
使用 Java 手写一个 Redis 服务端!

零,起因
我为什么要造redis这个轮子?
破除对redis神秘感。 “基础服务中台”的同事们在开会讨论redis云,以及redis代理。 开一个redis资源并不是容易事,为什么不可以不可以写成java直接推送到未来云上,简单方便。
以这个思路我开始使用业余时间研究了redis的tcp通讯原理与redis命令,出发点是写一个redis云代理之类的云管理软件,但是还是忍不住写成了java版的redis,本文章主要分享redis的编写心路历程。
一,redis通讯与Netty
1,tcp
连到Redis服务器的客户端建立了一个到6379端口的TCP连接。
虽然RESP在技术上不特定于TCP,但是在Redis的上下文中,该协议仅用于TCP连接(或类似的面向流的连接,如unix套接字)。
使用netty作为通讯框架。
2,协议
Redis客户端和服务器端通信使用名为 RESP (REdis Serialization Protocol) 的协议。虽然这个协议是专门为Redis设计的,它也可以用在其它 client-server 通信模式的软件上。RESP 协议在Redis1.2被引入,直到Redis2.0才成为和Redis服务器通信的标准。这个协议需要在你的Redis客户端实现。
RESP 是一个支持多种数据类型的序列化协议:简单字符串(Simple Strings),错误( Errors),整型( Integers), 大容量字符串(Bulk Strings)和数组(Arrays)。
RESP在Redis中作为一个请求-响应协议以如下方式使用:
客户端以大容量字符串RESP数组的方式发送命令给服务器端。服务器端根据命令的具体实现返回某一种RESP数据类型。在 RESP 中,数据的类型依赖于首字节:
单行字符串(Simple Strings):响应的首字节是 "+" 错误(Errors):响应的首字节是 "-" 整型(Integers):响应的首字节是 ":" 多行字符串(Bulk Strings):响应的首字节是"$" 数组(Arrays):响应的首字节是 "*" 另外,RESP可以使用大容量字符串或者数组类型的特殊变量表示空值,下面会具体解释。RESP协议的不同部分总是以 "\r\n" (CRLF) 结束。字符串 "foobar" 编码如下:
"$6\r\nfoobar\r\n"
实际redis命令是什么样的,比如SET lhjljh lhjkjhkh
