
C++异步变化:libunifex实现!

导语 | 本篇我们将重点从libunifex介绍,感受sender/receiver模型带来的整个C++异步的改变,以及它为何能够弥补lambda post的一些缺陷,希望对这部分感兴趣的开发者提供一些经验和思考。
前言
在前文《C++异步从理论到实践!》中我们也提到过,对于lambda post的一些缺陷,在execution中都能够比较好的得到解决。由于c++ execution目前还是PR状态,并未正式发布,但sender/receiver机制应该是得到了越来越多人的认可了,也确实将C++的异步提到了一个新的高度。这里我们选用高度符合标准提案,能够实际测试,并且test众多的libunifex来展开本篇的内容,从libunifex上,我们也能感受到sender/receiver模型带来的整个C++异步的改变,以及他为何能够弥补lambda post的一些缺陷。
需要注意的是,execution的实现大量依赖c++ linq与 cpo-tag_invoke机制,所以请务必通过前文先了解这两块,会让大家理解整个库的代码实现方便很多:《C++尝鲜:在C++中实现LINQ!》、《C++特殊定制:揭秘cpo与tag_invoke!》
另外,本文侧重于libunifex的源码分析,所以内容本身更多会围绕libunifex来展开。
众所周知execution提案出来前几经变更,到这版的sender/receiver模型,跟最初的提案已经有了相当大的区别,希望了解这部分历史,以及整个c++异步演化过程,如std::async,std::future,std::promise等存在的适用性问题等,可以直接阅读Madokakaroto的相关文章和视频, Madokakaroto以清晰的主线讲述了整个execution迭代的方方面面,也能够帮助大家快速了解exectuion本身,非常推荐阅读与观看:
Madokakaroto-浅谈The C++ Executors
(https://zhuanlan.zhihu.com/p/395250667)
Madokakaroto-The C++ Executors设计与演化的简史
(https://www.bilibili.com/video/BV1VM4y1c7yW?spm_id_from=333.999.0.0)
二、libunifex的主要设计目标
除了前面说的解决lambda post的一些缺陷外,libunifex官方给出的设计目标主要是以下这几个:
(一)将一些共性问题封装为可复用的算法
sender/receiver机制的主要目标之一是能够允许业务通过泛型的异步算法来组合各类异步操作,甚至这种方式也能在不同领域和任意类型的异步操作中得到复用。
在平时的异步开发中,我们会遇到有很多共性问题情况。
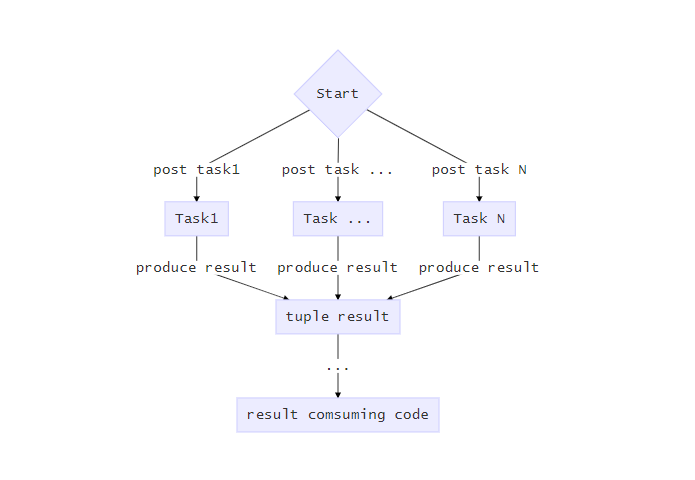
如上图所示,在业务开发中我们可能会在并发的执行多个操作后,阻塞的等待他们执行完成,并且将他们产生的结果直接包装为一个tuple返回的情况。如果没有错误产生,这不是一个太难的问题。
但假设执行的过程中,某个Task的执行有可能失败,比如Task1发生了错误,这种情况下正确的做法应该是尝试取消正在执行的其他任务,并将错误向外层传递。但有过相关经验的同学应该知道,这种代码实现起来往往比较复杂,并且在缺乏相关的并发编程经验的情况下很难让相关代码正确高效的运行。更不用说因为业务代码和并发代码的耦合导致在发生一些Bug的情况下,会导致我们花上大半夜时间去尝试定位和fix到底哪里错了的问题了。
