
Redis 生产架构选型解决方案
有帮助的话,请点一个关注,支持我的继续撰稿,谢谢~
Redis 6.0新特性说明
模块系统新增多个API。
支持SSL/TLS加密。
支持新的Redis协议:
RESP3。
服务端支持多模式的客户端缓存。
支持多线程IO。
副本中支持无盘复制(diskless replication)。
Redis-benchmark新增了Redis集群模式。
支持重写Systemd。
支持Disque模块。
Redis 5.0新特性说明
云数据库Redis 5.0版本大幅度优化内核,运行更加稳定,同时新增Stream、账号管理、审计日志等多种特性,满足您更多场景下的使用需求。 新的数据类型: 流数据(Stream)。 详细说明请参见Redis Streams。 新增账号管理功能。 新增日志管理功能,支持审计日志、运行日志和慢日志,您可以通过日志管理查询读写操作、敏感操作(如KEYS、FLUSHALL)和管理类命令的使用记录以及慢日志。 新增基于快照的缓存分析功能。 新的定时器(Timers)、集群( Cluster)和字典(Dictionary)模块的API。 RDB中增加LFU和LRU信息。 集群管理器从Ruby (redis-trib.rb)移植到了redis-cli中的C语言代码。 新增有序集合(Sorted Set)命令ZPOPMIN、ZPOPMAX、BZPOPMIN和BZPOPMAX。 升级Active Defragmentation至v2版本。 增强HyperLogLog的实现。 优化内存统计报告。 为许多有子命令的命令增加了HELP子命令。 提高了客户端频繁连接和断开连接时的性能表现。 升级Jemalloc至5.1版本。 新增命令CLIENT ID和CLIENT UNBLOCK。 新增了为艺术而生的LOLWUT命令。 弃用slave术语(需要API向后兼容的情况例外)。 对网络层进行了多处优化。 进行了一些Lua相关的改进。 新增动态HZ(Dynamic HZ)以平衡空闲CPU使用率和响应性。 对Redis核心代码进行了重构并在许多方面进行了改进。
二 架构
集群架构可轻松突破Redis自身单线程瓶颈,满足大容量、高性能的业务需求。
