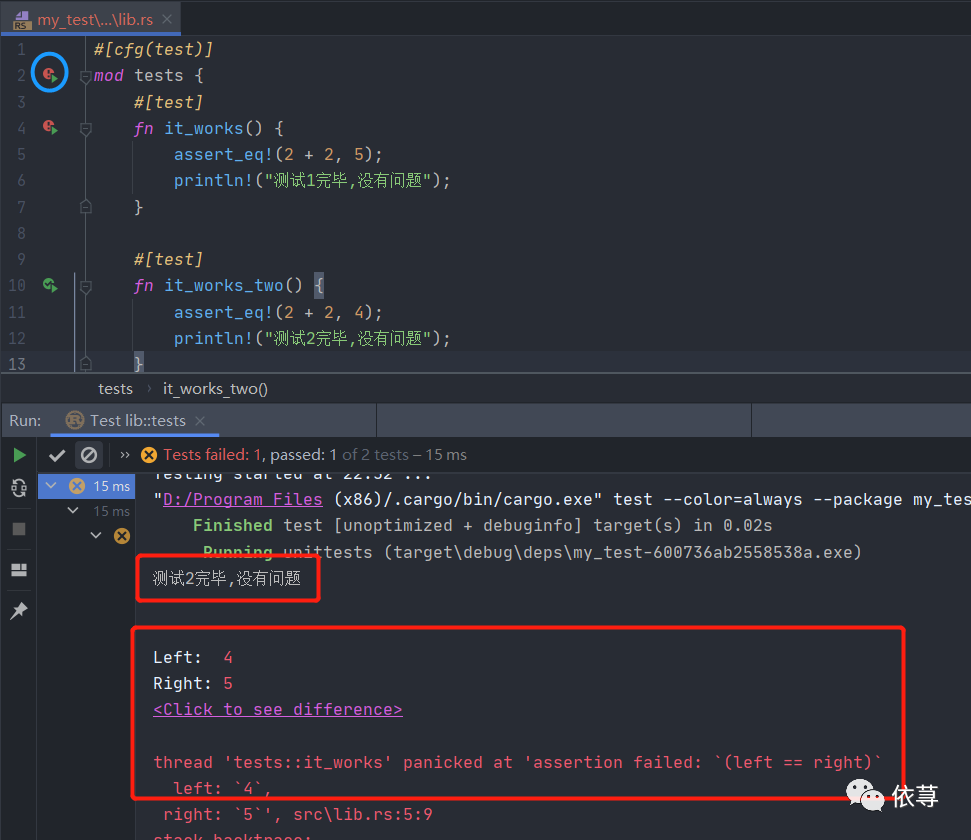
这里是执行的mod上的运行,第一个函数执行错误,第二个执行正确,同时第一个的错误堆栈信息都打印出来了
关于测试的一些宏,下面举例常见的一些宏,其他的可以参照官方API文档
assert_eq!,断言是否相等,比如上面的例子
assert!,断言获取结果是否为true,为false时panic!,比如assert!(true)
assert_ne!,和assert_eq!恰好相反
#[should_panic]检查代码是否按照期望处理错误
单元测试类比较简单,但是很实用,官方提供了很多宏,可以查看官方API。
https://doc.rust-lang.org/std/index.html
编写好测试类可以更能保证代码的安全和正确性。
本期分享内容有点多,得多写代码温习下!(#^.^#)
基本上,Rust的基础就到这儿了,之后会有一些中高级一些的Rust,比如多线程、IO、智能指针等等。
点击下面公众号获取更多
欢迎点赞转发,谢谢