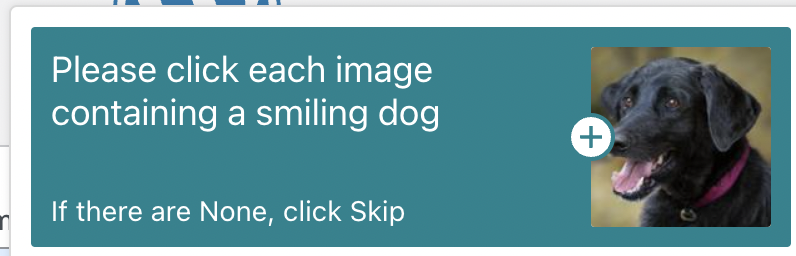
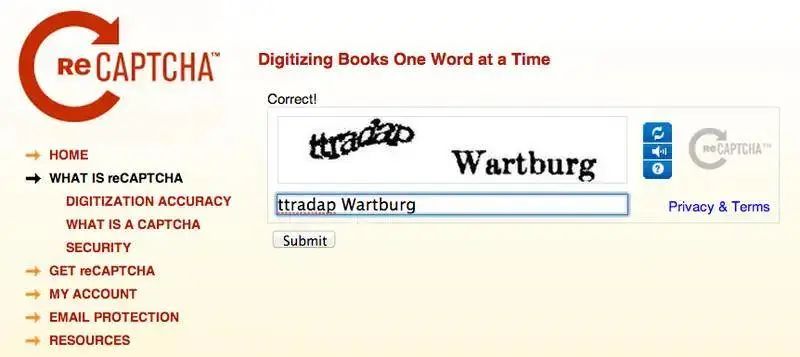
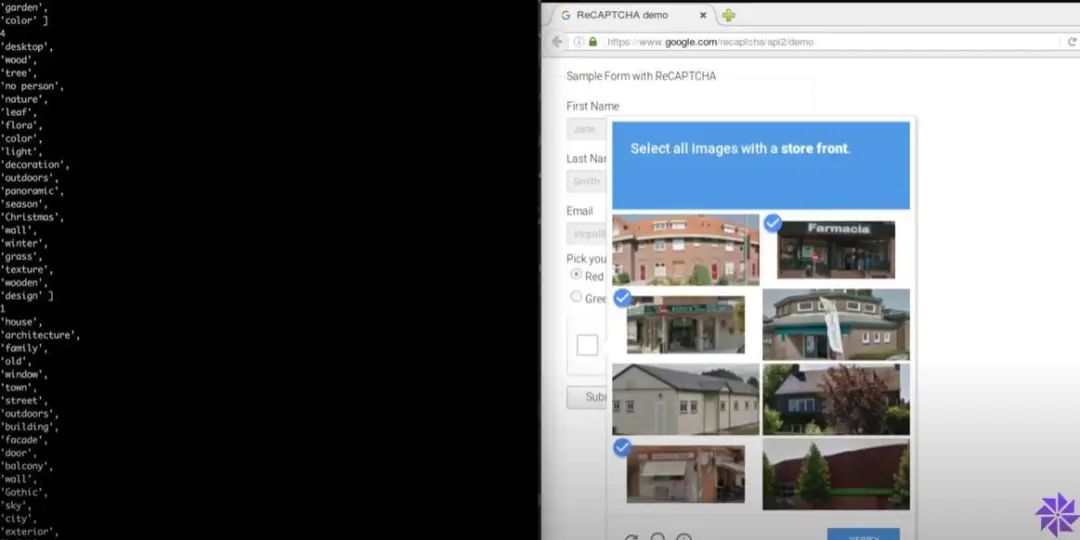
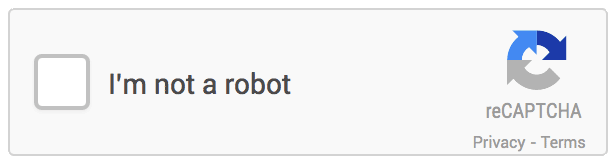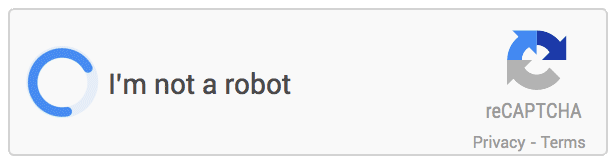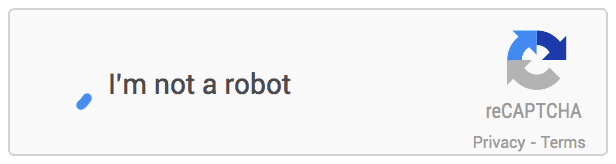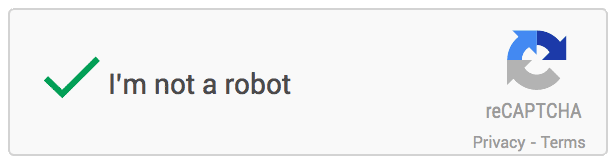
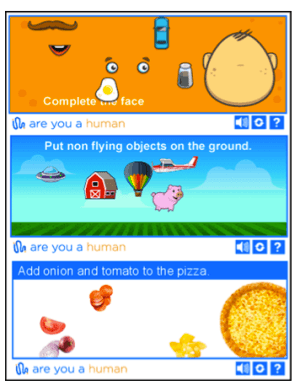
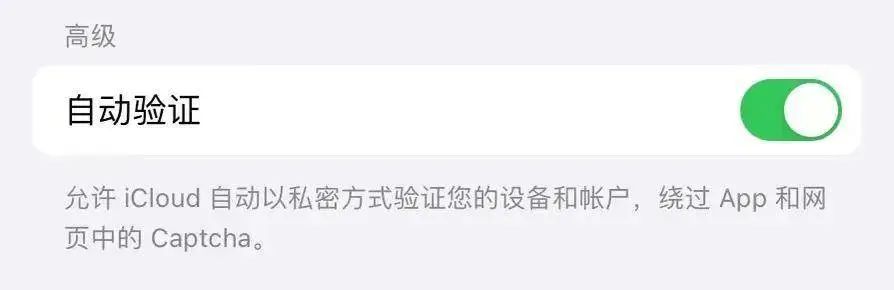
但在计算机承认你是人类之前,你可能会被要求点击包含红绿灯或人行道的图像。当你靠近屏幕眯起眼睛,思考一个微乎其微的边角算不算时,你就会知道,这并不像听起来那么容易。这种难以自证的感觉,2015 年在 12306 抢票的春运人应该就有领略。多年过去了,不断翻新花样的验证码,依然迫使你思考古老的哲学问题——我是谁?某创意营销机构创始人 Jared Bauman 最近被验证码难住了。他疑惑的是,狗真的会笑吗?大多数狗看起来既不高兴也不难过,有些在做鬼脸,有些只是张着嘴。8 月 2 日,他又被要求找出「用云做成的马」,9 张图里有 2 张用云做成的大象,他第一次点击时不幸败北。Jared Bauman 意识到了一个严重的问题——找出红绿灯、公交车或烟囱已经过时了,验证码系统开始设置下一个级别的挑战了。这些验证码出自 hCaptcha,开发者称,它比 Google 的验证码系统 reCAPTCHA 更注重隐私,只收集最低限度的必要个人数据。而验证码为什么会越来越难,还是要从验证码是什么,以及 Google 的验证码系统 reCAPTCHA 是什么说起。验证码(CAPTCHA),全称是「全自动区分计算机和人类的公开图灵测试」。由于它是用计算机来考人类,而不是标准图灵测试中那样由人类来考计算机,所以验证码也被视为一种反向图灵测试。验证码的设计初衷是,保护网站免受有害机器人的侵害,包括传播恶意软件、散布虚假账户、执行 DDoS 攻击、发送大量垃圾邮件、窃取用户信息等。这些机器人本质上是一行行自动运行的计算机代码。验证码创建于 2000 年代初,最早由卡内基梅隆大学的几位计算机科学家开发。