
IO 密集型服务 性能优化实战记录
背景
项目背景
Feature 服务作为特征服务,产出特征数据供上游业务使用。服务压力:高峰期 API 模块 10wQPS,计算模块 20wQPS。服务本地缓存机制:
计算模块有本地缓存,且命中率较高,最高可达 50% 左右; 计算模块本地缓存在每分钟第 0 秒会全部失效,而在此时流量会全部击穿至下游 Codis; Codis 中 Key 名 = 特征名 + 地理格子 Id + 分钟级时间串;
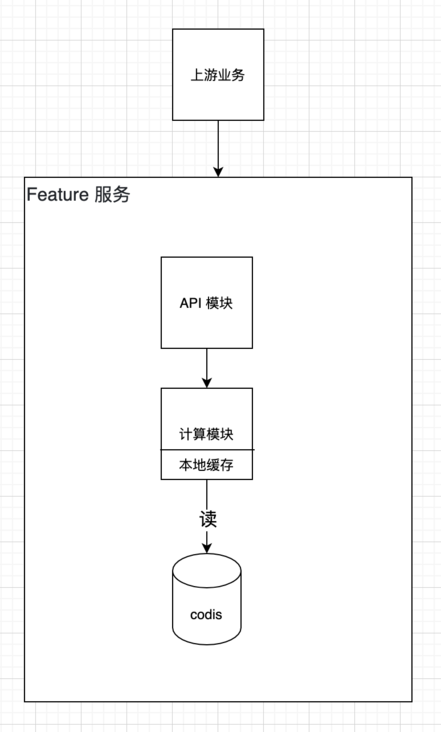
Feature 服务模块图
面对问题
服务 API 侧存在较严重的 P99 耗时毛刺问题(固定出现在每分钟第 0-10s),导致上游服务的访问错误率达到 1‰ 以上,影响到业务指标;目标:解决耗时毛刺问题,将 P99 耗时整体优化至 15ms 以下; API 模块返回上游 P99 耗时图
API 模块返回上游 P99 耗时图
解决方案
服务 CPU 优化
背景
偶然的一次上线变动中,发现对 Feature 服务来说 CPU 的使用率的高低会较大程度上影响到服务耗时,因此从提高服务 CPU Idle 角度入手,对服务耗时毛刺问题展开优化。
优化
通过对 Pprof profile 图的观察发现 JSON 反序列化操作占用了较大比例(50% 以上),因此通过减少反序列化操作、更换 JSON 序列化库(json-iterator)两种方式进行了优化。
效果
收益:CPU idle 提升 5%,P99 耗时毛刺从 30ms 降低至 20 ms 以下。
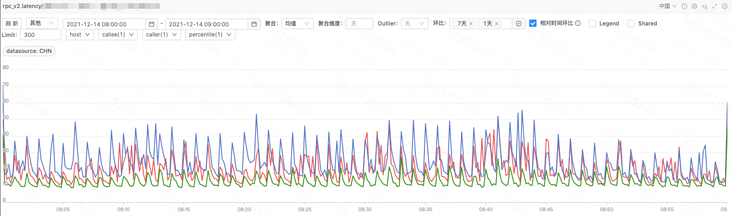 优化后的耗时曲线(红色与绿色线)
优化后的耗时曲线(红色与绿色线)关于 CPU 与耗时
为什么 CPU Idle 提升耗时会下降
反序列化时的开销减少,使单个请求中的计算时间得到了减少; 单个请求的处理时间减少,使同时并发处理的请求数得到了减少,减轻了调度切换、协程/线程排队、资源竞争的开销;
关于 json-iterator 库
json-iterator 库为什么快标准库 json 库使用 reflect.Value 进行取值与赋值,但 reflect.Value 不是一个可复用的反射对象,每次都需要按照变量生成 reflect.Value 结构体,因此性能很差。json-iterator 实现原理是用 reflect.Type 得出的类型信息通过「对象指针地址+字段偏移」的方式直接进行取值与赋值,而不依赖于 reflect.Value,reflect.Type 是一个可复用的对象,同一类型的 reflect.Type 是相等的,因此可按照类型对 reflect.Type 进行 cache 复用。总的来说其作用是减少内存分配和反射调用次数,进而减少了内存分配带来的系统调用、锁和 GC 等代价,以及使用反射带来的开销。