*3\r\n$3\r\nSET\r\n$6\r\nlhjljh\r\n$8\r\nlhjkjhkh
RESP协议中文详情文档:https://www.redis.com.cn/topics/protocol.html。
3,编解码
由于RESP天然是面向处理命令的,所以没办法直接把redis消息像grpc或者dubbo那样直接序列化和反序列化消息。并且每个内容限定了长度,很适合做成及时序列化、零拷贝,直接针对输入流做反序列化和序列化,这一点与Protostuff序列化协议的设计很类似。所以序列化直接将服务端接收的流直接转成值。
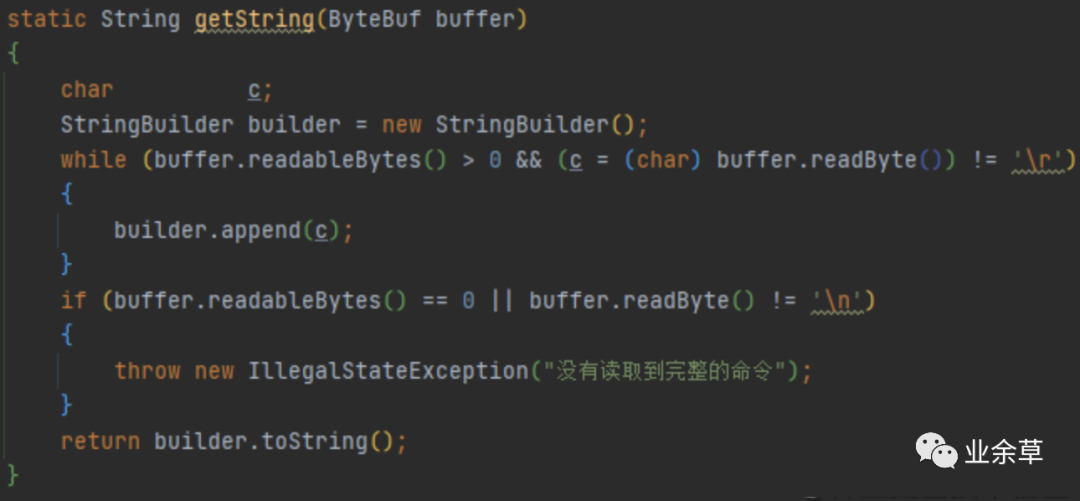
编解码的实体类直接加入redis server 的处理某一个长连接tcp客户端的管道上。
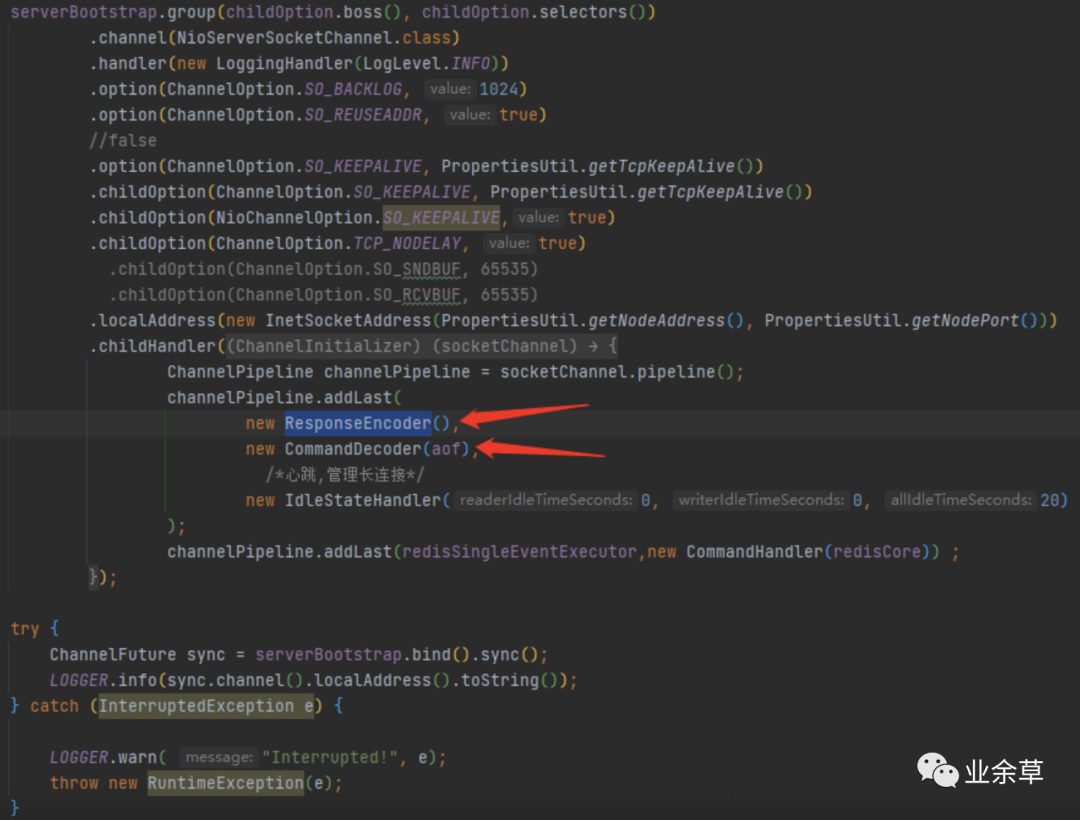
如果有兴趣研究可以看c语言原版的源码分析。
4,命令处理
将消息解码成RESP,还需要将RESP转为Command对象,这里因为是java语言,方法与类绑定,编写上和理解上会更加容易。但是会增加一些开销。
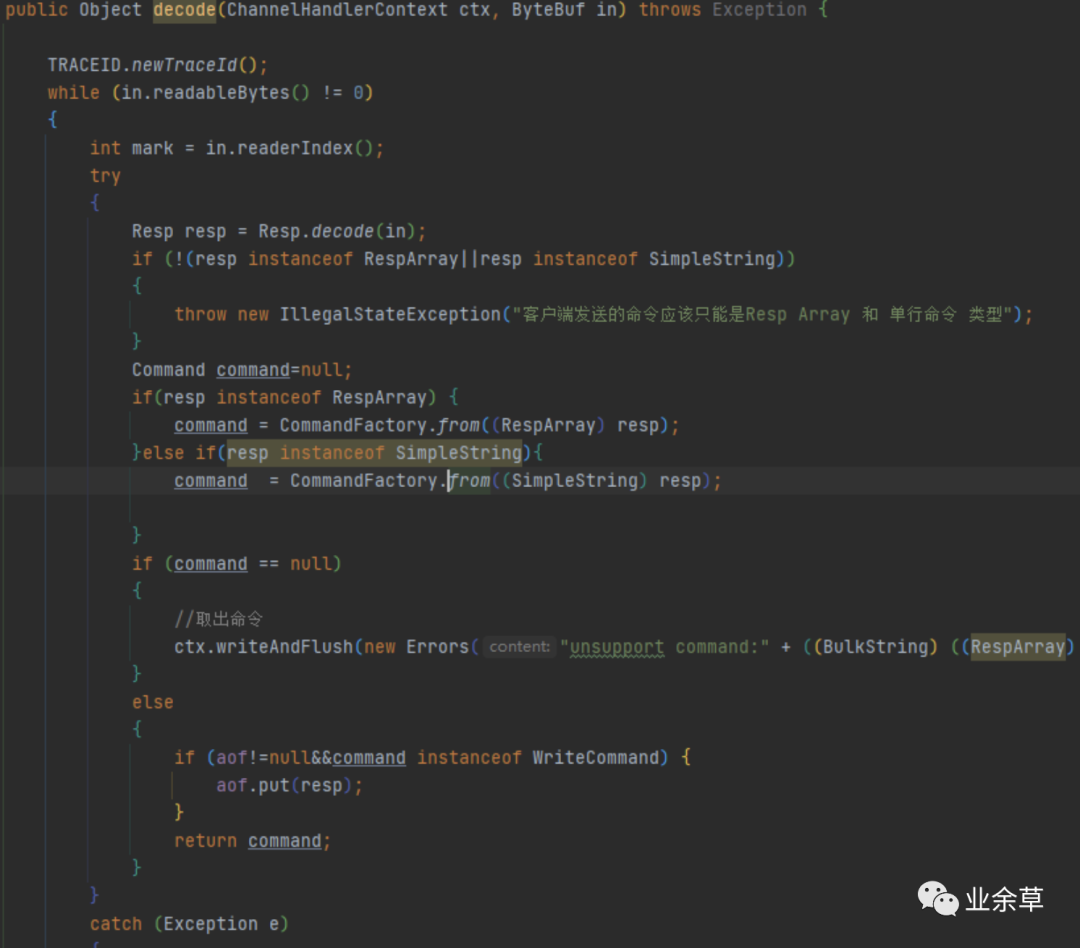