最初的验证码采用了扭曲的文本形式,避免被光学字符识别等计算机程序自动识别,超过了当时计算机可以破译的程度,但对大多数人类可读。很快,研究人员意识到这项技术具有区分人类和机器人之外的潜力,他们开发了 reCAPTCHA 技术,让用户在填写验证码的过程中将纸质档案数字化,因为人类可以比计算机更好地破译老旧文献中扭曲的字母。这一阶段,用户必须输入两个词,一个是答案明确的真正测试,另一个是尚未转录的新词。通过向世界各地用户多次显示相同单词,reCAPTCHA 便可以自动验证单词是否被正确转录。这就像互联网的一次众筹,求得你的时间而非金钱。互联网的神奇之处便在此,在技术支持下,再创造一些乐趣,你可以利用所有人的一点精力,自然而然聚沙成塔。2009 年,Google 收购了 reCAPTCHA,并将其用于数字化 Google 图书和纽约时报档案。2011 年,Recaptcha 已经完成了整个 Google 图书档案、1300 万篇纽约时报文章的数字化。2012 年,它每天翻译大约 1.5 亿个单词。人类沉浸在知识的海洋,机器人也没有停下学习的脚步。2014 年,Google 发布了一个专门解读扭曲文本验证码的算法,人工智能技术已经能以 99.8% 的准确率解决最困难的扭曲文本,而人类的成功率是 33%。扭曲的字母失去了它最初的用处,该让下一代验证码登场了。2012 年,Google 推出了 reCAPTCHA 的图像识别版本,其中包括来自 Google 街景的照片,从而让用户转录门牌号码和其他标志。类似当初将旧书数字化,在这个过程中,Google 一举多得,既防御了恶意脚本,自己的人工智能也在进步。Google 称:「街景和 reCAPTCHA 团队密切合作,两者都将继续改进,使地图更加精确和有用,reCAPTCHA 更安全、更有效。」让地图更加精确和有用,意味着 Google 需要训练人工智能更好地识别图像中的物体。那怎么训练人工智能?reCAPTCHA。数以亿计的用户为了证明自己是人类,为科技公司建立起了机器学习数据集。进步的不止 Google。2017 年,开发人员 Francis Kim 进行了一项实验,用 40 行 Javascript构建了一个系统,使用 Google 竞争对手 Clarifai 的图像识别 API,尝试通过 reCAPTCHA 的图像验证码。结果,这个脚本成功找出了图中的商店。理论上,这也可以使用 Google 自己的图像识别技术来实现。Google 的验证码系统其实有两个目的:在用文本、图像等训练人工智能的同时,抑制恶性脚本的行为。