详情可见:https://cloud.tencent.com/developer/article/1064753
调用方式优化 - 对冲请求
背景
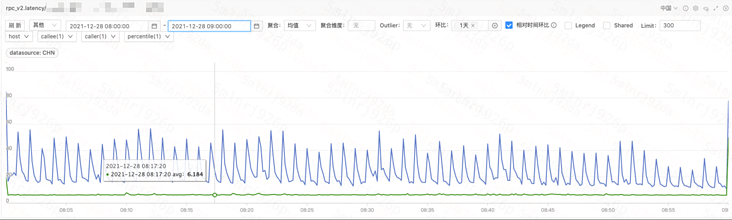
Feature 服务 API 模块访问计算模块 P99 显著高于 P95; 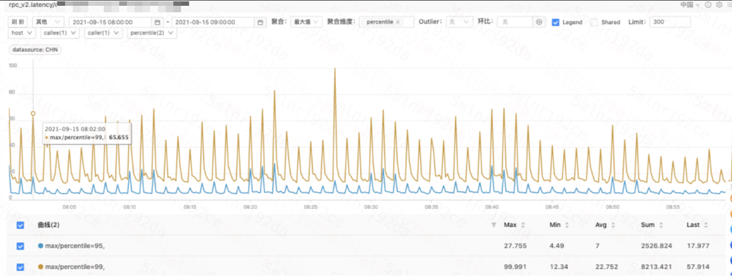 API 模块访问计算模块 P99 与 P95 耗时曲线
API 模块访问计算模块 P99 与 P95 耗时曲线经观察计算模块不同机器之间毛刺出现时间点不同,单机毛刺呈偶发现象,所有机器聚合看呈规律性毛刺; 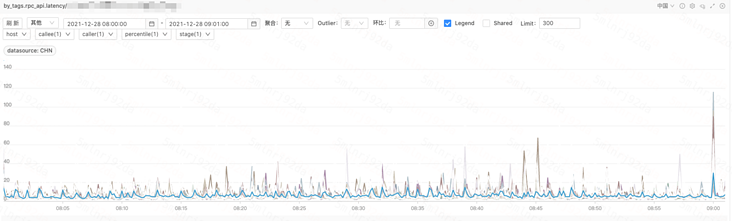 计算模块返回 API P99 耗时曲线(未聚合)
计算模块返回 API P99 耗时曲线(未聚合)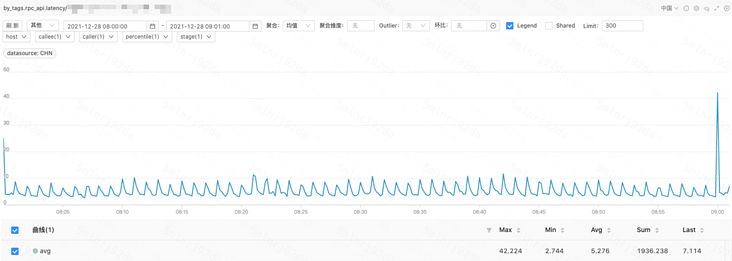 计算模块返回 API P99 耗时曲线(均值聚合)
计算模块返回 API P99 耗时曲线(均值聚合)
优化
针对 P99 高于 P95 现象,提出对冲请求方案,对毛刺问题进行优化;
对冲请求:把对下游的一次请求拆成两个,先发第一个,n毫秒超时后,发出第二个,两个请求哪个先返回用哪个;Hedged requests.
A simple way to curb latency variability is to issue the same request to multiple replicas and use the results from whichever replica responds first. We term such requests “hedged requests” because a client first sends one request to the replica be- lieved to be the most appropriate, but then falls back on sending a secondary request after some brief delay. The cli- ent cancels remaining outstanding re- quests once the first result is received. Although naive implementations of this technique typically add unaccept- able additional load, many variations exist that give most of the latency-re- duction effects while increasing load only modestly.