主从架构,提供高性能的缓存服务和数据高可靠。
读写分离架构提供高可用、高性能、高灵活的读写分离服务,解决热点数据集中及高并发读取的业务需求,最大化地节约用户运维成本。
2.1 主从架构-双副本
可靠性
服务可靠采用双机主从(master-replica)架构,主从节点位于不同物理机。
主节点对外提供访问,用户可通过Redis命令行和通用客户端进行数据的增删改查操作。
当主节点出现故障,HA系统会自动进行主从切换,保证业务平稳运行。
数据可靠默认开启数据持久化功能,数据全部落盘。
支持数据备份功能,用户可以针对备份集回滚实例或者克隆实例,有效地解决数据误操作等问题。
使用场景
Redis作为持久化数据存储使用的业务标准版提供持久化机制及备份恢复机制,极大地保证数据可靠性。
单个Redis性能压力可控的业务由于Redis原生采用单线程机制,性能在10万QPS以下的业务建议使用。
如果需要更高的性能要求,请选用集群版本。
Redis命令相对简单,排序、计算类命令较少的业务由于Redis的单线程机制,CPU会成为主要瓶颈。
如排序、计算类较多的业务建议选用集群版配置。
2.2 主从架构-单副本
可以在没有数据可靠性要求的纯缓存场景充分发挥性能优势。
使用场景
纯缓存类业务场景
单副本版本只有一个数据库节点,节点出现故障时,系统会重新拉起一个Redis进程(没有数据),当节点故障业务自动切换完成后,应用程序需要将数据重新预热,以免对后端数据库产生访问压力冲击。单副本架构不能提供数据可靠性,如果发生节点故障,您需要重新对业务进行预热,因此,在对数据可靠性要求较高的敏感性业务中,建议选用双副本架构。
单个Redis性能压力可控
由于Redis原生采用单线程机制,CPU为单核能力,性能在8万QPS的业务建议使用。如果需要更高的性能要求,请选用集群版配置。
Redis命令相对简单,排序、计算类命令较少
由于Redis的单线程机制,CPU为主要瓶颈。如排序、计算类较多的业务建议选用集群版配置。
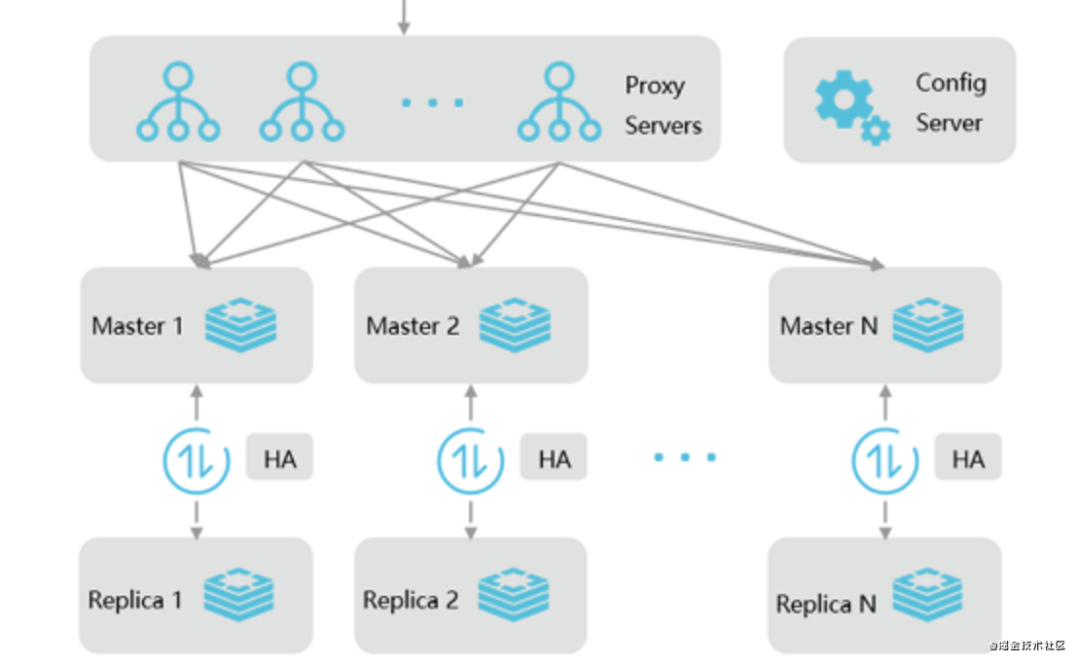
2.3 集群版-双副本
代理模式

直连模式
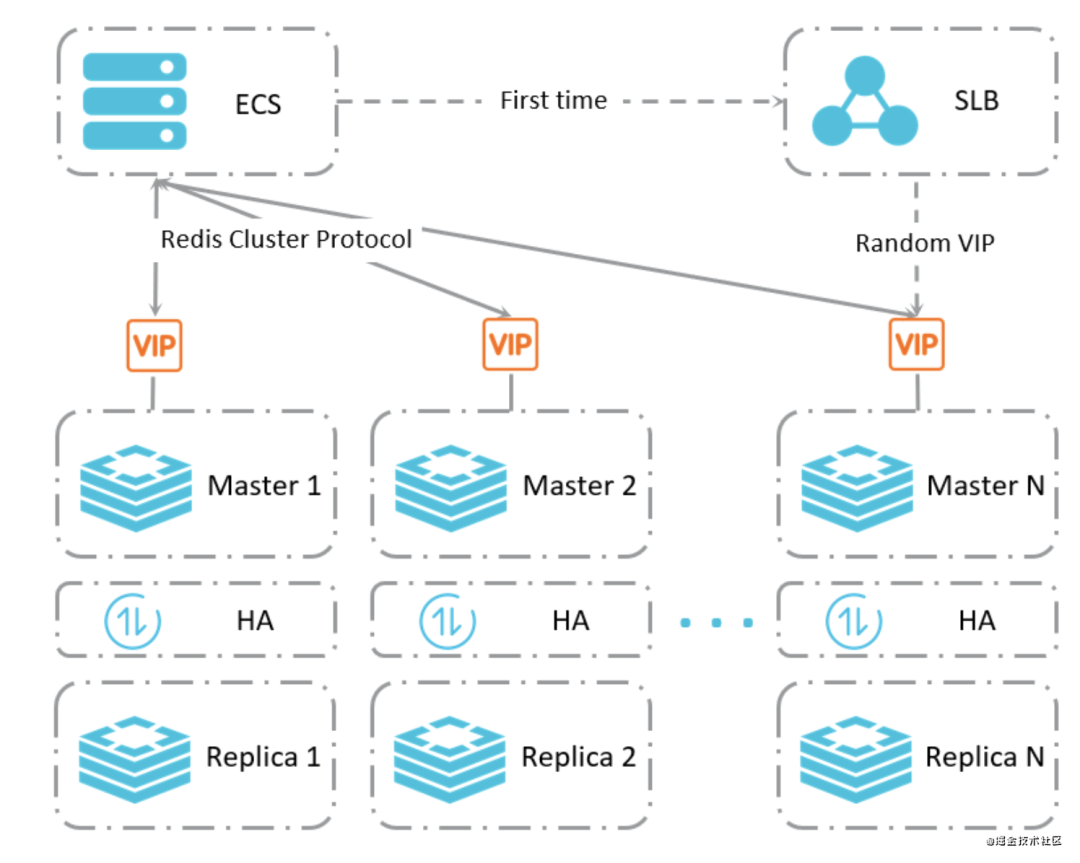
