
Hudi 实践 | 字节跳动基于 Apache Hudi 构建 EB 级数据湖实践

来自字节跳动的管梓越同学一篇关于Apache Hudi在字节跳动构建EB级数据湖实践的分享。

接下来将分为场景需求、设计选型、功能支持、性能调优、未来展望五部分介绍Hudi在字节跳动推荐系统中的实践。



在推荐系统中,我们在两个场景下使用数据湖
1.我们使用BigTable作为整个系统近线处理的数据存储,这是一个公司自研的组件TBase,提供了BigTable的语义和搜索推荐广告场景下一些需求的抽象,并屏蔽底层存储的差异。为了更好的理解,这里可以把它直接看做一个HBase。在这过程中为了能够服务离线对数据的分析挖掘需求,需要将数据导出到离线存储中。在过去用户或是使用MR/Spark直接访问存储,或是通过扫库的方式获取数据,不符合OLAP场景下的数据访问特性。因此我们基于数据湖构建BigTable的CDC,提高数据时效,减少近线系统访问压力,提供高效的OLAP访问和用户友好的SQL消费方式。2.除此之外,我们还在特征工程与模型训练的场景中使用数据湖。我们从内部和外部分别获得两类实时数据流,一个是来自系统内部回流的Instance,包含了推荐系统Serving时获得的Feature。另一种是来自端上埋点/多种复杂外部数据源的反馈,这类数据作为Label,和之前的feature共同组成了完整的机器学习样本。针对这个场景,我们需要实现一个基于主键的拼接操作,将Instance和Label Merge到一起。开窗范围可能长达数十天,千亿行量级。需要支持高效的列式选取和谓词下推。同时还需要支持并发Update等相关能力。
在这两个场景下存在如下挑战
1.数据的非常不规整。相比Binlog,WAL没法获得一行的全部信息,同时数据大小变化非常大。2.吞吐量比较大,单表吞吐超百GB/s,单表PB级存储。3.数据Schema 复杂。数据存在高维、稀疏等现象。表列数从1000-10000+都有。并且有大量复杂数据类型。


在引擎选型时,我们考察过Hudi,Iceberg,DeltaLake三个最热门的数据湖引擎。三者在我们的场景下各有优劣,最终基于Hudi对上下游生态的开放,对全局索引的支持,对若干存储逻辑提供了定制化的开发接口等原因,选择了Hudi作为存储引擎。
•针对实时写入,选择了时效性更好的MOR。•考察了索引类型,首先因为WAL不能每次都获取到数据的分区,所以必须要全局索引。在几种全局索引实现中,为了实现高性能的写入,HBase是唯一的选择。另外两种的实现决定了都和HBase在性能有本质上的差距。•在计算引擎上和API上,当时Hudi对Flink的支持还不是特别完善,所以选择了更为成熟的Spark,为了能灵活实现一些定制功能和逻辑,也因为DataFrame的API语义限制比较多,所以选择了更底层的RDD API。

功能支持包括存储语义的MVCC和Schema注册系统。
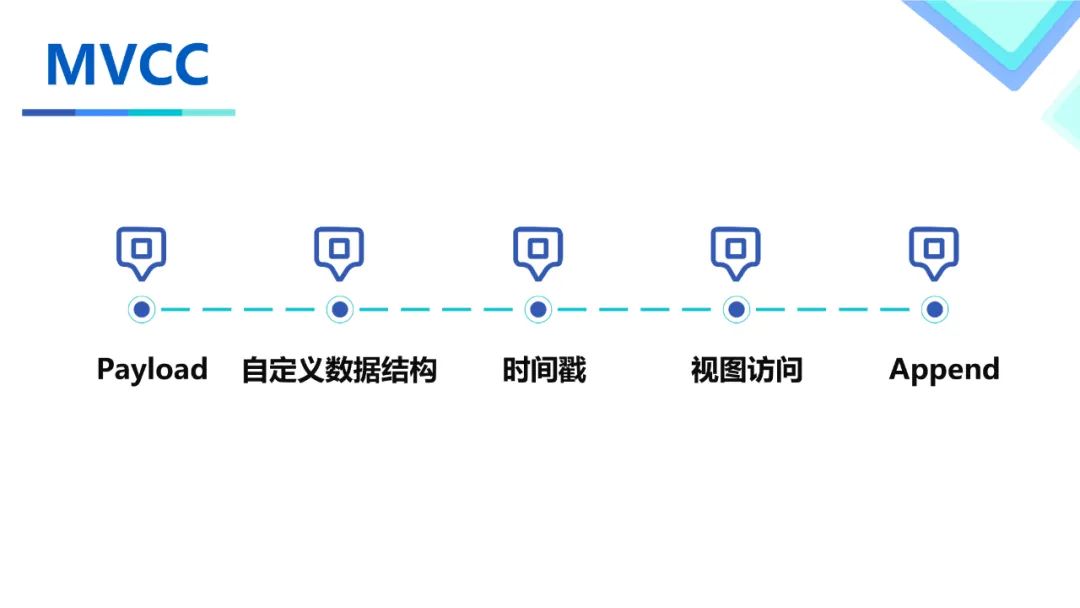
首先为了支持WAL语义的写入,我们实现了针对MVCC的Payload,基于Avro自定义了一套带时间戳的数据结构实现。并通过视图访问的方式对用户屏蔽了这套逻辑。除此之外还实现了HBase Append的语义,可以实现对List类型的追加写而非覆盖写。
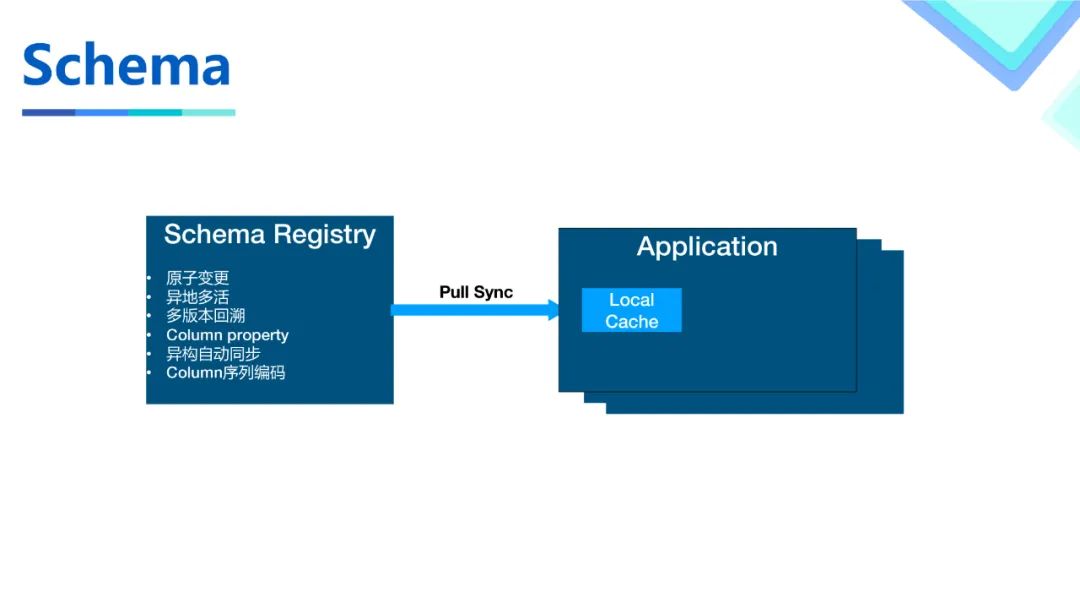
由于Hudi本身的Schema从Write的数据中获取,这种方式和其他系统对接不是很方便,以及我们需要一些基于Schema的扩展功能,所以我们构建了一个元数据中心来提供元数据相关的操作。
•首先我们基于一种内部的存储提供的语义实现了原子变更和异地多活。用户可以通过接口原子地触发Schema变更并立刻获得结果。•并通过加入版本号的方法实现了Schema的多版本,有了版本号之后可以方便的使用Schema而不是把Json传来传去。有了多版本也可以实现Schema更灵活的演进。•我们还支持了列级别的额外信息编码,来帮助业务实现一些场景下特有的扩展功能。并把列名替换成了数字来节约使用过程中的开销。•Hudi的Spark Job在使用的时候会在JVM级别构建一个local cache并通过pull的方式和元数据中心同步数据,实现Schema的快速访问和进程内Schema的单例。