One such approach is to defer send- ing a secondary request until the first request has been outstanding for more than the 95th-percentile expected la- tency for this class of requests. This approach limits the additional load to approximately 5% while substantially shortening the latency tail. The tech- nique works because the source of la- tency is often not inherent in the par- ticular request but rather due to other forms of interference.
摘自:论文《The Tail at Scale》
调研
阅读论文 Google《The Tail at Scale》; 开源实现:BRPC、RPCX; 工业实践:百度默认开启、Grab LBS 服务(下游纯内存型数据库)效果非常明显、谷歌论文中也有相关的实践效果阐述; 落地实现:修改自 RPCX 开源实现
package backuprequest
import (
"sync/atomic"
"time"
"golang.org/x/net/context"
)
var inflight int64
// call represents an active RPC.
type call struct {
Name string
Reply interface{} // The reply from the function (*struct).
Error error // After completion, the error status.
Done chan *call // Strobes when call is complete.
}
func (call *call) done() {
select {
case call.Done <- call:
default:
logger.Debug("rpc: discarding Call reply due to insufficient Done chan capacity")
}
}
func BackupRequest(backupTimeout time.Duration, fn func() (interface{}, error)) (interface{}, error) {
ctx, cancelFn := context.WithCancel(context.Background())
defer cancelFn()
callCh := make(chan *call, 2)
call1 := &call{Done: callCh, Name: "first"}
call2 := &call{Done: callCh, Name: "second"}
go func(c *call) {
defer helpers.PanicRecover()
c.Reply, c.Error = fn()
c.done()
}(call1)
t := time.NewTimer(backupTimeout)
select {
case <-ctx.Done(): // cancel by context