使用不支持Redis Cluster的客户端,可能因客户端无法重定向请求到正确的分片而获取不到需要的数据。 Jedis对于Redis Cluster的支持是基于JedisCluster这个类,详细说明请参见Jedis文档。 您可以在Redis官网的客户端列表里查找更多支持Redis Cluster的客户端。
import redis.clients.jedis.*;import java.util.HashSet;import java.util.Set;public class main {private static final int DEFAULT_TIMEOUT = 2000;private static final int DEFAULT_REDIRECTIONS = 5;private static final JedisPoolConfig DEFAULT_CONFIG = new JedisPoolConfig();public static void main(String args[]){JedisPoolConfig config = new JedisPoolConfig();// 最大空闲连接数, 根据业务需要设置,不能超过实例规格规定的最大的连接数config.setMaxIdle(200);// 最大连接数, 根据业务需要设置,不能超过实例规格规定的最大的连接数config.setMaxTotal(300);config.setTestOnBorrow(false);config.setTestOnReturn(false);// 开通直连访问时申请到的直连地址String host = "r-bp1xxxxxxxxxxxx.redis.rds.aliyuncs.com";int port = 6379;// 实例的密码String password = "xxxxx";SetjedisClusterNode = new HashSet (); jedisClusterNode.add(new HostAndPort(host, port));JedisCluster jc = new JedisCluster(jedisClusterNode, DEFAULT_TIMEOUT, DEFAULT_TIMEOUT,DEFAULT_REDIRECTIONS,password, "clientName", config);}}