在我们场景下性能挑战比较大,最大单表数据量达400PB+,日增PB级数据量,总数据量达EB级别,因此我们针对性能和数据特性开发做了一些工作来提高性能。

序列化方面包括如下优化
1.Schema:数据使用Avro序列化开销特别大,而且消耗资源也非常多。针对这个问题,我们首先借助Schema的JVM单例,规避了序列化过程中很多费CPU的比较操作。2.通过优化Payload逻辑,减少了需要序列化的次数。3.借助了第三方的Avro序列化实现,通过将序列化过程编译成字节码的方式来提高SerDe的速度以及降低内存占用。对这种序列化形式做了修改,以保证我们的复杂Schema也能够正常编译。
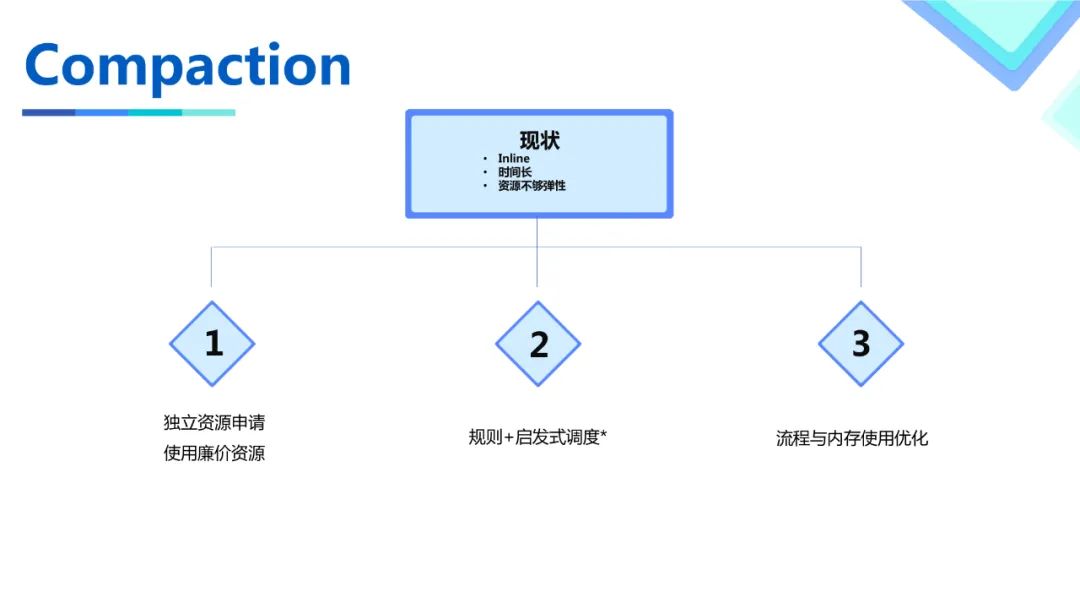
对于Compaction流程优化如下
•Hudi除了默认的Inline/Async compaction选项之外,还支持Compaction的灵活部署。Compaction Job的作业特性和Ingestion作业其实有较大区别。在同一个Spark Application当中不仅不能针对性设置,也存在资源弹性不足的问题。我们首先构建了独立部署的脚本,让Compaction作业可以独立触发运行。使用了低成本的混部队列并可以针对此次Compaction的Plan做资源申请。除此之外还做了基于规则和启发式的Compaction Strategy,用户的需求通常是保证天级别或者小时级别的SLA,并针对性地压缩某些分区的数据,所以提供了针对性压缩的能力。•为了能缩短关键Compaction的时间,我们通常会提前做Compaction来避免所有工作都在一个Compaction Job中完成。但是如果一个Compact过的FileGroup又有新的Update,就不得不再次Compact。为了优化整体的效率,我们根据业务信息对一个FileGroup该在何时被压缩做了启发式的调度以减少额外的压缩损耗。该特性的具体收益还在评估中。•最后我们对Compaction做了一些流程的优化,比如不使用WriteStatus的Cache等等。

HDFS作为一种面向吞吐设计的存储,在集群水位比较高的情况下,实时写入毛刺比较严重。通过和HDFS团队的沟通与合作,做了相关的一些工作。
•首先把原有的数据HSync操作替换为HFlush,避免了分散性update导致的磁盘IO写放大。•针对场景调参做了激进的pipeline切换设置,并且HDFS团队开发了灵活的可以控制pipeline的api,来实现这个场景下灵活的配置。•最后还通过logfile独立IO隔离的方式保证了实时写入的时效性。

还有一些零零碎碎的性能提升,流程修改和Bug Fix,大家感兴趣可以找我交流。


未来我们会在以下几个方面持续迭代。
•产品化问题:目前使用的API和调参调优方式都对用户要求很高,尤其是调参和运维,需要对Hudi原理有相当的了解才可以完成,不利于用户推广使用。•生态对接问题:在我们的场景中,技术栈以Flink为主,未来会探索Flink的使用。除此之外上下游使用的应用和环境也比较复杂,非常需要跨语言和通用的接口实现。目前和Spark绑定过于严重。•成本和性能问题:老生常谈的话题,由于我们场景比较大,所以在这块优化上的收益非常可观。•存储语义:我们把Hudi当做一种存储来使用而非一种表格式。所以未来会拓展Hudi的使用场景,需要更丰富的存储语义,会在这方面做更多的工作。
最后打个广告,我们推荐架构团队负责抖音、今日头条、西瓜视频等产品的推荐架构设计和开发,挑战大、成长快。现在正在招人,工作地包括:北京/上海/杭州/新加坡/山景城,有兴趣的小伙伴欢迎添加微信 qinglingcannotfly 或发送简历至邮箱: guanziyue.gzy@bytedance.com