return nil, ctx.Err()
case c := <-callCh:
t.Stop()
return c.Reply, c.Error
case <-t.C:
go func(c *call) {
defer helpers.PanicRecover()
defer atomic.AddInt64(&inflight, -1)
if atomic.AddInt64(&inflight, 1) > BackupLimit {
metric.Counter("backup", map[string]string{"mark": "limited"})
return
}
metric.Counter("backup", map[string]string{"mark": "trigger"})
c.Reply, c.Error = fn()
c.done()
}(call2)
}
select {
case <-ctx.Done(): // cancel by context
return nil, ctx.Err()
case c := <-callCh:
metric.Counter("backup_back", map[string]string{"call": c.Name})
return c.Reply, c.Error
}
}
效果
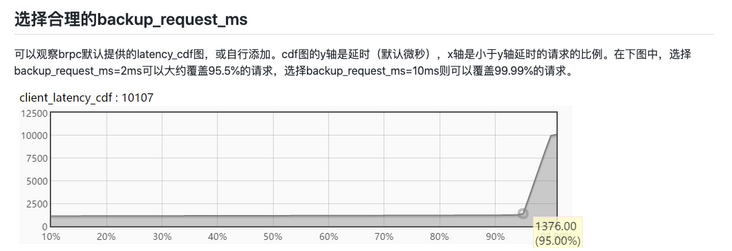
收益:P99 耗时整体从 20-60ms 降低至 6ms,毛刺全部干掉;(backupTimeout=5ms)
 API 模块返回上游服务耗时统计图
API 模块返回上游服务耗时统计图《The Tail at Scale》论文节选及解读
括号中内容为个人解读为什么存在变异性?(高尾部延迟的响应时间)
导致服务的个别部分出现高尾部延迟的响应时间的变异性(耗时长尾的原因)可能由于许多原因而产生,包括: 共享的资源。机器可能被不同的应用程序共享,争夺共享资源(如CPU核心、处理器缓存、内存带宽和网络带宽)(在云上环境中这个问题更甚,如不同容器资源争抢、Sidecar 进程影响);在同一个应用程序中,不同的请求可能争夺资源。 守护程序。后台守护程序可能平均只使用有限的资源,但在安排时可能产生几毫秒的中断。 全局资源共享。在不同机器上运行的应用程序可能会争夺全球资源(如网络交换机和共享文件系统(数据库))。 维护活动。后台活动(如分布式文件系统中的数据重建,BigTable等存储系统中的定期日志压缩(此处指 LSM Compaction 机制,基于 RocksDB 的数据库皆有此问题),以及垃圾收集语言中的定期垃圾收集(自身和上下游都会有 GC 问题 1. Codis proxy 为 GO 语言所写,也会有 GC 问题;2. 此次 Feature 服务耗时毛刺即时因为服务本身 GC 问题,详情见下文)会导致周期性的延迟高峰;以及排队。中间服务器和网络交换机的多层排队放大了这种变化性。
减少组件的可变性
后台任务可以产生巨大的CPU、磁盘或网络负载;例子是面向日志的存储系统的日志压缩和垃圾收集语言的垃圾收集器活动。 通过节流、将重量级的操作分解成较小的操作(例如 GO、Redis rehash 时渐进式搬迁),并在整体负载较低的时候触发这些操作(例如某数据库将 RocksDB Compaction 操作放在凌晨定时执行),通常能够减少后台活动对交互式请求延迟的影响。
关于消除变异源