这种情况下我们很自然的能想到,通过适当的封装,将这种共性问题的解决由每个地方的专用代码,变为可重用的算法,但实际我们通过execution方案的多次变更,并且到最后整个模型都推翻重新设计的情况,就知道要做到这点并不容易。可喜的是,新的sender/receiver模型的提出,以及cpo的使用,让问题得到收敛并且我们切实得到了一个已经能够逐步投入工业生产的解决方案。通过这样的方案:
我们能够对每个通用算法做足够细致的测试,保证它们的适用性和正确性。这样自然也能规避掉很多因为各处专有代码实现导致的一些极难发现的Bug。
业务开发可以在一个更高的抽象层次上思考问题的解决方案。
很多时候处理并发和异步任务,会像我们处理ranges一样的简洁。
(二)异步concepts抽象
前面我们介绍cpo的时候也提到过,cpo主要是配合泛型来使用的,但泛型带来通用性的同时,也会容易引入错误,这种情况下,就需要提供一组concepts来对不同的cpo接受的参数进行约束了。这样一方面很多约束问题被解决了,另外,concept本身的定义也能很好的体现整个框架的设计思路。
在了解libunifex相关设计前,我们先来看一下ranges相关的设计,对于cpo与concept的结合使用,ranges的相关实现同样清晰。这样对ranges有了解的读者可以通过对比快速的掌握libunifex的相关设计意图。
ranges cpos
ranges concepts
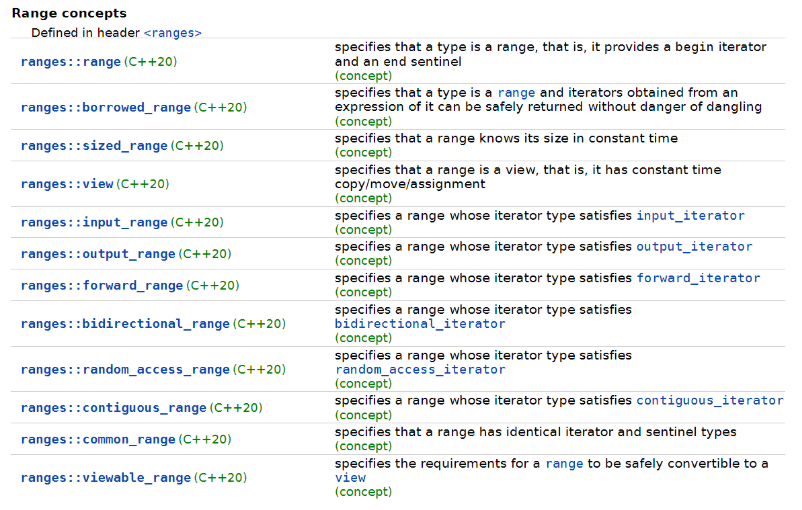
与传统的函数Api方式相比,cpo的定义,加上辅助的concepts,就形成了基本的业务外观,通过了解它们,你基本就了解了整个接口的设计和使用约束。
当然,这种方式比传统的函数Api来说,会复杂一些。使用传统函数Api的SDK中,我们掌握一组Api就能够很好的使用一个功能库了。但对于使用cpo+concept的库来说,我们需要同时理解cpo和关联的concepts,才能更好的掌握和使用对应的库。
未使用ranges的同学,可以通过已经被不同compiler支持的c++20 ranges来尝试掌握一下这种新的Api包装方式,ranges本身也是c++20开发中的一大助力,具体的ranges相关的内容可以参考《C++尝鲜:在C++中实现LINQ!》
libunifex的concepts概述
了解了ranges相关的实现后,我们再切回libunifex来看一下libunfiex中的cpos与concepts实现。
libunifex因为是遵循sender/receiver的设计模式,所以我们能看到很多concepts基本都是围绕这个来定义的。
异步操作的包装
首先要解决前面提到的统一异步模型的目的,我们肯定需要对异步操作有一个基础的抽象,我们先来看一下libunifex是如何完成对一个异步操作的包装的:
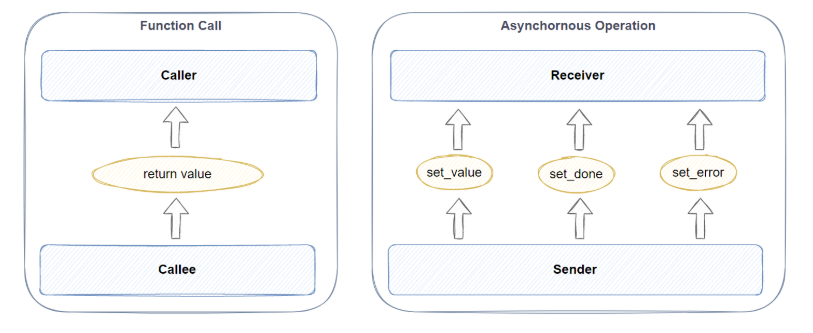
这里我们直接以普通函数的执行过程来类比,如上图所示,区别于普通函数通过return来返回值,libunifex中的Sender和Receiver所表达的是这样一种关系:一个作为生产者的Sender对象通过
set_value
set_done
set_error
这三个receivers cpo的其中一个来向作为消费者的Receiver对象传递值的。
libunifex中的异步concepts简介
Receiver-libunifex中的消费者类型,用于接收异步操作结果的对象。
Sender-libunifex中的生产者类型,会将自己的结果通过其中一种callback方式传递给关联的Receiver(set_value/ set_done/ set_error 中的一个)
TypedSender-同上,添加了对生产的数值类型的约束。
OperationState-用于持有异步操作状态的对象,一般由connect()产生。
ExecutionContext-并不直接出现的类型,表达一个支持异步任务执行的上下文环境,一般通过Scheduler概念来包装使用,但对于我们理解libunifex的执行模型比较重要。
Scheduler-libunifex中可以支持异步操作调度的调度器实现。
TimeScheduler-同上,额外支持特定时间点执行任务的能力。
StopToken-不同类型的stop-token实现,用于libunifex的取消机制。
ManySender-Sender的一种扩展,可以传递多个值到Receiver(可以不详细了解,非标准的实现)。
AsyncStream-类似用于输入范围值,序列中的每个值只会在请求的时候才惰性的去产生(可以不详细了解,非标准的实现)。
cpos主要包括:
receiver cpos-用于传递异步任务结果的set_value,set_error,set_done这三个cpo。
connect()-用于将一个Sender和一个Receiver连接起来产生一个OperationState。
start()-用于执行一个OperationState。
其它algorithm类的cpo实现-如then(),sync_wait()等。
(三)高效自然的整合c++20的协程
要达成与协程自然整合的目的,我们当然应该寻求一种机制,让所有的异步操作都能够天然的支持co_await操作,而不是为每个异步操作都重载一遍operator co_await()运算符。
首先我们还是通过coroutine的概览图重新回顾一下coroutine的核心对象和机制:
croutine中的awatiable类型天然有规避堆内存分配的作用。从operator co_await()返回一个被coroutine frame自动持有的临时awaitable对象,异步操作可以将需要的数据成员定义在其上,以避免额外的堆内存分配。
临时awaitable对象的生命周期会由compiler来保证,它的生命周期处在await_ready()和await_resume()调用之间。
有一点我们需要注意,在coroutine/awaitable模式下,异步操作的生命周期是由消费者来控制的,这与sender/receiver模式下,由生产者来持有消费者的callback,保证生命周期的正确性是不太一样的。这种生命周期控制在coroutine模式下是很自然的,compiler会生成必须的代码保证awitable对象生命周期的正确性并正确析构它。
同样的规则我们也能用于基于callback的异步操作,消费者必须保证在生产者返回值前消费者是一直持续存在的。
通过这些, 我们能够实现一个通用的operator co_await(),能够自动通过coroutine本身的生命周期策略来保证生成的awaitable对象的生命周期的正确性而不需要额外的堆内存分配。
(四)良好的cancellation支持
当我们遇到以下的几种情况:
同时发起的一组异步操作我们仅需要其中一项的执行结果。
同时发起一组异步操作后我们需要取消他们的执行。
如前面提到的, 一组异步操作中有一项出错, 我们需要取消其他异步操作的执行。
前面我们也提到过,要正确的实现相关的逻辑,并不是一个简单的事情,所以libunifex会考虑将cancellation当成一个框架固有的特性来支持,这样,相关的代码实现就会变得简单。比如对于带超时的文件异步读取,超时之后, 我们可以通过cancellation机制来中止异步读取的执行,直接向调用方返回文件读取失败的结果。
在那些并不需要取消机制的代码中,我们需要确保相关的runtime实现是不会因为cancellation机制的存在而带来额外的cpu开销的。
(五)异构计算
除了通过c++的线程来执行异步任务,有些情况下,我们会依赖特定的设备来对并发任务进行加速,比如GPU,在这种情况下,框架允许我们通过自定义scheduler+algorithm的方式来扩展相关的实现,以支持在特定的设备上执行异步计算,这样整个异步框架能够很好的同时支持在不同的exection context上执行计算,并将相关的结果传输给后续的节点。这部分具体我们会以ISPC或者PC上的CUDA为例来展开,这里不详细赘述了。
三、代码实现概述
《C++异步从理论到实践!》中我们也曾介绍过,libunifex的原始实现是同时支持c++20和c++17的,不过因为c++17的fallback引入了大量的宏机制以及使用大量的enable_if,导致代码噪声过重,此处的讲述我们将直接移除c++17相关的fallback,以一个比较简洁的仅包含c++20的代码作为讲述的对象。另外,libunifex的原始代码是没有进行文件夹分类的,这里我们为了更好的进行代码的迭代和理解,我们在不改变绝大多数文件名的情况下对基本的代码进行了归类,这样整个工程的结构更清晰,更方便进行迭代修改和理解。
(一)整体的代码结构
如下图所述,是基本的功能分类:
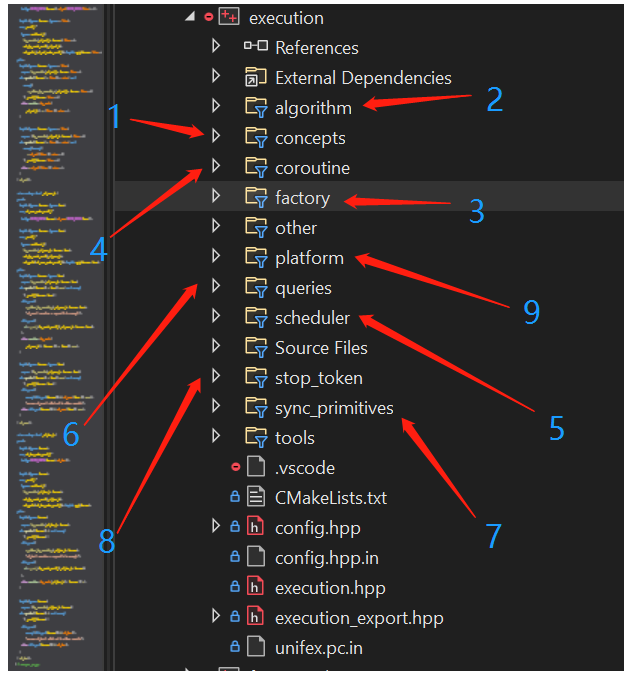
concepts: execution的各种concepts定义以及cpo定义。
algorithm: execution的各种通用算法包装,包括sender adapter,以及默认实现的各种receiver。
factory: 可以用作初始sender节点的各种sender工厂。
coroutine: croutine相关的支持部分。
scheduler: libunifex默认实现的一些调度器,后续会有一篇文章专门展开其中的实现细节。
queries: libunifex提供的少量query cpo,特定的机制比如cancellation依赖相关的query机制。
sync_primitives: libunifex中被使用的基础同步原语定义。如mutex实现等。
stop_token: cancellation相关的stop token实现。
platform: 平台专有的实现,这个地方主要是linux和windows下一些专有的scheduler的实现。
四、pipeline使用示例-结构化并发
在execution中一个比较重要的概念是pipeline,pipeline的基础知识我们在《C++尝鲜:在C++中实现LINQ!》借助ranges的实现系统的介绍了在c++中如何正确的实现一个pipeline机制,libunifex所使用的相关机制跟ranges的非常类同。我们利用execution来编写异步代码,很多时候也是在组织一个个pipeline。一个完整的pipeline的组成我们可以表述如下图:
从上图上可以看出:
每个pipeline的首节点必然是一个Sender Factory,libunifex的实现中可作为sender factory的节点特别的少,比如 just()或者schedule()这些cpo,就是一个sender_factory,调用相关的实现后会生成一个sender。
pipeline的中间是0个或者多个sender adapters,也就是在algorithm里定义的大量异步算法实现。
pipeline的末尾一般是接的一个receiver,也在algorithm文件夹下,libunifex中默认的receiver比较少,比如sync_wait()这个cpo,就是一个receiver实现,会在当前线程等待整个pipeline执行完成再继续往下执行。
整个过程的处理是从左到右发生的,sender factory产生的sender经过sender adapter修饰后依然还是sender,所以我们我们先理解sender与sender adapter之间的复合,再理解sender 与 receiver之间的复合,整个pipeline的处理基本就理解了。
如下面的例子所示:
single_thread_context tcontext;int count = 0;then([&] { ++count; })sync_wait();
这段代码比较简单:
通过schedule()节点,我们将pipeline的后续执行都交由我们通过tcontext获取的调度器来完成。
然后我们利用then()节点执行一个lambda完成对count的计数值+1。
最后利用sync_wait()节点完成对整个pipeline的执行和等待。
当然,有的时候我们为了表达的自由,或者一些特殊情况,比如还需要在整个pipeline中获取结果,如sync_wait_r(),这种情况下,我们也会组织只有sender factory和若干sender adapters组成的pipeline,最后再利用函数调用的方式执行sync_wait_r(),如下面的示例所示:
TEST(Execution, TestAllocatePipe) {single_thread_context tcontext;auto sched = tcontext.get_scheduler();auto s = just(1)| then([&](int add_val) {return add_val;});auto ret = sync_wait_r<int>(s);int count = ret.value();EXPECT_EQ(count, 1);}
这段代码与上段代码大同小异:
首先我们利用just()创建了一个能够向后续节点传值的sender(整数1)。
利用then()节点接收just()传递的值, 并且调用相关的lambda,最后再向后续节点传递该值。
使用带返回值的sync_wait_r<>()执行对应的pipeline,并获取返回值。
当然,还有一些极端情况,我们直接不使用pipeline,而是直接通过函数调用的方式来组织代码,比如对于第一段示例代码,它的函数调用方式为:
sync_wait(then(schedule(tcontext.get_scheduler()), [&] { ++count; }));这种方式虽然与pipeline是等价的,但在node比较多,相关参数也比较多的情况下,明显可读性会急剧下降,所以正常我们还是推荐更多的使用pipeline表达方式,之前在介绍《C++尝鲜:在C++中实现LINQ!》的时候也简单提到过,pipeline机制加上cpo与compiler的优化是能够很好的配合的,很多时候编译器可以将相关代码直接优化到极简的调用模式,所以这种情况下,我们肯定是选择可读性更好的方式,剩下的事情更多的交给compiler来做了。
五、start()与connect()机制
在前一部分的示例中,我们隐藏了一个比较重要的概念,sender和receiver是如何连接起来,并且配合工作的呢?
我们将前面的pipeline图做适当的展开:
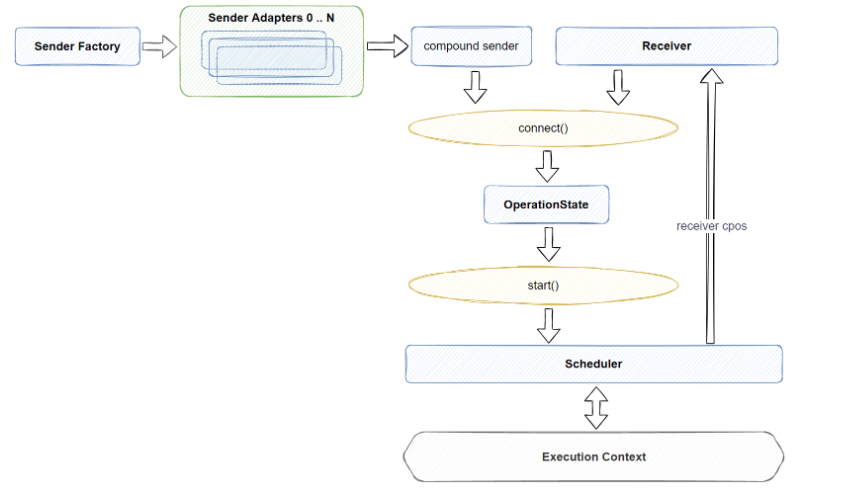
答案是黄色部分的connect()和start()这两个cpo,通过connect,我们能将任意符合约束的sender和receiver连接到一起,产生一个中间对象OperationState,然后再通过start(OperationState),相关的 OperationState就会在指定的Exectuion Context上被执行了。
这里很多作者都会强调start-connect机制带来的lazy evaluation的特性,后续篇章中我们将会具体分析这个特性的形成以及带来的好处,OperationState的生命周期等细节。
我们以libunifex的sync_wait实现举例,前面的例子中,我们直接通过pipeline就完成了整个异步操作的执行,实际上sync_wait本身帮我们封装了connect()和start()相关的操作:
auto _sync_wait_cpo::operator()(Sender&& sender) const {using Result = /*unspecified*/;return _sync_wait::_impl<Result>((Sender&&) sender);}
对应的_imp实现为:
auto _impl(Sender&& sender) {manual_event_loop ctx;// Store state for the operation on the stack.auto operation = connect((Sender&&)sender,_sync_wait::receiver_t<Result>{promise, ctx});start(operation);ctx.run();// ... (result handling here)}
整个执行过程,忽略一些细节,主要就是以下几步:
执行connect()操作连接sender和receiver,形成对应的operation state。
对operation state执行start()操作。
对结果的收尾处理。
注意此处sync_wait()的实现为了接收前面sender传输的结果, 有一个隐含的 _sync_wait::receiver_t<>的receiver实现, 此处为了代码的简洁, 并没有展开, 后续其他实现的分析中, 我们也会看到类似的实现机制, 需要中转或者接收sender的结果, 我们都需要自定义的receiver实现.
另外就是细心的读者可能发现上述context的定义和使用,这部分的作用其实就是单纯用来等待异步执行结果的,详细的分析会在后期具体展开,此处不再赘述。
七、总结
本篇我们通过:
对libunifex设计目标的了解
对整体代码的初步认知
pipeline概念的简单了解和简单的示例
start()和connect()机制的简介
sync_wait()的大致实现
了解了libunifex对一个异步任务的大致处理过程,有了初步的印象后,接下来的篇章中我们会逐步展开各部分代码的实现细节。
参考资料:
1.Madokakaroto-浅谈The C++ Executors
2.Madokakaroto-The C++ Executors设计与演化的简史
作者简介
沈芳
腾讯后台开发工程师
IEG研发效能部开发人员,毕业于华中科技大学。目前负责CrossEngine Server的开发工作,对GamePlay技术比较感兴趣。
推荐阅读
