
大语言模型为什么这么强?关键步骤是……
👆点击“博文视点Broadview”,获取更多书讯


--文末赠书--
研究人员发现,随着语言模型参数量的不断增加,模型完成各个任务的效果也得到不同程度的提升。
大语言模型是指模型参数量超过一定规模的语言模型,相比参数量较小的预训练模型(如 BERT、GPT-1、GPT-2 等)!
大语言模型有以下 3 个显著特点。
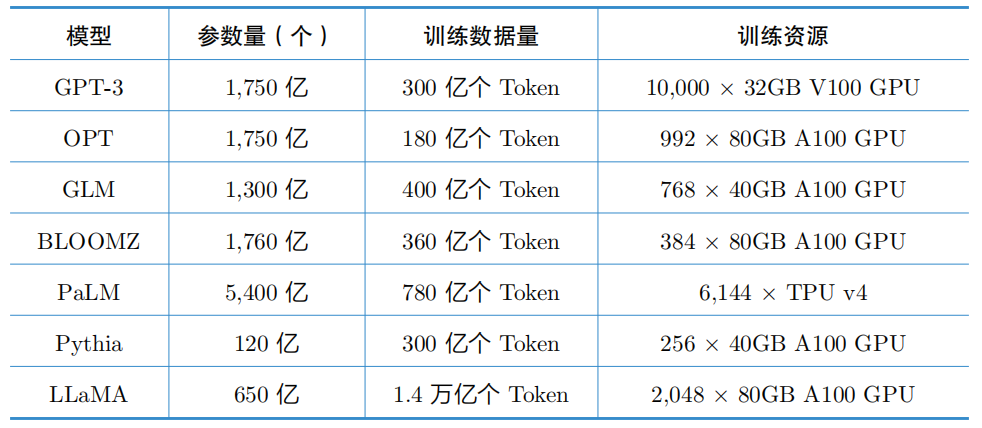
(1)模型参数规模更大:这是最直观的特点,在 BERT 时代,1B 的参数量已经属于很大 的参数规模,而在大语言模型时代,GPT-3 系列中最大的模型具有 175B 的参数量,BLOOM 具有 176B 的参数量,PaLM 具有 540B 的参数量。巨大的参数规模意味着模型能够存储和 处理前所未有的信息量。理论上,巨大的参数量可以帮助模型更好地学习语言中的细微差异, 捕捉复杂的语义结构,理解更复杂的句子和文本结构。巨大的参数量也是大语言模型任务处 理能力的基本保证。
(2)训练数据量更多:大语言模型时代,模型的预训练数据覆盖范围更广,量级更大。大 部分大语言模型的预训练数据量在万亿 Token 以上,如 Meta 推出的 LLaMA 系列使用 1.4 万亿个 Token 的参数量进行预训练,LLaMA2 则使用 2 万亿个 Token 的参数量进行预训练, QWen(通义千问)系列大语言模型更是使用 3 万亿个 Token 的参数量进行预训练。这种大规模的数据训练使模型学习到更多的语言规律和知识,从而在各种自然语言处理任务上表现 更佳。
(3)计算资源要求更高:大语言模型的训练通常需要极大的计算资源,包括大量的 GPU 或 TPU,以及巨大的存储和内存空间。这对模型训练阶段和推理阶段的计算能力、内存空间 提出更高要求。LLaMA 的 65B 模型使用了 2,048 块 80GB A100 GPU,训练了近一个月。因 此,计算资源昂贵成为制约大语言模型研究和开发的一个重要因素。
表1 列出了部分已公开的大语言模型的基本情况,从上面提到的模型参数、训练数据 和所用的训练资源等情况可以看出,相比传统模型,大语言模型拥有更大的参数量和更大规模的训练数据。
这预示着模型的复杂性和处理能力都将显著增强,并展现出以下两种能力。
表1 部分已公开的大语言模型的基本情况
(1)具备涌现能力:涌现能力是指模型能在未明确进行优化的情况下表现出一些特定的能力或特征。例如,大语言模型能在没有经过特定任务微调的情况下,依靠其庞大的参数量和预训练数据,显示出在多种自然语言处理任务上的高效性和泛化能力。这种零样本学习或少样本学习的能力,在大语言模型上表现得尤为突出,也是与传统预训练模型的最大区别之一。如图1所示,随着模型变大、数据变多(模型训练计算量增加),涌现出很多小模型不存在的能力。当 GPT-3 的训练计算量较小时,训练效果接近 0;当训练计算量达到 2 × 1022 时,训练效果突然提升,这就是“涌现能力”,如图1(A)所示。另外,这种能力也从根本上改变了用户使用大语言模型的方式,ChatGPT 是其中最有代表性的应用之一,通过问答 的形式,用户可以与大语言模型进行交互。