消除大规模系统中所有的延迟变异源是不现实的,特别是在共享环境中。 使用一种类似于容错计算的方法(此处指对冲请求),容尾软件技术从不太可预测的部分中形成一个可预测的整体(对下游耗时曲线进行建模,从概率的角度进行优化)。 一个真实的谷歌服务的测量结果,该服务在逻辑上与这个理想化的场景相似;根服务器通过中间服务器将一个请求分发到大量的叶子服务器。该表显示了大扇出对延迟分布的影响。在根服务器上测量的单个随机请求完成的第99个百分点的延迟是10ms。然而,所有请求完成的第99百分位数延迟是140ms,95%的请求完成的第99百分位数延迟是70ms,这意味着等待最慢的5%的请求完成的时间占总的99%百分位数延迟的一半。专注于这些慢速异常值的技术可以使整体服务性能大幅降低。 同样,由于消除所有的变异性来源也是不可行的,因此正在为大规模服务开发尾部容忍技术。尽管解决特定的延迟变异来源的方法是有用的,但最强大的尾部容错技术可以重新解决延迟问题,而不考虑根本原因。这些尾部容忍技术允许设计者继续为普通情况进行优化,同时提供对非普通情况的恢复能力。
对冲请求原理
 对冲请求典型场景
对冲请求典型场景其原理是从概率角度出发,利用下游服务的耗时模型,在这条耗时曲线上任意取两个点,其中一个小于x的概率,这个概率远远大于任意取一个点小于x的概率,所以可以极大程度降低耗时; 但如果多发的请求太多了,比如说1倍,会导致下游压力剧增,耗时曲线模型产生恶化,达不到预期的效果,如果控制比如说在5%以内,下游耗时曲线既不会恶化,也可以利用他95分位之前的那个平滑曲线,因此对冲请求超时时间的选择也是一个需要关注的点; 当超过95分位耗时的时候,再多发一个请求,这时候这整个请求剩余的耗时就取决于在这整个线上任取一点,和在95分位之后的那个线上任取一点,耗时是这两点中小的那个,从概率的角度看,这样95分位之后的耗时曲线,会比之前平滑相当多; 这个取舍相当巧妙,只多发5%的请求,就能基本上直接干掉长尾情况; 局限性 如同一个 mget 接口查 100 个 key 与查 10000 个 key 耗时一定差异很大,这种情况下对冲请求时无能为力的,因此需要保证同一个接口请求之间质量是相似的情况下,这样下游的耗时因素就不取决于请求内容本身; 如 Feature 服务计算模块访问 Codis 缓存击穿导致的耗时毛刺问题,在这种情况下对冲请求也无能为力,甚至一定情况下会恶化耗时; 请求需要幂等,否则会造成数据不一致; 总得来说对冲请求是从概率的角度消除偶发因素的影响,从而解决长尾问题,因此需要考量耗时是否为业务侧自身固定因素导致,举例如下: 对冲请求超时时间并非动态调整而是人为设定,因此极端情况下会有雪崩风险,解决方案见一下小节;
名称来源
backup request 好像是 BRPC 落地时候起的名字,论文原文里叫 Hedged requests,简单翻译过来是对冲请求,GRPC 也使用的这个名字。
关于雪崩风险
对冲请求超时时间并非动态调整,而是人为设定,因此极端情况下会有雪崩风险;

如果不加限制确实会有雪崩风险,有如下解法
BRPC 实践:对冲请求会消耗一次对下游的重试次数; 
bilibili 实践: 对 retry 请求下游会阻断级联; 本身要做熔断; 在 middleware 层实现窗口统计,限制重试总请求占比,比如 1.1 倍; 服务自身对下游实现熔断机制,下游服务对上游流量有限流机制,保证不被打垮。从两方面出发保证服务的稳定性; Feature 服务实践:对每个对冲请求在发出和返回时增加 atmoic 自增自减操作,如果大于某个值(请求耗时 ✖️ QPS ✖️ 5%),则不发出对冲请求,从控制并发请求数的角度进行流量限制;
