
面试官:为什么ConcurrentHashMap要放弃分段锁?
什么是分段锁
我们都知道 HashMap 是一个线程不安全的类,多线程环境下,使用 HashMap 进行put操作会引起死循环,导致CPU利用率接近100%,所以如果你的并发量很高的话,所以是不推荐使用 HashMap 的。
而我们所知的,HashTable 是线程安全的,但是因为 HashTable 内部使用的 synchronized 来保证线程的安全,所以,在多线程情况下,HashTable 虽然线程安全,但是他的效率也同样的比较低下。
所以就出现了一个效率相对来说比 HashTable 高,但是还比 HashMap 安全的类,那就是 ConcurrentHashMap,而 ConcurrentHashMap 在 JDK8 中却放弃了使用分段锁,为什么呢?那他之后是使用什么来保证线程安全呢?我们今天来看看。
什么是分段锁?
其实这个分段锁很容易理解,既然其他的锁都是锁全部,那分段锁是不是和其他的不太一样,是的,他就相当于把一个方法切割成了很多块,在单独的一块上锁的时候,其他的部分是不会上锁的,也就是说,这一段被锁住,并不影响其他模块的运行,分段锁如果这样理解是不是就好理解了,我们先来看看 JDK7 中的 ConcurrentHashMap 的分段锁的实现。
在 JDK7 中 ConcurrentHashMap 底层数据结构是数组加链表,这也是之前阿粉说过的 JDK7和 JDK8 中 HashMap 不同的地方,源码送上。
//初始总容量,默认16
static final int DEFAULT_INITIAL_CAPACITY = 16;
//加载因子,默认0.75
static final float DEFAULT_LOAD_FACTOR = 0.75f;
//并发级别,默认16
static final int DEFAULT_CONCURRENCY_LEVEL = 16;
static final class Segment<K,V> extends ReentrantLock implements Serializable {
transient volatile HashEntry<K,V>[] table;
}
在阿粉贴上的上面的源码中,有Segment<K,V>,这个类才是真正的的主要内容, ConcurrentHashMap 是由 Segment 数组结构和 HashEntry 数组结构组成.
我们看到了 Segment<K,V>,而他的内部,又有HashEntry数组结构组成. Segment 继承自 RentrantLock 在这里充当的是一个锁,而在其内部的 HashEntry 则是用来存储键值对数据.
图就像下面这个样子
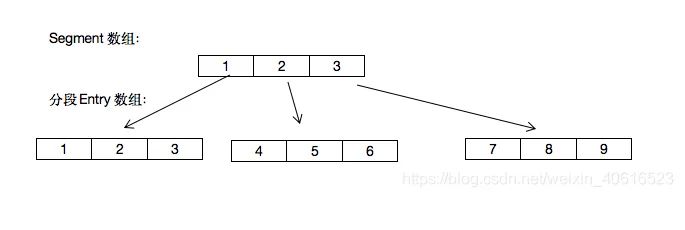
也就是说,一个Segment里包含一个HashEntry数组,每个HashEntry是一个链表结构的元素,当需要put元素的时候,并不是对整个hashmap进行加锁,而是先通过hashcode来知道他要放在哪一个分段中,然后对这个分段进行加锁。
最后也就出现了,如果不是在同一个分段中的 put 数据,那么 ConcurrentHashMap 就能够保证并行的 put ,也就是说,在并发过程中,他就是一个线程安全的 Map 。
为什么 JDK8 舍弃掉了分段锁呢?
这时候就有很多人关心了,说既然这么好用,为啥在 JDK8 中要放弃使用分段锁呢?
这就要我们来分析一下为什么要用 ConcurrentHashMap ,
1.线程安全。
2.相对高效。
因为在 JDK7 中 Segment 继承了重入锁ReentrantLock,但是大家有没有想过,如果说每个 Segment 在增长的时候,那你有没有考虑过这时候锁的粒度也会在不断的增长。
而且前面阿粉也说了,一个Segment里包含一个HashEntry数组,每个锁控制的是一段,那么如果分成很多个段的时候,这时候加锁的分段还是不连续的,是不是就会造成内存空间的浪费。
所以问题一出现了,分段锁在某些特定的情况下是会对内存造成影响的,什么情况呢?我们倒着推回去就知道:
1.每个锁控制的是一段,当分段很多,并且加锁的分段不连续的时候,内存空间的浪费比较严重。
大家都知道,并发是什么样子的,就相当于百米赛跑,你是第一,我是第二这种形式,同样的,线程也是这样的,在并发操作中,因为分段锁的存在,线程操作的时候,争抢同一个分段锁的几率会小很多,既然小了,那么应该是优点了,但是大家有没有想过如果这一分块的分段很大的时候,那么操作的时间是不是就会变的更长了。
所以第二个问题出现了:
2.如果某个分段特别的大,那么就会影响效率,耽误时间。
所以,这也是为什么在 JDK8 不在继续使用分段锁的原因。
既然我们说到这里了,我们就来聊一下这个时间和空间的概念,毕竟很多面试官总是喜欢问时间复杂度,这些看起来有点深奥的东西,但是如果你自己想想,用自己的话说出来,是不是就没有那么难理解了。
什么是时间复杂度
百度百科是这么说的:
在计算机科学中,时间复杂性,又称时间复杂度,算法的时间复杂度是一个函数,它定性描述该算法的运行时间,
这是一个代表算法输入值的字符串的长度的函数。时间复杂度常用大O符号表述,不包括这个函数的低阶项和首项系数
其实面试官问这个 时间复杂度 无可厚非,因为如果你作为一个公司的领导,如果手底下的两个员工,交付同样的功能提测,A交付的代码,运行时间50s,内存占用12M,B交付的代码,运行时间110s,内存占用50M 的时候,你会选择哪个员工提交的代码?