2.4 集群版-单副本
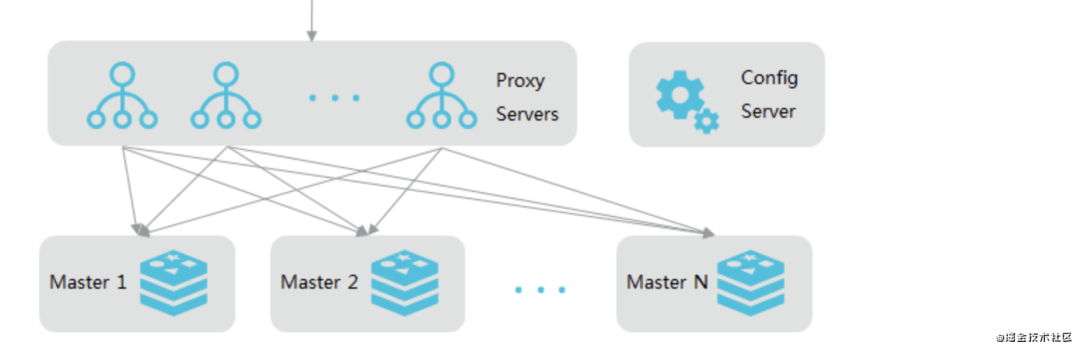
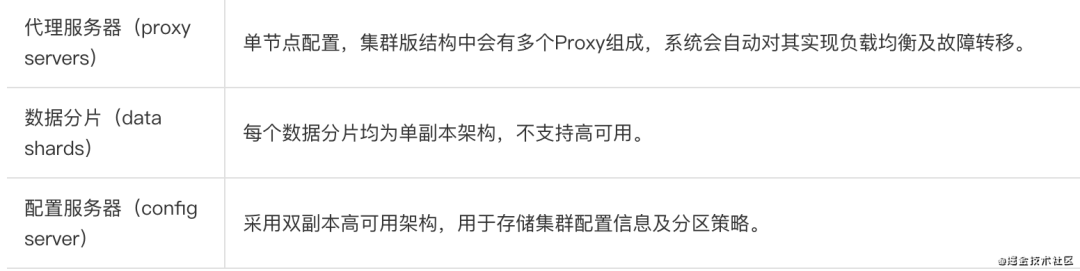
2.5 读写分离版
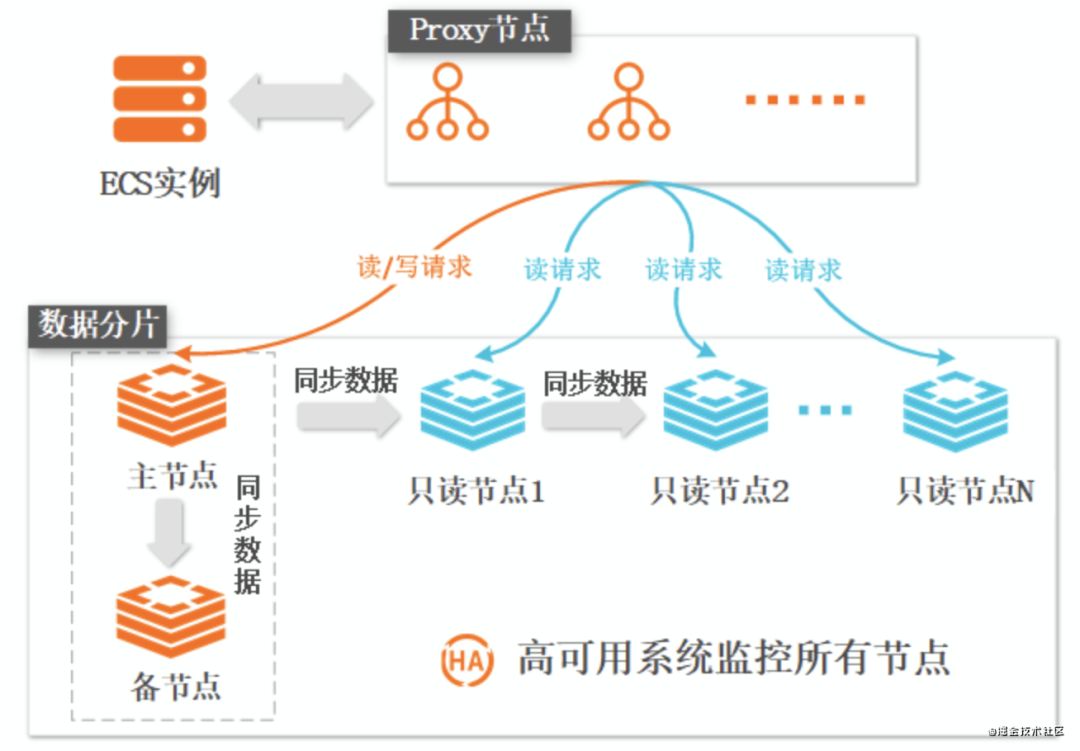

特点
高可用
通过自研的高可用系统自动监控所有数据节点的健康状态,为整个实例的可用性保驾护航。 主节点不可用时自动选择新的主节点并重新搭建复制拓扑。 某个只读节点异常时,高可用系统能够自动探知并重新启动新节点完成数据同步,下线异常节点。 Proxy节点实时感知每个只读实例的服务状态。 在某个只读实例异常期间,Proxy会自动降低该节点的服务权重,发现只读节点连续失败超过一定次数以后,会停止异常节点的服务权利,并具备继续监控后续重新启动节点服务的能力。
高性能
读写分离版采取链式复制架构,可以通过扩展只读实例个数使整体实例性能呈线性增长,同时基于源码层面对Redis复制流程的定制优化,可以最大程度地提升线性复制的系统稳定性,充分利用每一个只读节点的物理资源。
使用场景
读取请求QPS(Queries Per Second)压力较大
建议与使用须知
当一个只读节点发生故障时,请求会转发到其他节点;如果所有只读节点均不可用,请求会全部转发到主节点。只读节点异常可能导致主节点负载提高、响应时间变长,因此在读负载高的业务场景建议使用多个只读节点。 某些场景会触发只读节点的全量同步,例如在主节点触发高可用切换后。全量同步期间只读节点不提供服务并返回-LOADING Redis is loading the dataset in memory\r\n信息。
「全栈架构社区」建立了读者架构师交流群,大家可以添加小编微信进行加群。欢迎有想法、乐于分享的朋友们一起交流学习。
扫描添加好友邀你进架构师群,加我时注明【姓名+公司+职位】
看完本文有收获?请转发分享给更多人
往期资源: