
流式编程时代,效率之王了解下?

前言
大家在找工作的时候,面试官经常会问到JDK1.8的一些新特性,不知道大家回答的时候是真的已经在用这些新特性,还是说仅仅停留在了解这些新特性的基础上,实话实说,以前我用JDK1.8和用1.6没太大的区别,新特性除了接口的默认default实现方法,其他的新特性确实没咋用过,一个重要的原因就是没有深入了解过,而且当时公司用的还是JDK1.6,所以这些新特性就算真的学会了,也不咋用,会忘记(借口),直到这一次入职以后,公司的生产环境大规模地使用lambda表达式、函数下编程、stream编程等,才真正为我打开这些新特性的大门,用起来是真的香呀
好了,话不多说,直接开干!
忘了说了,今天我们主要讲下流式编程(stream),lambda表达式之前分享过了,感兴趣的小伙伴去爬楼吧
流式编程
流式编程(stream),顾名思义,就是让数据的流转像水一样丝滑,当然用起来确实也是如此丝滑,美滋滋。官方给的解释是:通过将集合转换为这么一种叫做 “流” 的元素序列,通过声明性方式,能够对集合中的每个元素进行一系列并行或串行的流水线操作。大同小异哈,流式编程的流程图:
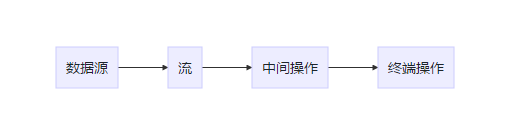
简单来说,就是把数据源转换为流stream,然后对stream进行一些操作,最后拿到你想要的数据,可以是list、map、string或者count等。就像你把水导入净水器,然后最后拿到纯净水;或者从水中提取你想要的元素,最终的结果取决于你的操作过程。
从jdk1.8开始,collection增加了一个stream方法,而且还是默认实现,也正是如此,我们也才能实现流式编程:
下面我们通过一些简单示例来演示说明一下。
集合过滤
在1.8以前,我们如果要过来集合中的元素,我们需要自己手动遍历集合,然后过滤,生成新的集合,但是如果用流式编程,一行代码搞定:
private static void listStreamTest1() {
TestEntity testEntity = new TestEntity();
ChildEntriy childEntriy = new ChildEntriy();
testEntity.setChildEntriy(childEntriy);
testEntity.setAge(20);
testEntity.setId(34124234L);
testEntity.setName("name-test");
TestEntity testEntity2 = new TestEntity();
ChildEntriy childEntriy2 = new ChildEntriy();
testEntity2.setChildEntriy(childEntriy2);
testEntity2.setAge(12);
testEntity2.setId(34124234L);
testEntity2.setName("name-test2");
List testEntityList = Lists.newArrayList(testEntity, testEntity2);
List collect = testEntityList.stream().filter(t -> t.getAge() > 18).collect(Collectors.toList());
System.out.println(collect);
}
解释下,上面我们先构建了一个TestEntity的list,我们的需求是获取testEntityList中年龄大于18的元素,我们只用了一行代码:
List collect = testEntityList.stream().filter(t -> t.getAge() > 18).collect(Collectors.toList());
其中,关键地方有两个,一个是.filter(t -> t.getAge() > 18),这里是我们的过滤条件,过滤条件就是我们要保留的元素,只是条件为true的时候,才会被保留,同样也用到了lambda表达式;一个是collect(Collectors.toList()),作用是将符合条件的元素收集起来
我们也可以对过滤之后的元素做其他操作,以满足我们不同需求:
统计条数
过滤完直接返回符合条件的元素个数
long count = testEntityList.stream().filter(t -> t.getAge() > 18).count();
转成map
这里直接用Collectors.toMap就可以了。
Map collect1 = testEntityList.stream().filter(t -> t.getAge() > 18).collect(Collectors.toMap(TestEntity::getId, TestEntity::getName));
上面这行代码,是将过滤后的元素构建成key为id,value为name的map,写法看起来很高端,比如TestEntity::getId其实就是获取元素的id,也是lambda表达式的写法,常规的lambda表达式写法是这样的:
Map collect3 = testEntityList.stream().filter(t -> t.getAge() > 18).collect(Collectors.toMap(t -> t.getId(), t -> t.getName()));
t -> t.getName()写法就等同于TestEntity::getName,看习惯就好了
如果你想要构建key为id,value为当前元素的集合,这样写就可以了:
Map collect2 = testEntityList.stream().filter(t -> t.getAge() > 18).collect(Collectors.toMap(TestEntity::getId, t -> t));
补充说明
其实不通过filter也是可以直接操作的,从这一点上来说,straem式编程确实很灵活,就像你们家的净水器一样,不需要中间哪个功能段,可以直接拿掉,很灵活有没有:
List collect1 = testEntityList.stream().collect(Collectors.toList());
long count = testEntityList.stream().filter(t -> t.getAge() > 18).count();
Map collect2 = testEntityList.stream().collect(Collectors.toMap(TestEntity::getId, TestEntity::getName));
Map collect3 = testEntityList.stream().collect(Collectors.toMap(t -> t.getId(), t -> t.getName()));
Map collect4 = testEntityList.stream().collect(Collectors.toMap(TestEntity::getId, t -> t));
其他应用
内容未完待续……明天我们继续,今天时间不够了,六点半起床,一个小时没搞完 ,但是早起感觉不错哟,继续坚持,奥里给
,但是早起感觉不错哟,继续坚持,奥里给 !
!
结语
今天我们分享了流式编程(stream)常用的接口和用法,从实际意义上讲,这些确实很方便,也确实很实用,一方面让你的代码更简洁,更好看,逼格也更高;另外一方面,免去了繁琐的循环遍历,代码的性能也上来了,岂不是美滋滋 。
。
更现实的意义是,如果你不去主动学这些东西,不去主动用这些东西,也行未来有一天你入职新公司了,你可能连java原生的代码写法都看不懂了,一脸懵逼😳,你说你问身边人吧,人比人家资深,应该懂得更多,结果还不如新人,你说尴尬不 ?再多说一句,其实大家都很鄙视那些比你资深,拿的工资可能还比你高
?再多说一句,其实大家都很鄙视那些比你资深,拿的工资可能还比你高 ,但知道的还没你多的人,所以你想成为这样的人吗?不想就得学习新东西,这是现实,你说呢?
,但知道的还没你多的人,所以你想成为这样的人吗?不想就得学习新东西,这是现实,你说呢?
项目路径:
https://github.com/Syske/example-everyday
本项目会每日更新,让我们一起学习,一起进步,遇见更好的自己,加油呀
- END -