
这是一个middle fusion方法,CenterFusion,它先通过一个center point检测法得到图像的目标,然后和雷达检测结果做数据相关,采用的是一个frustum-based方法。最后关联的目标检测产生基于雷达的特征图补充图像特征,这样回归目标的深度、旋转角和深度
作者 | 黄浴
链接 | https://zhuanlan.zhihu.com/p/345845006
以前提到过此文(在想法中),WACV‘2021录取:“CenterFusion: Center-based Radar and Camera Fusion for 3D Object Detection“,作者来自田纳西大学。
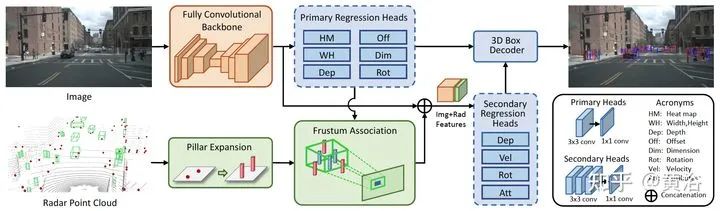
作者提供了代码:https://github.com/mrnabati/CenterFusion网络架构如图所示:跟摘要说的那样,细节见下面模块分析。
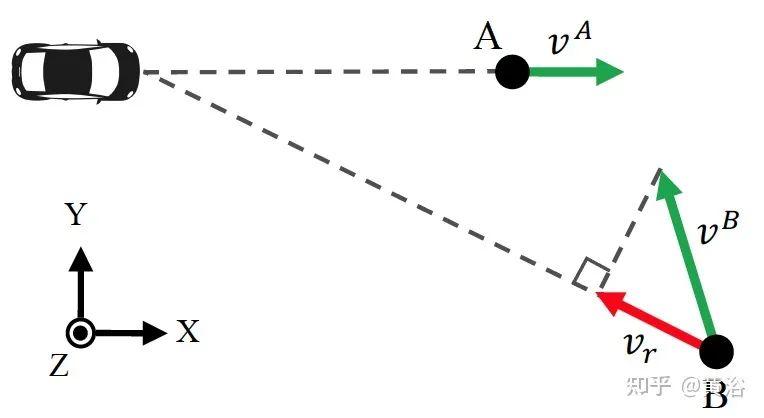
首先,需要搞清楚雷达信号检测的是径向深度和目标实际速度的不同,如图:
作者采用CenterNet方法,无锚单目的目标检测方法。其中keypoint的heatmap定义为: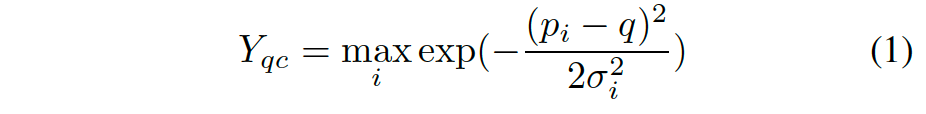
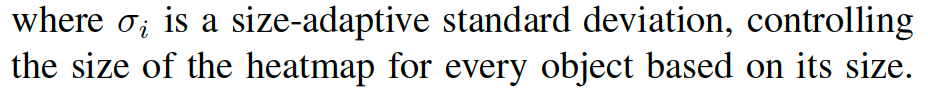 采用一个卷积encoder-decoder网络预测Y。基于此,回归3D目标的深度、尺寸和朝向。其训练分类损失,即focal loss:
采用一个卷积encoder-decoder网络预测Y。基于此,回归3D目标的深度、尺寸和朝向。其训练分类损失,即focal loss: CenterFusion利用CenterNet先得到一个初步检测,然后修正的DLA(deep layer aggregation)网络作为主干,在primary regression head中预测初步的3D目标信息,其中构成包括一个3X3的卷积层和一个1X1的卷积层。Frustum association是关键融合雷达和图像的机制。用图像2D框和其深度+大小的估计构建一个3D RoI frustum,如图所示:
CenterFusion利用CenterNet先得到一个初步检测,然后修正的DLA(deep layer aggregation)网络作为主干,在primary regression head中预测初步的3D目标信息,其中构成包括一个3X3的卷积层和一个1X1的卷积层。Frustum association是关键融合雷达和图像的机制。用图像2D框和其深度+大小的估计构建一个3D RoI frustum,如图所示:

如果有多个雷达检测点在这个RoI,直接取距离最近的一个。注意这里提到一个scaling factor可增大frustum尺寸,以便包容深度估计的误差。另外,目标高度的不准确,作者采用Pillar expansion对雷达点云做预处理。如图所示:第一行是雷达点云扩大成3D pillar的显示,第二行是直接把pillars和图像匹配的结果,相关较弱。第三行是frustum相关,减少了上面的深度值重叠,也防止背景目标(如大楼)错分类成前景。

图像和雷达的数据相关之后,可以提取雷达目标特征,深度和速度等。
 如果两个目标有重叠的heatmap区域,按距离取最近的。之后,这些特征进入secondary regression head,其结构包括3个3X3卷积层和一个1X1卷积层。最后结果需要经过一个box decoder得到。训练中regression head的损失采用SmoothL1 loss,center point heatmap采用focal loss,而attributes regression head基于Binary Cross Entropy (BCE) loss。
如果两个目标有重叠的heatmap区域,按距离取最近的。之后,这些特征进入secondary regression head,其结构包括3个3X3卷积层和一个1X1卷积层。最后结果需要经过一个box decoder得到。训练中regression head的损失采用SmoothL1 loss,center point heatmap采用focal loss,而attributes regression head基于Binary Cross Entropy (BCE) loss。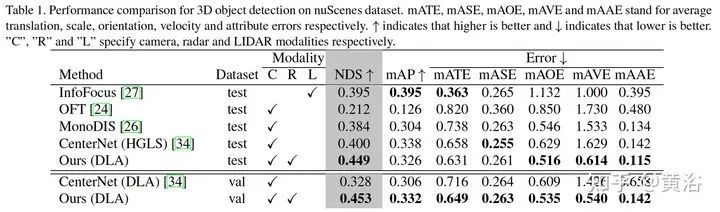
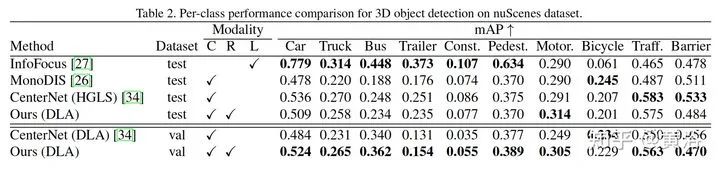
直观结果比较如下:1-2行CenterFusion,3-4行CenterNet。

雷达点云绿色,目标框GT红色,目标预测速度蓝色箭头。双一流大学研究生团队创建,专注于目标检测与深度学习,希望可以将分享变成一种习惯!整理不易,点赞三连↓
 下载APP
下载APP