图1 模型能力随训练计算量的变化情况
(2)多模态能力增强:部分大语言模型的功能进一步拓展到了多模态学习领域,能够理解和生成包括文本、图像和声音在内的多种类型的数据。这类模型不仅能处理单一模态的任 务,还能进行跨模态的信息理解和生成,比如从文本到图像或从图像到文本的内容生成。
从参数规模的爆炸性增长,到涌现能力的出现,再到对巨大计算资源的需求,大语言模型的出现标志着自然语言处理的新纪元的开始。
这些模型之所以能够取得如此显著的成果, 其背后的关键步骤就是预训练。
预训练是模型训练的初始阶段,通常在大量无监督的文本数据上进行。
在这个阶段,模型通过学习有数十亿或数万亿个Token 的文本,逐渐掌握语言的基本结构、模式和上下文关系。
这种大规模的数据驱动训练,使模型有能力捕捉到微妙的语言细节和语境变化。
在完成预训练后,模型可以在特定的下游任务上进行微调,从而快速适应并在多种自然语言处理任务上表现出色。
这种先预训练后微调的策略,不仅提高了模型的泛化能力,还减轻了对大量标注数据的依赖,这是传统模型难以比肩的。
与此同时,预训练也带来了新的问题,如模型如何处理偏见信息、如何确保模型生成的内容不违反道德伦理等。
在《大语言模型:原理与工程实践(全彩)》一书中,笔者将更详细地介绍大语言模型预训练阶段的完整过程,更多内容可参阅此书。
参考文献:
[1] BROWN T, MANN B, RYDER N, et al. Language models are few-shot learners[J]. Advances in neural information processing systems, 2020, 33: 1877-1901.
[2] SHANAHAN M. Talking about large language models[J]. arXiv preprint arXiv:2212.03551, 2022.
[3] WEI J, TAY Y, BOMMASAN R, et al. Emergent abilities of large language models[J]. arXiv preprint arXiv:2206.07682, 2022.
↑新书首发,限时优惠↑

本书一经上市便位居京东新书热卖榜日榜TOP 1 !
新书首发,感兴趣的小伙伴推荐入手
互动有奖
按以下方式与博文菌互动,即有机会获赠图书!
活动方式:在评论区留言参与“你认为大语言模型之所以这么厉害的关键是什么”等话题互动,届时会在参与的小伙伴中抽取1名幸运鹅赠送本期图书一本!
说明:留言区收到回复“恭喜中奖”者将免费获赠本图书,中奖者请在收到通知的24小时内将您的“姓名+电话+快递地址”留言至原评论下方处即可,隐私信息不会被放出,未在规定时间内回复视作自动放弃兑奖资格。
活动时间:截至3月25日开奖。
快快拉上你的小伙伴参与进来吧~~
温馨提示:可以将“博文视点”设为星标,以免错过赠书活动哦!

发布:刘恩惠
审核:陈歆懿
如果喜欢本文
欢迎 在看丨留言丨分享至朋友圈 三连
<
PAST · 往期回顾
>
书单 | 3月新书速递!