语言 GC 优化
背景
在引入对冲请求机制进行优化后,在耗时方面取得了突破性的进展,但为从根本上解决耗时毛刺,优化服务内部问题,达到标本兼治的目的,着手对服务的耗时毛刺问题进行最后的优化;
优化
第一步:观察现象,初步定位原因对 Feature 服务早高峰毛刺时的 Trace 图进行耗时分析后发现,在毛刺期间程序 GC pause 时间(GC 周期与任务生命周期重叠的总和)长达近 50+ms(见左图),绝大多数 goroutine 在 GC 时进行了长时间的辅助标记(mark assist,见右图中浅绿色部分),GC 问题严重,因此怀疑耗时毛刺问题是由 GC 导致;
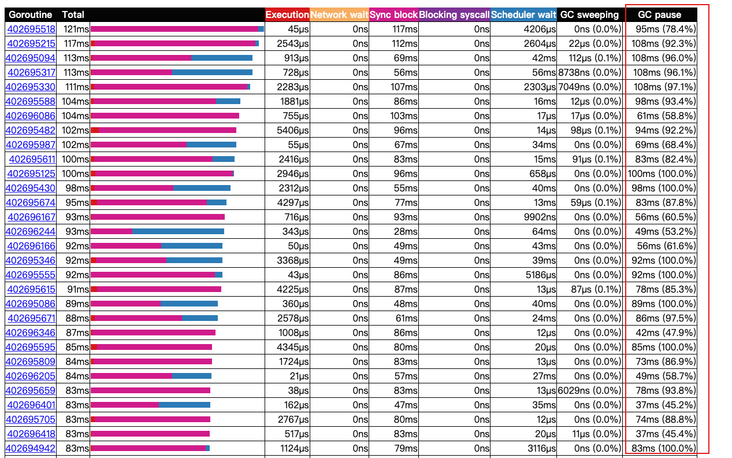
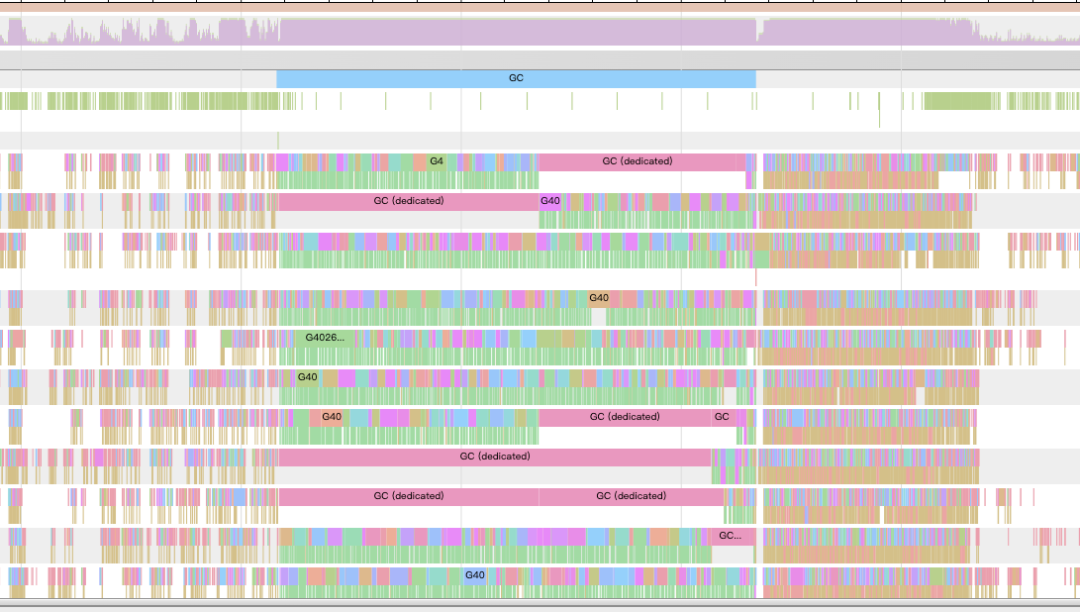
第二步:从原因出发,进行针对性分析
根据观察计算模块服务平均每 10 秒发生 2 次 GC,GC 频率较低,但在每分钟前 10s 第一次与第二次的 GC 压力大小(做 mark assist 的 goroutine 数)呈明显差距,因此怀疑是在每分钟前 10s 进行第一次 GC 时的压力过高导致了耗时毛刺。 根据 Golang GC 原理分析可知,G 被招募去做辅助标记是因为该 G 分配堆内存太快导致,而 计算模块每分钟缓存失效机制会导致大量的下游访问,从而引入更多的对象分配,两者结合互相印证了为何在每分钟前 10s 的第一次 GC 压力超乎寻常;
关于 GC 辅助标记 mark assist
为了保证在Marking过程中,其它G分配堆内存太快,导致Mark跟不上Allocate的速度,还需要其它G配合做一部分标记的工作,这部分工作叫辅助标记(mutator assists)。在Marking期间,每次G分配内存都会更新它的”负债指数”(gcAssistBytes),分配得越快,gcAssistBytes越大,这个指数乘以全局的”负载汇率”(assistWorkPerByte),就得到这个G需要帮忙Marking的内存大小(这个计算过程叫revise),也就是它在本次分配的mutator assists工作量(gcAssistAlloc)。引用自:https://wudaijun.com/2020/01/go-gc-keypoint-and-monitor/
第三步:按照分析结论,设计优化操作从减少对象分配数角度出发,对 Pprof heap 图进行观察
在 inuse_objects 指标下 cache 库占用最大; 在 alloc_objects 指标下 json 序列化占用最大;
但无法确定哪一个是真正使分配内存增大的因素,因此着手对这两点进行分开优化;

 通过对业界开源的 json 和 cache 库调研后(调研报告:https://segmentfault.com/a/1190000041591284),采用性能较好、低分配的 GJSON 和 0GC 的 BigCache 对原有库进行替换;
通过对业界开源的 json 和 cache 库调研后(调研报告:https://segmentfault.com/a/1190000041591284),采用性能较好、低分配的 GJSON 和 0GC 的 BigCache 对原有库进行替换;效果
更换 JSON 序列化库 GJSON 库优化无效果; 更换 Cache 库 BigCache 库效果明显,inuse_objects 由 200-300w 下降到 12w,毛刺基本消失;