二,redis 的数据结构
1,底层主结构
底层主树使用跳表ConcurrentSkipListMap实现,没用hash类map的原因是服务端是集群后,客户端可能使用hash路由,会导致服务端严重的hash冲突,性能大打折扣。
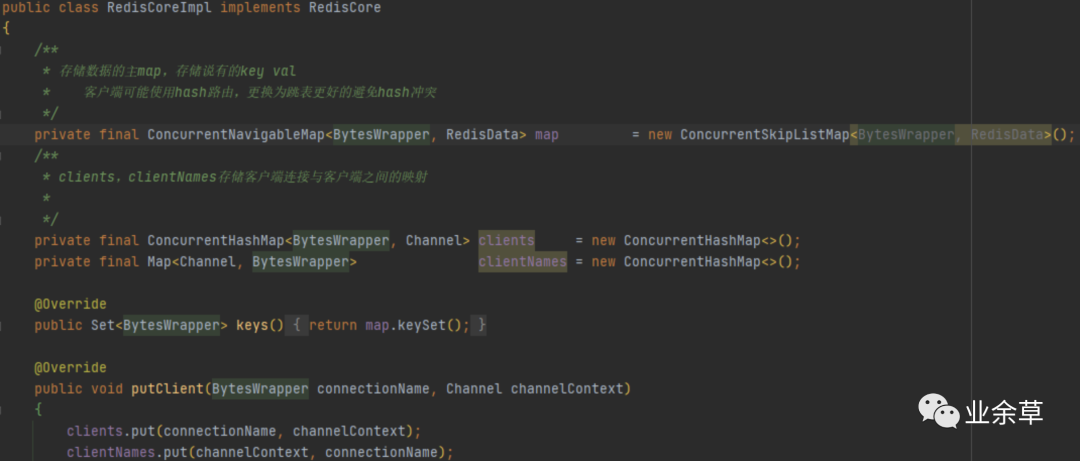
key为封装的“String”,重写了equals方法避免相同的key但是在jvm中指针不同
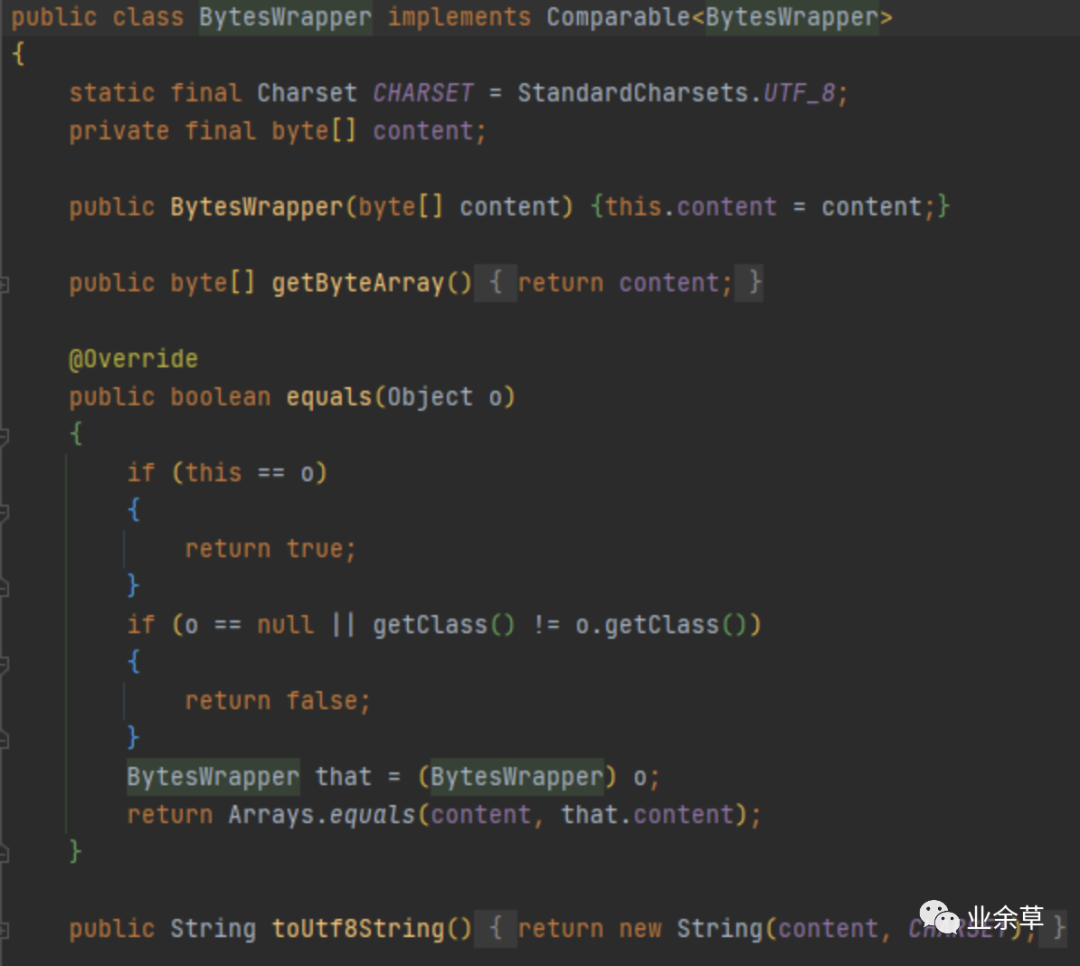
value是一个接口,实现类是redis的五大基本类型,所有数据类型都包含超时时间
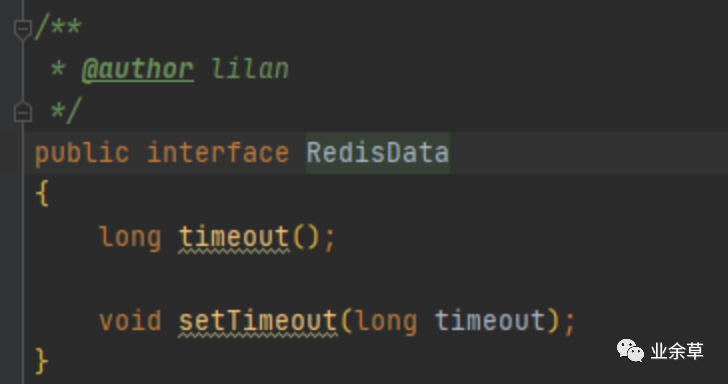
2,key
用封装的值做value的原因是方便统一管理。
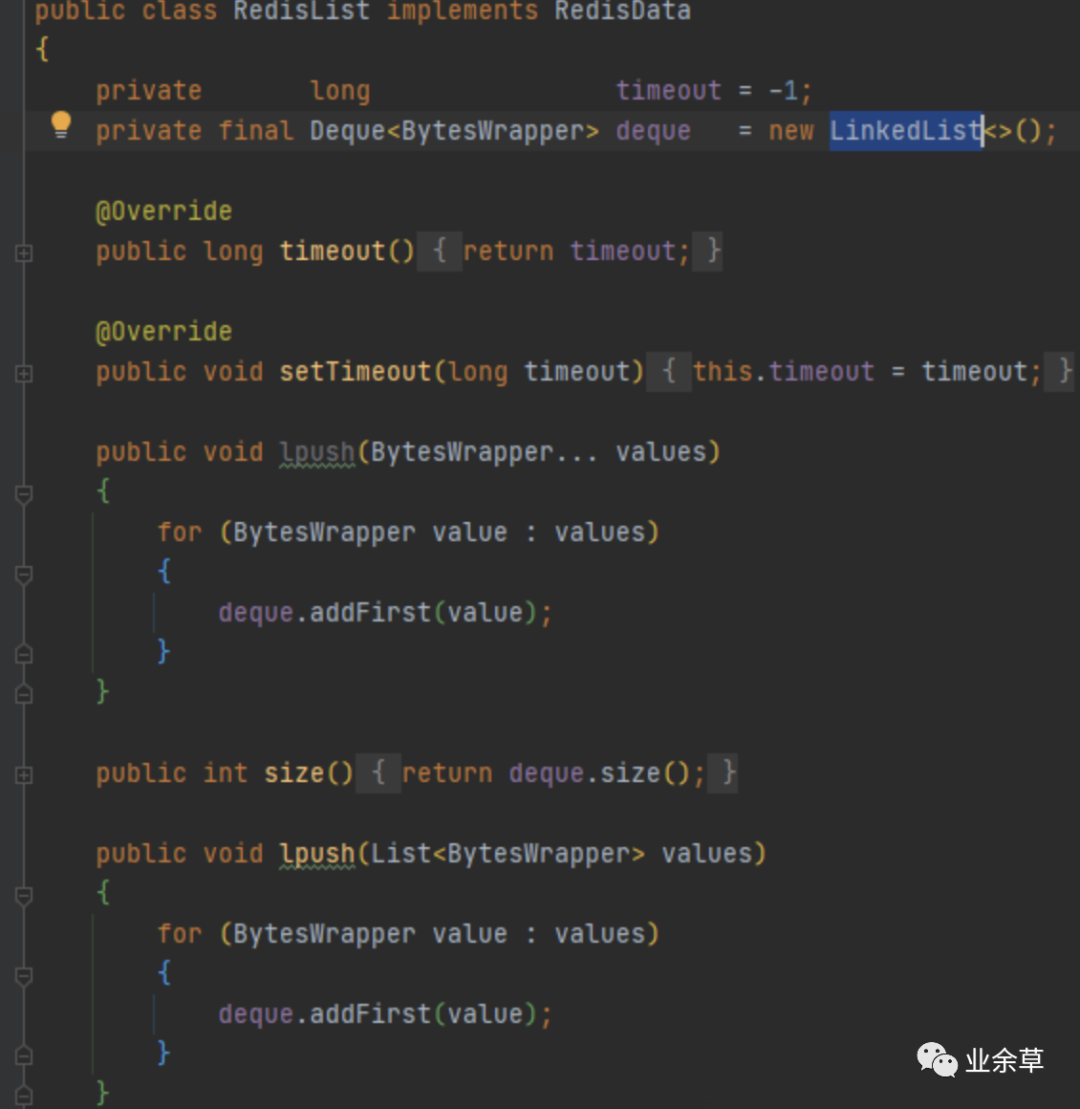
3,list
底层使用LinkedList的原因是LinkedList实现了多种接口,实现各种命令直接调用其现成实现的方法即可
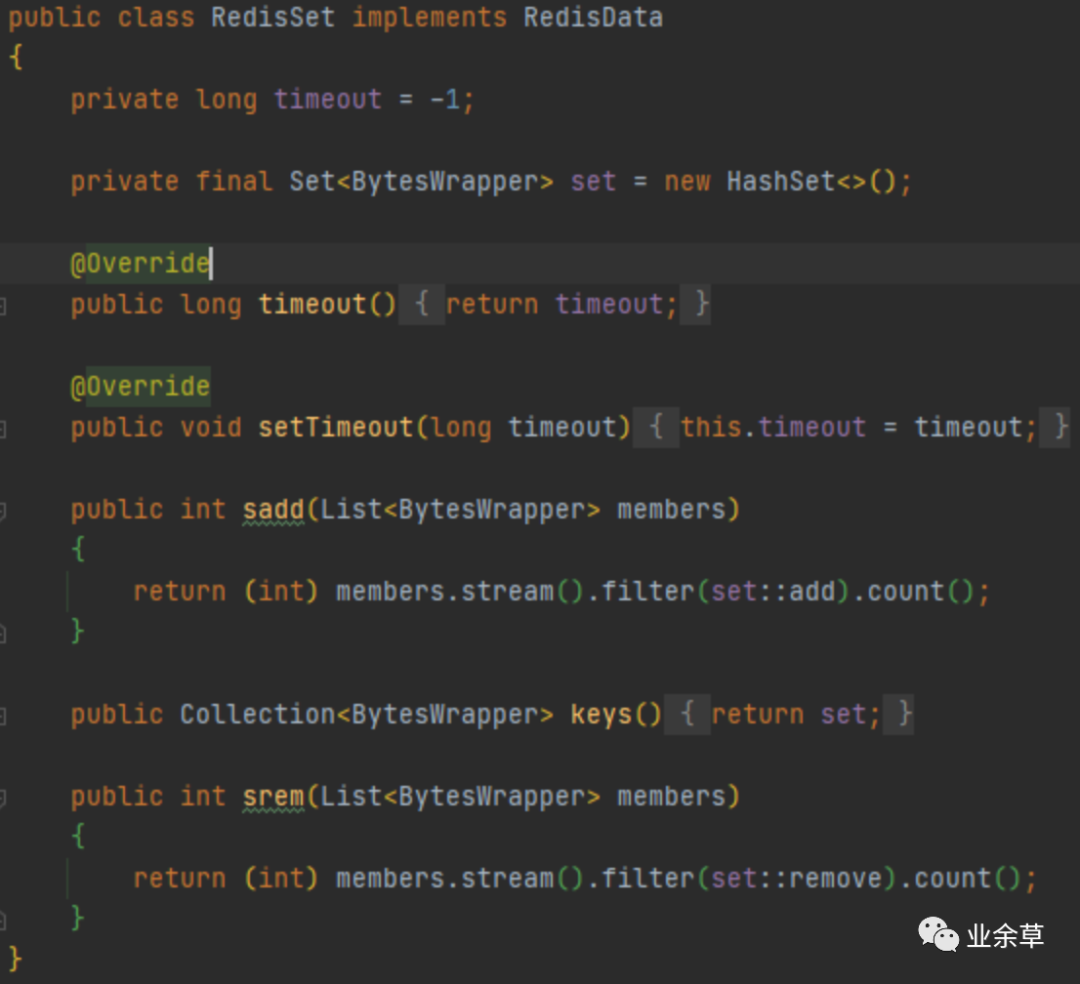
4,set
底层使用HashSet,redis里的set没有多特殊
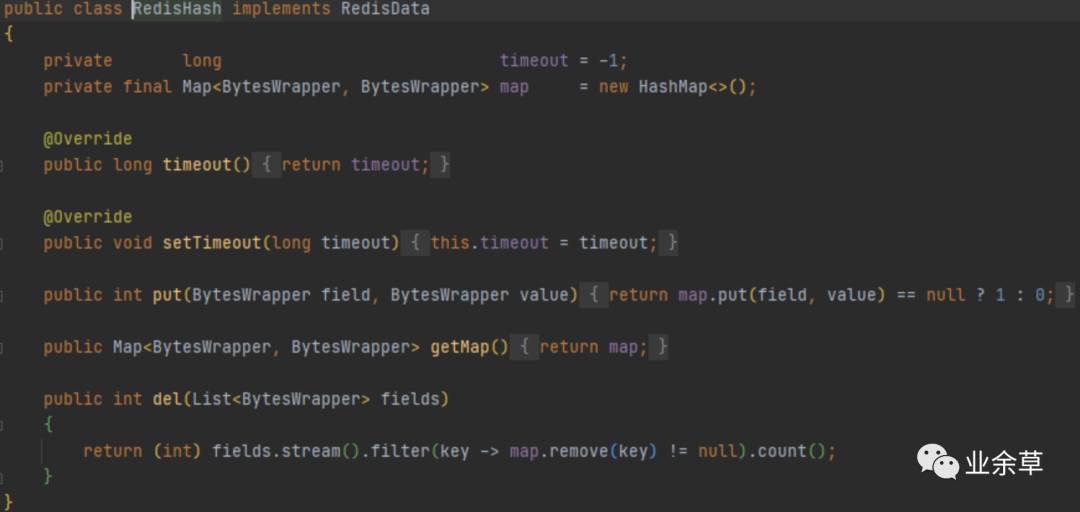
5,hash
底层使用HashMap,这里和开头说的HashMap不冲突。为什么不用跳表?压缩列表很巧妙,大抵的意思就是将通信收到的数组直接填充到list中,将list直接按照次序直接当map使用,主要是0拷贝的思想,无需创建新资源,性能极高,但注意压缩列表与压缩无关。感兴趣可以查看 redis 压缩列表。
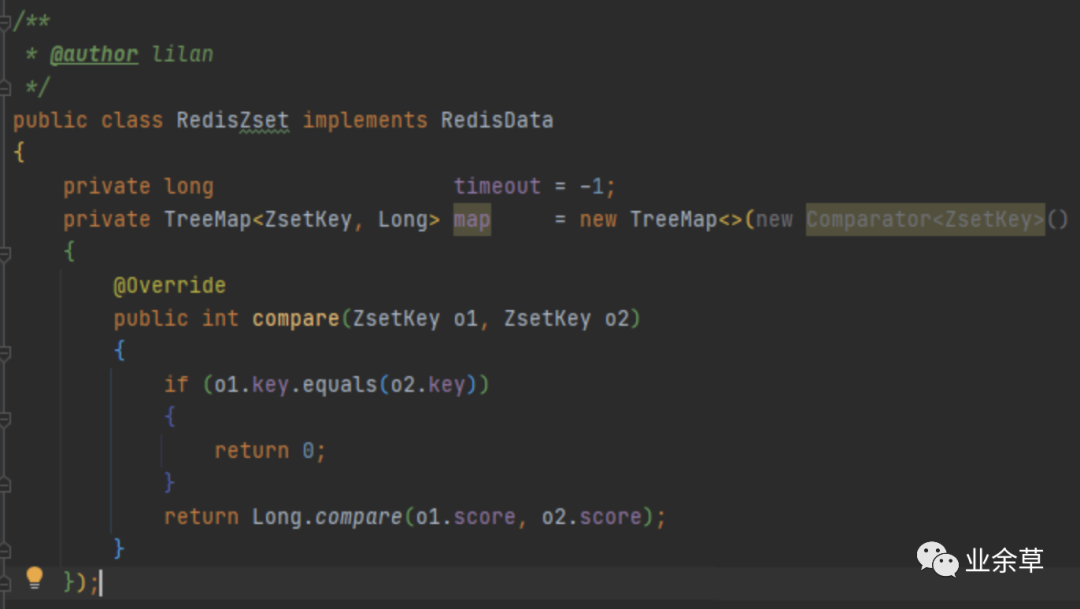
6,zset
首先需要封装一个带有值和分值的对象
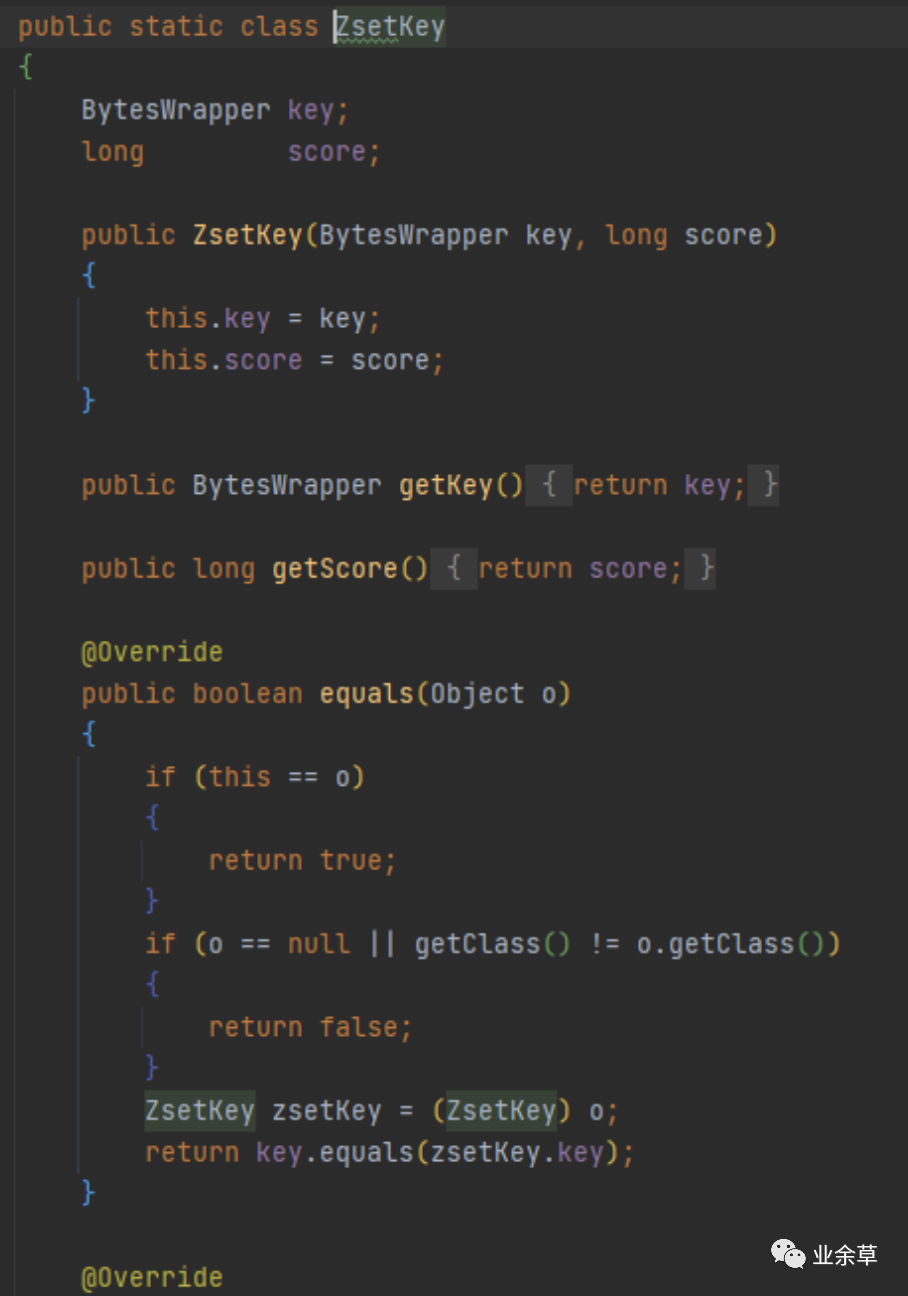
再用TreeMap重写compare方法即可,使用TreeMap原因是他天然有良好的排序功能,很多hash一致路由的算法都用的TreeMap二开。
三,redis AOF 持久化
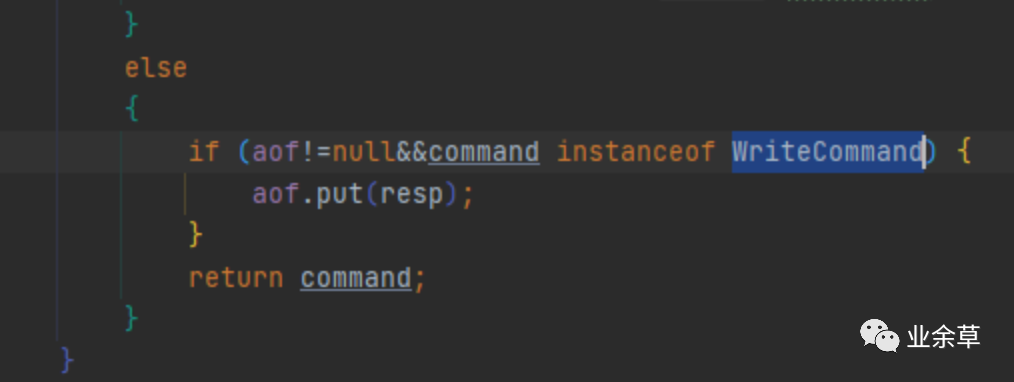
1,aof线程与tcp线程解耦,即写缓冲
再解析redis命令时,将redis写命令添加到写aof日志的队列中
这里自己封装了一个堵塞队列,单线程吞吐量可以达到3000W /s是LinkedBlockingQueue的6到10倍,完全可以胜任此场景