但事实是,Google 的人工智能是越来越厉害了,但恶性脚本也在斗智斗勇中进步,只有用户证明自己是人越来越难了。2014 年,Google 的「No CAPTCHA reCAPTCHA」登台,即「没有验证码的验证码」,界面简洁友好,只需要你坚信「我不是机器人」。Google 称,它推出了一个新的 API,可观察用户行为,收集指针移动速率、当前 IP、是否使用插件、页面使用时间、进行过多少次点击等数据,从根本上简化了 reCAPTCHA 体验。大多数情况下,只需单击一下,就能确认用户是不是机器人。但是,验证码没有消失。甚至可以说,最讨人厌的验证码出现了。在风险分析引擎无法预测用户是不是人的情况下,Google 会让验证码再次出山,并且给出了更多新玩法,比如基于经典计算机视觉图像标记问题,让你选出所有包括猫或火鸡的照片。此外,还有类似游戏的验证码,要求用户将物体旋转到特定角度,或将拼图移动到适当的位置。人类能够理解谜题的逻辑,但缺乏明确指令的机器人会被难住。但以后会不会掌握就难说了。机器学习得越多,人类拥有的优势就越少,这是一个道高一尺魔高一百丈的过程。伊利诺伊大学芝加哥分校计算机科学教授 Jason Polakis 指出,机器学习现在在基本的文本、图像和语音识别任务上与人类差不多,「我们需要一些替代方案」。更重要的是,在验证码系统前,用户体验和可访问性大大降低。验证码对很多人来说已经不容易,特别是老人等有学习障碍的群体。为老年客户提供技术建议的 Eileen Ridge 表示,她经常接到客户的电话,老人很难辨别油漆磨损的人行道和正常的人行横道,并且十分担心自己因为错误答案被锁定帐户,就像许多国内老年人对互联网的态度一样。一些网站使用一种人类用户不可见的验证码形式,将字段插入到仅对机器人可见的屏幕上,诱骗它们填写表格并证明它们不是人类。近两年,Google 推出了新验证码系统 reCaptcha v3,它采用逆向思维,自动记录使用者在网站中浏览的行为特征,根据这些记录来给用户打分,若用户分数过低则会被判定为机器人。否则不会打扰到用户,上网体验很丝滑。但它可能涉及隐私问题。FastCompany 报道,用户是否使用 Google Cookies 是决定评分的一个重要因素。如果用户选择让 Google 记住登录信息的话,会得到更高的分数,没有登录 Google 帐号,或者使用 VPN 或者洋葱浏览器通常会被提示高风险。机器人检测公司 Shape Security 的首席技术官 Ghosemajumder 则认为,游戏验证码、视频验证码等验证码测试,最终都会被破解。与测试相比,他更喜欢「持续身份验证」,本质是观察用户的行为,从中寻找自动化的迹象:「一个真正的人类不能很好地控制自己的运动功能,因此即使他们非常努力地尝试,他们也不能在多次交互中多次以相同的方式移动鼠标。」今年 6 月,苹果在全球开发者大会宣布将用私人访问令牌(Private Access Tokens)取代验证码。密码或生物识别解锁手机、打开浏览器、精准输入网站……一系列操作足以「验明正身」。当苹果系统验证该设备和 Apple ID 帐户是正常状态,再向需要验证码的 app 或网站提供「私人访问令牌」即可。提供网站安全管理的 Cloudflare、Ffast 等公司已支持私人访问令牌,用 iOS 16 设备登录这两家公司的 app 或网站,不再需要验证码。目前,这项技术还在推广之中,需要更多的支持者加入,才能更好用。苹果工程师 Tommy Pauly 指出:「这将为很多人节省大量时间,并且用户喜欢被信任的感觉。」但只要有虚假账户、垃圾邮件、骚扰信息等的存在,我们仍然需要将人类用户与机器人分开的技术,某种形式的验证码技术将始终存在,与人工智能并行发展。未来,验证码系统识别人类,很可能不是通过我们超越机器人的能力,而是通过我们犯错误的可能。也就是说设置更多挑战性的测试,我们往往会失败,而机器人给出正确答案。或许,在我们抓耳挠腮地寻找图中所有的信号灯时,就是在进行以人类一败涂地为结局的斗争。1.https://auth0.com/blog/captcha-can-ruin-your-ux-here-s-how-to-use-it-right/2.https://www.wired.com/story/smiling-dogs-horses-made-of-clouds-captcha-has-gone-too-far/3.https://www.techradar.com/news/captcha-if-you-can-how-youve-been-training-ai-for-years-without-realising-it4.https://www.theverge.com/2019/2/1/18205610/google-captcha-ai-robot-human-difficult-artificial-intelligence 更多精彩内容,尽在最潮酷的科技媒体「爱范儿」,欢迎关注。









 下载APP
下载APP