A 还是 B 这个答案一目了然,当然,我们得先把 Bug 这种因素排除掉,没有任何质疑,肯定选 A 员工提交的代码,因为运行时间快,内存占用量小,那肯定的优先考虑。
那么既然我们知道这个代码都和时间复杂度有关系了,那么面试官再问这样的问题,你还觉得有问题么?
答案也很肯定,没问题,你计算不太熟,但是也需要了解。
我们要想知道这个时间复杂度,那么就把我们的程序拉出来运行一下,看看是什么样子的,我们先从循环入手,
for(i=1; i<=n; i++)
{
j = i;
j++;
}
它的时间复杂度是什么呢?上面百度百科说用大O符号表述,那么实际上它的时间复杂度就是 O(n),这个公式是什么意思呢?
线性阶 O(n),也就是说,我们上面写的这个最简单的算法的时间趋势是和 n 挂钩的,如果 n 变得越来越大,那么相对来说,你的时间花费的时间也就越来越久,也就是说,我们代码中的 n 是多大,我们的代码就要循环多少遍。这样说是不是就很简单了?
关于时间复杂度,阿粉以后会给大家说,话题跑远了,我们回来,继续说,JDK8 的 ConcurrentHashMap 既然不使用分段锁了,那么他使用的是什么呢?
JDK8 的 ConcurrentHashMap 使用的是什么?
从上面的分析中,我们得出了 JDK7 中的 ConcurrentHashMap 使用的是 Segment 和 HashEntry,而在 JDK8 中 ConcurrentHashMap 就变了,阿粉现在这里给大家把这个抛出来,我们再分析, JDK8 中的 ConcurrentHashMap 使用的是 synchronized 和 CAS 和 HashEntry 和红黑树。
听到这里的时候,我们是不是就感觉有点类似,HashMap 是不是也是使用的红黑树来着?有这个感觉就对了,
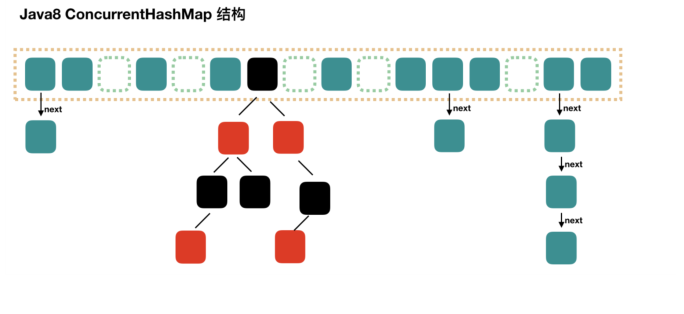
ConcurrentHashMap 和 HashMap 一样,使用了红黑树,而在 ConcurrentHashMap 中则是取消了Segment分段锁的数据结构,取而代之的是Node数组+链表+红黑树的结构。
为什么要这么做呢?
因为这样就实现了对每一行数据进行加锁,减少并发冲突。
实际上我们也可以这么理解,就是在 JDK7 中,使用的是分段锁,在 JDK8 中使用的是 “读写锁” 毕竟采用了 CAS 和 Synchronized 来保证线程的安全。
我们来看看源码:
//第一次put 初始化 Node 数组
private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
while ((tab = table) == null || tab.length == 0) {
if ((sc = sizeCtl) < 0)
Thread.yield(); // lost initialization race; just spin
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
if ((tab = table) == null || tab.length == 0) {
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = tab = nt;
sc = n - (n >>> 2);
}
} finally {
sizeCtl = sc;
}
break;
}
}
return tab;
}
public V put(K key, V value) {
return putVal(key, value, false);
}
/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0)
tab = initTable();
//如果相应位置的Node还未初始化,则通过CAS插入相应的数据
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
...
//如果该节点是TreeBin类型的节点,说明是红黑树结构,则通过putTreeVal方法往红黑树中插入节点
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
//如果binCount不为0,说明put操作对数据产生了影响,如果当前链表的个数达到8个,则通过treeifyBin方法转化为红黑树,如果oldVal不为空,说明是一次更新操作,返回旧值
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
addCount(1L, binCount);
return null;
}
put 的方法有点太长了,阿粉就截取了部分代码,大家莫怪,如果大家有兴趣,大家可以去对比一下去 JDK7 和 JDK8 中寻找不同的东西,这样亲自动手才能收获到更多不是么?
文章参考
《百度百科-时间复杂度》