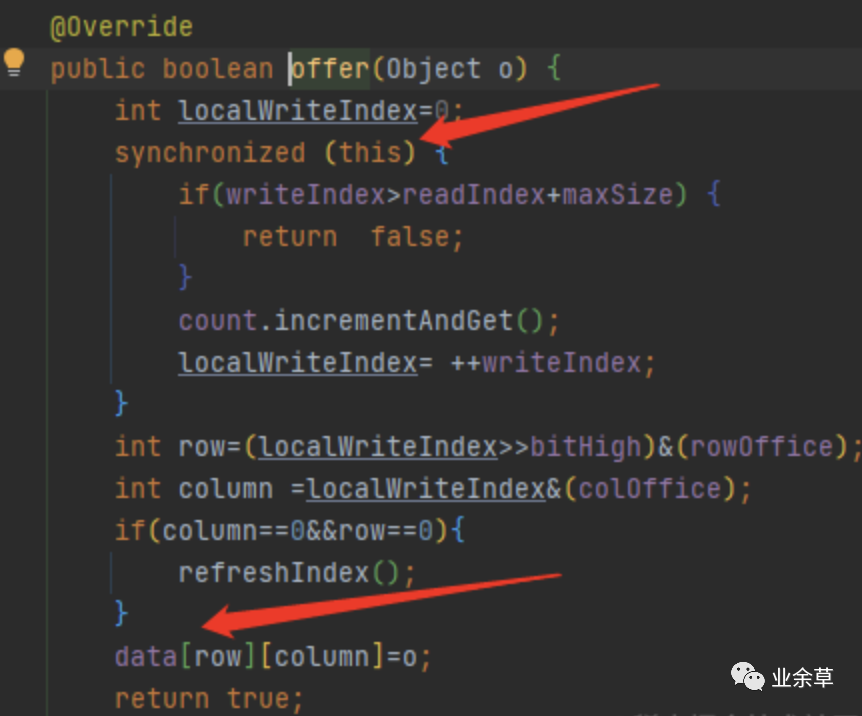
RingBlockingQueue吞吐量非常高的原因是使用了内存连续页的机制。

c语言原版的实现:redis原版的aof缓冲实现http://bbs.redis.cn/forum.php?mod=viewthread&tid=573&highlight=aof
2,aof持久化协议
aof协议一句话概括就是将写命令,追加到日志中,开始时将命令读取,当作收到网络的命令执行即可。由于协议过于简单,这里就不贴链接了。
aof之日格式如下图:
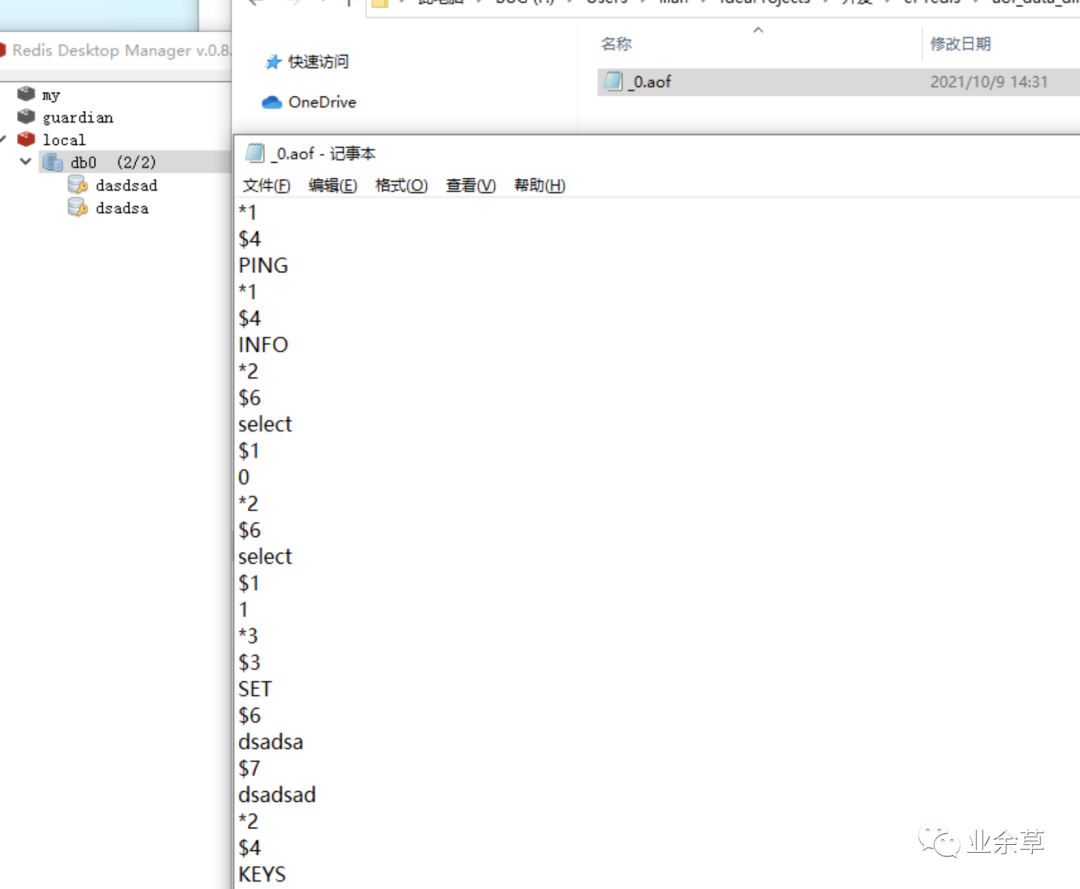
3,aof的加载与存储实现
这里读写内存都是用的内存文件映射,好处是读写性能好,坏处是可能会出现内存泄漏,调试期间比较麻烦。
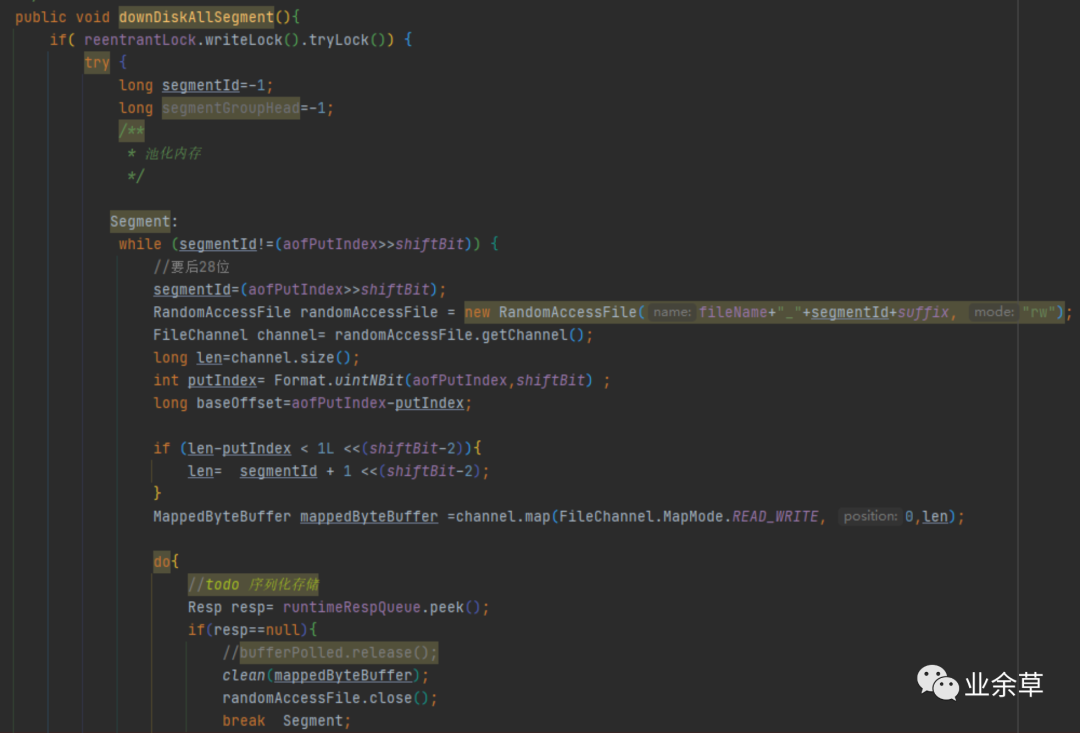
4,内存文件映射与面向对象
这里存储和加载aof文件的代码都是面向过程的,看起来非常复杂。实际上之前是按照面向对象写的,封装成了行对象,调用落盘符和拾起方法就可以写入和读取aof中的命令,但是TPS仅为10w/s,后来权衡后改为面向过程,吞吐量提升到了100W的TPS以上。