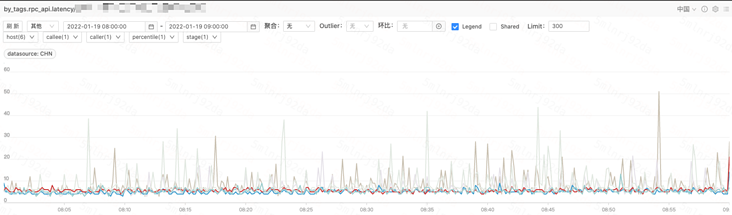 计算模块耗时统计图(浅色部分:GJSON,深色部分:BigCache)
计算模块耗时统计图(浅色部分:GJSON,深色部分:BigCache)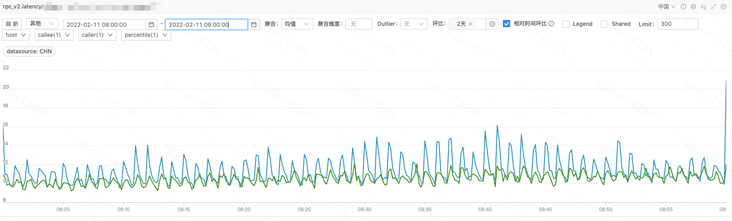 API 模块返回上游耗时统计图
API 模块返回上游耗时统计图关于 Golang GC
在通俗意义上常认为,GO GC 触发时机为堆大小增长为上次 GC 两倍时。但在 GO GC 实际实践中会按照 Pacer 调频算法根据堆增长速度、对象标记速度等因素进行预计算,使堆大小在达到两倍大小前提前发起 GC,最佳情况下会只占用 25% CPU 且在堆大小增长为两倍时,刚好完成 GC。
关于 Pacer 调频算法:https://golang.design/under-the-hood/zh-cn/part2runtime/ch08gc/pacing/
但 Pacer 只能在稳态情况下控制 CPU 占用为 25%,一旦服务内部有瞬态情况,例如定时任务、缓存失效等等,Pacer 基于稳态的预判失效,导致 GC 标记速度小于分配速度,为达到 GC 回收目标(在堆大小到达两倍之前完成 GC),会导致大量 Goroutine 被招募去执行 Mark Assist 操作以协助回收工作,从而阻碍到 Goroutine 正常的工作执行。因此目前 GO GC 的 Marking 阶段对耗时影响时最为严重的。
关于 gc pacer 调频器
引用自:https://go.googlesource.com/proposal/+/a216b56e743c5b6b300b3ef1673ee62684b5b63b/design/44167-gc-pacer-redesign.md
最终效果
API 模块 P99 耗时从 20-50ms 降低至 6ms,访问错误率从 1‰ 降低到 1‱。
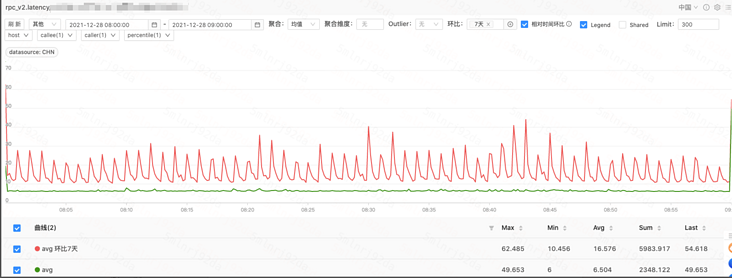 API 返回上游服务耗时统计图
API 返回上游服务耗时统计图总结
当分析耗时问题时,观察监控或日志后,可能会发现趋势完全匹配的两种指标,误以为是因果关系,但却有可能这两者都是外部表现,共同受到第三变量的影响,相关但不是因果; 相对于百毫秒耗时服务,低延时服务的耗时会较大程度上受到 CPU 使用率的影响,在做性能优化时切勿忽视这点;(线程排队、调度损耗、资源竞争等) 对于高并发、低延时服务,耗时方面受到下游的影响可能只是一个方面,服务自身开销如序列化、GC 等都可能会较大程度上影响到服务耗时; 性能优化因从提高可观测性入手,如链路追踪、标准化的 Metric、go pprof 工具等等,打好排查基础,基于多方可靠数据进行分析与猜测,最后着手进行优化、验证,避免盲人摸象似的操作,妄图通过碰运气的方式解决问题; 了解一些简单的建模知识对耗时优化的分析与猜测阶段会有不错的帮助; 理论结合实际问题进行思考;多看文章、参与分享、进行交流,了解更多技术,扩展视野;每一次的讨论和质疑都是进一步深入思考的机会,以上多项优化都出自与大佬(特别鸣谢 @李心宇@刘琦@龚勋)的讨论后的实践; 同为性能优化,耗时优化不同于 CPU、内存等资源优化,更加复杂,难度较高,在做资源优化时 Go 语言自带了方便易用的 PProf 工具,可以提供很大的帮助,但耗时优化尤其是长尾问题的优化非常艰难,因此在进行优化的过程中一定要稳住心态、耐心观察,行百里者半九十。 关注请求之间共享资源的争用导致的耗时问题,不仅限于下游服务,服务自身的 CPU、内存(引发 GC)等也是共享资源的一部分;