四,redis 的集群特性
1,主从
这里很容易联想到mysql的只从,很多场景下会使用基于mysql主从的读写分离,或者zk的主从。但实际上redis的主从是不保证一致性的,个人认为redist的主从主要考虑的是cap的分布式容错性。因为redis主从不保证一致性,所以使用redis读写分离,可能造成一些不一致的问题,写写是一致的,但是读是不一致的,可以根据项目需要做取舍。
2,主从复制
redis的主从复制这里作者没看懂(可能也是一致性上有坑没动力去看),所以没写出来。
3,分片集群
redis集群主要分为几个唯独:主从、分区集群、代理。一般在redis客户端的视角下,主要是分区集群,根据发送给redis的key做hash、md5等操作,取一个所有客户端的共识值,将key和value发送,也就是客户端路由分布式软件的集群实现方式https://zhuanlan.zhihu.com/p/368407754,京东的redis集群设计https://zhuanlan.zhihu.com/p/424053018 到redis具体一个分片。
五,redis 的压测与调优
1,aof内存泄漏
开启aof压测发现出现了内存泄漏,后来发现是频繁新建内存池而造成的,所以将内存池池化,即aof对象中仅存在一个bytebuff内存池。
2,内存复用提升性能
这里编解码没有单独开辟byte数据接收bytebuff的数据进行编解码,编解码直接读取bytebuff进行编解码,没有出现内存拷贝,唯独新建了BytesWrapper对象,但存储的数据都是使用BytesWrapper对象,对内存新建/销毁的开销很少。
3,0.05%消息延迟超200ms排查
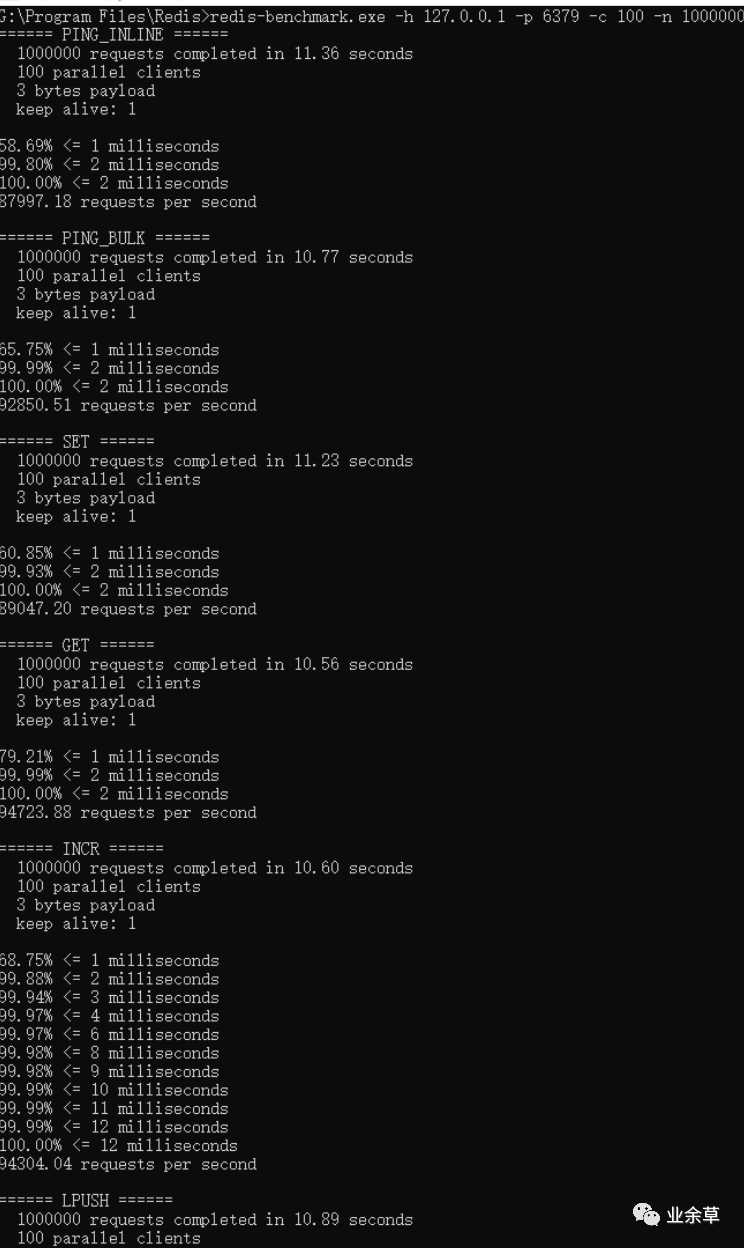
下图为c语言版的redis压测数据:
下图为java语言版的redis压测数据:
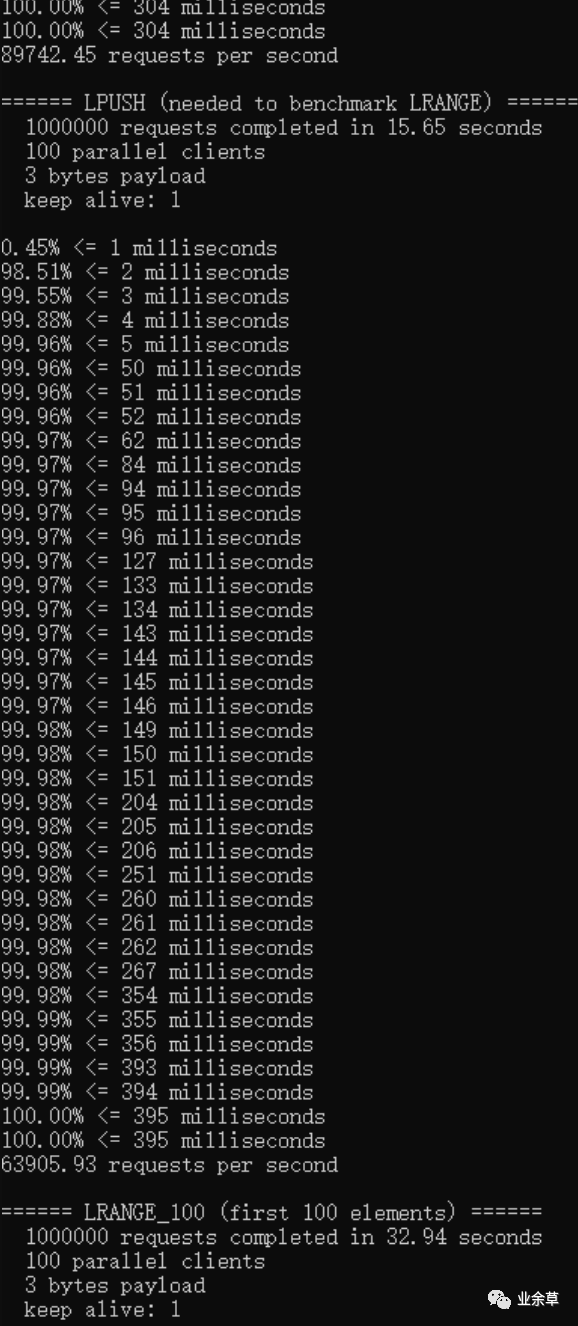
发现java版的redis会出现小概率消息延迟,为什么那?
4,性能表现
redis原版的性能大概是E5系列CPU 4-5w左右,上图中是使用amd芯片测试的数据。使用redis自带的压测工具,维持100个客户端连接,java版性能是c语言原版性能的75-90%左右,性能依然强悍。
源码
如需本文完整源码,可以加我微信:xttblog2,分享给你!